你想过敏捷流程里面那么大的并行工作压力是从哪里产生的吗?
好几年前写了几篇Jira的使用教程,后来没更新了。今天来水一篇番外篇,关于冲刺长度与冲刺间隔之间产生的有趣物理反应。
我们都知道敏捷开发跟瀑布流开发的不同。瀑布流开发更像是接力赛,一人跑一小段路。敏捷开发从理念上会注重多工种的任务交叉并行,让全员都参与到整个项目过程中来。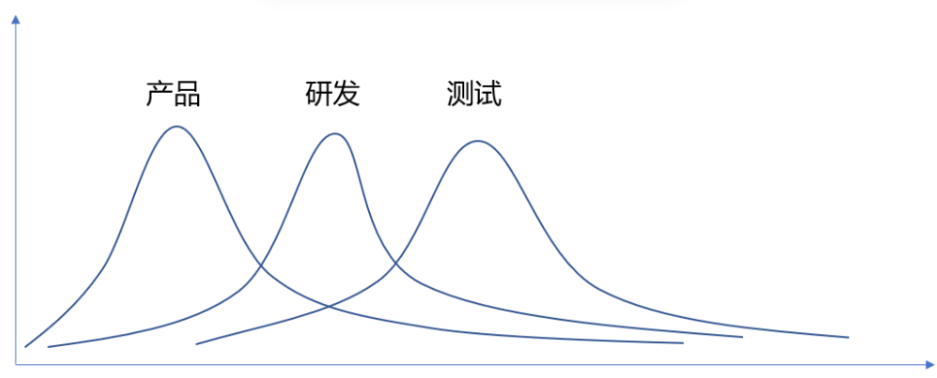
当一次冲刺中某个工种的工作变少时,就可以把腾出的精力放到下一个冲刺中,比如产品经理需求评审完之后就可以去准备下个版本的需求了,开发工程师提测之后就可以讨论下个版本的技术方案了,测试工程师测试通过发布之后就可以准备下个版本的测试用例了。
一个版本接一个版本,像列车不断发车一样,于是就有了“版本列车”这样的概念。每一期的需求像赶车的小人一样,发车之前能上车,到点就能到站(上线),发车之前上不了车,不好意思请等下一班列车。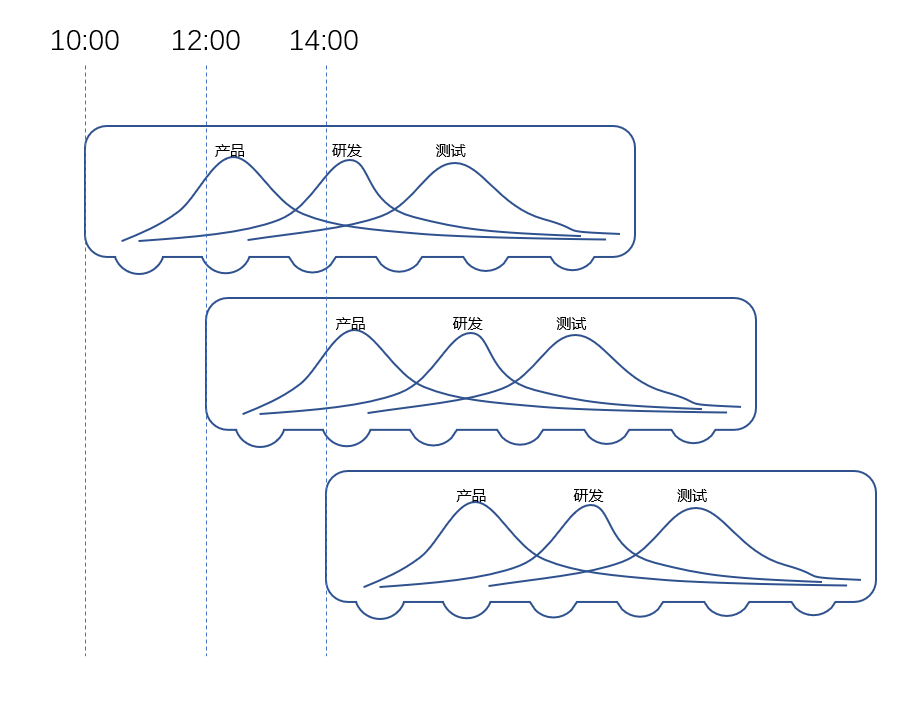
有意思的问题来了,列车运行时长和发车间隔之间,是如何影响工作人员的并行任务数量呢?
