1、冒泡排序
冒泡排序总的平均时间复杂度为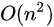
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
public static void bubbleSort(int arr[]) {for(int i =0 ; i<arr.length-1 ; i++) {for(int j=0 ; j<arr.length-1-i ; j++) {if(arr[j]>arr[j+1]) {int temp = arr[j];arr[j]=arr[j+1];arr[j+1]=temp;}}}}
2、快速排序
时间复杂度为O (nlogn)
首先设定一个分界值,通过该分界值将数组分成左右两部分
- 将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值
- 然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理
- 重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了
/*** @Description 快速排序* @Param [data, start, end]* @Return java.lang.Integer[]* @Author WJ* @Date 2021/8/29 3:17**/@Testpublic Integer[] quickSort(Integer[] data, Integer start, Integer end) {if (start >= end) {return data;}Integer low = start;Integer high = end;Integer temp = data[start];while (low < high) {while (low < high && data[high] >= temp) {high--;}data[low] = data[high];while (low < high && data[low] < temp) {low++;}data[high] = data[low];}data[low] = temp;quickSort(data, start, low - 1);quickSort(data, low + 1, end);return data;}
3、归并排序
时间复杂度:O(n log n)
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针超出序列尾
将另一序列剩下的所有元素直接复制到合并序列尾
public static int[] mergeSort(int[] nums, int l, int h) {if (l == h)return new int[] { nums[l] };int mid = l + (h - l) / 2;int[] leftArr = mergeSort(nums, l, mid); //左有序数组int[] rightArr = mergeSort(nums, mid + 1, h); //右有序数组int[] newNum = new int[leftArr.length + rightArr.length]; //新有序数组int m = 0, i = 0, j = 0;while (i < leftArr.length && j < rightArr.length) {newNum[m++] = leftArr[i] < rightArr[j] ? leftArr[i++] : rightArr[j++];}while (i < leftArr.length)newNum[m++] = leftArr[i++];while (j < rightArr.length)newNum[m++] = rightArr[j++];return newNum;}
```java private static void mergeSort(int[] arrays, int lefts, int rights, int[] newArray) {
if (lefts < rights) {int mid = (lefts + rights) / 2;mergeSort(arrays, lefts, mid, newArray);mergeSort(arrays, mid + 1, rights, newArray);mergearray(arrays, lefts, mid, rights, newArray);}
}
public static void mergearray(int a[], int first, int mid, int last, int temp[]) {
int i = first, j = mid + 1;
int m = mid, n = last;
int k = 0;
while (i <= m && j <= n) {
if (a[i] <= a[j]) {
temp[k++] = a[i++];
} else {
temp[k++] = a[j++];
}
}
while (i <= m) {
temp[k++] = a[i++];
}
while (j <= n) {
temp[k++] = a[j++];
}
for (i = 0; i < k; i++) {
a[first + i] = temp[i];
}
}
<a name="c1AEA"></a>
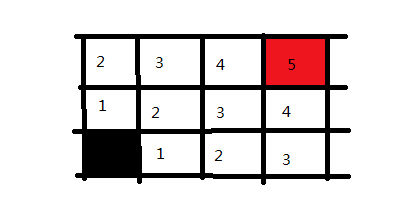
# 4、广度优先搜索BFS
**BFS(Breath First Search)广度优先搜索。**<br />何为BFS宽搜?即由一点逐级往下搜索,以图为例,由顶点v1可以延伸到v2、v3,再由v2可以延伸到v1、v4、v5,被搜索过的顶点不用再次搜索,直到整个图的节点被搜完一遍。<br />**优缺点**
- 空间复杂度是呈现出指数增长。
- 不存在爆栈的危险。
- 可以搜索最短路径、最小等问题
```java
public static void printBFS(int[][] graph,int s){
boolean[] visited = new boolean[graph.length];
Queue<Integer> queue = new LinkedList<>();
queue.add(s);
