本文首发于 语雀文档
题目
https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/
流程图 & 调试代码
所有流程图 & 调试代码,均以 Github 仓库上的为准
https://github.com/blueju/leetcode/
第 1 次尝试
代码
/*** @param {string} s* @return {number}*/var lengthOfLongestSubstring = function (s) {let stack = new Set();for (let i = 0; i < s.length; i++) {for (let j = i; j < s.length; j++) {if (stack.has(s[j])) {stack.clear();continue;}}}return stack.length;};
流程图
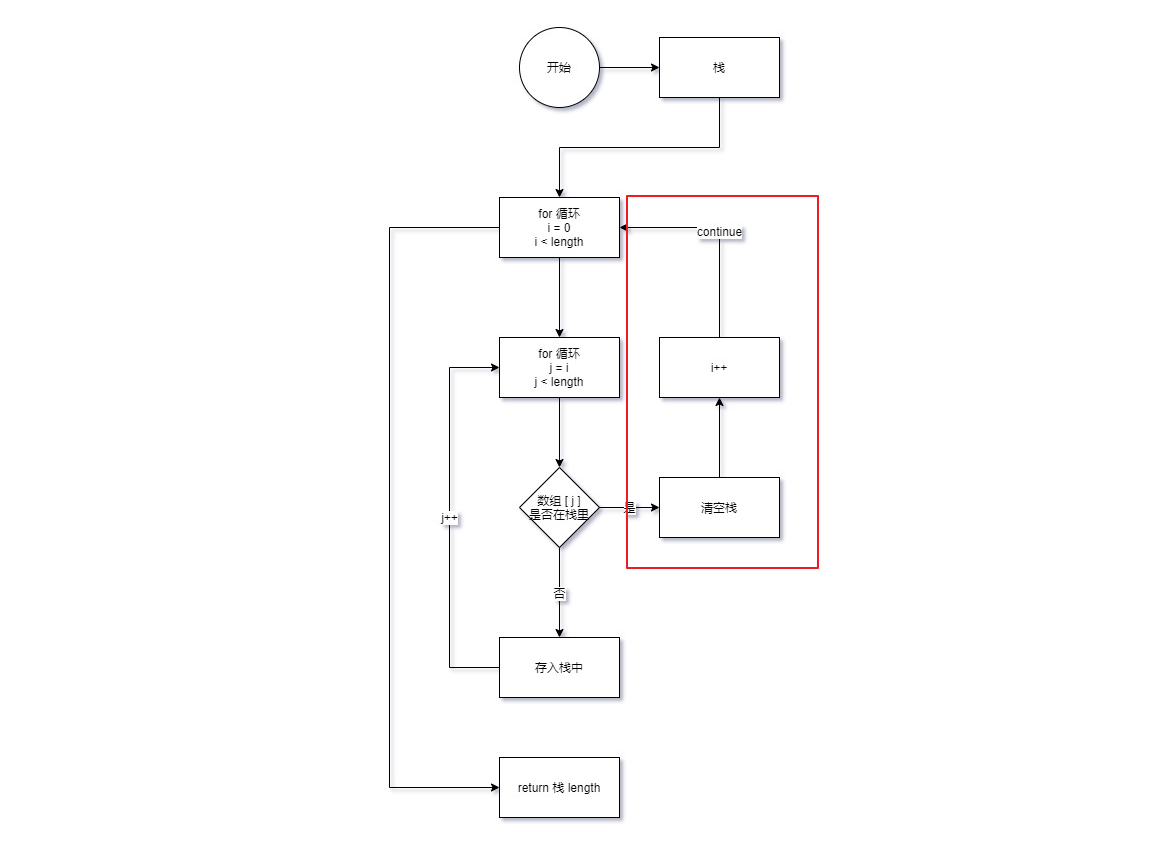
结果
未通过测试用例
错在:
- 无法统计无重复字符最长子串,因为每次发现有重复项时,都直接清空栈了,也算是错误理解题目了。
第 2 次尝试
代码
/*** @param {string} s* @return {number}*/var lengthOfLongestSubstring = function (s) {let resultStack = new Set();let tempStack = new Set();for (let i = 0; i < s.length; i++) {for (let j = i; j < s.length; j++) {if (tempStack.has(s[j])) {if (tempStack.length > resultStack.length) {resultStack = new Set([...tempStack]);tempStack.clear();} else {tempStack.clear();}break;} else {tempStack.add(s[j]);}}}return resultStack.length;};
流程图
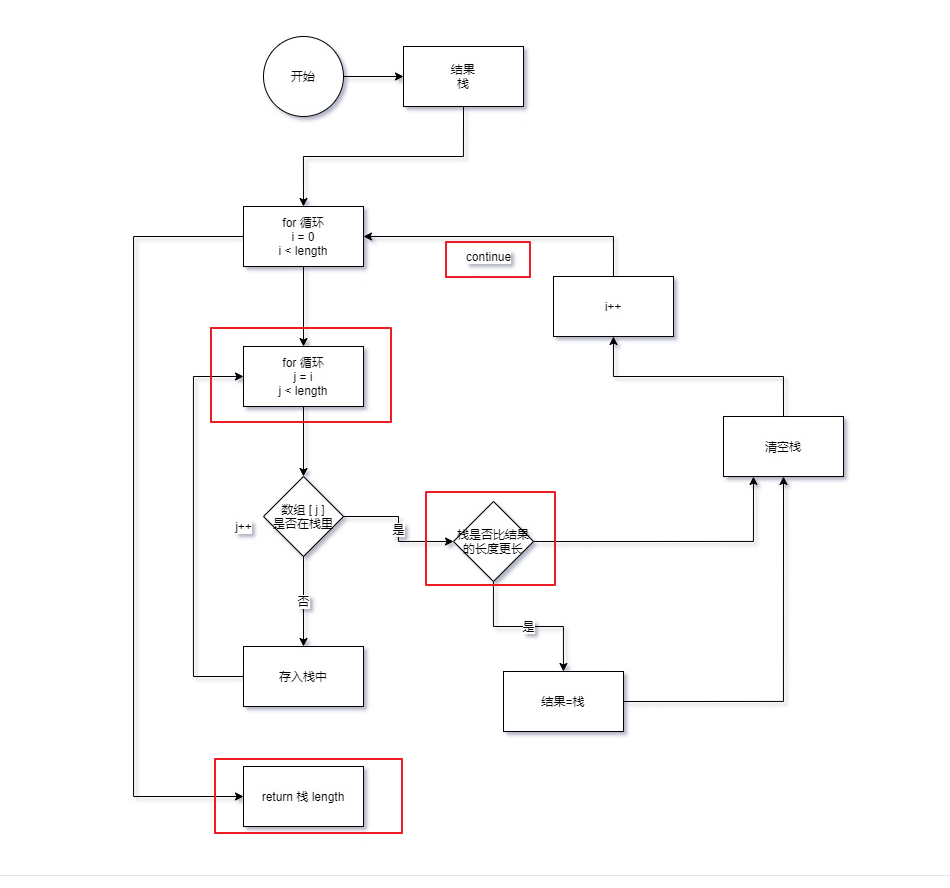
总结
未通过测试用例
错在:
- 错误使用了 Set 统计长度的 API
- 错误使用了 for 的中断跳出
第 3 次尝试
代码
/*** @param {string} s* @return {number}*/var lengthOfLongestSubstring = function (s) {let result = new Set()let stack = new Set()const length = s.lengthfor (let i = 0; i < length; i++) {for (let j = i; j < length; j++) {const item = s[j]if (stack.has(item)) {if (result.size < stack.size) {result = new Set([...stack])stack.clear()} else {stack.clear()}break} else {stack.add(item)}}}return result.size};
