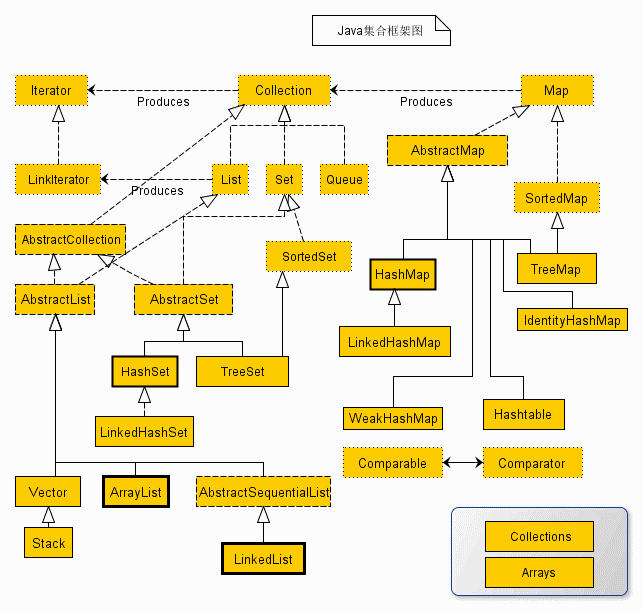
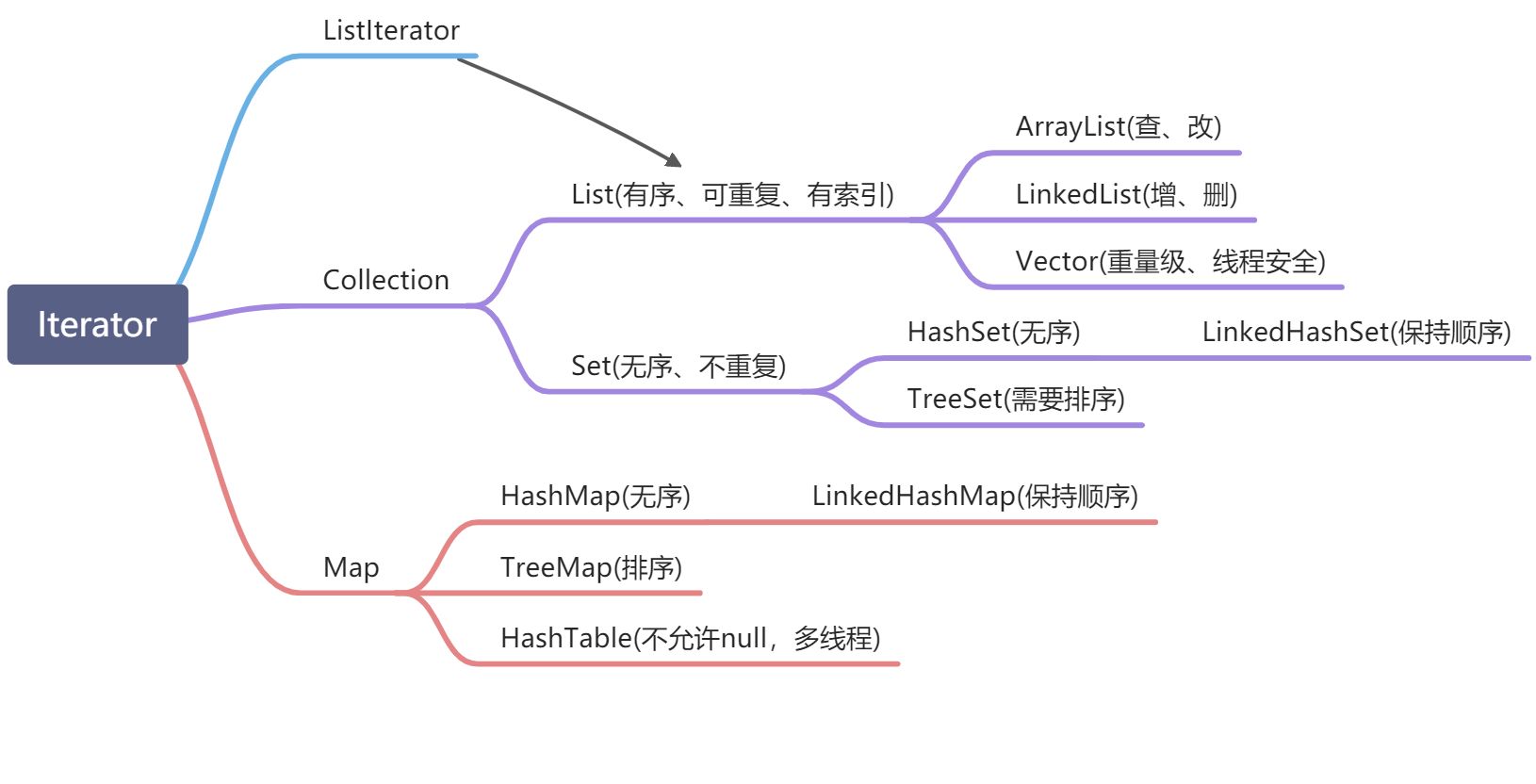
1、HashMap
HashMap详解
HashMap在JDK1.7和JDK1.8之后产生了一些变化
结构不同:
- JDK1.7是数组+链表。JDK1.8之后是数组+链表+红黑树,引入红黑树是为了提高查询效率链表O(N)其实时n/2,红黑树是O(log(N))
- 哈希碰撞时需要插入节点的时候,JDK1.7采用的是头插法,JDK1.8采用的是尾插法,头插法在多线程的环境下可能会形成循环链表,耗尽CPU性能
散列表是懒加载机制,在HashMap第一次put的时候创建。
初始化容量大小:JDK并不会直接拿传进来的数值当做默认容量,而是计算大于等于的用户传过来的初始容量最近的二次幂。最好直接传二次幂。将来(要存储的数据数量/0.75)+1。
扩容问题:
- 当插入节点的数量Size>=容量*加载因子时进行扩容。位运算,左移一位,也就是乘2,但是直接乘2,效率不好,毕竟cpu不能直接计算乘法。
树化问题:
- 链表的长度>=8,且数组的长度大于等于64时进行树化。当数组长度小于64时优先选择扩容。
PUT:
- 首先通过高低位异或运算计算出一个槽位下标也就是数组下标
- 根据槽位下表进行操作
- 开放地址法
- 当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。
- 链地址法
- HashMap和Hashtable都实现了Map接口,因此很多特性非常相似。但是,他们有以下不同点:
- HashMap允许键和值是null,而Hashtable不允许键或者值是null。
- Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。
- HashMap提供了可供应用迭代的键的集合,因此,HashMap是快速失败的。另一方面,Hashtable提供了对键的列举(Enumeration)。
-
3、ArrayList和LinkedList
ArrayList是基于数组实现的,LinkedList是基于双链表实现的。LinkedList还实现了Deque接口,Deque接口是Queue接口的子接口,它代表一个双向队列,因此LinkedList可以作为双向队列 ,栈(可以参见Deque提供的接口方法)和List集合使用,功能强大。
ArrayList 适合查找和修改 get() 直接读取第几个下标,复杂度 O(1)