visited[s] = true;
int[] bfs = new int[graph.length];
int j = 0;
while (!queue.isEmpty()){
int vertex = queue.poll();
int[] nodes = graph[vertex];
for(int i = 0; i < nodes.length; i++){
if(!visited[i] && nodes[i]!=0){
queue.add(i);
visited[i] = true;
}
}
bfs[j] = vertex;
j++;
System.out.print(vertex+" ");
}
}
5、深度优先搜索DFS
DFS(Deep First Search)深度优先搜索。
何为DFS深搜?即先一条道走到黑,不管中途遇到什么岔路口都不停,直到这条道没后面的路了,再回到前一个岔路口,继续一条道走到黑。不断回溯,直到全部节点都被搜完。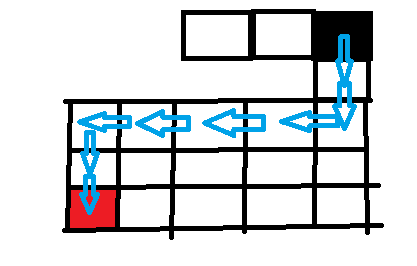
优缺点
- 空间复杂度:与深度成正比,假设深度为n,则为O(n)
- 可能会存在爆栈的危险。
不能搜最短路径,最小等问题
public static void printDFS(int[][] graph,int s,int e) { Stack<Integer> stack = new Stack<Integer>(); stack.push(s); boolean visited[] = new boolean[6];//默认为false visited[s] = true; while(!stack.isEmpty()){ int vertex = stack.pop(); int[] nodes = graph[vertex]; for(int i =0; i<nodes.length;i++){ if(!visited[i] && nodes[i]>0){ //还未访问 stack.push(i); visited[i] = true; } } System.out.print(vertex+" "); } }7、二分查找
条件:
有序
- 无重复元素
复杂度分析
- 时间复杂度:O(logN)。
- 空间复杂度:O(1)。
public int search(int[] nums, int target) { // 避免当 target 小于nums[0] nums[nums.length - 1]时多次循环运算 if (target < nums[0] || target > nums[nums.length - 1]) { return -1; } int left = 0, right = nums.length - 1; while (left <= right) { int mid = left + ((right - left) >> 1); if (nums[mid] == target) return mid; else if (nums[mid] < target) left = mid + 1; else if (nums[mid] > target) right = mid - 1; } return -1; }8、贪心算法
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。
贪心算法没有固定的算法框架,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择的贪心策略必须具备无后效性,即某个状态以后的过程不会影响以前的状态,只与当前状态有关。
所以对所采用的贪心策略一定要仔细分析其是否满足无后效性。9、滑动窗口
10、回溯法
11、动态规划
将原问题拆解成若干个子问题,同时保存子问题的答案,使得每个子问题只求解一次,最终获得原问题的答案。
记忆化搜索:自顶向下
动态规划:自底向上
11、斐波那契数列
public int fbnq(int n){
if(n == 0){
return 0;
}
if (n == 1){
return 1;
}
return fbnq(n-1)+fbnq(n-2);
}
//记忆化搜索
int[] data = new int[n+1];
public int fbnqPlus(int n){
if(n == 0){
return 0;
}
if (n == 1){
return 1;
}
if(data[n] == 0){
data[n] = fbnq(n-1)+fbnq(n-2);
}
return data[n];
}
//动态规划
public int fbnqPlusPlus(){
data[0] = 0;
data[1] = 1;
for(int i = 2;i<=n;i++){
data[i] = data[i-1]+data[i-2];
}
return data[n];
}
13、01背包
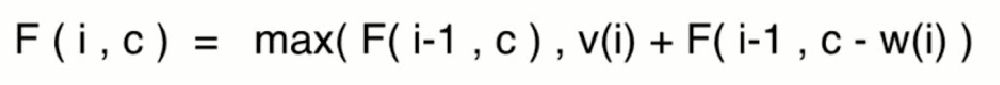
private static int package01(int[] w, int[] v, int index, int c) {
if (index < 0 || c <= 0) {
return 0;
}
int res = package01(w, v, index - 1, c);
if (c >= w[index]) {
res = Math.max(res, v[index] + package01(w, v, index - 1, c - w[index]));
}
return res;
}
//记忆化搜索
static int[][] data = new int[w.length][c + 1];
private static int package01Plus(int[] w, int[] v, int index, int c) {
if (index < 0 || c <= 0) {
return 0;
}
if(data[index][c]!= -1){
return data[index][c];
}
int res = package01(w, v, index - 1, c);
if (c >= w[index]) {
res = Math.max(res, v[index] + package01(w, v, index - 1, c - w[index]));
}
data[index][c] = res;
return res;
}
