- 第1章 Netty——异步和事件驱动
- 第3章 Netty的组件和设计
- 第4章 传输
- 第5章 ByteBuf
- 5.1 ByteBuf的API
Netty的数据处理API通过两个组件暴露——abstract class ByteBuf和interface ByteBufHolder。 下面是一些ByteBuf API的优点: 它可以被用户自定义的缓冲区类型扩展; 通过内置的复合缓冲区类型实现了透明的零拷贝; 容量可以按需增长(类似于JDK的StringBuilder); 在读和写这两种模式之间切换不需要调用ByteBuffer的flip()方法; 读和写使用了不同的索引; 支持方法的链式调用; 支持引用计数; 支持池化。 其他类可用于管理ByteBuf实例的分配,以及执行各种针对于数据容器本身和它所持有的数据的操作。我们将在仔细研究ByteBuf和ByteBufHolder时探讨这些特性。 - 5.2 ByteBuf类——Netty的数据容器
- 5.3 字节级操作
- 5.4 ByteBufHolder接口
- 5.5 ByteBuf分配
- 5.6 引用计数
- http://docs.oracle. com/javase/8/docs/api/ java/nio/ByteBuffer.html。 [3] 这尤其适用于JDK所使用的一种称为分散/收集I/O(Scatter/Gather I/O)的技术,定义为“一种输入和输出的方法,其中,单个系统调用从单个数据流写到一组缓冲区中,或者,从单个数据源读到一组缓冲区中”。《Linux System Programming》,作者Robert Love(O’Reilly, 2007)。 [4] 因为只是移动了可以读取的字节以及writerIndex,而没有对所有可写入的字节进行擦除写。——译者注 [5] 在往ByteBuf中写入数据时,其将首先确保目标ByteBuf具有足够的可写入空间来容纳当前要写入的数据,如果没有,则将检查当前的写索引以及最大容量是否可以在扩展后容纳该数据,可以则会分配并调整容量,否则就会抛出该异常。——译者注 [6] 在Netty 4.1.x中,该类已经废弃,请使用io.netty.util.ByteProcessor。——译者注 [7] 有关Flash套接字的讨论可参考Flash ActionScript 3.0 Developer’s Guide中Networking and Communication部分里的Sockets页面:http://help.adobe.com/en_US/as3/dev/WSb2ba3b1aad8a27b0-181c51321220efd9d1c-8000.html。 [8] 默认地,当所运行的环境具有sun.misc.Unsafe支持时,返回基于直接内存存储的ByteBuf,否则返回基于堆内存存储的ByteBuf;当指定使用PreferHeapByteBufAllocator时,则只会返回基于堆内存存储的ByteBuf。——译者注 [9] Jason Evans的“A Scalable Concurrent malloc(3) Implementation for FreeBSD”(2006):http://people.freebsd. org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf。 [10] 这里指Netty4.1.x,Netty4.0.x默认使用的是UnpooledByteBufAllocator。——译者注">5.7 小结
本章专门探讨了Netty的基于ByteBuf的数据容器。我们首先解释了ByteBuf相对于JDK所提供的实现的优势。我们还强调了该API的其他可用变体,并且指出了它们各自最佳适用的特定用例。 我们讨论过的要点有: 使用不同的读索引和写索引来控制数据访问; 使用内存的不同方式——基于字节数组和直接缓冲区; 通过CompositeByteBuf生成多个ByteBuf的聚合视图; 数据访问方法——搜索、切片以及复制; 读、写、获取和设置API; ByteBufAllocator池化和引用计数。 在下一章中,我们将专注于ChannelHandler,它为你的数据处理逻辑提供了载体。因为ChannelHandler大量地使用了ByteBuf,你将开始看到Netty的整体架构的各个重要部分最终走到了一起。 [1] 也就是说用户直接或者间接使capacity(int)或者ensureWritable(int)方法来增加超过该最大容量时抛出异常。——译者注 [2] Java平台,标准版第8版API规范,java.nio,class ByteBuffer:http://docs.oracle. com/javase/8/docs/api/ java/nio/ByteBuffer.html。 [3] 这尤其适用于JDK所使用的一种称为分散/收集I/O(Scatter/Gather I/O)的技术,定义为“一种输入和输出的方法,其中,单个系统调用从单个数据流写到一组缓冲区中,或者,从单个数据源读到一组缓冲区中”。《Linux System Programming》,作者Robert Love(O’Reilly, 2007)。 [4] 因为只是移动了可以读取的字节以及writerIndex,而没有对所有可写入的字节进行擦除写。——译者注 [5] 在往ByteBuf中写入数据时,其将首先确保目标ByteBuf具有足够的可写入空间来容纳当前要写入的数据,如果没有,则将检查当前的写索引以及最大容量是否可以在扩展后容纳该数据,可以则会分配并调整容量,否则就会抛出该异常。——译者注 [6] 在Netty 4.1.x中,该类已经废弃,请使用io.netty.util.ByteProcessor。——译者注 [7] 有关Flash套接字的讨论可参考Flash ActionScript 3.0 Developer’s Guide中Networking and Communication部分里的Sockets页面:http://help.adobe.com/en_US/as3/dev/WSb2ba3b1aad8a27b0-181c51321220efd9d1c-8000.html。 [8] 默认地,当所运行的环境具有sun.misc.Unsafe支持时,返回基于直接内存存储的ByteBuf,否则返回基于堆内存存储的ByteBuf;当指定使用PreferHeapByteBufAllocator时,则只会返回基于堆内存存储的ByteBuf。——译者注 [9] Jason Evans的“A Scalable Concurrent malloc(3) Implementation for FreeBSD”(2006):http://people.freebsd. org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf。 [10] 这里指Netty4.1.x,Netty4.0.x默认使用的是UnpooledByteBufAllocator。——译者注
- 5.1 ByteBuf的API
- 第6章 ChannelHandler和ChannelPipeline
- 第7章 EventLoop和线程模型
- 第8章 引导
- 8.1 Bootstrap类
- 8.2 引导客户端和无连接协议
Bootstrap类被用于客户端或者使用了无连接协议的应用程序中。表8-1提供了该类的一个概览,其中许多方法都继承自AbstractBootstrap类。 表8-1 Bootstrap类的API 名 称 描 述 Bootstrap group(EventLoopGroup) 设置用于处理 Channel所有事件的EventLoopGroup Bootstrap channel( Class<? extends C>) Bootstrap channelFactory( ChannelFactory<? extends C>) channel()方法指定了Channel的实现类。如果该实现类没提供默认的构造函数[7],可以通过调用channel- Factory()方法来指定一个工厂类,它将会被bind()方法调用 Bootstrap localAddress( SocketAddress) 指定 Channel应该绑定到的本地地址。如果没有指定,则将由操作系统创建一个随机的地址。或者,也可以通过bind()或者connect()方法指定localAddress Bootstrap option( ChannelOption option, T value) 设置 ChannelOption,其将被应用到每个新创建的Channel的ChannelConfig。这些选项将会通过bind()或者connect()方法设置到Channel,不管哪个先被调用。这个方法在Channel已经被创建后再调用将不会有任何的效果。支持的ChannelOption取决于使用的Channel类型。参见8.6节以及ChannelConfig的API文档,了解所使用的Channel类型 Bootstrap attr( Attribute key, T value) 指定新创建的 Channel的属性值。这些属性值是通过bind()或者connect()方法设置到Channel的,具体取决于谁最先被调用。这个方法在Channel被创建后将不会有任何的效果。参见8.6节 Bootstrap handler(ChannelHandler) 设置将被添加到 ChannelPipeline以接收事件通知的ChannelHandler Bootstrap clone() 创建一个当前 Bootstrap的克隆,其具有和原始的Bootstrap相同的设置信息 Bootstrap remoteAddress( SocketAddress) 设置远程地址。或者,也可以通过 connect()方法来指定它 ChannelFuture connect() 连接到远程节点并返回一个 ChannelFuture,其将会在连接操作完成后接收到通知 ChannelFuture bind() 绑定 Channel并返回一个ChannelFuture,其将会在绑定操作完成后接收到通知,在那之后必须调用Channel. connect()方法来创建连接 下一节将一步一步地讲解客户端的引导过程。我们也将讨论在选择可用的组件实现时保持兼容性的问题。 - 8.3 引导服务器
- 8.4 从Channel引导客户端
- 8.5 在引导过程中添加多个ChannelHandler
- 8.7 引导DatagramChannel
- 8.8 关闭
- 8.9 小结
- 第10章 编解码器框架
第1章 Netty——异步和事件驱动
本章主要内容
Java网络编程
Netty简介
Netty的核心组件
假设你正在为一个重要的大型公司开发一款全新的任务关键型的应用程序。在第一次会议上,你得知该系统必须要能够扩展到支撑150 000名并发用户,并且不能有任何的性能损失,这时所有的目光都投向了你。你会怎么说呢?
如果你可以自信地说:“当然,没问题。”那么大家都会向你脱帽致敬。但是,我们大多数人可能会采取一个更加谨慎的立场,例如:“听上去是可行的。”然后,一回到计算机旁,我们便开始搜索“high performance Java networking”(高性能Java网络编程)。
如果你现在搜索它,在第一页结果中,你将会看到下面的内容:
Netty: Home netty.io/
Netty是一款异步的事件驱动的网络应用程序框架,支持快速地开发可维护的高性能的面向协议的服务器和客户端。
如果你和大多数人一样,通过这样的方式发现了Netty,那么你的下一步多半是:浏览该网站,下载源代码,仔细阅读Javadoc和一些相关的博客,然后写点儿代码试试。如果你已经有了扎实的网络编程经验,那么可能进展还不错,不然则可能是一头雾水。
这是为什么呢?因为像我们例子中那样的高性能系统不仅要求超一流的编程技巧,还需要几个复杂领域(网络编程、多线程处理和并发)的专业知识。Netty优雅地处理了这些领域的知识,使得即使是网络编程新手也能使用。但到目前为止,由于还缺乏一本全面的指南,使得对它的学习过程比实际需要的艰涩得多——因此便有了这本书。
我们编写这本书的主要目的是:使得Netty能够尽可能多地被更加广泛的开发者采用。这也包括那些拥有创新的内容或者服务,却没有时间或者兴趣成为网络编程专家的人。如果这适用于你,我们相信你将会非常惊讶自己这么快便可以开始创建你的第一款基于Netty的应用程序了。当然在另一个层面上讲,我们也需要支持那些正在寻找工具来创建他们自己的网络协议的高级从业人员。
Netty确实提供了极为丰富的网络编程工具集,我们将花大部分的时间来探究它的能力。但是,Netty终究是一个框架,它的架构方法和设计原则是:每个小点都和它的技术性内容一样重要,穷其精妙。因此,我们也将探讨很多其他方面的内容,例如:
关注点分离——业务和网络逻辑解耦;
模块化和可复用性;
可测试性作为首要的要求。
在这第1章中,我们将从一些与高性能网络编程相关的背景知识开始铺陈,特别是它在Java开发工具包(JDK)中的实现。有了这些背景知识后,我们将介绍Netty,它的核心概念以及构建块。在本章结束之后,你就能够编写你的第一款基于Netty的客户端和服务器应用程序了。
1.1 Java网络编程
早期的网络编程开发人员,需要花费大量的时间去学习复杂的C语言套接字库,去处理它们在不同的操作系统上出现的古怪问题。虽然最早的Java(1995—2002)引入了足够多的面向对象façade(门面)来隐藏一些棘手的细节问题,但是创建一个复杂的客户端/服务器协议仍然需要大量的样板代码(以及相当多的底层研究才能使它整个流畅地运行起来)。
那些最早期的Java API(java.net)只支持由本地系统套接字库提供的所谓的阻塞函数。
代码清单1-1展示了一个使用了这些函数调用的服务器代码的普通示例。
代码清单1-1 阻塞I/O示例
ServerSocket serverSocket = new ServerSocket(portNumber); ← -- 创建一个新的ServerSocket,用以监听指定端口上的连接请求Socket clientSocket = serverSocket.accept(); ← -- ❶ 对accept()方法的调用将被阻塞,直到一个连接创建BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream())); PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true); ← -- ❷ 这些流对象都派生于该套接字的流对象String request, response; while ((request = in.readLine()) != null) { ← -- ❸ 处理循环开始 if ("Done".equals(request)) {break; ← -- 如果客户端发送了“Done”,则退出处理循环 }response = processRequest(request); ← — ❹ 请求被传递给服 务器的处理方法 out.println(response); ← -- 服务器的响应被发送给了客户端 } ← -- 继续执行处理循环
代码清单1-1实现了Socket API的基本模式之一。以下是最重要的几点。
ServerSocket上的accept()方法将会一直阻塞到一个连接创建❶,随后返回一个新的Socket用于客户端和服务器之间的通信。该ServerSocket将继续监听传入的连接。
BufferedReader和PrintWriter都衍生自Socket的输入输出流❷。前者从一个字符输入流中读取文本,后者打印对象的格式化的表示到文本输出流。
readLine()方法将会阻塞,直到在❸处一个由换行符或者掉头符结尾的字符串被读取。
客户端的请求已经被处理❹。
这段代码片段将只能同时处理一个连接,要管理多个并发客户端,需要为每个新的客户端Socket创建一个新的Thread,如图1-1所示。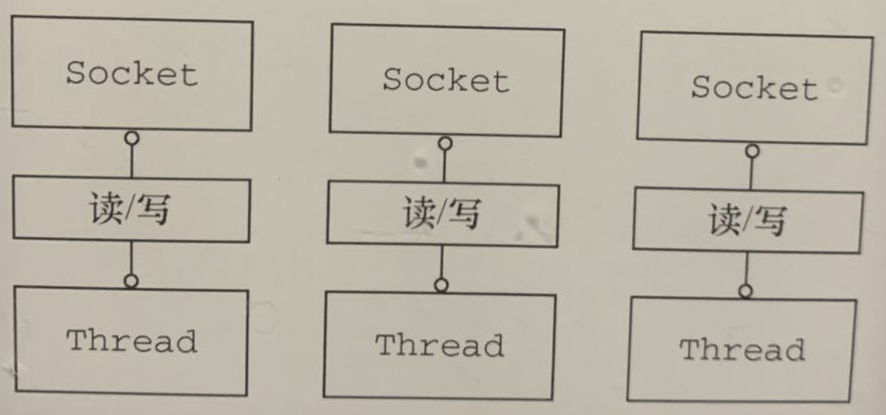
图1-1 使用阻塞I/O处理多个连接
让我们考虑一下这种方案的影响。第一,在任何时候都可能有大量的线程处于休眠状态,只是等待输入或者输出数据就绪,这可能算是一种资源浪费。第二,需要为每个线程的调用栈都分配内存,其默认值大小区间为64 KB到1 MB,具体取决于操作系统。第三,即使Java虚拟机(JVM)在物理上可以支持非常大数量的线程,但是远在到达该极限之前,上下文切换所带来的开销就会带来麻烦,例如,在达到10 000个连接的时候。
虽然这种并发方案对于支撑中小数量的客户端来说还算可以接受,但是为了支撑100 000或者更多的并发连接所需要的资源使得它很不理想。幸运的是,还有一种方案。
1.1.1 Java NIO
除了代码清单1-1中代码底层的阻塞系统调用之外,本地套接字库很早就提供了非阻塞调用,其为网络资源的利用率提供了相当多的控制:
可以使用setsockopt()方法配置套接字,以便读/写调用在没有数据的时候立即返回,也就是说,如果是一个阻塞调用应该已经被阻塞了[1];
可以使用操作系统的事件通知API[2]注册一组非阻塞套接字,以确定它们中是否有任何的套接字已经有数据可供读写。
Java对于非阻塞I/O的支持是在2002年引入的,位于JDK 1.4的java.nio包中。
新的还是非阻塞的 NIO最开始是新的输入/输出(New Input/Output)的英文缩写,但是,该Java API已经出现足够长的时间了,不再是“新的”了,因此,如今大多数的用户认为NIO代表非阻塞I/O(Non-blocking I/O),而阻塞I/O(blocking I/O)是旧的输入/输出(old input/output,OIO)。你也可能遇到它被称为普通I/O(plain I/O)的时候。
1.1.2 选择器
图1-2展示了一个非阻塞设计,其实际上消除了上一节中所描述的那些弊端。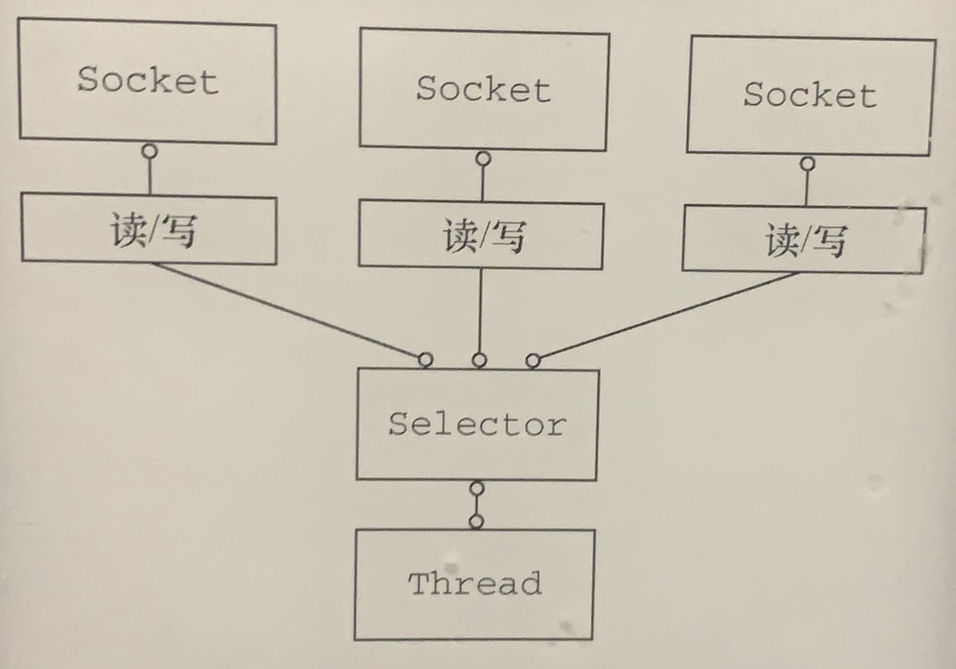
图1-2 使用Selector的非阻塞I/O
class java.nio.channels.Selector是Java的非阻塞I/O实现的关键。它使用了事件通知API以确定在一组非阻塞套接字中有哪些已经就绪能够进行I/O相关的操作。因为可以在任何的时间检查任意的读操作或者写操作的完成状态,所以如图1-2所示,一个单一的线程便可以处理多个并发的连接。
总体来看,与阻塞I/O模型相比,这种模型提供了更好的资源管理:
使用较少的线程便可以处理许多连接,因此也减少了内存管理和上下文切换所带来开销;
当没有I/O操作需要处理的时候,线程也可以被用于其他任务。
尽管已经有许多直接使用Java NIO API的应用程序被构建了,但是要做到如此正确和安全并不容易。特别是,在高负载下可靠和高效地处理和调度I/O操作是一项繁琐而且容易出错的任务,最好留给高性能的网络编程专家——Netty。
1.2 Netty简介
不久以前,我们在本章一开始所呈现的场景——支持成千上万的并发客户端——还被认定为是不可能的。然而今天,作为系统用户,我们将这种能力视为理所当然;同时作为开发人员,我们期望将水平线提得更高[3]。因为我们知道,总会有更高的吞吐量和可扩展性的要求——在更低的成本的基础上进行交付。
不要低估了这最后一点的重要性。我们已经从漫长的痛苦经历中学到:直接使用底层的API暴露了复杂性,并且引入了对往往供不应求的技能的关键性依赖[4]。这也就是,面向对象的基本概念:用较简单的抽象隐藏底层实现的复杂性。
这一原则也催生了大量框架的开发,它们为常见的编程任务封装了解决方案,其中的许多都和分布式系统的开发密切相关。我们可以确定地说:所有专业的Java开发人员都至少对它们熟知一二。[5]对于我们许多人来说,它们已经变得不可或缺,因为它们既能满足我们的技术需求,又能满足我们的时间表。
在网络编程领域,Netty是Java的卓越框架。[6]它驾驭了Java高级API的能力,并将其隐藏在一个易于使用的API之后。Netty使你可以专注于自己真正感兴趣的——你的应用程序的独一无二的价值。
在我们开始首次深入地了解Netty之前,请仔细审视表1-1中所总结的关键特性。有些是技术性的,而其他的更多的则是关于架构或设计哲学的。在本书的学习过程中,我们将不止一次地重新审视它们。
表1-1 Netty的特性总结
分 类 Netty的特性
设计
统一的API,支持多种传输类型,阻塞的和非阻塞的
简单而强大的线程模型
真正的无连接数据报套接字支持
链接逻辑组件以支持复用
易于使用
详实的Javadoc和大量的示例集
不需要超过JDK 1.6+[7]的依赖。(一些可选的特性可能需要Java 1.7+和/或额外的依赖)
性能
拥有比Java的核心API更高的吞吐量以及更低的延迟
得益于池化和复用,拥有更低的资源消耗 最少的内存复制
健壮性
不会因为慢速、快速或者超载的连接而导致 OutOfMemoryError
消除在高速网络中NIO应用程序常见的不公平读/写比率
安全性
完整的SSL/TLS以及StartTLS支持
可用于受限环境下,如Applet和OSGI
社区驱动
发布快速而且频繁
1.2.1 谁在使用Netty
Netty拥有一个充满活力并且不断壮大的用户社区,其中不乏大型公司,如Apple、Twitter、Facebook、Google、Square和Instagram,还有流行的开源项目,如Infinispan、HornetQ、Vert.x、Apache Cassandra和Elasticsearch[8],它们所有的核心代码都利用了Netty强大的网络抽象[9]。在初创企业中,Firebase和Urban Airship也在使用Netty,前者用来做HTTP长连接,而后者用来支持各种各样的推送通知。
每当你使用Twitter,你便是在使用Finagle[10],它们基于Netty的系统间通信框架。Facebook在Nifty中使用了Netty,它们的Apache Thrift服务。可伸缩性和性能对这两家公司来说至关重要,他们也经常为Netty贡献代码[11]。
反过来,Netty也已从这些项目中受益,通过实现FTP、SMTP、HTTP和WebSocket以及其他的基于二进制和基于文本的协议,Netty扩展了它的应用范围及灵活性。
1.2.2 异步和事件驱动
因为我们要大量地使用“异步”这个词,所以现在是一个澄清上下文的好时机。异步(也就是非同步)事件肯定大家都熟悉。考虑一下电子邮件:你可能会也可能不会收到你已经发出去的电子邮件对应的回复,或者你也可能会在正在发送一封电子邮件的时候收到一个意外的消息。异步事件也可以具有某种有序的关系。通常,你只有在已经问了一个问题之后才会得到一个和它对应的答案,而在你等待它的同时你也可以做点别的事情。
在日常的生活中,异步自然而然地就发生了,所以你可能没有对它考虑过多少。但是让一个计算机程序以相同的方式工作就会产生一些非常特殊的问题。本质上,一个既是异步的又是事件驱动的系统会表现出一种特殊的、对我们来说极具价值的行为:它可以以任意的顺序响应在任意的时间点产生的事件。
这种能力对于实现最高级别的可伸缩性至关重要,定义为:“一种系统、网络或者进程在需要处理的工作不断增长时,可以通过某种可行的方式或者扩大它的处理能力来适应这种增长的能力。”[12]
异步和可伸缩性之间的联系又是什么呢?