- add(E) 添加元素,直接在后面添加,复杂度O(1)
- add(index, E) 添加元素,在第几个元素后面插入,后面的元素需要向后移动,复杂度O(n)
- remove()删除元素,后面的元素需要逐个移动,复杂度O(n)
LinkedList 适合插入和删除
- get() 获取第几个元素,依次遍历,复杂度O(n)
- add(E) 添加到末尾,复杂度O(1)
- add(index, E) 添加第几个元素后,需要先查找到第几个元素,直接指针指向操作,复杂度O(n)
- remove()删除元素,直接指针指向操作,复杂度O(1)
ArrayList初始容量大小是10,满了之后扩容1.5倍。
4、ConcurrentHashMap
- JDK1.7:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
JDK1.8:其中抛弃了原有的 Segment 分段锁,而采用了
CAS + synchronized来保证并发安全性。5、红黑树
维护红黑树的通过左旋和右旋来实现的
特点每个节点或者是黑色,或者是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
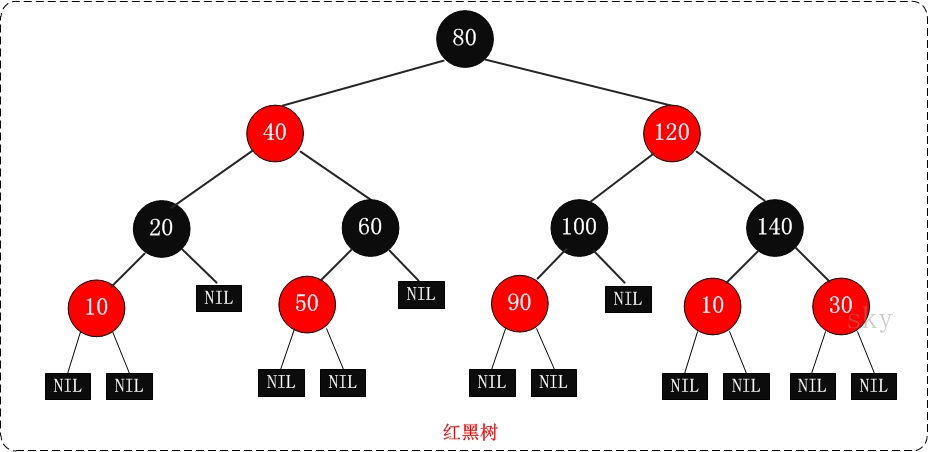
5.1、为什么用红黑树log(n)不用AVL树
红黑树:黑色完美平衡,任意一个节点到每个叶子节点的路径都包含想通数量的黑色节点。AVL树和红黑树有几点比较和区别:
(1)AVL树是更加严格的平衡,因此可以提供更快的查找速度,一般读取查找密集型任务,适用AVL树。
(2)红黑树更适合于插入修改密集型任务。
6、HashSet
HashSet底层原理就是HashMap
/*** Constructs a new, empty set; the backing <tt>HashMap</tt> instance has* default initial capacity (16) and load factor (0.75).*/public HashSet() {map = new HashMap<>();}
但是HashSet.add(“key”),HashMap(“key”,”value”),添加元素时个数不一样。HashSet之关注key,value全部都是Object。关注key是因为,key不可重复