总结
未通过测试用例
错在
- 未考虑特殊情况(当字符串是””和” “时,字符串长度是 0 和 1 的时候)
思考:
- 结果老是用复杂数据结构存储好吗?我需要只是长度而已。
第 4 次尝试(通过测试用例)
代码
/*** @param {string} s* @return {number}*/var lengthOfLongestSubstring = function (s) {const length = s.lengthif (length === 0) return 0if (length === 1) return 1let maxLength = 0let stack = new Set()for (let i = 0; i < length; i++) {for (let j = i; j < length; j++) {if (stack.has(s[j])) {maxLength = Math.max(maxLength, stack.size)stack.clear()break} else {stack.add(s[j])}}}return maxLength};
流程图

总结
通过了测试用例
第 5 次尝试(通过测试用例)
再想想, 每次清空栈后,第一个 for 循环的索引 i 到下一位,如果我们是 abcd 遇到 c,那之前栈中保存的 abcd 中的 bcd 岂不是重新在下一次索引为 i 的 for 循环中入栈保存。
那我们是不是可以在判断栈中是否已有与 s[j] 相同的数据时,如果有也顺便判断它的位置,然后在下一次索引为 i 的 for 循环时,将 i 直接定位到重复项后面一位,以上一段话中的 abcd 遇到 c 为例,直接 i 定位到 d 处,这样就省去了在下次循环时 i 从 b 开始的时间。
代码
/*** @param {string} s* @return {number}*/var lengthOfLongestSubstring = function (s) {const length = s.lengthif (length === 0) return 0if (length === 1) return 1let maxLength = 0let stack = []for (let i = 0; i < length; i++) {for (let j = i; j < length; j++) {const index = stack.indexOf(s[j])if (index > -1) {maxLength = Math.max(maxLength, stack.length)stack.length = 0i = i + indexbreak} else {stack.push(s[j])maxLength = Math.max(maxLength, stack.length)}}}return maxLength};