非阻塞网络调用使得我们可以不必等待一个操作的完成。完全异步的I/O正是基于这个特性构建的,并且更进一步:异步方法会立即返回,并且在它完成时,会直接或者在稍后的某个时间点通知用户。
选择器使得我们能够通过较少的线程便可监视许多连接上的事件。
将这些元素结合在一起,与使用阻塞I/O来处理大量事件相比,使用非阻塞I/O来处理更快速、更经济。从网络编程的角度来看,这是构建我们理想系统的关键,而且你会看到,这也是Netty的设计底蕴的关键。
在1.3节中,我们将首先看一看Netty的核心组件。现在,只需要将它们看作是域对象,而不是具体的Java类。随着时间的推移,我们将看到它们是如何协作,来为在网络上发生的事件提供通知,并使得它们可以被处理的。
1.3 Netty的核心组件
在本节中我将要讨论Netty的主要构件块:
Channel;
回调;
Future;
事件和ChannelHandler。
这些构建块代表了不同类型的构造:资源、逻辑以及通知。你的应用程序将使用它们来访问网络以及流经网络的数据。
对于每个组件来说,我们都将提供一个基本的定义,并且在适当的情况下,还会提供一个简单的示例代码来说明它的用法。
1.3.1 Channel
Channel是Java NIO的一个基本构造。
它代表一个到实体(如一个硬件设备、一个文件、一个网络套接字或者一个能够执行一个或者多个不同的I/O操作的程序组件)的开放连接,如读操作和写操作[13]。
目前,可以把Channel看作是传入(入站)或者传出(出站)数据的载体。因此,它可以被打开或者被关闭,连接或者断开连接。
1.3.2 回调
一个回调其实就是一个方法,一个指向已经被提供给另外一个方法的方法的引用。这使得后者[14]可以在适当的时候调用前者。回调在广泛的编程场景中都有应用,而且也是在操作完成后通知相关方最常见的方式之一。
Netty在内部使用了回调来处理事件;当一个回调被触发时,相关的事件可以被一个interface-ChannelHandler的实现处理。代码清单1-2展示了一个例子:当一个新的连接已经被创建时,ChannelHandler的channelActive()回调方法将会被调用,并将打印出一条信息。
代码清单1-2 被回调触发的ChannelHandler
public class ConnectHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception { ← — 当一个新的连接已经被创建时,
channelActive(ChannelHandlerContext)将会被调用
System.out.println( “Client “ + ctx.channel().remoteAddress() + “ connected”);
} }
1.3.3 Future
Future提供了另一种在操作完成时通知应用程序的方式。这个对象可以看作是一个异步操作的结果的占位符;它将在未来的某个时刻完成,并提供对其结果的访问。
JDK预置了interface java.util.concurrent.Future,但是其所提供的实现,只允许手动检查对应的操作是否已经完成,或者一直阻塞直到它完成。这是非常繁琐的,所以Netty提供了它自己的实现——ChannelFuture,用于在执行异步操作的时候使用。
ChannelFuture提供了几种额外的方法,这些方法使得我们能够注册一个或者多个ChannelFutureListener实例。监听器的回调方法operationComplete(),将会在对应的操作完成时被调用[15]。然后监听器可以判断该操作是成功地完成了还是出错了。如果是后者,我们可以检索产生的Throwable。简而言之,由ChannelFutureListener提供的通知机制消除了手动检查对应的操作是否完成的必要。
每个Netty的出站I/O操作都将返回一个ChannelFuture;也就是说,它们都不会阻塞。正如我们前面所提到过的一样,Netty完全是异步和事件驱动的。
代码清单1-3展示了一个ChannelFuture作为一个I/O操作的一部分返回的例子。这里,connect()方法将会直接返回,而不会阻塞,该调用将会在后台完成。这究竟什么时候会发生则取决于若干的因素,但这个关注点已经从代码中抽象出来了。因为线程不用阻塞以等待对应的操作完成,所以它可以同时做其他的工作,从而更加有效地利用资源。
代码清单1-3 异步地创建连接
Channel channel = …;
// Does not block ChannelFuture future = channel.connect( ← — 异步地连接到远程节点
new InetSocketAddress(“192.168.0.1”, 25));
代码清单1-4显示了如何利用ChannelFutureListener。首先,要连接到远程节点上。然后,要注册一个新的ChannelFutureListener到对connect()方法的调用所返回的ChannelFuture上。当该监听器被通知连接已经创建的时候,要检查对应的状态❶。如果该操作是成功的,那么将数据写到该Channel。否则,要从ChannelFuture中检索对应的Throwable。
代码清单1-4 回调实战
Channel channel = ...;// Does not blockChannelFuture future = channel.connect( ← -- 异步地连接到远程节点new InetSocketAddress("192.168.0.1", 25)); future.addListener(new ChannelFutureListener() { ← -- 注册一个ChannelFutureListener,以便在操作完成时获得通知@Overridepublic void operationComplete(ChannelFuture future) { ← -- ❶ 检查操作 的状态if (future.isSuccess()){ ByteBuf buffer = Unpooled.copiedBuffer( ← -- 如果操作是成功的,则创建一个ByteBuf以持有数据 "Hello",Charset.defaultCharset()); ChannelFuture wf = future.channel() .writeAndFlush(buffer); ← -- 将数据异步地发送到远程节点。 返回一个ChannelFuture ....} else {Throwable cause = future.cause(); ← -- 如果发生错误,则访问描述原因的Throwable cause.printStackTrace();}} });
需要注意的是,对错误的处理完全取决于你、目标,当然也包括目前任何对于特定类型的错误加以的限制。例如,如果连接失败,你可以尝试重新连接或者创建一个到另一个远程节点的连接。
如果你把ChannelFutureListener看作是回调的一个更加精细的版本,那么你是对的。事实上,回调和Future是相互补充的机制;它们相互结合,构成了Netty本身的关键构件块之一。
1.3.4 事件和ChannelHandler
Netty使用不同的事件来通知我们状态的改变或者是操作的状态。这使得我们能够基于已经发生的事件来触发适当的动作。这些动作可能是:
记录日志;
数据转换;
流控制;
应用程序逻辑。
Netty是一个网络编程框架,所以事件是按照它们与入站或出站数据流的相关性进行分类的。可能由入站数据或者相关的状态更改而触发的事件包括:
连接已被激活或者连接失活;
数据读取;
用户事件;
错误事件。
出站事件是未来将会触发的某个动作的操作结果,这些动作包括:
打开或者关闭到远程节点的连接;
将数据写到或者冲刷到套接字。
每个事件都可以被分发给ChannelHandler类中的某个用户实现的方法。这是一个很好的将事件驱动范式直接转换为应用程序构件块的例子。图1-3展示了一个事件是如何被一个这样的ChannelHandler链处理的。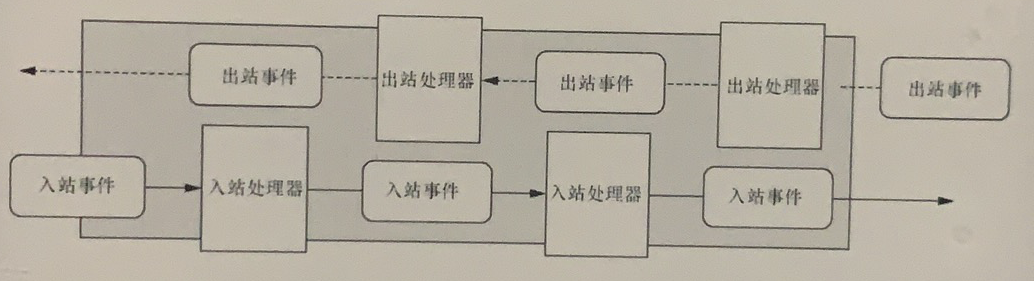
图1-3 流经ChannelHandler链的入站事件和出站事件
Netty的ChannelHandler为处理器提供了基本的抽象,如图1-3所示的那些。我们会在适当的时候对ChannelHandler进行更多的说明,但是目前你可以认为每个Channel-Handler的实例都类似于一种为了响应特定事件而被执行的回调。
Netty提供了大量预定义的可以开箱即用的ChannelHandler实现,包括用于各种协议(如HTTP和SSL/TLS)的ChannelHandler。在内部,ChannelHandler自己也使用了事件和Future,使得它们也成为了你的应用程序将使用的相同抽象的消费者。
1.3.5 把它们放在一起
在本章中,我们介绍了Netty实现高性能网络编程的方式,以及它的实现中的一些主要的组件。让我们大体回顾一下我们讨论过的内容吧。
1.Future、回调和ChannelHandler
Netty的异步编程模型是创建在Future和回调的概念之上的, 而将事件派发到ChannelHandler的方法则发生在更深的层次上。结合在一起,这些元素就提供了一个处理环境,使你的应用程序逻辑可以独立于任何网络操作相关的顾虑而独立地演变。这也是Netty的设计方式的一个关键目标。
拦截操作以及高速地转换入站数据和出站数据,都只需要你提供回调或者利用操作所返回的Future。这使得链接操作变得既简单又高效,并且促进了可重用的通用代码的编写。
2.选择器、事件和EventLoop
Netty通过触发事件将Selector从应用程序中抽象出来,消除了所有本来将需要手动编写的派发代码。在内部,将会为每个Channel分配一个EventLoop,用以处理所有事件,包括:
注册感兴趣的事件;
将事件派发给ChannelHandler;
安排进一步的动作。
EventLoop本身只由一个线程驱动,其处理了一个Channel的所有I/O事件,并且在该EventLoop的整个生命周期内都不会改变。这个简单而强大的设计消除了你可能有的在ChannelHandler实现中需要进行同步的任何顾虑,因此,你可以专注于提供正确的逻辑,用来在有感兴趣的数据要处理的时候执行。如同我们在详细探讨Netty的线程模型时将会看到的,该API是简单而紧凑的。
1.4 小结
在这一章中,我们介绍了Netty框架的背景知识,包括Java网络编程API的演变过程,阻塞和非阻塞网络操作之间的区别,以及异步I/O在高容量、高性能的网络编程中的优势。
然后,我们概述了Netty的特性、设计和优点,其中包括Netty异步模型的底层机制,包括回调、Future以及它们的结合使用。我们还谈到了事件是如何产生的以及如何拦截和处理它们。
在本书接下来的部分,我们将更加深入地探讨如何利用这些丰富的工具集来满足自己的应用程序的特定需求。
在下一章中,我们将要深入地探讨Netty的API以及编程模型的基础知识,而你则将编写你的第一款客户端和服务器应用程序。 [1] W. Richard Stevens的
第3章 Netty的组件和设计
本章主要内容
Netty的技术和体系结构方面的内容
Channel、EventLoop和ChannelFuture
ChannelHandler和ChannelPipeline
引导
在第1章中,我们给出了Java高性能网络编程的历史以及技术基础的小结。这为Netty的核心概念和构件块的概述提供了背景。
在第2章中,我们把我们的讨论范围扩大到了应用程序的开发。通过构建一个简单的客户端和服务器,你学习了引导,并且获得了最重要的ChannelHandler API的实战经验。与此同时,你也验证了自己的开发工具都能正常运行。
由于本书剩下的部分都创建在这份材料的基础之上,所以我们将从两个不同的但却又密切相关的视角来探讨Netty:类库的视角以及框架的视角。对于使用Netty编写高效的、可重用的和可维护的代码来说,两者缺一不可。
从高层次的角度来看,Netty解决了两个相应的关注领域,我们可将其大致标记为技术的和体系结构的。首先,它的基于Java NIO的异步的和事件驱动的实现,保证了高负载下应用程序性能的最大化和可伸缩性。其次,Netty也包含了一组设计模式,将应用程序逻辑从网络层解耦,简化了开发过程,同时也最大限度地提高了可测试性、模块化以及代码的可重用性。
在我们更加详细地研究Netty的各个组件时,我们将密切关注它们是如何通过协作来支撑这些体系结构上的最佳实践的。通过遵循同样的原则,我们便可获得Netty所提供的所有益处。牢记这个目标,在本章中,我们将回顾到目前为止我们介绍过的主要概念和组件。
3.1 Channel、EventLoop和ChannelFuture
接下来的各节将会为我们对于Channel、EventLoop和ChannelFuture类进行的讨论增添更多的细节,这些类合在一起,可以被认为是Netty网络抽象的代表:
Channel——Socket;
EventLoop——控制流、多线程处理、并发;
ChannelFuture——异步通知。
3.1.1 Channel接口
基本的I/O操作(bind()、connect()、read()和write())依赖于底层网络传输所提供的原语。在基于Java的网络编程中,其基本的构造是class Socket。Netty的Channel接口所提供的API,大大地降低了直接使用Socket类的复杂性。此外,Channel也是拥有许多预定义的、专门化实现的广泛类层次结构的根,下面是一个简短的部分清单:
EmbeddedChannel;
LocalServerChannel;
NioDatagramChannel;
NioSctpChannel;
NioSocketChannel。
3.1.2 EventLoop接口
EventLoop定义了Netty的核心抽象,用于处理连接的生命周期中所发生的事件。我们将在第7章中结合Netty的线程处理模型的上下文对EventLoop进行详细的讨论。目前,图3-1在高层次上说明了Channel、EventLoop、Thread以及EventLoopGroup之间的关系。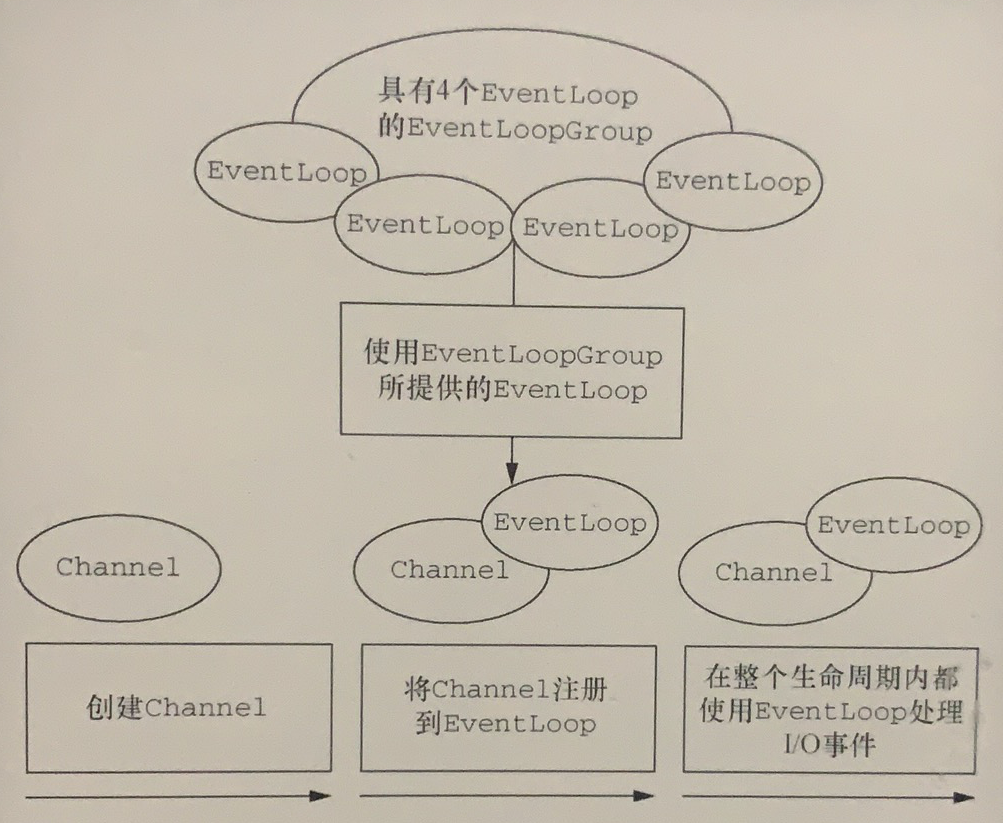
图3-1 Channel、EventLoop和EventLoopGroup
这些关系是:
一个EventLoopGroup包含一个或者多个EventLoop;
一个EventLoop在它的生命周期内只和一个Thread绑定;
所有由EventLoop处理的I/O事件都将在它专有的Thread上被处理;
一个Channel在它的生命周期内只注册于一个EventLoop;
一个EventLoop可能会被分配给一个或多个Channel。
注意,在这种设计中,一个给定Channel的I/O操作都是由相同的Thread执行的,实际上消除了对于同步的需要。
3.1.3 ChannelFuture接口
正如我们已经解释过的那样,Netty中所有的I/O操作都是异步的。因为一个操作可能不会立即返回,所以我们需要一种用于在之后的某个时间点确定其结果的方法。为此,Netty提供了ChannelFuture接口,其addListener()方法注册了一个ChannelFutureListener,以便在某个操作完成时(无论是否成功)得到通知。
关于ChannelFuture的更多讨论 可以将ChannelFuture看作是将来要执行的操作的结果的占位符。它究竟什么时候被执行则可能取决于若干的因素,因此不可能准确地预测,但是可以肯定的是它将会被执行。此外,所有属于同一个Channel的操作都被保证其将以它们被调用的顺序被执行。
我们将在第7章中深入地讨论EventLoop和EventLoopGroup。
3.2 ChannelHandler和ChannelPipeline
现在,我们将更加细致地看一看那些管理数据流以及执行应用程序处理逻辑的组件。
3.2.1 ChannelHandler接口
从应用程序开发人员的角度来看,Netty的主要组件是ChannelHandler,它充当了所有处理入站和出站数据的应用程序逻辑的容器。这是可行的,因为ChannelHandler的方法是由网络事件(其中术语“事件”的使用非常广泛)触发的。事实上,ChannelHandler可专门用于几乎任何类型的动作,例如将数据从一种格式转换为另外一种格式,或者处理转换过程中所抛出的异常。
举例来说,ChannelInboundHandler是一个你将会经常实现的子接口。这种类型的ChannelHandler接收入站事件和数据,这些数据随后将会被你的应用程序的业务逻辑所处理。当你要给连接的客户端发送响应时,也可以从ChannelInboundHandler冲刷数据。你的应用程序的业务逻辑通常驻留在一个或者多个ChannelInboundHandler中。
3.2.2 ChannelPipeline接口
ChannelPipeline为ChannelHandler链提供了容器,并定义了用于在该链上传播入站和出站事件流的API。当Channel被创建时,它会被自动地分配到它专属的ChannelPipeline。
ChannelHandler安装到ChannelPipeline中的过程如下所示:
一个ChannelInitializer的实现被注册到了ServerBootstrap中[1];
当ChannelInitializer.initChannel()方法被调用时,ChannelInitializer将在ChannelPipeline中安装一组自定义的ChannelHandler;
ChannelInitializer将它自己从ChannelPipeline中移除。
为了审查发送或者接收数据时将会发生什么,让我们来更加深入地研究ChannelPipeline和ChannelHandler之间的共生关系吧。
ChannelHandler是专为支持广泛的用途而设计的,可以将它看作是处理往来Channel- Pipeline事件(包括数据)的任何代码的通用容器。图3-2说明了这一点,其展示了从Channel- Handler派生的ChannelInboundHandler和ChannelOutboundHandler接口。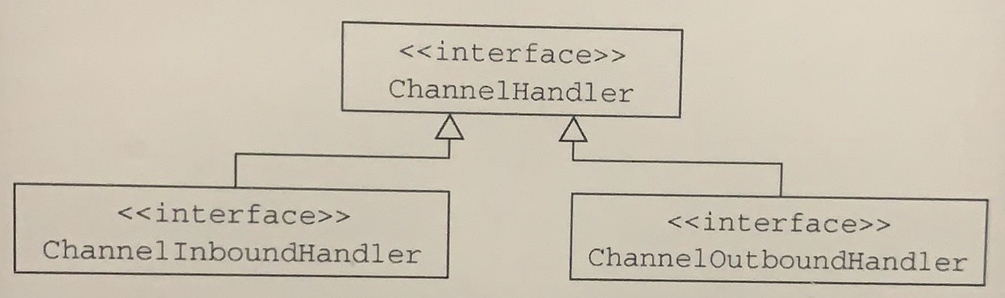
图3-2 ChannelHandler类的层次结构
使得事件流经ChannelPipeline是ChannelHandler的工作,它们是在应用程序的初始化或者引导阶段被安装的。这些对象接收事件、执行它们所实现的处理逻辑,并将数据传递给链中的下一个ChannelHandler。它们的执行顺序是由它们被添加的顺序所决定的。实际上,被我们称为ChannelPipeline的是这些ChannelHandler的编排顺序。
图3-3说明了一个Netty应用程序中入站和出站数据流之间的区别。从一个客户端应用程序的角度来看,如果事件的运动方向是从客户端到服务器端,那么我们称这些事件为出站的,反之则称为入站的。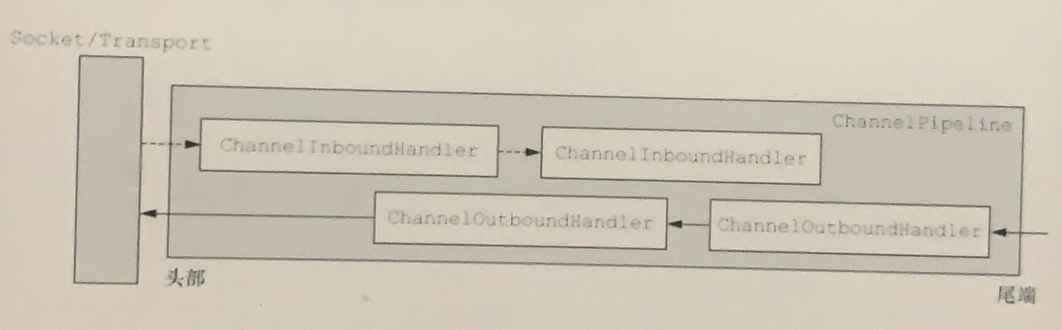
图3-3 包含入站和出站ChannelHandler的ChannelPipeline
图3-3也显示了入站和出站ChannelHandler可以被安装到同一个ChannelPipeline中。如果一个消息或者任何其他的入站事件被读取,那么它会从ChannelPipeline的头部开始流动,并被传递给第一个ChannelInboundHandler。这个ChannelHandler不一定会实际地修改数据,具体取决于它的具体功能,在这之后,数据将会被传递给链中的下一个ChannelInboundHandler。最终,数据将会到达ChannelPipeline的尾端,届时,所有处理就都结束了。
数据的出站运动(即正在被写的数据)在概念上也是一样的。在这种情况下,数据将从ChannelOutboundHandler链的尾端开始流动,直到它到达链的头部为止。在这之后,出站数据将会到达网络传输层,这里显示为Socket。通常情况下,这将触发一个写操作。 关于入站和出站ChannelHandler的更多讨论
通过使用作为参数传递到每个方法的ChannelHandlerContext,事件可以被传递给当前ChannelHandler链中的下一个ChannelHandler。因为你有时会忽略那些不感兴趣的事件,所以Netty提供了抽象基类ChannelInboundHandlerAdapter和ChannelOutboundHandlerAdapter。通过调用ChannelHandlerContext上的对应方法,每个都提供了简单地将事件传递给下一个ChannelHandler的方法的实现。随后,你可以通过重写你所感兴趣的那些方法来扩展这些类。
鉴于出站操作和入站操作是不同的,你可能会想知道如果将两个类别的ChannelHandler都混合添加到同一个ChannelPipeline中会发生什么。虽然ChannelInboundHandle和ChannelOutboundHandle都扩展自ChannelHandler,但是Netty能区分ChannelIn-boundHandler实现和ChannelOutboundHandler实现,并确保数据只会在具有相同定向类型的两个ChannelHandler之间传递。
当ChannelHandler被添加到ChannelPipeline时,它将会被分配一个ChannelHandler-Context,其代表了ChannelHandler和ChannelPipeline之间的绑定。虽然这个对象可以被用于获取底层的Channel,但是它主要还是被用于写出站数据。 在Netty中,有两种发送消息的方式。你可以直接写到Channel中,也可以写到和Channel-Handler相关联的ChannelHandlerContext对象中。前一种方式将会导致消息从Channel-Pipeline的尾端开始流动,而后者将导致消息从ChannelPipeline中的下一个Channel- Handler开始流动。
3.2.3 更加深入地了解ChannelHandler
正如我们之前所说的,有许多不同类型的ChannelHandler,它们各自的功能主要取决于它们的超类。Netty以适配器类的形式提供了大量默认的ChannelHandler实现,其旨在简化应用程序处理逻辑的开发过程。你已经看到了,ChannelPipeline中的每个ChannelHandler将负责把事件转发到链中的下一个ChannelHandler。这些适配器类(及它们的子类)将自动执行这个操作,所以你可以只重写那些你想要特殊处理的方法和事件。 为什么需要适配器类 有一些适配器类可以将编写自定义的ChannelHandler所需要的努力降到最低限度,因为它们提供了定义在对应接口中的所有方法的默认实现。 下面这些是编写自定义ChannelHandler时经常会用到的适配器类:
ChannelHandlerAdapter
ChannelInboundHandlerAdapter
ChannelOutboundHandlerAdapter
ChannelDuplexHandler
接下来我们将研究3个ChannelHandler的子类型:编码器、解码器和SimpleChannel-InboundHandler —— ChannelInboundHandlerAdapter的一个子类。
3.2.4 编码器和解码器
当你通过Netty发送或者接收一个消息的时候,就将会发生一次数据转换。入站消息会被解码;也就是说,从字节转换为另一种格式,通常是一个Java对象。如果是出站消息,则会发生相反方向的转换:它将从它的当前格式被编码为字节。这两种方向的转换的原因很简单:网络数据总是一系列的字节。
对应于特定的需要,Netty为编码器和解码器提供了不同类型的抽象类。例如,你的应用程序可能使用了一种中间格式,而不需要立即将消息转换成字节。你将仍然需要一个编码器,但是它将派生自一个不同的超类。为了确定合适的编码器类型,你可以应用一个简单的命名约定。
通常来说,这些基类的名称将类似于ByteToMessageDecoder或MessageToByte-Encoder。对于特殊的类型,你可能会发现类似于ProtobufEncoder和ProtobufDecoder这样的名称——预置的用来支持Google的Protocol Buffers。
严格地说,其他的处理器也可以完成编码器和解码器的功能。但是,正如有用来简化ChannelHandler的创建的适配器类一样,所有由Netty提供的编码器/解码器适配器类都实现了ChannelOutboundHandler或者ChannelInboundHandler接口。