//动态规划
static int[][] data = new int[w.length][c + 1];
private static int package01PlusPlus(int[] w, int[] v, int c) {
if (w.length == 0 || v.length == 0){
return 0;
}
for (int j = 0; j < c; j++) {
data[0][j] = j>=w[0]?v[0]:0;
}
for (int i = 1; i < w.length; i++) {
for (int j = 0; j <= c; j++) {
data[i][j] = data[i-1][j];
if (j>=w[i]){
data[i][j] = Math.max(data[i][j],v[i]+data[i-1][j-w[i]]);
}
}
}
return data[w.length-1][c];
}
14、N皇后问题
15、LRU
15.1、巧用LinkedHashMap完成LRU算法
import java.util.LinkedHashMap;
public class LRUCache {
private LinkedHashMap<Integer, Integer> cache;
public LRUCache(int capacity) {
cache = new LinkedHashMap<Integer, Integer>(capacity, 0.75f, true){
private static final long serialVersionUID = 1L;
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
};
}
public int get(int key) {
return cache.getOrDefault(key, -1);
}
public void put(int key, int value) {
cache.put(key, value);
}
@Override
public String toString() {
return cache.toString();
}
}
15.2、手写LRU算法
class LRUCache2{
class Node<K, V>{//双向链表节点
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
public Node(K key, V value) {
super();
this.key = key;
this.value = value;
}
}
//新的插入头部,旧的从尾部移除
class DoublyLinkedList<K, V>{
Node<K, V> head;
Node<K, V> tail;
public DoublyLinkedList() {
//头尾哨兵节点
this.head = new Node<K, V>();
this.tail = new Node<K, V>();
this.head.next = this.tail;
this.tail.prev = this.head;
}
public void addHead(Node<K, V> node) {
node.next = this.head.next;
node.prev = this.head;
this.head.next.prev = node;
this.head.next = node;
}
public void removeNode(Node<K, V> node) {
node.prev.next = node.next;
node.next.prev = node.prev;
node.prev = null;
node.next = null;
}
public Node<K, V> getLast() {
if(this.tail.prev == this.head)
return null;
return this.tail.prev;
}
}
private int cacheSize;
private Map<Integer, Node<Integer, Integer>> map;
private DoublyLinkedList<Integer, Integer> doublyLinkedList;
public LRUCache2(int cacheSize) {
this.cacheSize = cacheSize;
map = new HashMap<>();
doublyLinkedList = new DoublyLinkedList<>();
}
public int get(int key) {
if(!map.containsKey(key)) {
return -1;
}
Node<Integer, Integer> node = map.get(key);
//更新节点位置,将节点移置链表头
doublyLinkedList.removeNode(node);
doublyLinkedList.addHead(node);
return node.value;
}
public void put(int key, int value) {
if(map.containsKey(key)) {
Node<Integer, Integer> node = map.get(key);
node.value = value;
map.put(key, node);
doublyLinkedList.removeNode(node);
doublyLinkedList.addHead(node);
}else {
if(map.size() == cacheSize) {//已达到最大容量了,把旧的移除,让新的进来
Node<Integer, Integer> lastNode = doublyLinkedList.getLast();
map.remove(lastNode.key);//node.key主要用处,反向连接map
doublyLinkedList.removeNode(lastNode);
}
Node<Integer, Integer> newNode = new Node<>(key, value);
map.put(key, newNode);
doublyLinkedList.addHead(newNode);
}
}
}

若有收获,就点个赞吧
0 人点赞