流程图
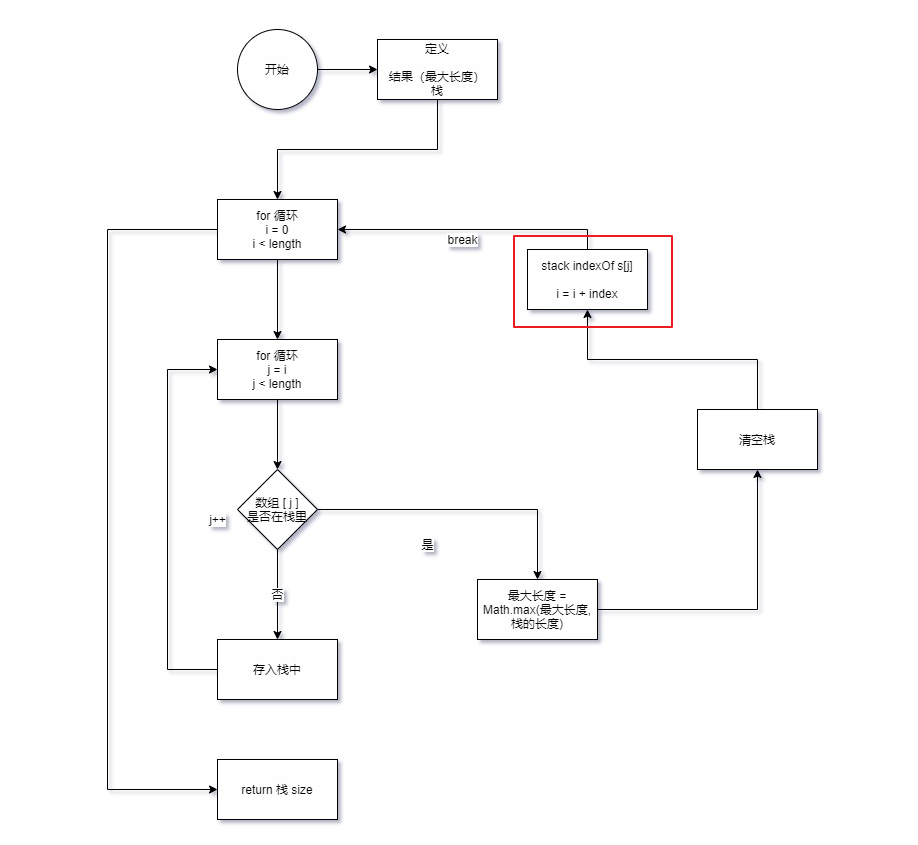
总结
通过了测试用例
虽然执行用时反而比第 4 次尝试更长了,我认为主要原因是 Set 改为 Array 的原因,并且我也尝试将第 4 次尝试改为了 Array,执行用时也一样延长到了 600+ ms。但即使如此相比,也并没有快能多,合理怀疑是测试用例的长度不够长。
思考:
- 我们能不能一次 for 循环搞定
第 6 次尝试(通过测试用例)
我们之前每次发现重复项后,都改变第一层 for 循环的索引进行重新入栈,我们依旧以 abcdb 这个例子, 第一次 for 循环,发现重复项 b 时,栈的值为 abcd;清空栈第二次 for 循环,发现重复项时,肯定是以 cd 开头,那这个 cd 是重复的,如果测试用例更长,那 cd 这样的重复计算项也会更长,那我们是不是可以考虑将其缓存起来。
看来,举例子很重要呀,能从中发现规律。
代码
基于第 4 次尝试,我们可以按以上思路改成这样:
/*** @param {string} s* @return {number}*/var lengthOfLongestSubstring = function (s) {const length = s.lengthif (length === 0) return 0if (length === 1) return 1let maxLength = 0let stack = []for (let i = 0; i < length; i++) {if (stack.includes(s[i])) {stack.shift()i--} else {stack.push(s[i])maxLength = Math.max(stack.length, maxLength)}}return maxLength};
基于第 5 次尝试,我们可以按以上思路改成这样:
/*** @param {string} s* @return {number}*/var lengthOfLongestSubstring = function (s) {const length = s.lengthif (length === 0) return 0if (length === 1) return 1let maxLength = 0let stack = []for (let i = 0; i < length; i++) {const result = stack.indexOf(s[i])if (result > -1) {stack.splice(0, result + 1)i--} else {stack.push(s[i])maxLength = Math.max(stack.length, maxLength)}}return maxLength};
结果
比之前可快多了

若有收获,就点个赞吧
0 人点赞