你将会发现对于入站数据来说,channelRead方法/事件已经被重写了。对于每个从入站Channel读取的消息,这个方法都将会被调用。随后,它将调用由预置解码器所提供的decode()方法,并将已解码的字节转发给ChannelPipeline中的下一个ChannelInboundHandler。 出站消息的模式是相反方向的:编码器将消息转换为字节,并将它们转发给下一个ChannelOutboundHandler。
3.2.5 抽象类SimpleChannelInboundHandler
最常见的情况是,你的应用程序会利用一个ChannelHandler来接收解码消息,并对该数据应用业务逻辑。要创建一个这样的ChannelHandler,你只需要扩展基类SimpleChannel-InboundHandler,其中T是你要处理的消息的Java类型。在这个ChannelHandler中,你将需要重写基类的一个或者多个方法,并且获取一个到ChannelHandlerContext的引用,这个引用将作为输入参数传递给ChannelHandler的所有方法。
在这种类型的ChannelHandler中,最重要的方法是channelRead0(Channel-HandlerContext,T)。除了要求不要阻塞当前的I/O线程之外,其具体实现完全取决于你。我们稍后将对这一主题进行更多的说明。
3.3 引导
Netty的引导类为应用程序的网络层配置提供了容器,这涉及将一个进程绑定到某个指定的端口,或者将一个进程连接到另一个运行在某个指定主机的指定端口上的进程。
通常来说,我们把前面的用例称作引导一个服务器,后面的用例称作引导一个客户端。虽然这个术语简单方便,但是它略微掩盖了一个重要的事实,即“服务器”和“客户端”实际上表示了不同的网络行为;换句话说,是监听传入的连接还是创建到一个或者多个进程的连接。
面向连接的协议 请记住,严格来说,“连接”这个术语仅适用于面向连接的协议,如TCP,其保证了两个连接端点之间消息的有序传递。
因此,有两种类型的引导:一种用于客户端(简单地称为Bootstrap),而另一种(ServerBootstrap)用于服务器。无论你的应用程序使用哪种协议或者处理哪种类型的数据,唯一决定它使用哪种引导类的是它是作为一个客户端还是作为一个服务器。表3-1比较了这两种类型的引导类。
表3-1 比较Bootstrap类
类 别 Bootstrap ServerBootstrap
网络编程中的作用 连接到远程主机和端口 绑定到一个本地端口
EventLoopGroup的数目 1 2 [2]
这两种类型的引导类之间的第一个区别已经讨论过了:ServerBootstrap将绑定到一个端口,因为服务器必须要监听连接,而Bootstrap则是由想要连接到远程节点的客户端应用程序所使用的。
第二个区别可能更加明显。引导一个客户端只需要一个EventLoopGroup,但是一个ServerBootstrap则需要两个(也可以是同一个实例)。为什么呢?
因为服务器需要两组不同的Channel。第一组将只包含一个ServerChannel,代表服务器自身的已绑定到某个本地端口的正在监听的套接字。而第二组将包含所有已创建的用来处理传入客户端连接(对于每个服务器已经接受的连接都有一个)的Channel。图3-4说明了这个模型,并且展示了为何需要两个不同的EventLoopGroup。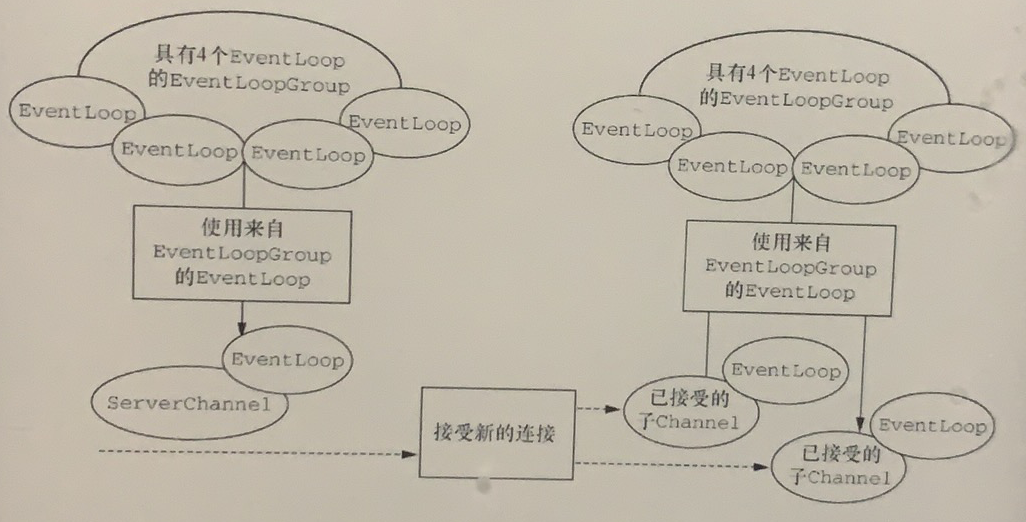
图3-4 具有两个EventLoopGroup的服务器
与ServerChannel相关联的EventLoopGroup将分配一个负责为传入连接请求创建Channel的EventLoop。一旦连接被接受,第二个EventLoopGroup就会给它的Channel分配一个EventLoop。
3.4 小结
在本章中,我们从技术和体系结构这两个角度探讨了理解Netty的重要性。我们也更加详细地重新审视了之前引入的一些概念和组件,特别是ChannelHandler、ChannelPipeline和引导。
特别地,我们讨论了ChannelHandler类的层次结构,并介绍了编码器和解码器,描述了它们在数据和网络字节格式之间来掉头换的互补功能。
下面的许多章节都将致力于深入研究这些组件,而这里所呈现的概览应该有助于你对整体的把控。
下一章将探索Netty所提供的不同类型的传输,以及如何选择一个最适合于你的应用程序的传输。
第4章 传输
[TOC]
本章主要内容 OIO——阻塞传输 NIO——异步传输 Local——JVM内部的异步通信 Embedded——测试你的ChannelHandler 流经网络的数据总是具有相同的类型:字节。这些字节是如何流动的主要取决于我们所说的网络传输——一个帮助我们抽象底层数据传输机制的概念。用户并不关心这些细节;他们只想确保他们的字节被可靠地发送和接收。 如果你有Java网络编程的经验,那么你可能已经发现,在某些时候,你需要支撑比预期多很多的并发连接。如果你随后尝试从阻塞传输切换到非阻塞传输,那么你可能会因为这两种网络API的截然不同而遇到问题。 然而,Netty为它所有的传输实现提供了一个通用API,这使得这种转换比你直接使用JDK所能够达到的简单得多。所产生的代码不会被实现的细节所污染,而你也不需要在你的整个代码库上进行广泛的重构。简而言之,你可以将时间花在其他更有成效的事情上。 在本章中,我们将学习这个通用API,并通过和JDK的对比来证明它极其简单易用。我们将阐述Netty自带的不同传输实现,以及它们各自适用的场景。有了这些信息,你会发现选择最适合于你的应用程序的选项将是直截了当的。 本章的唯一前提是Java编程语言的相关知识。有网络框架或者网络编程相关的经验更好,但不是必需的。 我们先来看一看传输在现实世界中是如何工作的。
4.1 案例研究:传输迁移
我们将从一个应用程序开始我们对传输的学习,这个应用程序只简单地接受连接,向客户端写“Hi!”,然后关闭连接。
4.1.1 不通过Netty使用OIO和NIO
我们将介绍仅使用了JDK API的应用程序的阻塞(OIO)版本和异步(NIO)版本。代码清单4-1展示了其阻塞版本的实现。如果你曾享受过使用JDK进行网络编程的乐趣,那么这段代码将唤起你美好的回忆。 代码清单4-1 未使用Netty的阻塞网络编程
public class PlainOioServer { public void serve(int port) throws IOException { final ServerSocket socket = new ServerSocket(port); ← -- 将服务器绑定到指定端口 try { for (;;) { final Socket clientSocket = socket.accept(); ← -- 接受连接 System.out.println( "Accepted connection from " + clientSocket); new Thread(new Runnable() { ← -- 创建一个新的线程来处理该连接 @Override public void run() { OutputStream out; try { out = clientSocket.getOutputStream(); out.write("Hi!\r\n".getBytes( ← -- 将消息写给已连接的客户端 Charset.forName("UTF-8"))); out.flush(); clientSocket.close(); ← -- 关闭连接 } catch (IOException e) { e.printStackTrace(); } finally { try { clientSocket.close(); } catch (IOException ex) { // ignore on close } } } }).start(); ← -- 启动线程 } } catch (IOException e) { e.printStackTrace(); } } }
这段代码完全可以处理中等数量的并发客户端。但是随着应用程序变得流行起来,你会发现它并不能很好地伸缩到支撑成千上万的并发连入连接。你决定改用异步网络编程,但是很快就发现异步API是完全不同的,以至于现在你不得不重写你的应用程序。 其非阻塞版本如代码清单4-2所示。 代码清单4-2 未使用Netty的异步网络编程
public class PlainNioServer { public void serve(int port) throws IOException { ServerSocketChannel serverChannel = ServerSocketChannel.open(); serverChannel.configureBlocking(false); ServerSocket ssocket = serverChannel.socket(); InetSocketAddress address = new InetSocketAddress(port); ssocket.bind(address); ← -- 将服务器绑定到选定的端口 Selector selector = Selector.open(); ← -- 打开Selector来处理Channel serverChannel.register(selector, SelectionKey.OP_ACCEPT); ← -- 将ServerSocket注册到Selector 以接受连接 final ByteBuffer msg = ByteBuffer.wrap("Hi!\r\n".getBytes()); for (;;) { try { selector.select(); ← -- 等待需要处理的新事件;阻塞将一直持续到下一个传入事件 } catch (IOException ex) { ex.printStackTrace(); // handle exception break; } Set<SelectionKey> readyKeys = selector.selectedKeys(); ← -- 获取所有接收事件的Selection-Key 实例 Iterator<SelectionKey> iterator = readyKeys.iterator(); while (iterator.hasNext()) { SelectionKey key = iterator.next(); iterator.remove(); try { if (key.isAcceptable()) { ← -- 检查事件是否是一个新的已经就绪可以被接受的连接 ServerSocketChannel server = (ServerSocketChannel)key.channel(); SocketChannel client = server.accept(); client.configureBlocking(false); client.register(selector, SelectionKey.OP_WRITE | ← -- 接受客户端,并将它注册到选择器 SelectionKey.OP_READ, msg.duplicate()); System.out.println( "Accepted connection from " + client); } if (key.isWritable()) { ← -- 检查套接字是否已经准备好写数据 SocketChannel client = (SocketChannel)key.channel(); ByteBuffer buffer = (ByteBuffer)key.attachment(); while (buffer.hasRemaining()) { if (client.write(buffer) == 0) { ← -- 将数据写到已连接的客户端 break; } } client.close(); ← -- 关闭连接 } } catch (IOException ex) { key.cancel(); try { key.channel().close(); } catch (IOException cex) { // ignore on close } } } } } }
如同你所看到的,虽然这段代码所做的事情与之前的版本完全相同,但是代码却截然不同。如果为了用于非阻塞I/O而重新实现这个简单的应用程序,都需要一次完全的重写的话,那么不难想象,移植真正复杂的应用程序需要付出什么样的努力。 鉴于此,让我们来看看使用Netty实现该应用程序将会是什么样子吧。
4.1.2 通过Netty使用OIO和NIO
我们将先编写这个应用程序的另一个阻塞版本,这次我们将使用Netty框架,如代码清单4-3所示。 代码清单4-3 使用Netty的阻塞网络处理
public class NettyOioServer { public void server(int port) throws Exception { final ByteBuf buf = Unpooled.unreleasableBuffer( Unpooled.copiedBuffer("Hi!\r\n", Charset.forName("UTF-8"))); EventLoopGroup group = new OioEventLoopGroup(); try { ServerBootstrap b = new ServerBootstrap(); ← -- 创建Server-Bootstrap b.group(group) .channel(OioServerSocketChannel.class) ← -- 使用OioEventLoopGroup以允许阻塞模式(旧的I/O) .localAddress(new InetSocketAddress(port)) .childHandler(new ChannelInitializer<SocketChannel>() { ← -- 指定Channel-Initializer,对于每个已接受的连接都调用它 @Override public void initChannel(SocketChannel ch) throws Exception { ch.pipeline().addLast( new ChannelInboundHandlerAdapter() { ← -- 添加一个Channel-InboundHandler-Adapter 以拦截和处理事件 @Override public void channelActive( ChannelHandlerContext ctx) throws Exception { ctx.writeAndFlush(buf.duplicate()) .addListener( ChannelFutureListener.CLOSE); ← -- 将消息写到客户端,并添加ChannelFutureListener,以便消息一被写完就关闭连接 } }); } }); ChannelFuture f = b.bind().sync(); ← -- 绑定服务器以接受连接 f.channel().closeFuture().sync(); } finally { group.shutdownGracefully().sync(); ← -- 释放所有的资源 } } }
接下来,我们使用Netty和非阻塞I/O来实现同样的逻辑。
4.1.3 非阻塞的Netty版本
代码清单4-4和代码清单4-3几乎一模一样,除了高亮显示的那两行。这就是从阻塞(OIO)传输切换到非阻塞(NIO)传输需要做的所有变更。 代码清单4-4 使用Netty的异步网络处理
public class NettyNioServer { public void server(int port) throws Exception { final ByteBuf buf = Unpooled.copiedBuffer("Hi!\r\n", Charset.forName("UTF-8")); EventLoopGroup group = new NioEventLoopGroup(); ← -- 为非阻塞模式使用NioEventLoopGroup try { ServerBootstrap b = new ServerBootstrap(); ← -- 创建ServerBootstrap b.group(group).channel(NioServerSocketChannel.class) .localAddress(new InetSocketAddress(port)) .childHandler(new ChannelInitializer() { ← -- 指定Channel-Initializer,对于每个已接受的连接都调用它 @Override public void initChannel(SocketChannel ch) throws Exception{ ch.pipeline().addLast( new ChannelInboundHandlerAdapter() { ← -- 添加ChannelInbound-HandlerAdapter 以接收和处理事件 @Override public void channelActive( ChannelHandlerContext ctx) throws Exception { ← -- 将消息写到客户端,并添加ChannelFutureListener,以便消息一被写完就关闭连接 ctx.writeAndFlush(buf.duplicate()) .addListener( ChannelFutureListener.CLOSE); } }); } }); ChannelFuture f = b.bind().sync(); ← -- 绑定服务器以接受连接 f.channel().closeFuture().sync(); } finally { group.shutdownGracefully().sync(); ← -- 释放所有的资源 } } }
因为Netty为每种传输的实现都暴露了相同的API,所以无论选用哪一种传输的实现,你的代码都仍然几乎不受影响。在所有的情况下,传输的实现都依赖于interface Channel、ChannelPipeline和ChannelHandler。 在看过一些使用基于Netty的传输的这些优点之后,让我们仔细看看传输API本身。
4.2 传输API
传输API的核心是interfaceChannel,它被用于所有的I/O操作。Channel类的层次结构如图4-1所示。 图4-1 Channel接口的层次结构 如图所示,每个Channel都将会被分配一个ChannelPipeline和ChannelConfig。ChannelConfig包含了该Channel的所有配置设置,并且支持热更新。由于特定的传输可能具有独特的设置,所以它可能会实现一个ChannelConfig的子类型。(请参考ChannelConfig实现对应的Javadoc。) 由于Channel是独一无二的,所以为了保证顺序将Channel声明为java.lang.Comparable的一个子接口。因此,如果两个不同的Channel实例都返回了相同的散列码,那么AbstractChannel中的compareTo()方法的实现将会抛出一个Error。 ChannelPipeline持有所有将应用于入站和出站数据以及事件的ChannelHandler实例,这些ChannelHandler实现了应用程序用于处理状态变化以及数据处理的逻辑。 ChannelHandler的典型用途包括: 将数据从一种格式转换为另一种格式; 提供异常的通知; 提供Channel变为活动的或者非活动的通知; 提供当Channel注册到EventLoop或者从EventLoop注销时的通知; 提供有关用户自定义事件的通知。 拦截过滤器 ChannelPipeline实现了一种常见的设计模式——拦截过滤器(Intercepting Filter)。UNIX管道是另外一个熟悉的例子:多个命令被链接在一起,其中一个命令的输出端将连接到命令行中下一个命令的输入端。 你也可以根据需要通过添加或者移除ChannelHandler实例来修改ChannelPipeline。通过利用Netty的这项能力可以构建出高度灵活的应用程序。例如,每当STARTTLS[1]协议被请求时,你可以简单地通过向ChannelPipeline添加一个适当的ChannelHandler(SslHandler)来按需地支持STARTTLS协议。 除了访问所分配的ChannelPipeline和ChannelConfig之外,也可以利用Channel的其他方法,其中最重要的列举在表4-1中。 表4-1 Channel的方法 方 法 名 描 述 eventLoop 返回分配给 Channel的EventLoop pipeline 返回分配给 Channel的ChannelPipeline isActive 如果 Channel是活动的,则返回true。活动的意义可能依赖于底层的传输。例如,一个Socket传输一旦连接到了远程节点便是活动的,而一个Datagram传输一旦被打开便是活动的 localAddress 返回本地的 SokcetAddress remoteAddress 返回远程的 SocketAddress write 将数据写到远程节点。这个数据将被传递给 ChannelPipeline,并且排队直到它被冲刷 flush 将之前已写的数据冲刷到底层传输,如一个 Socket writeAndFlush 一个简便的方法,等同于调用 write()并接着调用flush() 稍后我们将进一步深入地讨论所有这些特性的应用。目前,请记住,Netty所提供的广泛功能只依赖于少量的接口。这意味着,你可以对你的应用程序逻辑进行重大的修改,而又无需大规模地重构你的代码库。 考虑一下写数据并将其冲刷到远程节点这样的常规任务。代码清单4-5演示了使用Channel.writeAndFlush()来实现这一目的。 代码清单4-5 写出到Channel Channel channel = … ByteBuf buf = Unpooled.copiedBuffer(“your data”, CharsetUtil.UTF_8); ← — 创建持有要写数据的ByteBuf ChannelFuture cf = channel.writeAndFlush(buf); ← — 写数据并冲刷它 cf.addListener(new ChannelFutureListener() { ← — 添加ChannelFutureListener 以便在写操作完成后接收通知 @Override public void operationComplete(ChannelFuture future) { if (future.isSuccess()) { ← — 写操作完成,并且没有错误发生 System.out.println(“Write successful”); } else { System.err.println(“Write error”); ← — 记录错误 future.cause().printStackTrace(); } } }); Netty的Channel实现是线程安全的,因此你可以存储一个到Channel的引用,并且每当你需要向远程节点写数据时,都可以使用它,即使当时许多线程都在使用它。代码清单4-6展示了一个多线程写数据的简单例子。需要注意的是,消息将会被保证按顺序发送。 代码清单4-6 从多个线程使用同一个Channel final Channel channel = … final ByteBuf buf = Unpooled.copiedBuffer(“your data”, CharsetUtil.UTF_8).retain(); ← — 创建持有要写数据的ByteBuf Runnable writer = new Runnable() { ← — 创建将数据写到Channel 的Runnable @Override public void run() { channel.writeAndFlush(buf.duplicate()); } }; Executor executor = Executors.newCachedThreadPool(); ← — 获取到线程池Executor 的引用 // write in one thread executor.execute(writer); ← — 递交写任务给线程池以便在某个线程中执行 // write in another thread executor.execute(writer); ← — 递交另一个写任务以便在另一个线程中执行 …