我画了几张图来研究这个问题,以周为单位,第一行的数字是列车运行时长t,第二行的数字是发车间隔i,之后每一行的彩色方块都是列车运行的时间表,最右的数字是任务并行压力:最大并行列车数n。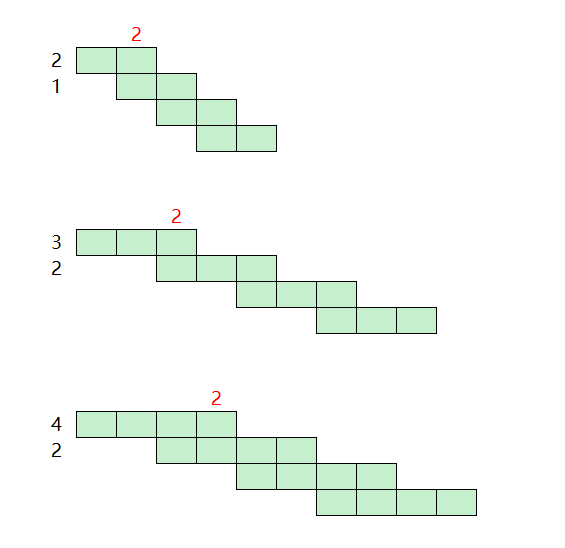
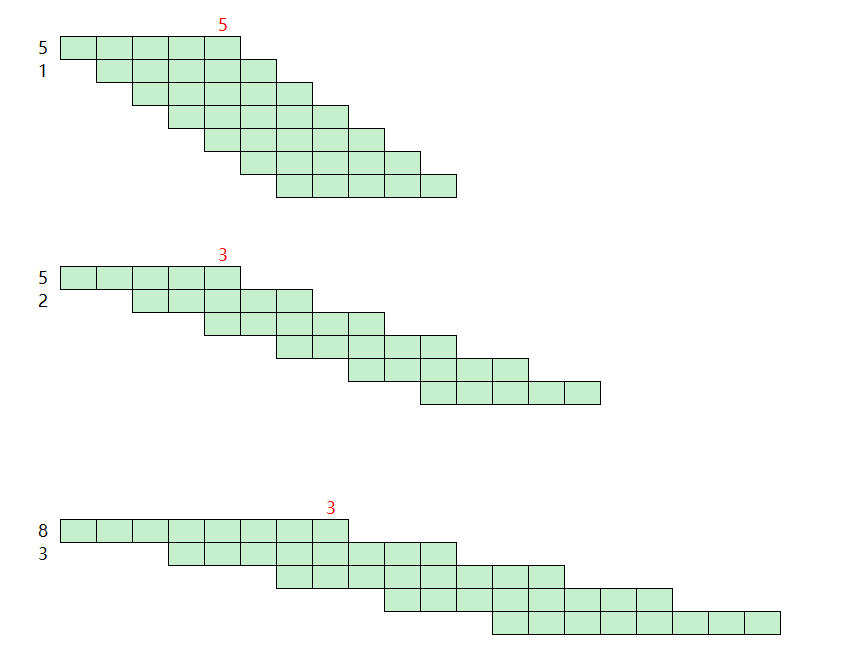
从这些图里你观察到什么规律了吗? 首先n一定是t和i的函数,即n=f(t,i)
但是具体的函数表达式是什么呢?你看出来了吗?给你点时间思考下
公布答案:n = Ceiling( t / i )
其实很简单,把发车间隔这个“缺口”明确的画出来,很容易发现规律。
当累加的发车间隔没有超过列车运行时长的时候,有几个发车间隔,就会多出几个并行的列车,当累加的发车间隔超过了列车运行时长,并行列车数不再增加。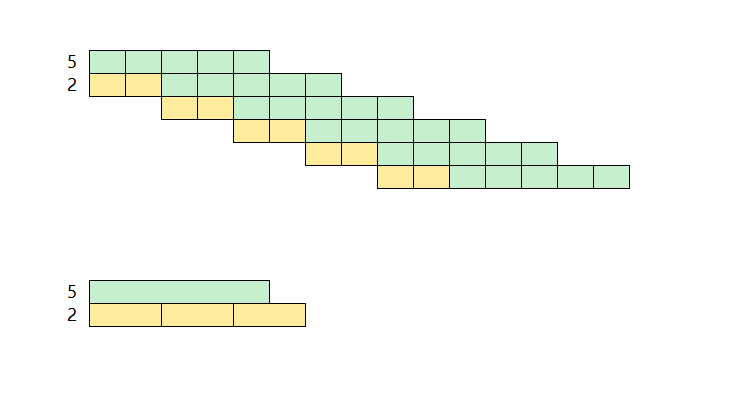
从这个简单的数学题上我们能发现什么客观规律呢?首先i是人为决定的,不受其他因素影响。
而t虽然也能说是人为决定的,但实质是冲刺中所包含的需求量S的简单一次函数,毕竟一次冲刺里想实现的需求越多,需要的时间越久。我们可以记作t=kS,k可以看作单个需求的平均工时,1/k也就是工作速度v,所以t=S/v
v又受什么影响呢?每个人的处理能力都是有限的,并且人类只能使用单线程工作模式,做A事情的时候不能做B事情,同一天里想同时做A又做B,只能停下来一会儿做A、一会儿做B。看起来是多任务处理好似多线程,实际还是单线程。
我认为你可能已经猜出来我想表达什么了。
如果用c代表单任务工作速度,那么v=c/n,这里n就是我们前面提到的并行工作量。所以t=S/(c/n)=nS/c
于是可得: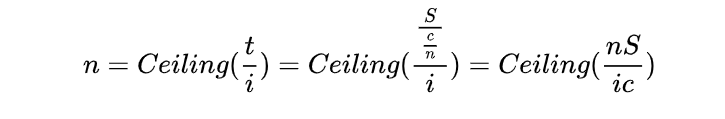
假设nS/ic结果是整数,则有n = nS / ic
换一换位置,n消掉:S = ic
来,再解读一下:一次冲刺中可以完成的需求量S,本质上取决于两次冲刺之间的发车间隔i 和 团队成员的单任务工作速度c。
如果把没说完的话说完:与并行的冲刺数n无关、与冲刺的时长t无关
简化的模型揭示了一个朴实无华且枯燥的道理:*单纯以提高并行任务量或者拉长迭代周期的方式妄图提高产出,都是自欺欺人。
其实背后的逻辑也很好解释:拉长Sprint的时长但不改变间隔Interval,并行的Sprint会变多,因此实际的产出会下降。
欲速则不达,放慢冲刺的间隔才能提升冲刺的产出,没想到吧?

若有收获,就点个赞吧
0 人点赞
