所谓递归,是当一个函数调用自身,并且该调用做了同样的事情,这个循环持续到基本条件满足时,调用循环返回。
警告: 如果你不能确保基本条件是递归的 终结者,递归将会一直执行下去,并且会把你的项目损坏或锁死;恰当的基本条件十分重要!
function foo(x) {if (x < 5) return x;return foo( x / 2 );}foo(16)
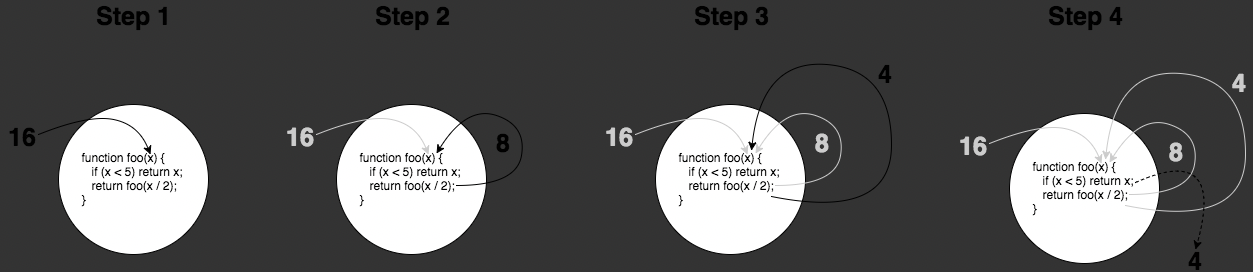
在 step 2 中, x / 2 的结果是 8, 这个结果以参数的形式传递到 foo(..) 并运行。同样的,在 step 3 中, x / 2 的结果是 4,这个结果以参数的形式传递到另一个 foo(..) 并运行
step 4:一旦我们满足了基本条件 x (值为4) < 5,我们将不再调用递归函数,只是(有效地)执行了 return 4。 特别是图中返回 4 的虚线那块,它简化了那里的过程,因此我们来深入了解最后一步,并把它折分为三个子步骤: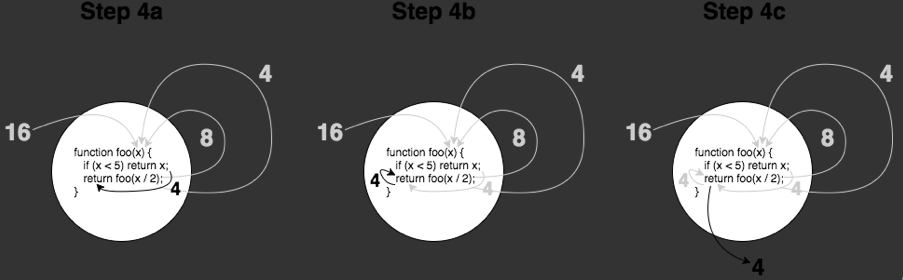
堆栈
function isOdd(v) {if (v === 0) return false;return isEven( Math.abs( v ) - 1 );}function isEven(v) {if (v === 0) return true;return isOdd( Math.abs( v ) - 1 );}isOdd( 33333 ); // RangeError: Maximum call stack size exceeded
引擎抛出这个错误,是因为它试图保护系统内存不会被你的程序耗尽。为了解释这个问题,我们需要先看看当函数调用时JS引擎中发生了什么。
每个函数调用都将开辟出一小块称为堆栈帧的内存。堆栈帧中包含了函数语句当前状态的某些重要信息,包括任意变量的值。之所以这样,是因为一个函数暂停去执行另外一个函数,而另外一个函数运行结束后,引擎需要返回到之前暂停时候的状态继续执行。
当第二个函数开始执行,堆栈帧增加到 2 个。如果第二个函数又调用了另外一个函数,堆栈帧将增加到 3 个,以此类推。“栈”的意思是,函数被它前一个函数调用时,这个函数帧会被“推”到最顶部。当这个函数调用结束后,它的帧会从堆栈中退出。
注意: 如果这些函数间没有相互调用,而只是依次执行 — 比如前一个函数运行结束后才开始调用下一个函数 baz(); bar(); foo(); — 则堆栈帧并没有产生;因为在下一个函数开始之前,上一个函数运行结束并把它的帧从堆栈里面移除了。
每一个函数运行时候,都会占用一些内存。对多数程序来说,这没什么大不了的,但是,一旦你引用了递归,问题就不一样了。 虽然你几乎肯定不会在一个调用栈中手动调用成千(或数百)次不同的函数,但你很容易看到产生数万个或更多递归调用的堆栈。
当引擎认为调用栈增加的太多并且应该停止增加时候,它会以主观的限制来阻止当前步骤,所以 isOdd(..) 或 isEven(..) 函数抛出了 RangeError 未知错误。这不太可能是内存接近零时候产生的限制,而是引擎的预测,因为如果这种程序持续运行下去,内存会爆掉的。由于引擎无法判断一个程序最终是否会停止,所以它必须做出确定的猜测。
引擎的限制因情况而定。规范里面并没有任何说明,因此,它也不是 必需的。但如果没有限制的话,设备很容易遭到破坏或恶意代码攻击,故而几乎所有的JS引擎都有一个限制。不同的设备环境、不同的引擎,会有不同的限制,也就无法预测或保证函数调用栈能调用多少次。
在处理大数据量时候,这个限制对于开发人员来说,会对递归的性能有一定的要求。我认为,这种限制也可能是造成开发人员不喜欢使用递归编程的最大原因。 遗憾的是,递归编程是一种编程思想而不是主流的编程技术。

若有收获,就点个赞吧
0 人点赞