4.3 内置的传输
Netty内置了一些可开箱即用的传输。因为并不是它们所有的传输都支持每一种协议,所以你必须选择一个和你的应用程序所使用的协议相容的传输。在本节中我们将讨论这些关系。 表4-2显示了所有Netty提供的传输。 表4-2 Netty所提供的传输 名 称 包 描 述 NIO io.netty.channel.socket.nio 使用 java.nio.channels包作为基础——基于选择器的方式 Epoll [2] io.netty.channel.epoll 由JNI驱动的 epoll()和非阻塞IO。这个传输支持只有在Linux上可用的多种特性,如SO_REUSEPORT,比NIO传输更快,而且是完全非阻塞的 OIO io.netty.channel.socket.oio 使用 java.net包作为基础——使用阻塞流 Local io.netty.channel.local 可以在VM内部通过管道进行通信的本地传输 Embedded io.netty.channel.embedded Embedded传输,允许使用 ChannelHandler而又不需要一个真正的基于网络的传输。这在测试你的ChannelHandler实现时非常有用 我们将在接下来的几节中详细讨论这些传输。
4.3.1 NIO——非阻塞I/O
NIO提供了一个所有I/O操作的全异步的实现。它利用了自NIO子系统被引入JDK 1.4时便可用的基于选择器的API。 选择器背后的基本概念是充当一个注册表,在那里你将可以请求在Channel的状态发生变化时得到通知。可能的状态变化有: 新的Channel已被接受并且就绪; Channel连接已经完成; Channel有已经就绪的可供读取的数据; Channel可用于写数据。 选择器运行在一个检查状态变化并对其做出相应响应的线程上,在应用程序对状态的改变做出响应之后,选择器将会被重置,并将重复这个过程。 表4-3中的常量值代表了由class java.nio.channels.SelectionKey定义的位模式。这些位模式可以组合起来定义一组应用程序正在请求通知的状态变化集。 表4-3 选择操作的位模式 名 称 描 述 OP_ACCEPT 请求在接受新连接并创建 Channel时获得通知 OP_CONNECT 请求在创建一个连接时获得通知 OP_READ 请求当数据已经就绪,可以从 Channel中读取时获得通知 OP_WRITE 请求当可以向 Channel中写更多的数据时获得通知。这处理了套接字缓冲区被完全填满时的情况,这种情况通常发生在数据的发送速度比远程节点可处理的速度更快的时候 对于所有Netty的传输实现都共有的用户级别API完全地隐藏了这些NIO的内部细节。图4-2展示了该处理流程。 图4-2 选择并处理状态的变化 零拷贝 零拷贝(zero-copy)是一种目前只有在使用NIO和Epoll传输时才可使用的特性。它使你可以快速高效地将数据从文件系统移动到网络接口,而不需要将其从内核空间复制到用户空间,其在像FTP或者HTTP这样的协议中可以显著地提升性能。但是,并不是所有的操作系统都支持这一特性。特别地,它对于实现了数据加密或者压缩的文件系统是不可用的——只能传输文件的原始内容。反过来说,传输已被加密的文件则不是问题。
4.3.2 Epoll——用于Linux的本地非阻塞传输
正如我们之前所说的,Netty的NIO传输基于Java提供的异步/非阻塞网络编程的通用抽象。虽然这保证了Netty的非阻塞API可以在任何平台上使用,但它也包含了相应的限制,因为JDK为了在所有系统上提供相同的功能,必须做出妥协。 Linux作为高性能网络编程的平台,其重要性与日俱增,这催生了大量先进特性的开发,其中包括epoll——一个高度可扩展的I/O事件通知特性。这个API自Linux内核版本2.5.44(2002)被引入,提供了比旧的POSIX select和poll系统调用[3]更好的性能,同时现在也是Linux上非阻塞网络编程的事实标准。Linux JDK NIO API使用了这些epoll调用。 Netty为Linux提供了一组NIO API,其以一种和它本身的设计更加一致的方式使用epoll,并且以一种更加轻量的方式使用中断。[4]如果你的应用程序旨在运行于Linux系统,那么请考虑利用这个版本的传输;你将发现在高负载下它的性能要优于JDK的NIO实现。 这个传输的语义与在图4-2所示的完全相同,而且它的用法也是简单直接的。相关示例参照代码清单4-4。如果要在那个代码清单中使用epoll替代NIO,只需要将NioEventLoopGroup替换为EpollEventLoopGroup,并且将NioServerSocketChannel.class替换为EpollServerSocketChannel.class即可。
4.3.3 OIO——旧的阻塞I/O
Netty的OIO传输实现代表了一种折中:它可以通过常规的传输API使用,但是由于它是创建在java.net包的阻塞实现之上的,所以它不是异步的。但是,它仍然非常适合于某些用途。 例如,你可能需要移植使用了一些进行阻塞调用的库(如JDBC[5])的遗留代码,而将逻辑转换为非阻塞的可能也是不切实际的。相反,你可以在短期内使用Netty的OIO传输,然后再将你的代码移植到纯粹的异步传输上。让我们来看一看怎么做。 在java.netAPI中,你通常会有一个用来接受到达正在监听的ServerSocket的新连接的线程。会创建一个新的和远程节点进行交互的套接字,并且会分配一个新的用于处理相应通信流量的线程。这是必需的,因为某个指定套接字上的任何I/O操作在任意的时间点上都可能会阻塞。使用单个线程来处理多个套接字,很容易导致一个套接字上的阻塞操作也捆绑了所有其他的套接字。 有了这个背景,你可能会想,Netty是如何能够使用和用于异步传输相同的API来支持OIO的呢。答案就是,Netty利用了SO_TIMEOUT这个Socket标志,它指定了等待一个I/O操作完成的最大毫秒数。如果操作在指定的时间间隔内没有完成,则将会抛出一个SocketTimeout Exception。Netty将捕获这个异常并继续处理循环。在EventLoop下一次运行时,它将再次尝试。这实际上也是类似于Netty这样的异步框架能够支持OIO的唯一方式[6]。图4-3说明了这个逻辑。
4.3.4 用于JVM内部通信的Local传输
Netty提供了一个Local传输,用于在同一个JVM中运行的客户端和服务器程序之间的异步通信。同样,这个传输也支持对于所有Netty传输实现都共同的API。 在这个传输中,和服务器Channel相关联的SocketAddress并没有绑定物理网络地址;相反,只要服务器还在运行,它就会被存储在注册表里,并在Channel关闭时注销。因为这个传输并不接受真正的网络流量,所以它并不能够和其他传输实现进行互操作。因此,客户端希望连接到(在同一个JVM中)使用了这个传输的服务器端时也必须使用它。除了这个限制,它的使用方式和其他的传输一模一样。 图4-3 OIO的处理逻辑
4.3.5 Embedded传输
Netty提供了一种额外的传输,使得你可以将一组ChannelHandler作为帮助器类嵌入到其他的ChannelHandler内部。通过这种方式,你将可以扩展一个ChannelHandler的功能,而又不需要修改其内部代码。 不足为奇的是,Embedded传输的关键是一个被称为EmbeddedChannel的具体的Channel实现。在第9章中,我们将详细地讨论如何使用这个类来为ChannelHandler的实现创建单元测试用例。
4.4 传输的用例
既然我们已经详细地了解了所有的传输,那么让我们考虑一下选用一个适用于特定用途的协议的因素吧。正如前面所提到的,并不是所有的传输都支持所有的核心协议,其可能会限制你的选择。表4-4展示了截止出版时的传输和其所支持的协议。 表4-4 支持的传输和网络协议 传 输 TCP UDP SCTP UDT [7] NIO × × × × Epoll(仅Linux) × × — — OIO × × × × 参见RFC 2960中有关流控制传输协议(SCTP)的解释:www.ietf.org/rfc/rfc2960.txt。表中X表示支持,—表示不支持。 在Linux上启用SCTP SCTP需要内核的支持,并且需要安装用户库。 例如,对于Ubuntu,可以使用下面的命令: # sudo apt-get install libsctp1 对于Fedora,可以使用yum: #sudo yum install kernel-modules-extra.x86_64 lksctp-tools.x86_64 有关如何启用SCTP的详细信息,请参考你的Linux发行版的文档。 虽然只有SCTP传输有这些特殊要求,但是其他传输可能也有它们自己的配置选项需要考虑。此外,如果只是为了支持更高的并发连接数,服务器平台可能需要配置得和客户端不一样。 这里是一些你很可能会遇到的用例。 非阻塞代码库——如果你的代码库中没有阻塞调用(或者你能够限制它们的范围),那么在Linux上使用NIO或者epoll始终是个好主意。虽然NIO/epoll旨在处理大量的并发连接,但是在处理较小数目的并发连接时,它也能很好地工作,尤其是考虑到它在连接之间共享线程的方式。 阻塞代码库——正如我们已经指出的,如果你的代码库严重地依赖于阻塞I/O,而且你的应用程序也有一个相应的设计,那么在你尝试将其直接转换为Netty的NIO传输时,你将可能会遇到和阻塞操作相关的问题。不要为此而重写你的代码,可以考虑分阶段迁移:先从OIO开始,等你的代码修改好之后,再迁移到NIO(或者使用epoll,如果你在使用Linux)。 在同一个JVM内部的通信——在同一个JVM内部的通信,不需要通过网络暴露服务,是Local传输的完美用例。这将消除所有真实网络操作的开销,同时仍然使用你的Netty代码库。如果随后需要通过网络暴露服务,那么你将只需要把传输改为NIO或者OIO即可。 测试你的ChannelHandler实现——如果你想要为自己的ChannelHandler实现编写单元测试,那么请考虑使用Embedded传输。这既便于测试你的代码,而又不需要创建大量的仿真(mock)对象。你的类将仍然符合常规的API事件流,保证该ChannelHandler在和真实的传输一起使用时能够正确地工作。你将在第9章中发现关于测试ChannelHandler的更多信息。 表4-5总结了我们探讨过的用例。 表4-5 应用程序的最佳传输 应用程序的需求 推荐的传输 非阻塞代码库或者一个常规的起点 NIO(或者在Linux上使用epoll) 阻塞代码库 OIO 在同一个JVM内部的通信 Local 测试 ChannelHandler的实现 Embedded
4.5 小结
在本章中,我们研究了传输、它们的实现和使用,以及Netty是如何将它们呈现给开发者的。 我们深入探讨了Netty预置的传输,并且解释了它们的行为。因为不是所有的传输都可以在相同的Java版本下工作,并且其中一些可能只在特定的操作系统下可用,所以我们也描述了它们的最低需求。最后,我们讨论了你可以如何匹配不同的传输和特定用例的需求。 在下一章中,我们将关注于ByteBuf和ByteBufHolder——Netty的数据容器。我们将展示如何使用它们以及如何通过它们获得最佳性能。
第5章 ByteBuf
本章主要内容
ByteBuf——Netty的数据容器
API的详细信息
用例
内存分配
正如前面所提到的,网络数据的基本单位总是字节。Java NIO提供了ByteBuffer作为它的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐。 Netty的ByteBuffer替代品是ByteBuf,一个强大的实现,既解决了JDK API的局限性,又为网络应用程序的开发者提供了更好的API。 在本章中我们将会说明和JDK的ByteBuffer相比,ByteBuf的卓越功能性和灵活性。这也将有助于更好地理解Netty数据处理的一般方式,并为将在第6章中针对ChannelPipeline和ChannelHandler的讨论做好准备。
5.1 ByteBuf的API
Netty的数据处理API通过两个组件暴露——abstract class ByteBuf和interface ByteBufHolder。 下面是一些ByteBuf API的优点: 它可以被用户自定义的缓冲区类型扩展; 通过内置的复合缓冲区类型实现了透明的零拷贝; 容量可以按需增长(类似于JDK的StringBuilder); 在读和写这两种模式之间切换不需要调用ByteBuffer的flip()方法; 读和写使用了不同的索引; 支持方法的链式调用; 支持引用计数; 支持池化。 其他类可用于管理ByteBuf实例的分配,以及执行各种针对于数据容器本身和它所持有的数据的操作。我们将在仔细研究ByteBuf和ByteBufHolder时探讨这些特性。
5.2 ByteBuf类——Netty的数据容器
因为所有的网络通信都涉及字节序列的移动,所以高效易用的数据结构明显是必不可少的。Netty的ByteBuf实现满足并超越了这些需求。让我们首先来看看它是如何通过使用不同的索引来简化对它所包含的数据的访问的吧。
5.2.1 它是如何工作的
ByteBuf维护了两个不同的索引:一个用于读取,一个用于写入。当你从ByteBuf读取时,它的readerIndex将会被递增已经被读取的字节数。同样地,当你写入ByteBuf时,它的writerIndex也会被递增。图5-1展示了一个空ByteBuf的布局结构和状态。 图5-1 一个读索引和写索引都设置为0的16字节ByteBuf 要了解这些索引两两之间的关系,请考虑一下,如果打算读取字节直到readerIndex达到和writerIndex同样的值时会发生什么。在那时,你将会到达“可以读取的”数据的末尾。就如同试图读取超出数组末尾的数据一样,试图读取超出该点的数据将会触发一个IndexOutOf-BoundsException。 名称以read或者write开头的ByteBuf方法,将会推进其对应的索引,而名称以set或者get开头的操作则不会。后面的这些方法将在作为一个参数传入的一个相对索引上执行操作。 可以指定ByteBuf的最大容量。试图移动写索引(即readerIndex)超过这个值将会触发一个异常[1]。(默认的限制是Integer.MAX_VALUE。)
5.2.2 ByteBuf的使用模式
在使用Netty时,你将遇到几种常见的围绕ByteBuf而构建的使用模式。在研究它们时,我们心里想着图5-1会有所裨益—— 一个由不同的索引分别控制读访问和写访问的字节数组。 1.堆缓冲区 最常用的ByteBuf模式是将数据存储在JVM的堆空间中。这种模式被称为支撑数组(backing array),它能在没有使用池化的情况下提供快速的分配和释放。这种方式,如代码清单5-1所示,非常适合于有遗留的数据需要处理的情况。 代码清单5-1 支撑数组 ByteBuf heapBuf = …; if (heapBuf.hasArray()) { ← — 检查ByteBuf 是否有一个支撑数组 byte[] array = heapBuf.array(); ← — 如果有,则获取对该数组的引用 int offset = heapBuf.arrayOffset() + heapBuf.readerIndex(); ← — 计算第一个字节的偏移量。 int length = heapBuf.readableBytes(); ← — 获得可读字节数 handleArray(array, offset, length); ← — 使用数组、偏移量和长度作为参数调用你的方法 } 注意 当hasArray()方法返回false时,尝试访问支撑数组将触发一个UnsupportedOperationException。这个模式类似于JDK的ByteBuffer的用法。 2.直接缓冲区 直接缓冲区是另外一种ByteBuf模式。我们期望用于对象创建的内存分配永远都来自于堆中,但这并不是必须的——NIO在JDK 1.4中引入的ByteBuffer类允许JVM实现通过本地调用来分配内存。这主要是为了避免在每次调用本地I/O操作之前(或者之后)将缓冲区的内容复制到一个中间缓冲区(或者从中间缓冲区把内容复制到缓冲区)。 ByteBuffer的Javadoc[2]明确指出:“直接缓冲区的内容将驻留在常规的会被垃圾回收的堆之外。”这也就解释了为何直接缓冲区对于网络数据传输是理想的选择。如果你的数据包含在一个在堆上分配的缓冲区中,那么事实上,在通过套接字发送它之前,JVM将会在内部把你的缓冲区复制到一个直接缓冲区中。 直接缓冲区的主要缺点是,相对于基于堆的缓冲区,它们的分配和释放都较为昂贵。如果你正在处理遗留代码,你也可能会遇到另外一个缺点:因为数据不是在堆上,所以你不得不进行一次复制,如代码清单5-2所示。 显然,与使用支撑数组相比,这涉及的工作更多。因此,如果事先知道容器中的数据将会被作为数组来访问,你可能更愿意使用堆内存。 代码清单5-2 访问直接缓冲区的数据 ByteBuf directBuf = …; if (!directBuf.hasArray()) { ← — 检查ByteBuf 是否由数组支撑。如果不是,则这是一个直接缓冲区 int length = directBuf.readableBytes(); ← — 获取可读字节数 byte[] array = new byte[length]; ← — 分配一个新的数组来保存具有该长度的字节数据 directBuf.getBytes(directBuf.readerIndex(), array); ← — 将字节复制到该数组 handleArray(array, 0, length); ← — 使用数组、偏移量和长度作为参数调用你的方法 } 3.复合缓冲区 第三种也是最后一种模式使用的是复合缓冲区,它为多个ByteBuf提供一个聚合视图。在这里你可以根据需要添加或者删除ByteBuf实例,这是一个JDK的ByteBuffer实现完全缺失的特性。 Netty通过一个ByteBuf子类——CompositeByteBuf——实现了这个模式,它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示。 警告 CompositeByteBuf中的ByteBuf实例可能同时包含直接内存分配和非直接内存分配。如果其中只有一个实例,那么对CompositeByteBuf上的hasArray()方法的调用将返回该组件上的hasArray()方法的值;否则它将返回false。 为了举例说明,让我们考虑一下一个由两部分——头部和主体——组成的将通过HTTP协议传输的消息。这两部分由应用程序的不同模块产生,将会在消息被发送的时候组装。该应用程序可以选择为多个消息重用相同的消息主体。当这种情况发生时,对于每个消息都将会创建一个新的头部。 因为我们不想为每个消息都重新分配这两个缓冲区,所以使用CompositeByteBuf是一个完美的选择。它在消除了没必要的复制的同时,暴露了通用的ByteBuf API。图5-2展示了生成的消息布局。 图5-2 持有一个头部和主体的CompositeByteBuf 代码清单5-3展示了如何通过使用JDK的ByteBuffer来实现这一需求。创建了一个包含两个ByteBuffer的数组用来保存这些消息组件,同时创建了第三个ByteBuffer用来保存所有这些数据的副本。 代码清单5-3 使用ByteBuffer的复合缓冲区模式 // Use an array to hold the message parts ByteBuffer[] message = new ByteBuffer[] { header, body }; // Create a new ByteBuffer and use copy to merge the header and body ByteBuffer message2 = ByteBuffer.allocate(header.remaining() + body.remaining()); message2.put(header); message2.put(body); message2.flip(); 分配和复制操作,以及伴随着对数组管理的需要,使得这个版本的实现效率低下而且笨拙。代码清单5-4展示了一个使用了CompositeByteBuf的版本。 代码清单5-4 使用CompositeByteBuf的复合缓冲区模式 CompositeByteBuf messageBuf = Unpooled.compositeBuffer(); ByteBuf headerBuf = …; // can be backing or direct ByteBuf bodyBuf = …; // can be backing or direct messageBuf.addComponents(headerBuf, bodyBuf); ← — 将ByteBuf 实例追加到CompositeByteBuf ….. messageBuf.removeComponent(0); // remove the header ← — 删除位于索引位置为 0(第一个组件)的ByteBuf for (ByteBuf buf : messageBuf) { ← — 循环遍历所有的ByteBuf 实例 System.out.println(buf.toString()); } CompositeByteBuf可能不支持访问其支撑数组,因此访问CompositeByteBuf中的数据类似于(访问)直接缓冲区的模式,如代码清单5-5所示。 代码清单5-5 访问CompositeByteBuf中的数据 CompositeByteBuf compBuf = Unpooled.compositeBuffer(); int length = compBuf.readableBytes(); ← — 获得可读字节数 byte[] array = new byte[length]; ← — 分配一个具有可读字节数长度的新数组 compBuf.getBytes(compBuf.readerIndex(), array); ← — 将字节读到该数组中 handleArray(array, 0, array.length); ← — 使用偏移量和长度作为参数使用该数组 需要注意的是,Netty使用了CompositeByteBuf来优化套接字的I/O操作,尽可能地消除了由JDK的缓冲区实现所导致的性能以及内存使用率的惩罚。[3]这种优化发生在Netty的核心代码中,因此不会被暴露出来,但是你应该知道它所带来的影响。 CompositeByteBuf API 除了从ByteBuf继承的方法,CompositeByteBuf提供了大量的附加功能。请参考Netty的Javadoc以获得该API的完整列表。
5.3 字节级操作
ByteBuf提供了许多超出基本读、写操作的方法用于修改它的数据。在接下来的章节中,我们将会讨论这些中最重要的部分。
5.3.1 随机访问索引
如同在普通的Java字节数组中一样,ByteBuf的索引是从零开始的:第一个字节的索引是0,最后一个字节的索引总是capacity() - 1。代码清单5-6表明,对存储机制的封装使得遍历ByteBuf的内容非常简单。 代码清单5-6 访问数据 ByteBuf buffer = …; for (int i = 0; i < buffer.capacity(); i++) { byte b = buffer.getByte(i); System.out.println((char)b); } 需要注意的是,使用那些需要一个索引值参数的方法(的其中)之一来访问数据既不会改变readerIndex也不会改变writerIndex。如果有需要,也可以通过调用readerIndex(index)或者writerIndex(index)来手动移动这两者。
5.3.2 顺序访问索引
虽然ByteBuf同时具有读索引和写索引,但是JDK的ByteBuffer却只有一个索引,这也就是为什么必须调用flip()方法来在读模式和写模式之间进行切换的原因。图5-3展示了ByteBuf是如何被它的两个索引划分成3个区域的。 图5-3 ByteBuf的内部分段
5.3.3 可丢弃字节