// Dummy value to associate with an Object in the backing Mapprivate static final Object PRESENT = new Object();/*** Adds the specified element to this set if it is not already present.* More formally, adds the specified element <tt>e</tt> to this set if* this set contains no element <tt>e2</tt> such that* <tt>(e==null ? e2==null : e.equals(e2))</tt>.* If this set already contains the element, the call leaves the set* unchanged and returns <tt>false</tt>.** @param e element to be added to this set* @return <tt>true</tt> if this set did not already contain the specified* element*/public boolean add(E e) {return map.put(e, PRESENT)==null;}
7、Collections和Arrays
Collections和Arrays都是静态的类,为了方便操作集合和数组而产生。Arrays和Collections中所有的方法都为静态的,不需要创建对象,直接使用类名调用即可。
- Arrsys是数组的工具类,提供了对数组操作的工具方法。
- Arrays.binarySearch:二分查找
- Arrays.copyOf:复制
- Arrays.copyOfRange:复制部分
- Arrays.sort:排序
- Arrays.fill:填充
- Arrays.toString:字符串返回
- Arrays.hashCode:哈希值
- Collections是集合对象的工具类,提供了操作集合的工具方法。
- Collections.sort():为List集合进行排序
- Collections.max和 Collections.min:返回集合(List和Set)中的最大最小值
- Collections.reverse:反转集合内元素的顺序
- Collections.binarySearch:对List结合进行二分查找,需要先进行升序排列Collections.sort()

若有收获,就点个赞吧
0 人点赞