在图5-3中标记为可丢弃字节的分段包含了已经被读过的字节。通过调用discardRead-Bytes()方法,可以丢弃它们并回收空间。这个分段的初始大小为0,存储在readerIndex中,会随着read操作的执行而增加(get*操作不会移动readerIndex)。 图5-4展示了图5-3中所展示的缓冲区上调用discardReadBytes()方法后的结果。可以看到,可丢弃字节分段中的空间已经变为可写的了。注意,在调用discardReadBytes()之后,对可写分段的内容并没有任何的保证[4]。 图5-4 丢弃已读字节之后的ByteBuf 虽然你可能会倾向于频繁地调用discardReadBytes()方法以确保可写分段的最大化,但是请注意,这将极有可能会导致内存复制,因为可读字节(图中标记为CONTENT的部分)必须被移动到缓冲区的开始位置。我们建议只在有真正需要的时候才这样做,例如,当内存非常宝贵的时候。
5.3.4 可读字节
ByteBuf的可读字节分段存储了实际数据。新分配的、包装的或者复制的缓冲区的默认的readerIndex值为0。任何名称以read或者skip开头的操作都将检索或者跳过位于当前readerIndex的数据,并且将它增加已读字节数。 如果被调用的方法需要一个ByteBuf参数作为写入的目标,并且没有指定目标索引参数,那么该目标缓冲区的writerIndex也将被增加,例如: readBytes(ByteBuf dest); 如果尝试在缓冲区的可读字节数已经耗尽时从中读取数据,那么将会引发一个IndexOutOf-BoundsException。 代码清单5-7展示了如何读取所有可以读的字节。 代码清单5-7 读取所有数据 ByteBuf buffer = …; while (buffer.isReadable()) { System.out.println(buffer.readByte()); }
5.3.5 可写字节
可写字节分段是指一个拥有未定义内容的、写入就绪的内存区域。新分配的缓冲区的writerIndex的默认值为0。任何名称以write开头的操作都将从当前的writerIndex处开始写数据,并将它增加已经写入的字节数。如果写操作的目标也是ByteBuf,并且没有指定源索引的值,则源缓冲区的readerIndex也同样会被增加相同的大小。这个调用如下所示: writeBytes(ByteBuf dest); 如果尝试往目标写入超过目标容量的数据,将会引发一个IndexOutOfBoundException[5]。 代码清单5-8是一个用随机整数值填充缓冲区,直到它空间不足为止的例子。writeableBytes()方法在这里被用来确定该缓冲区中是否还有足够的空间。 代码清单5-8 写数据 // Fills the writable bytes of a buffer with random integers. ByteBuf buffer = …; while (buffer.writableBytes() >= 4) { buffer.writeInt(random.nextInt()); }
5.3.6 索引管理
JDK的InputStream定义了mark(int readlimit)和reset()方法,这些方法分别被用来将流中的当前位置标记为指定的值,以及将流重置到该位置。 同样,可以通过调用markReaderIndex()、markWriterIndex()、resetWriterIndex()和resetReaderIndex()来标记和重置ByteBuf的readerIndex和writerIndex。这些和InputStream上的调用类似,只是没有readlimit参数来指定标记什么时候失效。 也可以通过调用readerIndex(int)或者writerIndex(int)来将索引移动到指定位置。试图将任何一个索引设置到一个无效的位置都将导致一个IndexOutOfBoundsException。 可以通过调用clear()方法来将readerIndex和writerIndex都设置为0。注意,这并不会清除内存中的内容。图5-5(重复上面的图5-3)展示了它是如何工作的。 图5-5 clear()方法被调用之前 和之前一样,ByteBuf包含3个分段。图5-6展示了在clear()方法被调用之后ByteBuf的状态。 图5-6 在clear()方法被调用之后 调用clear()比调用discardReadBytes()轻量得多,因为它将只是重置索引而不会复制任何的内存。
5.3.7 查找操作
在ByteBuf中有多种可以用来确定指定值的索引的方法。最简单的是使用indexOf()方法。较复杂的查找可以通过那些需要一个ByteBufProcessor[6]作为参数的方法达成。这个接口只定义了一个方法: boolean process(byte value) 它将检查输入值是否是正在查找的值。 ByteBufProcessor针对一些常见的值定义了许多便利的方法。假设你的应用程序需要和所谓的包含有以NULL结尾的内容的Flash套接字[7]集成。调用 forEachByte(ByteBufProcessor.FIND_NUL) 将简单高效地消费该Flash数据,因为在处理期间只会执行较少的边界检查。 代码清单5-9展示了一个查找掉头符(\r)的例子。 代码清单5-9 使用ByteBufProcessor来寻找\r ByteBuf buffer = …; int index = buffer.forEachByte(ByteBufProcessor.FIND_CR);
5.3.8 派生缓冲区
派生缓冲区为ByteBuf提供了以专门的方式来呈现其内容的视图。这类视图是通过以下方法被创建的: duplicate(); slice(); slice(int, int); Unpooled.unmodifiableBuffer(…); order(ByteOrder); readSlice(int)。 每个这些方法都将返回一个新的ByteBuf实例,它具有自己的读索引、写索引和标记索引。其内部存储和JDK的ByteBuffer一样也是共享的。这使得派生缓冲区的创建成本是很低廉的,但是这也意味着,如果你修改了它的内容,也同时修改了其对应的源实例,所以要小心。 ByteBuf复制 如果需要一个现有缓冲区的真实副本,请使用copy()或者copy(int, int)方法。不同于派生缓冲区,由这个调用所返回的ByteBuf拥有独立的数据副本。 代码清单5-10展示了如何使用slice(int,int)方法来操作ByteBuf的一个分段。 代码清单5-10 对ByteBuf进行切片 Charset utf8 = Charset.forName(“UTF-8”); ByteBuf buf = Unpooled.copiedBuffer(“Netty in Action rocks!”, utf8); ← — 创建一个用于保存给定字符串的字节的ByteBuf ByteBuf sliced = buf.slice(0, 15); ← — 创建该ByteBuf 从索引0 开始到索引15结束的一个新切片 System.out.println(sliced.toString(utf8)); ← — 将打印“Netty in Action” buf.setByte(0, (byte)’J’); ← — 更新索引0 处的字节 assert buf.getByte(0) == sliced.getByte(0); ← — 将会成功,因为数据是共享的,对其中一个所做的更改对另外一个也是可见的 现在,让我们看看ByteBuf的分段的副本和切片有何区别,如代码清单5-11所示。 代码清单5-11 复制一个ByteBuf Charset utf8 = Charset.forName(“UTF-8”); ByteBuf buf = Unpooled.copiedBuffer(“Netty in Action rocks!”, utf8); ← — 创建ByteBuf 以保存所提供的字符串的字节 ByteBuf copy = buf.copy(0, 15); ← — 创建该ByteBuf 从索引0 开始到索引15结束的分段的副本 System.out.println(copy.toString(utf8)); ← — 将打印“Netty in Action” buf.setByte(0, (byte) ‘J’); ← — 更新索引0 处的字节 assert buf.getByte(0) != copy.getByte(0); ← — 将会成功,因为数据不是共享的 除了修改原始ByteBuf的切片或者副本的效果以外,这两种场景是相同的。只要有可能,使用slice()方法来避免复制内存的开销。
5.3.9 读/写操作
正如我们所提到过的,有两种类别的读/写操作: get()和set()操作,从给定的索引开始,并且保持索引不变; read()和write()操作,从给定的索引开始,并且会根据已经访问过的字节数对索引进行调整。 表5-1列举了最常用的get()方法。完整列表请参考对应的API文档。 表5-1 get()操作 名 称 描 述 getBoolean(int) 返回给定索引处的 Boolean值 getByte(int) 返回给定索引处的字节 getUnsignedByte(int) 将给定索引处的无符号字节值作为 short返回 getMedium(int) 返回给定索引处的24位的中等 int值 getUnsignedMedium(int) 返回给定索引处的无符号的24位的中等 int值 getInt(int) 返回给定索引处的 int值 getUnsignedInt(int) 将给定索引处的无符号 int值作为long返回 getLong(int) 返回给定索引处的 long值 getShort(int) 返回给定索引处的 short值 getUnsignedShort(int) 将给定索引处的无符号 short值作为int返回 getBytes(int, …) 将该缓冲区中从给定索引开始的数据传送到指定的目的地 大多数的这些操作都有一个对应的set()方法。这些方法在表5-2中列出。 表5-2 set()操作 名 称 描 述 setBoolean(int, boolean) 设定给定索引处的 Boolean值 setByte(int index, int value) 设定给定索引处的字节值 setMedium(int index, int value) 设定给定索引处的24位的中等 int值 setInt(int index, int value) 设定给定索引处的 int值 setLong(int index, long value) 设定给定索引处的 long值 setShort(int index, int value) 设定给定索引处的 short值 代码清单5-12说明了get()和set()方法的用法,表明了它们不会改变读索引和写索引。 代码清单5-12 get()和set()方法的用法 Charset utf8 = Charset.forName(“UTF-8”); ByteBuf buf = Unpooled.copiedBuffer(“Netty in Action rocks!”, utf8); ← — 创建一个新的ByteBuf以保存给定字符串的字节 System.out.println((char)buf.getByte(0)); ← — 打印第一个字符’N’ int readerIndex = buf.readerIndex(); ← — 存储当前的readerIndex 和writerIndex int writerIndex = buf.writerIndex(); buf.setByte(0, (byte)’B’); ← — 将索引0 处的字节更新为字符’B’ System.out.println((char)buf.getByte(0)); ← — 打印第一个字符,现在是’B’ assert readerIndex == buf.readerIndex(); ← — 将会成功,因为这些操作并不会修改相应的索引 assert writerIndex == buf.writerIndex(); 现在,让我们研究一下read()操作,其作用于当前的readerIndex或writerIndex。这些方法将用于从ByteBuf中读取数据,如同它是一个流。表5-3展示了最常用的方法。 表5-3 read()操作 名 称 描 述 readBoolean() 返回当前 readerIndex处的Boolean,并将readerIndex增加1 readByte() 返回当前 readerIndex处的字节,并将readerIndex增加1 readUnsignedByte() 将当前 readerIndex处的无符号字节值作为short返回,并将readerIndex增加1 readMedium() 返回当前 readerIndex处的24位的中等int值,并将readerIndex增加3 readUnsignedMedium() 返回当前 readerIndex处的24位的无符号的中等int值,并将readerIndex增加3 readInt() 返回当前 readerIndex的int值,并将readerIndex增加4 readUnsignedInt() 将当前 readerIndex处的无符号的int值作为long值返回,并将readerIndex增加4 readLong() 返回当前 readerIndex处的long值,并将readerIndex增加8 readShort() 返回当前 readerIndex处的short值,并将readerIndex增加2 readUnsignedShort() 将当前 readerIndex处的无符号short值作为int值返回,并将readerIndex增加2 readBytes(ByteBuf | byte[] destination, int dstIndex [,int length]) 将当前 ByteBuf中从当前readerIndex处开始的(如果设置了,length长度的字节)数据传送到一个目标ByteBuf或者byte[],从目标的dstIndex开始的位置。本地的readerIndex将被增加已经传输的字节数 几乎每个read()方法都有对应的write()方法,用于将数据追加到ByteBuf中。注意,表5-4中所列出的这些方法的参数是需要写入的值,而不是索引值。 表5-4 写操作 名 称 描 述 writeBoolean(boolean) 在当前 writerIndex处写入一个Boolean,并将writerIndex增加1 writeByte(int) 在当前 writerIndex处写入一个字节值,并将writerIndex增加1 writeMedium(int) 在当前 writerIndex处写入一个中等的int值,并将writerIndex增加3 writeInt(int) 在当前 writerIndex处写入一个int值,并将writerIndex增加4 writeLong(long) 在当前 writerIndex处写入一个long值,并将writerIndex增加8 writeShort(int) 在当前 writerIndex处写入一个short值,并将writerIndex增加2 writeBytes(source ByteBuf |byte[] [,int srcIndex ,int length]) 从当前 writerIndex开始,传输来自于指定源(ByteBuf或者byte[])的数据。如果提供了srcIndex和length,则从srcIndex开始读取,并且处理长度为length的字节。当前writerIndex将会被增加所写入的字节数 代码清单5-13展示了这些方法的用法。 代码清单5-13 ByteBuf上的read()和write()操作 Charset utf8 = Charset.forName(“UTF-8”); ByteBuf buf = Unpooled.copiedBuffer(“Netty in Action rocks!”, utf8); ← — 创建一个新的ByteBuf 以保存给定字符串的字节 System.out.println((char)buf.readByte()); ← — 打印第一个字符’N’ int readerIndex = buf.readerIndex(); ← — 存储当前的readerIndex int writerIndex = buf.writerIndex(); ← — 存储当前的writerIndex buf.writeByte((byte)’?’); ← — 将字符’?’追加到缓冲区 assert readerIndex == buf.readerIndex(); assert writerIndex != buf.writerIndex(); ← — 将会成功,因为writeByte()方法移动了writerIndex
5.3.10 更多的操作
表5-5 列举了由ByteBuf提供的其他有用操作。 表5-5 其他有用的操作 名 称 描 述 isReadable() 如果至少有一个字节可供读取,则返回 true isWritable() 如果至少有一个字节可被写入,则返回 true readableBytes() 返回可被读取的字节数 writableBytes() 返回可被写入的字节数 capacity() 返回 ByteBuf可容纳的字节数。在此之后,它会尝试再次扩展直 到达到maxCapacity() maxCapacity() 返回 ByteBuf可以容纳的最大字节数 hasArray() 如果 ByteBuf由一个字节数组支撑,则返回true array() 如果 ByteBuf由一个字节数组支撑则返回该数组;否则,它将抛出一个UnsupportedOperationException异常
5.4 ByteBufHolder接口
我们经常发现,除了实际的数据负载之外,我们还需要存储各种属性值。HTTP响应便是一个很好的例子,除了表示为字节的内容,还包括状态码、cookie等。 为了处理这种常见的用例,Netty提供了ByteBufHolder。ByteBufHolder也为Netty的高级特性提供了支持,如缓冲区池化,其中可以从池中借用ByteBuf,并且在需要时自动释放。 ByteBufHolder只有几种用于访问底层数据和引用计数的方法。表5-6列出了它们(这里不包括它继承自ReferenceCounted的那些方法)。 表5-6 ByteBufHolder的操作 名 称 描 述 content() 返回由这个 ByteBufHolder所持有的ByteBuf copy() 返回这个 ByteBufHolder的一个深拷贝,包括一个其所包含的ByteBuf的非共享拷贝 duplicate() 返回这个 ByteBufHolder的一个浅拷贝,包括一个其所包含的ByteBuf的共享拷贝 如果想要实现一个将其有效负载存储在ByteBuf中的消息对象,那么ByteBufHolder将是个不错的选择。
5.5 ByteBuf分配
在这一节中,我们将描述管理ByteBuf实例的不同方式。
5.5.1 按需分配:ByteBufAllocator接口
为了降低分配和释放内存的开销,Netty通过interface ByteBufAllocator实现了(ByteBuf的)池化,它可以用来分配我们所描述过的任意类型的ByteBuf实例。使用池化是特定于应用程序的决定,其并不会以任何方式改变ByteBuf API(的语义)。 表5-7 列出了ByteBufAllocator提供的一些操作。 表5-7 ByteBufAllocator的方法 名 称 描 述 buffer() buffer(int initialCapacity); buffer(int initialCapacity, int maxCapacity); 返回一个基于堆或者直接内存存储的 ByteBuf heapBuffer() heapBuffer(int initialCapacity) heapBuffer(int initialCapacity, int maxCapacity) 返回一个基于堆内存存储的 ByteBuf directBuffer() directBuffer(int initialCapacity) directBuffer(int initialCapacity, int maxCapacity) 返回一个基于直接内存存储的 ByteBuf compositeBuffer() compositeBuffer(int maxNumComponents) compositeDirectBuffer() compositeDirectBuffer(int maxNumComponents); compositeHeapBuffer() compositeHeapBuffer(int maxNumComponents); 返回一个可以通过添加最大到指定数目的基于堆的或者直接内存存储的缓冲区来扩展的 CompositeByteBuf ioBuffer() [8] 返回一个用于套接字的I/O操作的 ByteBuf 可以通过Channel(每个都可以有一个不同的ByteBufAllocator实例)或者绑定到ChannelHandler的ChannelHandlerContext获取一个到ByteBufAllocator的引用。代码清单5-14说明了这两种方法。 代码清单5-14 获取一个到ByteBufAllocator的引用 Channel channel = …; ByteBufAllocator allocator = channel.alloc(); ← — 从Channel 获取一个到ByteBufAllocator 的引用 …. ChannelHandlerContext ctx = …; ByteBufAllocator allocator2 = ctx.alloc(); ← — 从ChannelHandlerContext 获取一个到ByteBufAllocator 的引用 … Netty提供了两种ByteBufAllocator的实现:PooledByteBufAllocator和Unpooled-ByteBufAllocator。前者池化了ByteBuf的实例以提高性能并最大限度地减少内存碎片。此实现使用了一种称为jemalloc[9]的已被大量现代操作系统所采用的高效方法来分配内存。后者的实现不池化ByteBuf实例,并且在每次它被调用时都会返回一个新的实例。 虽然Netty默认[10]使用了PooledByteBufAllocator,但这可以很容易地通过Channel-Config API或者在引导你的应用程序时指定一个不同的分配器来更改。更多的细节可在第8章中找到。
5.5.2 Unpooled缓冲区
可能某些情况下,你未能获取一个到ByteBufAllocator的引用。对于这种情况,Netty提供了一个简单的称为Unpooled的工具类,它提供了静态的辅助方法来创建未池化的ByteBuf实例。表5-8列举了这些中最重要的方法。 表5-8 Unpooled的方法 名 称 描 述 buffer() buffer(int initialCapacity) buffer(int initialCapacity, int maxCapacity) 返回一个未池化的基于堆内存存储的 ByteBuf directBuffer() directBuffer(int initialCapacity) directBuffer(int initialCapacity, int maxCapacity) 返回一个未池化的基于直接内存存储的 ByteBuf wrappedBuffer() 返回一个包装了给定数据的 ByteBuf copiedBuffer() 返回一个复制了给定数据的 ByteBuf Unpooled类还使得ByteBuf同样可用于那些并不需要Netty的其他组件的非网络项目,使得其能得益于高性能的可扩展的缓冲区API。
5.5.3 ByteBufUtil类
ByteBufUtil提供了用于操作ByteBuf的静态的辅助方法。因为这个API是通用的,并且和池化无关,所以这些方法已然在分配类的外部实现。 这些静态方法中最有价值的可能就是hexdump()方法,它以十六进制的表示形式打印ByteBuf的内容。这在各种情况下都很有用,例如,出于调试的目的记录ByteBuf的内容。十六进制的表示通常会提供一个比字节值的直接表示形式更加有用的日志条目,此外,十六进制的版本还可以很容易地转换回实际的字节表示。 另一个有用的方法是boolean equals(ByteBuf, ByteBuf),它被用来判断两个ByteBuf实例的相等性。如果你实现自己的ByteBuf子类,你可能会发现ByteBufUtil的其他有用方法。
5.6 引用计数
引用计数是一种通过在某个对象所持有的资源不再被其他对象引用时释放该对象所持有的资源来优化内存使用和性能的技术。Netty在第4版中为ByteBuf和ByteBufHolder引入了引用计数技术,它们都实现了interface ReferenceCounted。 引用计数背后的想法并不是特别的复杂;它主要涉及跟踪到某个特定对象的活动引用的数量。一个ReferenceCounted实现的实例将通常以活动的引用计数为1作为开始。只要引用计数大于0,就能保证对象不会被释放。当活动引用的数量减少到0时,该实例就会被释放。注意,虽然释放的确切语义可能是特定于实现的,但是至少已经释放的对象应该不可再用了。 引用计数对于池化实现(如PooledByteBufAllocator)来说是至关重要的,它降低了内存分配的开销。代码清单5-15和代码清单5-16展示了相关的示例。 代码清单5-15 引用计数 Channel channel = …; ByteBufAllocator allocator = channel.alloc(); ← — 从Channel 获取ByteBufAllocator …. ByteBuf buffer = allocator.directBuffer(); ← — 从ByteBufAllocator分配一个ByteBuf assert buffer.refCnt() == 1; ← — 检查引用计数是否为预期的1 … 代码清单5-16 释放引用计数的对象 ByteBuf buffer = …; boolean released = buffer.release(); ← — 减少到该对象的活动引用。当减少到0 时,该对象被释放,并且该方法返回true … 试图访问一个已经被释放的引用计数的对象,将会导致一个IllegalReferenceCount- Exception。 注意,一个特定的(ReferenceCounted的实现)类,可以用它自己的独特方式来定义它的引用计数规则。例如,我们可以设想一个类,其release()方法的实现总是将引用计数设为零,而不用关心它的当前值,从而一次性地使所有的活动引用都失效。 谁负责释放 一般来说,是由最后访问(引用计数)对象的那一方来负责将它释放。在第6章中,我们将会解释这个概念和ChannelHandler以及ChannelPipeline的相关性。
5.7 小结
本章专门探讨了Netty的基于ByteBuf的数据容器。我们首先解释了ByteBuf相对于JDK所提供的实现的优势。我们还强调了该API的其他可用变体,并且指出了它们各自最佳适用的特定用例。 我们讨论过的要点有: 使用不同的读索引和写索引来控制数据访问; 使用内存的不同方式——基于字节数组和直接缓冲区; 通过CompositeByteBuf生成多个ByteBuf的聚合视图; 数据访问方法——搜索、切片以及复制; 读、写、获取和设置API; ByteBufAllocator池化和引用计数。 在下一章中,我们将专注于ChannelHandler,它为你的数据处理逻辑提供了载体。因为ChannelHandler大量地使用了ByteBuf,你将开始看到Netty的整体架构的各个重要部分最终走到了一起。 [1] 也就是说用户直接或者间接使capacity(int)或者ensureWritable(int)方法来增加超过该最大容量时抛出异常。——译者注 [2] Java平台,标准版第8版API规范,java.nio,class ByteBuffer:http://docs.oracle. com/javase/8/docs/api/ java/nio/ByteBuffer.html。 [3] 这尤其适用于JDK所使用的一种称为分散/收集I/O(Scatter/Gather I/O)的技术,定义为“一种输入和输出的方法,其中,单个系统调用从单个数据流写到一组缓冲区中,或者,从单个数据源读到一组缓冲区中”。《Linux System Programming》,作者Robert Love(O’Reilly, 2007)。 [4] 因为只是移动了可以读取的字节以及writerIndex,而没有对所有可写入的字节进行擦除写。——译者注 [5] 在往ByteBuf中写入数据时,其将首先确保目标ByteBuf具有足够的可写入空间来容纳当前要写入的数据,如果没有,则将检查当前的写索引以及最大容量是否可以在扩展后容纳该数据,可以则会分配并调整容量,否则就会抛出该异常。——译者注 [6] 在Netty 4.1.x中,该类已经废弃,请使用io.netty.util.ByteProcessor。——译者注 [7] 有关Flash套接字的讨论可参考Flash ActionScript 3.0 Developer’s Guide中Networking and Communication部分里的Sockets页面:http://help.adobe.com/en_US/as3/dev/WSb2ba3b1aad8a27b0-181c51321220efd9d1c-8000.html。 [8] 默认地,当所运行的环境具有sun.misc.Unsafe支持时,返回基于直接内存存储的ByteBuf,否则返回基于堆内存存储的ByteBuf;当指定使用PreferHeapByteBufAllocator时,则只会返回基于堆内存存储的ByteBuf。——译者注 [9] Jason Evans的“A Scalable Concurrent malloc(3) Implementation for FreeBSD”(2006):http://people.freebsd. org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf。 [10] 这里指Netty4.1.x,Netty4.0.x默认使用的是UnpooledByteBufAllocator。——译者注
第6章 ChannelHandler和ChannelPipeline
[TOC]
本章主要内容 ChannelHandler API和ChannelPipeline API 检测资源泄漏 异常处理 在上一章中你学习了ByteBuf——Netty的数据容器。当我们在本章中探讨Netty的数据流以及处理组件时,我们将基于已经学过的东西,并且你将开始看到框架的重要元素都结合到了一起。 你已经知道,可以在ChannelPipeline中将ChannelHandler链接在一起以组织处理逻辑。我们将会研究涉及这些类的各种用例,以及一个重要的关系——ChannelHandlerContext。 理解所有这些组件之间的交互对于通过Netty构建模块化的、可重用的实现至关重要。
6.1 ChannelHandler家族
在我们开始详细地学习ChannelHandler之前,我们将在Netty的组件模型的这部分基础上花上一些时间。
6.1.1 Channel的生命周期
Interface Channel定义了一组和ChannelInboundHandlerAPI密切相关的简单但功能强大的状态模型,表6-1列出了Channel的这4个状态。
表6-1 Channel的生命周期状态 状 态 描 述 ChannelUnregistered Channel已经被创建,但还未注册到EventLoop ChannelRegistered Channel已经被注册到了EventLoop ChannelActive Channel处于活动状态(已经连接到它的远程节点)。它现在可以接收和发送数据了 ChannelInactive Channel没有连接到远程节点 Channel的正常生命周期如图6-1所示。当这些状态发生改变时,将会生成对应的事件。这些事件将会被转发给ChannelPipeline中的ChannelHandler,其可以随后对它们做出响应。
图6-1 Channel的状态模型
6.1.2 ChannelHandler的生命周期
表6-2中列出了interface ChannelHandler定义的生命周期操作,在ChannelHandler被添加到ChannelPipeline中或者被从ChannelPipeline中移除时会调用这些操作。这些方法中的每一个都接受一个ChannelHandlerContext参数。
表6-2 ChannelHandler的生命周期方法 类 型 描 述 handlerAdded 当把 ChannelHandler添加到ChannelPipeline中时被调用 handlerRemoved 当从 ChannelPipeline中移除ChannelHandler时被调用 exceptionCaught
当处理过程中在 ChannelPipeline中有错误产生时被调用 Netty定义了下面两个重要的ChannelHandler子接口: ChannelInboundHandler——处理入站数据以及各种状态变化; ChannelOutboundHandler——处理出站数据并且允许拦截所有的操作。
在接下来的章节中,我们将详细地讨论这些子接口。
6.1.3 ChannelInboundHandler接口
表6-3列出了interface ChannelInboundHandler的生命周期方法。这些方法将会在数据被接收时或者与其对应的Channel状态发生改变时被调用。正如我们前面所提到的,这些方法和Channel的生命周期密切相关。
表6-3 ChannelInboundHandler的方法 类 型 描 述 channelRegistered 当 Channel已经注册到它的EventLoop并且能够处理I/O时被调用 channelUnregistered 当 Channel从它的EventLoop注销并且无法处理任何I/O时被调用 channelActive 当 Channel处于活动状态时被调用;Channel已经连接/绑定并且已经就绪 channelInactive 当 Channel离开活动状态并且不再连接它的远程节点时被调用 channelReadComplete 当 Channel上的一个读操作完成时被调用[1] channelRead 当从 Channel读取数据时被调用 ChannelWritability - Changed 当 Channel的可写状态发生改变时被调用。用户可以确保写操作不会完成得太快(以避免发生OutOfMemoryError)或者可以在Channel变为再次可写时恢复写入。可以通过调用Channel的isWritable()方法来检测Channel的可写性。与可写性相关的阈值可以通过Channel.config(). setWriteHighWaterMark()和Channel.config().setWriteLowWater- Mark()方法来设置 userEventTriggered 当 ChannelnboundHandler.fireUserEventTriggered()方法被调用时被调用,因为一个POJO被传经了ChannelPipeline 当某个ChannelInboundHandler的实现重写channelRead()方法时,它将负责显式地释放与池化的ByteBuf实例相关的内存。Netty为此提供了一个实用方法ReferenceCount-Util.release(),如代码清单6-1所示。 代码
清单6-1 释放消息资源 @Sharable public class DiscardHandler extends ChannelInboundHandlerAdapter { ← — 扩展了Channel-InboundHandler-Adapter @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { ← — 丢弃已接收的消息 ReferenceCountUtil.release(msg); } } Netty将使用WARN级别的日志消息记录未释放的资源,使得可以非常简单地在代码中发现违规的实例。但是以这种方式管理资源可能很繁琐。一个更加简单的方式是使用Simple- ChannelInboundHandler。代码清单6-2是代码清单6-1的一个变体,说明了这一点。 代码清单6-2 使用SimpleChannelInboundHandler @Sharable public class SimpleDiscardHandler extends SimpleChannelInboundHandler
6.1.4 ChannelOutboundHandler接口
出站操作和数据将由ChannelOutboundHandler处理。它的方法将被Channel、Channel- Pipeline以及ChannelHandlerContext调用。 ChannelOutboundHandler的一个强大的功能是可以按需推迟操作或者事件,这使得可以通过一些复杂的方法来处理请求。例如,如果到远程节点的写入被暂停了,那么你可以推迟冲刷操作并在稍后继续。 表6-4显示了所有由ChannelOutboundHandler本身所定义的方法(忽略了那些从Channel- Handler继承的方法)。 表6-4 ChannelOutboundHandler的方法 类 型 描 述 bind(ChannelHandlerContext, SocketAddress,ChannelPromise) 当请求将 Channel绑定到本地地址时被调用 connect(ChannelHandlerContext, SocketAddress,SocketAddress,ChannelPromise) 当请求将 Channel连接到远程节点时被调用 disconnect(ChannelHandlerContext, ChannelPromise) 当请求将 Channel从远程节点断开时被调用 close(ChannelHandlerContext,ChannelPromise) 当请求关闭 Channel时被调用 deregister(ChannelHandlerContext, ChannelPromise) 当请求将 Channel从它的EventLoop注销时被调用 read(ChannelHandlerContext) 当请求从 Channel读取更多的数据时被调用 flush(ChannelHandlerContext) 当请求通过 Channel将入队数据冲刷到远程节点时被调用 write(ChannelHandlerContext,Object, ChannelPromise) 当请求通过 Channel将数据写到远程节点时被调用 ChannelPromise与ChannelFuture ChannelOutboundHandler中的大部分方法都需要一个ChannelPromise参数,以便在操作完成时得到通知。ChannelPromise是ChannelFuture的一个子类,其定义了一些可写的方法,如setSuccess()和setFailure(),从而使ChannelFuture不可变[2]。 接下来我们将看一看那些简化了编写ChannelHandler的任务的类。
6.1.5 ChannelHandler适配器
你可以使用ChannelInboundHandlerAdapter和ChannelOutboundHandlerAdapter类作为自己的ChannelHandler的起始点。这两个适配器分别提供了ChannelInboundHandler和ChannelOutboundHandler的基本实现。通过扩展抽象类ChannelHandlerAdapter,它们获得了它们共同的超接口ChannelHandler的方法。生成的类的层次结构如图6-2所示。 图6-2 ChannelHandlerAdapter类的层次结构 ChannelHandlerAdapter还提供了实用方法isSharable()。如果其对应的实现被标注为Sharable,那么这个方法将返回true,表示它可以被添加到多个ChannelPipeline中(如在2.3.1节中所讨论过的一样)。 在ChannelInboundHandlerAdapter和ChannelOutboundHandlerAdapter中所提供的方法体调用了其相关联的ChannelHandlerContext上的等效方法,从而将事件转发到了ChannelPipeline中的下一个ChannelHandler中。 你要想在自己的ChannelHandler中使用这些适配器类,只需要简单地扩展它们,并且重写那些你想要自定义的方法。
6.1.6 资源管理
每当通过调用ChannelInboundHandler.channelRead()或者ChannelOutbound- Handler.write()方法来处理数据时,你都需要确保没有任何的资源泄漏。你可能还记得在前面的章节中所提到的,Netty使用引用计数来处理池化的ByteBuf。所以在完全使用完某个ByteBuf后,调整其引用计数是很重要的。 为了帮助你诊断潜在的(资源泄漏)问题,Netty提供了class ResourceLeakDetector[3],它将对你应用程序的缓冲区分配做大约1%的采样来检测内存泄露。相关的开销是非常小的。 如果检测到了内存泄露,将会产生类似于下面的日志消息: LEAK: ByteBuf.release() was not called before it’s garbage-collected. Enable advanced leak reporting to find out where the leak occurred. To enable advanced leak reporting, specify the JVM option ‘-Dio.netty.leakDetectionLevel=ADVANCED’ or call ResourceLeakDetector.setLevel(). Netty目前定义了4种泄漏检测级别,如表6-5所示。 表6-5 泄漏检测级别 级 别 描 述 DISABLED 禁用泄漏检测。只有在详尽的测试之后才应设置为这个值 SIMPLE 使用1%的默认采样率检测并报告任何发现的泄露。这是默认级别,适合绝大部分的情况 ADVANCED 使用默认的采样率,报告所发现的任何的泄露以及对应的消息被访问的位置 PARANOID 类似于 ADVANCED,但是其将会对每次(对消息的)访问都进行采样。这对性能将会有很大的影响,应该只在调试阶段使用 泄露检测级别可以通过将下面的Java系统属性设置为表中的一个值来定义: java -Dio.netty.leakDetectionLevel=ADVANCED 如果带着该JVM选项重新启动你的应用程序,你将看到自己的应用程序最近被泄漏的缓冲区被访问的位置。下面是一个典型的由单元测试产生的泄漏报告: Running io.netty.handler.codec.xml.XmlFrameDecoderTest 15:03:36.886 [main] ERROR io.netty.util.ResourceLeakDetector - LEAK: ByteBuf.release() was not called before it’s garbage-collected. Recent access records: 1 #1: io.netty.buffer.AdvancedLeakAwareByteBuf.toString( AdvancedLeakAwareByteBuf.java:697) io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithXml( XmlFrameDecoderTest.java:157) io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithTwoMessages( XmlFrameDecoderTest.java:133) … 实现ChannelInboundHandler.channelRead()和ChannelOutboundHandler.write()方法时,应该如何使用这个诊断工具来防止泄露呢?让我们看看你的channelRead()操作直接消费入站消息的情况;也就是说,它不会通过调用ChannelHandlerContext.fireChannelRead()方法将入站消息转发给下一个ChannelInboundHandler。代码清单6-3展示了如何释放消息。 代码清单6-3 消费并释放入站消息 @Sharable public class DiscardInboundHandler extends ChannelInboundHandlerAdapter { ← — 扩展了ChannelInboundandlerAdapter @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { ReferenceCountUtil.release(msg); ← — 通过调用ReferenceCountUtil.release()方法释放资源 } } 消费入站消息的简单方式 由于消费入站数据是一项常规任务,所以Netty提供了一个特殊的被称为SimpleChannelInboundHandler的ChannelInboundHandler实现。这个实现会在消息被channelRead0()方法消费之后自动释放消息。 在出站方向这边,如果你处理了write()操作并丢弃了一个消息,那么你也应该负责释放它。代码清单6-4展示了一个丢弃所有的写入数据的实现。 代码清单6-4 丢弃并释放出站消息 @Sharable public class DiscardOutboundHandler extends ChannelOutboundHandlerAdapter { ← — 扩展了ChannelOutboundHandlerAdapter @Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) { ReferenceCountUtil.release(msg); ← — 通过使用R eferenceCountUtil.realse(…)方法释放资源 promise.setSuccess(); ← — 通知ChannelPromise数据已经被处理了 } } 重要的是,不仅要释放资源,还要通知ChannelPromise。否则可能会出现Channel-FutureListener收不到某个消息已经被处理了的通知的情况。 总之,如果一个消息被消费或者丢弃了,并且没有传递给ChannelPipeline中的下一个ChannelOutboundHandler,那么用户就有责任调用ReferenceCountUtil.release()。如果消息到达了实际的传输层,那么当它被写入时或者Channel关闭时,都将被自动释放。
6.2 ChannelPipeline接口
如果你认为ChannelPipeline是一个拦截流经Channel的入站和出站事件的Channel-Handler实例链,那么就很容易看出这些ChannelHandler之间的交互是如何组成一个应用程序数据和事件处理逻辑的核心的。 每一个新创建的Channel都将会被分配一个新的ChannelPipeline。这项关联是永久性的;Channel既不能附加另外一个ChannelPipeline,也不能分离其当前的。在Netty组件的生命周期中,这是一项固定的操作,不需要开发人员的任何干预。 根据事件的起源,事件将会被ChannelInboundHandler或者ChannelOutboundHandler处理。随后,通过调用ChannelHandlerContext实现,它将被转发给同一超类型的下一个ChannelHandler。 ChannelHandlerContext ChannelHandlerContext使得ChannelHandler能够和它的ChannelPipeline以及其他的ChannelHandler交互。ChannelHandler可以通知其所属的ChannelPipeline中的下一个ChannelHandler,甚至可以动态修改它所属的ChannelPipeline[4]。 ChannelHandlerContext具有丰富的用于处理事件和执行I/O操作的API。6.3节将提供有关ChannelHandlerContext的更多内容。 图6-3展示了一个典型的同时具有入站和出站ChannelHandler的ChannelPipeline的布局,并且印证了我们之前的关于ChannelPipeline主要由一系列的ChannelHandler所组成的说法。ChannelPipeline还提供了通过ChannelPipeline本身传播事件的方法。如果一个入站事件被触发,它将被从ChannelPipeline的头部开始一直被传播到Channel Pipeline的尾端。在图6-3中,一个出站I/O事件将从ChannelPipeline的最右边开始,然后向左传播。 图6-3 ChannelPipeline和它的ChannelHandler ChannelPipeline相对论 你可能会说,从事件途经ChannelPipeline的角度来看,ChannelPipeline的头部和尾端取决于该事件是入站的还是出站的。然而Netty总是将ChannelPipeline的入站口(图6-3中的左侧)作为头部,而将出站口(该图的右侧)作为尾端。 当你完成了通过调用ChannelPipeline.add*()方法将入站处理器(ChannelInboundHandler)和出站处理器(ChannelOutboundHandler)混合添加到ChannelPipeline之后,每一个ChannelHandler从头部到尾端的顺序位置正如同我们方才所定义它们的一样。因此,如果你将图6-3中的处理器(ChannelHandler)从左到右进行编号,那么第一个被入站事件看到的ChannelHandler将是1,而第一个被出站事件看到的ChannelHandler将是5。 在ChannelPipeline传播事件时,它会测试ChannelPipeline中的下一个Channel- Handler的类型是否和事件的运动方向相匹配。如果不匹配,ChannelPipeline将跳过该ChannelHandler并前进到下一个,直到它找到和该事件所期望的方向相匹配的为止。(当然,ChannelHandler也可以同时实现ChannelInboundHandler接口和ChannelOutbound- Handler接口。)
6.2.1 修改ChannelPipeline
ChannelHandler可以通过添加、删除或者替换其他的ChannelHandler来实时地修改ChannelPipeline的布局。(它也可以将它自己从ChannelPipeline中移除。)这是Channel- Handler最重要的能力之一,所以我们将仔细地来看看它是如何做到的。表6-6列出了相关的方法。 表6-6 ChannelPipeline上的相关方法,由ChannelHandler用来修改ChannelPipeline的布局 名 称 描 述 addFirst addBefore addAfter addLast 将一个 ChannelHandler添加到ChannelPipeline中 remove 将一个 ChannelHandler从ChannelPipeline中移除 replace 将 ChannelPipeline中的一个ChannelHandler替换为另一个Channel- Handler 代码清单6-5展示了这些方法的使用。 代码清单6-5 修改ChannelPipeline ChannelPipeline pipeline = ..; FirstHandler firstHandler = new FirstHandler(); ← — 创建一个FirstHandler 的实例 pipeline.addLast(“handler1”, firstHandler); ← — 将该实例作为”handler1” 添加到ChannelPipeline 中 pipeline.addFirst(“handler2”, new SecondHandler()); ← — 将一个SecondHandler的实例作为”handler2”添加到ChannelPipeline的第一个槽中。这意味着它将被放置在已有的”handler1”之前 pipeline.addLast(“handler3”, new ThirdHandler()); ← — 将一个ThirdHandler 的实例作为”handler3”添加到ChannelPipeline 的最后一个槽中 … pipeline.remove(“handler3”); ← — 通过名称移除”handler3” pipeline.remove(firstHandler); ← — 通过引 用移除FirstHandler(它是唯一的,所以不需要它的名称) pipeline.replace(“handler2”, “handler4”, new ForthHandler()); ← — 将SecondHandler(“handler2”)替换为FourthHandler:”handler4” 稍后,你将看到,重组ChannelHandler的这种能力使我们可以用它来轻松地实现极其灵活的逻辑。 ChannelHandler的执行和阻塞 通常ChannelPipeline中的每一个ChannelHandler都是通过它的EventLoop(I/O线程)来处理传递给它的事件的。所以至关重要的是不要阻塞这个线程,因为这会对整体的I/O处理产生负面的影响。 但有时可能需要与那些使用阻塞API的遗留代码进行交互。对于这种情况,ChannelPipeline有一些接受一个EventExecutorGroup的add()方法。如果一个事件被传递给一个自定义的EventExecutor- Group,它将被包含在这个EventExecutorGroup中的某个EventExecutor所处理,从而被从该Channel本身的EventLoop中移除。对于这种用例,Netty提供了一个叫DefaultEventExecutor- Group的默认实现。 除了这些操作,还有别的通过类型或者名称来访问ChannelHandler的方法。这些方法都列在了表6-7中。 表6-7 ChannelPipeline的用于访问ChannelHandler的操作 名 称 描 述 get 通过类型或者名称返回 ChannelHandler context 返回和 ChannelHandler绑定的ChannelHandlerContext names 返回 ChannelPipeline中所有ChannelHandler的名称
6.2.2 触发事件
ChannelPipeline的API公开了用于调用入站和出站操作的附加方法。表6-8列出了入站操作,用于通知ChannelInboundHandler在ChannelPipeline中所发生的事件。 表6-8 ChannelPipeline的入站操作 方 法 名 称 描 述 fireChannelRegistered 调用 ChannelPipeline中下一个ChannelInboundHandler的channelRegistered(ChannelHandlerContext)方法 fireChannelUnregistered 调用 ChannelPipeline中下一个ChannelInboundHandler的channelUnregistered(ChannelHandlerContext)方法 fireChannelActive 调用 ChannelPipeline中下一个ChannelInboundHandler的channelActive(ChannelHandlerContext)方法 fireChannelInactive 调用 ChannelPipeline中下一个ChannelInboundHandler的channelInactive(ChannelHandlerContext)方法 fireExceptionCaught 调用 ChannelPipeline中下一个ChannelInboundHandler的exceptionCaught(ChannelHandlerContext, Throwable)方法 fireUserEventTriggered 调用 ChannelPipeline中下一个ChannelInboundHandler的userEventTriggered(ChannelHandlerContext, Object)方法 fireChannelRead 调用 ChannelPipeline中下一个ChannelInboundHandler的channelRead(ChannelHandlerContext, Object msg)方法 fireChannelReadComplete 调用 ChannelPipeline中下一个ChannelInboundHandler的channelReadComplete(ChannelHandlerContext)方法 fireChannelWritability - Changed 调用 ChannelPipeline中下一个ChannelInboundHandler的channelWritabilityChanged(ChannelHandlerContext)方法 在出站这边,处理事件将会导致底层的套接字上发生一系列的动作。表6-9列出了Channel- Pipeline API的出站操作。 表6-9 ChannelPipeline的出站操作 方 法 名 称 描 述 bind 将 Channel绑定到一个本地地址,这将调用ChannelPipeline中的下一个ChannelOutboundHandler的bind(ChannelHandlerContext, Socket- Address, ChannelPromise)方法 connect 将 Channel连接到一个远程地址,这将调用ChannelPipeline中的下一个ChannelOutboundHandler的connect(ChannelHandlerContext, Socket- Address, ChannelPromise)方法 disconnect 将 Channel断开连接。这将调用ChannelPipeline中的下一个ChannelOutbound- Handler的disconnect(ChannelHandlerContext, Channel Promise)方法 close 将 Channel关闭。这将调用ChannelPipeline中的下一个ChannelOutbound- Handler的close(ChannelHandlerContext, ChannelPromise)方法 deregister 将 Channel从它先前所分配的EventExecutor(即EventLoop)中注销。这将调用ChannelPipeline中的下一个ChannelOutboundHandler的deregister (ChannelHandlerContext, ChannelPromise)方法 flush 冲刷 Channel所有挂起的写入。这将调用ChannelPipeline中的下一个Channel- OutboundHandler的flush(ChannelHandlerContext)方法 write 将消息写入 Channel。这将调用ChannelPipeline中的下一个Channel- OutboundHandler的write(ChannelHandlerContext, Object msg, Channel- Promise)方法。注意:这并不会将消息写入底层的Socket,而只会将它放入队列中。要将它写入Socket,需要调用flush()或者writeAndFlush()方法 writeAndFlush 这是一个先调用 write()方法再接着调用flush()方法的便利方法 read 请求从 Channel中读取更多的数据。这将调用ChannelPipeline中的下一个ChannelOutboundHandler的read(ChannelHandlerContext)方法 总结一下: ChannelPipeline保存了与Channel相关联的ChannelHandler; ChannelPipeline可以根据需要,通过添加或者删除ChannelHandler来动态地修改; ChannelPipeline有着丰富的API用以被调用,以响应入站和出站事件。
6.3 ChannelHandlerContext接口
ChannelHandlerContext代表了ChannelHandler和ChannelPipeline之间的关联,每当有ChannelHandler添加到ChannelPipeline中时,都会创建ChannelHandler- Context。ChannelHandlerContext的主要功能是管理它所关联的ChannelHandler和在同一个ChannelPipeline中的其他ChannelHandler之间的交互。 ChannelHandlerContext有很多的方法,其中一些方法也存在于Channel和Channel- Pipeline本身上,但是有一点重要的不同。如果调用Channel或者ChannelPipeline上的这些方法,它们将沿着整个ChannelPipeline进行传播。而调用位于ChannelHandlerContext上的相同方法,则将从当前所关联的ChannelHandler开始,并且只会传播给位于该ChannelPipeline中的下一个能够处理该事件的ChannelHandler。 表6-10对ChannelHandlerContext API进行了总结。 表6-10 ChannelHandlerContext的API 方 法 名 称 描 述 alloc 返回和这个实例相关联的 Channel所配置的ByteBufAllocator bind 绑定到给定的 SocketAddress,并返回ChannelFuture channel 返回绑定到这个实例的 Channel close 关闭 Channel,并返回ChannelFuture connect 连接给定的 SocketAddress,并返回ChannelFuture deregister 从之前分配的 EventExecutor注销,并返回ChannelFuture disconnect 从远程节点断开,并返回 ChannelFuture executor 返回调度事件的 EventExecutor fireChannelActive 触发对下一个 ChannelInboundHandler上的channelActive()方法(已连接)的调用 fireChannelInactive 触发对下一个 ChannelInboundHandler上的channelInactive()方法(已关闭)的调用 fireChannelRead 触发对下一个 ChannelInboundHandler上的channelRead()方法(已接收的消息)的调用 fireChannelReadComplete 触发对下一个 ChannelInboundHandler上的channelReadComplete()方法的调用 fireChannelRegistered 触发对下一个 ChannelInboundHandler上的fireChannelRegistered()方法的调用 fireChannelUnregistered 触发对下一个 ChannelInboundHandler上的fireChannelUnregistered()方法的调用 fireChannelWritabilityChanged 触发对下一个 ChannelInboundHandler上的fireChannelWritabilityChanged()方法的调用 fireExceptionCaught 触发对下一个 ChannelInboundHandler上的fireExceptionCaught(Throwable)方法的调用 fireUserEventTriggered 触发对下一个 ChannelInboundHandler上的fireUserEventTriggered(Object evt)方法的调用 handler 返回绑定到这个实例的 ChannelHandler isRemoved 如果所关联的 ChannelHandler已经被从ChannelPipeline中移除则返回true name 返回这个实例的唯一名称 pipeline 返回这个实例所关联的 ChannelPipeline read 将数据从 Channel读取到第一个入站缓冲区;如果读取成功则触发[5]一个channelRead事件,并(在最后一个消息被读取完成后)通知ChannelInboundHandler的channelReadComplete (ChannelHandlerContext)方法 write 通过这个实例写入消息并经过 ChannelPipeline writeAndFlush 通过这个实例写入并冲刷消息并经过 ChannelPipeline 当使用ChannelHandlerContext的API的时候,请牢记以下两点: ChannelHandlerContext和ChannelHandler之间的关联(绑定)是永远不会改变的,所以缓存对它的引用是安全的; 如同我们在本节开头所解释的一样,相对于其他类的同名方法,ChannelHandlerContext的方法将产生更短的事件流,应该尽可能地利用这个特性来获得最大的性能。
6.3.1 使用ChannelHandlerContext
在这一节中我们将讨论ChannelHandlerContext的用法,以及存在于ChannelHandler- Context、Channel和ChannelPipeline上的方法的行为。图6-4展示了它们之间的关系。 图6-4 Channel、ChannelPipeline、ChannelHandler以及ChannelHandlerContext之间的关系 在代码清单6-6中,将通过ChannelHandlerContext获取到Channel的引用。调用Channel上的write()方法将会导致写入事件从尾端到头部地流经ChannelPipeline。 代码清单6-6 从ChannelHandlerContext访问Channel ChannelHandlerContext ctx = ..; Channel channel = ctx.channel(); ← — 获取到与ChannelHandlerContext相关联的Channel 的引用 channel.write(Unpooled.copiedBuffer(“Netty in Action”, ← — 通过Channel 写入缓冲区 CharsetUtil.UTF_8)); 代码清单6-7展示了一个类似的例子,但是这一次是写入ChannelPipeline。我们再次看到,(到ChannelPipline的)引用是通过ChannelHandlerContext获取的。 代码清单6-7 通过ChannelHandlerContext访问ChannelPipeline ChannelHandlerContext ctx = ..; ChannelPipeline pipeline = ctx.pipeline(); ← — 获取到与ChannelHandlerContext相关联的ChannelPipeline 的引用 pipeline.write(Unpooled.copiedBuffer(“Netty in Action”, ← — 通过ChannelPipeline写入缓冲区 CharsetUtil.UTF_8)); 如同在图6-5中所能够看到的一样,代码清单6-6和代码清单6-7中的事件流是一样的。重要的是要注意到,虽然被调用的Channel或ChannelPipeline上的write()方法将一直传播事件通过整个ChannelPipeline,但是在ChannelHandler的级别上,事件从一个ChannelHandler到下一个ChannelHandler的移动是由ChannelHandlerContext上的调用完成的。 图6-5 通过Channel或者ChannelPipeline进行的事件传播 为什么会想要从ChannelPipeline中的某个特定点开始传播事件呢? 为了减少将事件传经对它不感兴趣的ChannelHandler所带来的开销。 为了避免将事件传经那些可能会对它感兴趣的ChannelHandler。 要想调用从某个特定的ChannelHandler开始的处理过程,必须获取到在(Channel- Pipeline)该ChannelHandler之前的ChannelHandler所关联的ChannelHandler- Context。这个ChannelHandlerContext将调用和它所关联的ChannelHandler之后的ChannelHandler。 代码清单6-8和图6-6说明了这种用法。 代码清单6-8 调用ChannelHandlerContext的write()方法 ChannelHandlerContext ctx = ..; ← — 获取到ChannelHandlerContext的引用 ctx.write(Unpooled.copiedBuffer(“Netty in Action”, CharsetUtil.UTF_8)); ← — write()方法将把缓冲区数据发送到下一个ChannelHandler 如图6-6所示,消息将从下一个ChannelHandler开始流经ChannelPipeline,绕过了所有前面的ChannelHandler。 图6-6 通过ChannelHandlerContext触发的操作的事件流 我们刚才所描述的用例是常见的,对于调用特定的ChannelHandler实例上的操作尤其有用。
6.3.2 ChannelHandler和ChannelHandlerContext的高级用法
正如我们在代码清单6-6中所看到的,你可以通过调用ChannelHandlerContext上的pipeline()方法来获得被封闭的ChannelPipeline的引用。这使得运行时得以操作ChannelPipeline的ChannelHandler,我们可以利用这一点来实现一些复杂的设计。例如,你可以通过将ChannelHandler添加到ChannelPipeline中来实现动态的协议切换。 另一种高级的用法是缓存到ChannelHandlerContext的引用以供稍后使用,这可能会发生在任何的ChannelHandler方法之外,甚至来自于不同的线程。代码清单6-9展示了用这种模式来触发事件。 代码清单6-9 缓存到ChannelHandlerContext的引用 public class WriteHandler extends ChannelHandlerAdapter { private ChannelHandlerContext ctx; @Override public void handlerAdded(ChannelHandlerContext ctx) { this.ctx = ctx; ← — 存储到ChannelHandlerContext的引用以供稍后使用 } public void send(String msg) { ← — 使用之前存储的到ChannelHandlerContext的引用来发送消息 ctx.writeAndFlush(msg); } } 因为一个ChannelHandler可以从属于多个ChannelPipeline,所以它也可以绑定到多个ChannelHandlerContext实例。对于这种用法指在多个ChannelPipeline中共享同一个ChannelHandler,对应的ChannelHandler必须要使用@Sharable注解标注;否则,试图将它添加到多个ChannelPipeline时将会触发异常。显而易见,为了安全地被用于多个并发的Channel(即连接),这样的ChannelHandler必须是线程安全的。 代码清单6-10展示了这种模式的一个正确实现。 代码清单6-10 可共享的ChannelHandler @Sharable public class SharableHandler extends ChannelInboundHandlerAdapter { ← — 使用注解@Sharable标注 @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { System.out.println(“Channel read message: “ + msg); ctx.fireChannelRead(msg); ← — 记录方法调用,并转发给下一个ChannelHandler } } 前面的ChannelHandler实现符合所有的将其加入到多个ChannelPipeline的需求,即它使用了注解@Sharable标注,并且也不持有任何的状态。相反,代码清单6-11中的实现将会导致问题。 代码清单6-11 @Sharable的错误用法 @Sharable ← — 使用注解@Sharable标注 public class UnsharableHandler extends ChannelInboundHandlerAdapter { private int count; @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { count++; ← — 将count 字段的值加1 System.out.println(“channelRead(…) called the “ + count + “ time”); ← — 记录方法调用,并转发给下一个ChannelHandler ctx.fireChannelRead(msg); } } 这段代码的问题在于它拥有状态[6],即用于跟踪方法调用次数的实例变量count。将这个类的一个实例添加到ChannelPipeline将极有可能在它被多个并发的Channel访问时导致问题。(当然,这个简单的问题可以通过使channelRead()方法变为同步方法来修正。) 总之,只应该在确定了你的ChannelHandler是线程安全的时才使用@Sharable注解。 为何要共享同一个ChannelHandler 在多个ChannelPipeline中安装同一个ChannelHandler的一个常见的原因是用于收集跨越多个Channel的统计信息。 我们对于ChannelHandlerContext和它与其他的框架组件之间的关系的讨论到此就结束了。接下来我们将看看异常处理。
6.4 异常处理 异常处理是任何真实应用程序的重要组成部分,它也可以通过多种方式来实现。因此,Netty提供了几种方式用于处理入站或者出站处理过程中所抛出的异常。这一节将帮助你了解如何设计最适合你需要的方式。
6.4.1 处理入站异常
如果在处理入站事件的过程中有异常被抛出,那么它将从它在ChannelInboundHandler里被触发的那一点开始流经ChannelPipeline。要想处理这种类型的入站异常,你需要在你的ChannelInboundHandler实现中重写下面的方法。 public void exceptionCaught( ChannelHandlerContext ctx, Throwable cause) throws Exception 代码清单6-12展示了一个简单的示例,其关闭了Channel并打印了异常的栈跟踪信息。 代码清单6-12 基本的入站异常处理 public class InboundExceptionHandler extends ChannelInboundHandlerAdapter { @Override public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) { cause.printStackTrace(); ctx.close(); } } 因为异常将会继续按照入站方向流动(就像所有的入站事件一样),所以实现了前面所示逻辑的ChannelInboundHandler通常位于ChannelPipeline的最后。这确保了所有的入站异常都总是会被处理,无论它们可能会发生在ChannelPipeline中的什么位置。 你应该如何响应异常,可能很大程度上取决于你的应用程序。你可能想要关闭Channel(和连接),也可能会尝试进行恢复。如果你不实现任何处理入站异常的逻辑(或者没有消费该异常),那么Netty将会记录该异常没有被处理的事实[7]。 总结一下: ChannelHandler.exceptionCaught()的默认实现是简单地将当前异常转发给ChannelPipeline中的下一个ChannelHandler; 如果异常到达了ChannelPipeline的尾端,它将会被记录为未被处理; 要想定义自定义的处理逻辑,你需要重写exceptionCaught()方法。然后你需要决定是否需要将该异常传播出去。
6.4.2 处理出站异常 用于处理出站操作中的正常完成以及异常的选项,都基于以下的通知机制。 每个出站操作都将返回一个ChannelFuture。注册到ChannelFuture的Channel- FutureListener将在操作完成时被通知该操作是成功了还是出错了。 几乎所有的ChannelOutboundHandler上的方法都会传入一个ChannelPromise的实例。作为ChannelFuture的子类,ChannelPromise也可以被分配用于异步通知的监听器。但是,ChannelPromise还具有提供立即通知的可写方法: ChannelPromise setSuccess(); ChannelPromise setFailure(Throwable cause); 添加ChannelFutureListener只需要调用ChannelFuture实例上的addListener(ChannelFutureListener)方法,并且有两种不同的方式可以做到这一点。其中最常用的方式是,调用出站操作(如write()方法)所返回的ChannelFuture上的addListener()方法。 代码清单6-13使用了这种方式来添加ChannelFutureListener,它将打印栈跟踪信息并且随后关闭Channel。 代码清单6-13 添加ChannelFutureListener到ChannelFuture ChannelFuture future = channel.write(someMessage); future.addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture f) { if (!f.isSuccess()) { f.cause().printStackTrace(); f.channel().close(); } } }); 第二种方式是将ChannelFutureListener添加到即将作为参数传递给ChannelOut- boundHandler的方法的ChannelPromise。代码清单6-14中所展示的代码和代码清单6-13中所展示的具有相同的效果。 代码清单6-14 添加ChannelFutureListener到ChannelPromise public class OutboundExceptionHandler extends ChannelOutboundHandlerAdapter { @Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) { promise.addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture f) { if (!f.isSuccess()) { f.cause().printStackTrace(); f.channel().close(); } } }); } } ChannelPromise的可写方法 通过调用ChannelPromise上的setSuccess()和setFailure()方法,可以使一个操作的状态在ChannelHandler的方法返回给其调用者时便即刻被感知到。 为何选择一种方式而不是另一种呢?对于细致的异常处理,你可能会发现,在调用出站操作时添加ChannelFutureListener更合适,如代码清单6-13所示。而对于一般的异常处理,你可能会发现,代码清单6-14所示的自定义的ChannelOutboundHandler实现的方式更加的简单。 如果你的ChannelOutboundHandler本身抛出了异常会发生什么呢?在这种情况下,Netty本身会通知任何已经注册到对应ChannelPromise的监听器。
6.5 小结
在本章中我们仔细地研究了Netty的数据处理组件——ChannelHandler。我们讨论了ChannelHandler是如何链接在一起,以及它们是如何作为ChannelInboundHandler和ChannelOutboundHandler与ChannelPipeline进行交互的。 下一章将介绍Netty的EventLoop和并发模型,这对于理解Netty是如何实现异步的、事件驱动的网络编程模型来说至关重要。
第7章 EventLoop和线程模型
本章主要内容 线程模型概述 事件循环的概念和实现 任务调度 实现细节 简单地说,线程模型指定了操作系统、编程语言、框架或者应用程序的上下文中的线程管理的关键方面。显而易见地,如何以及何时创建线程将对应用程序代码的执行产生显著的影响,因此开发人员需要理解与不同模型相关的权衡。无论是他们自己选择模型,还是通过采用某种编程语言或者框架隐式地获得它,这都是真实的。 在本章中,我们将详细地探讨Netty的线程模型。它强大但又易用,并且和Netty的一贯宗旨一样,旨在简化你的应用程序代码,同时最大限度地提高性能和可维护性。我们还将讨论致使选择当前线程模型的经验。 如果你对Java的并发API(java.util.concurrent)有比较好的理解,那么你应该会发现在本章中的讨论都是直截了当的。如果这些概念对你来说还比较陌生,或者你需要更新自己的相关知识,那么由Brian Goetz等编写的《Java并发编程实战》 (Addison-Wesley Professional,2006)这本书将是极好的资源。
7.1 线程模型概述
在这一节中,我们将介绍常见的线程模型,随后将继续讨论Netty过去以及当前的线程模型,并评审它们各自的优点以及局限性。 正如我们在本章开头所指出的,线程模型确定了代码的执行方式。由于我们总是必须规避并发执行可能会带来的副作用,所以理解所采用的并发模型(也有单线程的线程模型)的影响很重要。忽略这些问题,仅寄希望于最好的情况(不会引发并发问题)无疑是赌博——赔率必然会击败你。 因为具有多核心或多个CPU的计算机现在已经司空见惯,大多数的现代应用程序都利用了复杂的多线程处理技术以有效地利用系统资源。相比之下,在早期的Java语言中,我们使用多线程处理的主要方式无非是按需创建和启动新的Thread来执行并发的任务单元——一种在高负载下工作得很差的原始方式。Java 5随后引入了ExecutorAPI,其线程池通过缓存和重用Thread极大地提高了性能。 基本的线程池化模式可以描述为: 从池的空闲线程列表中选择一个Thread,并且指派它去运行一个已提交的任务(一个Runnable的实现); 当任务完成时,将该Thread返回给该列表,使其可被重用。 图7-1说明了这个模式。 图7-1 Executor的执行逻辑 虽然池化和重用线程相对于简单地为每个任务都创建和销毁线程是一种进步,但是它并不能消除由上下文切换所带来的开销,其将随着线程数量的增加很快变得明显,并且在高负载下愈演愈烈。此外,仅仅由于应用程序的整体复杂性或者并发需求,在项目的生命周期内也可能会出现其他和线程相关的问题。 简而言之,多线程处理是很复杂的。在接下来的章节中,我们将会看到Netty是如何帮助简化它的。
7.2 EventLoop接口
运行任务来处理在连接的生命周期内发生的事件是任何网络框架的基本功能。与之相应的编程上的构造通常被称为事件循环——一个Netty使用了interface io.netty.channel. EventLoop来适配的术语。 代码清单7-1中说明了事件循环的基本思想,其中每个任务都是一个Runnable的实例(如图7-1所示)。 代码清单7-1 在事件循环中执行任务 while (!terminated) { List readyEvents = blockUntilEventsReady(); ← — 阻塞,直到有事件已经就绪可被运行 for (Runnable ev: readyEvents) { ev.run(); ← — 循环遍历,并处理所有的事件 } } Netty的EventLoop是协同设计的一部分,它采用了两个基本的API:并发和网络编程。首先,io.netty.util.concurrent包构建在JDK的java.util.concurrent包上,用来提供线程执行器。其次,io.netty.channel包中的类,为了与Channel的事件进行交互,扩展了这些接口/类。图7-2展示了生成的类层次结构。 图7-2 EventLoop的类层次结构 在这个模型中,一个EventLoop将由一个永远都不会改变的Thread驱动,同时任务(Runnable或者Callable)可以直接提交给EventLoop实现,以立即执行或者调度执行。根据配置和可用核心的不同,可能会创建多个EventLoop实例用以优化资源的使用,并且单个EventLoop可能会被指派用于服务多个Channel。 需要注意的是,Netty的EventLoop在继承了ScheduledExecutorService的同时,只定义了一个方法,parent()[1]。这个方法,如下面的代码片断所示,用于返回到当前EventLoop实现的实例所属的EventLoopGroup的引用。 public interface EventLoop extends EventExecutor, EventLoopGroup { @Override EventLoopGroup parent(); } 事件/任务的执行顺序 事件和任务是以先进先出(FIFO)的顺序执行的。这样可以通过保证字节内容总是按正确的顺序被处理,消除潜在的数据损坏的可能性。
7.2.1 Netty 4中的I/O和事件处理
正如我们在第6章中所详细描述的,由I/O操作触发的事件将流经安装了一个或者多个ChannelHandler的ChannelPipeline。传播这些事件的方法调用可以随后被Channel- Handler所拦截,并且可以按需地处理事件。 事件的性质通常决定了它将被如何处理;它可能将数据从网络栈中传递到你的应用程序中,或者进行逆向操作,或者执行一些截然不同的操作。但是事件的处理逻辑必须足够的通用和灵活,以处理所有可能的用例。因此,在Netty 4中,所有的I/O操作和事件都由已经被分配给了EventLoop的那个Thread来处理[2]。 这不同于Netty 3中所使用的模型。在下一节中,我们将讨论这个早期的模型以及它被替换的原因。
7.2.2 Netty 3中的I/O操作
在以前的版本中所使用的线程模型只保证了入站(之前称为上游)事件会在所谓的I/O线程(对应于Netty 4中的EventLoop)中执行。所有的出站(下游)事件都由调用线程处理,其可能是I/O线程也可能是别的线程。开始看起来这似乎是个好主意,但是已经被发现是有问题的,因为需要在ChannelHandler中对出站事件进行仔细的同步。简而言之,不可能保证多个线程不会在同一时刻尝试访问出站事件。例如,如果你通过在不同的线程中调用Channel.write()方法,针对同一个Channel同时触发出站的事件,就会发生这种情况。 当出站事件触发了入站事件时,将会导致另一个负面影响。当Channel.write()方法导致异常时,需要生成并触发一个exceptionCaught事件。但是在Netty 3的模型中,由于这是一个入站事件,需要在调用线程中执行代码,然后将事件移交给I/O线程去执行,然而这将带来额外的上下文切换。 Netty 4中所采用的线程模型,通过在同一个线程中处理某个给定的EventLoop中所产生的所有事件,解决了这个问题。这提供了一个更加简单的执行体系架构,并且消除了在多个ChannelHandler中进行同步的需要(除了任何可能需要在多个Channel中共享的)。 现在,已经理解了EventLoop的角色,让我们来看看任务是如何被调度执行的吧。
7.3 任务调度
偶尔,你将需要调度一个任务以便稍后(延迟)执行或者周期性地执行。例如,你可能想要注册一个在客户端已经连接了5分钟之后触发的任务。一个常见的用例是,发送心跳消息到远程节点,以检查连接是否仍然还活着。如果没有响应,你便知道可以关闭该Channel了。 在接下来的几节中,我们将展示如何使用核心的Java API和Netty的EventLoop来调度任务。然后,我们将研究Netty的内部实现,并讨论它的优点和局限性。
7.3.1 JDK的任务调度API
在Java 5之前,任务调度是创建在java.util.Timer类之上的,其使用了一个后台Thread,并且具有与标准线程相同的限制。随后,JDK提供了java.util.concurrent包,它定义了interface ScheduledExecutorService。表7-1展示了java.util.concurrent.Executors的相关工厂方法。 表7-1 java.util.concurrent.Executors类的工厂方法 方 法 描 述 newScheduledThreadPool( int corePoolSize) newScheduledThreadPool( int corePoolSize, ThreadFactorythreadFactory) 创建一个 ScheduledThreadExecutorService,用于调度命令在指定延迟之后运行或者周期性地执行。它使用corePoolSize参数来计算线程数 newSingleThreadScheduledExecutor() newSingleThreadScheduledExecutor( ThreadFactorythreadFactory) 创建一个 ScheduledThreadExecutorService,用于调度命令在指定延迟之后运行或者周期性地执行。它使用一个线程来执行被调度的任务 虽然选择不是很多[3],但是这些预置的实现已经足以应对大多数的用例。代码清单7-2展示了如何使用ScheduledExecutorService来在60秒的延迟之后执行一个任务。 代码清单7-2 使用ScheduledExecutorService调度任务 ScheduledExecutorService executor = Executors.newScheduledThreadPool(10); ← — 创建一个其线程池具有10 个线程的ScheduledExecutorService ScheduledFuture<?> future = executor.schedule( new Runnable() { ← — 创建一个R unnable,以供调度稍后执行 @Override public void run() { System.out.println(“60 seconds later”); ← — 该任务要打印的消息 } }, 60, TimeUnit.SECONDS); ← — 调度任务在从现在开始的60 秒之后执行 … executor.shutdown(); ← — 一旦调度任务执行完成,就关闭ScheduledExecutorService 以释放资源 虽然ScheduledExecutorServiceAPI是直截了当的,但是在高负载下它将带来性能上的负担。在下一节中,我们将看到Netty是如何以更高的效率提供相同的功能的。
7.3.2 使用EventLoop调度任务
ScheduledExecutorService的实现具有局限性,例如,事实上作为线程池管理的一部分,将会有额外的线程创建。如果有大量任务被紧凑地调度,那么这将成为一个瓶颈。Netty通过Channel的EventLoop实现任务调度解决了这一问题,如代码清单7-3所示。 代码清单7-3 使用EventLoop调度任务 Channel ch = … ScheduledFuture future = ch.eventLoop().schedule( ← — 创建一个Runnable以供调度稍后执行 new Runnable() { @Override public void run() { ← — 要执行的代码 System.out.println(“60 seconds later”); } }, 60, TimeUnit.SECONDS); ← — 调度任务在从现在开始的60 秒之后执行 经过60秒之后,Runnable实例将由分配给Channel的EventLoop执行。如果要调度任务以每隔60秒执行一次,请使用scheduleAtFixedRate()方法,如代码清单7-4所示。 代码清单7-4 使用EventLoop调度周期性的任务 Channel ch = … ScheduledFuture future = ch.eventLoop().scheduleAtFixedRate( ← — 创建一个Runnable,以供调度稍后执行 new Runnable() { @Override public void run() { System.out.println(“Run every 60 seconds”); ← — 这将一直运行,直到ScheduledFuture 被取消 } }, 60, 60, TimeUnit.Seconds); ← — 调度在60 秒之后,并且以后每间隔60 秒运行 如我们前面所提到的,Netty的EventLoop扩展了ScheduledExecutorService(见图7-2),所以它提供了使用JDK实现可用的所有方法,包括在前面的示例中使用到的schedule()和scheduleAtFixedRate()方法。所有操作的完整列表可以在ScheduledExecutorService的Javadoc中找到[4]。 要想取消或者检查(被调度任务的)执行状态,可以使用每个异步操作所返回的Scheduled- Future。代码清单7-5展示了一个简单的取消操作。 代码清单7-5 使用ScheduledFuture取消任务 ScheduledFuture<?> future = ch.eventLoop().scheduleAtFixedRate(…); ← — 调度任务,并获得所返回的ScheduledFuture // Some other code that runs… boolean mayInterruptIfRunning = false; future.cancel(mayInterruptIfRunning); ← — 取消该任务,防止它再次运行 这些例子说明,可以利用Netty的任务调度功能来获得性能上的提升。反过来,这些也依赖于底层的线程模型,我们接下来将对其进行研究。
7.4 实现细节
这一节将更加详细地探讨Netty的线程模型和任务调度实现的主要内容。我们也将会提到需要注意的局限性,以及正在不断发展中的领域。
7.4.1 线程管理
Netty线程模型的卓越性能取决于对于当前执行的Thread的身份的确定[5],也就是说,确定它是否是分配给当前Channel以及它的EventLoop的那一个线程。(回想一下EventLoop将负责处理一个Channel的整个生命周期内的所有事件。) 如果(当前)调用线程正是支撑EventLoop的线程,那么所提交的代码块将会被(直接)执行。否则,EventLoop将调度该任务以便稍后执行,并将它放入到内部队列中。当EventLoop下次处理它的事件时,它会执行队列中的那些任务/事件。这也就解释了任何的Thread是如何与Channel直接交互而无需在ChannelHandler中进行额外同步的。 注意,每个EventLoop都有它自已的任务队列,独立于任何其他的EventLoop。图7-3展示了EventLoop用于调度任务的执行逻辑。这是Netty线程模型的关键组成部分。 图7-3 EventLoop的执行逻辑 我们之前已经阐明了不要阻塞当前I/O线程的重要性。我们再以另一种方式重申一次:“永远不要将一个长时间运行的任务放入到执行队列中,因为它将阻塞需要在同一线程上执行的任何其他任务。”如果必须要进行阻塞调用或者执行长时间运行的任务,我们建议使用一个专门的EventExecutor。(见6.2.1节的“ChannelHandler的执行和阻塞”)。 除了这种受限的场景,如同传输所采用的不同的事件处理实现一样,所使用的线程模型也可以强烈地影响到排队的任务对整体系统性能的影响。(如同我们在第4章中所看到的,使用Netty可以轻松地切换到不同的传输实现,而不需要修改你的代码库。)
7.4.2 EventLoop/线程的分配
服务于Channel的I/O和事件的EventLoop包含在EventLoopGroup中。根据不同的传输实现,EventLoop的创建和分配方式也不同。 1.异步传输 异步传输实现只使用了少量的EventLoop(以及和它们相关联的Thread),而且在当前的线程模型中,它们可能会被多个Channel所共享。这使得可以通过尽可能少量的Thread来支撑大量的Channel,而不是每个Channel分配一个Thread。 图7-4显示了一个EventLoopGroup,它具有3个固定大小的EventLoop(每个EventLoop都由一个Thread支撑)。在创建EventLoopGroup时就直接分配了EventLoop(以及支撑它们的Thread),以确保在需要时它们是可用的。 图7-4 用于非阻塞传输(如NIO和AIO)的EventLoop分配方式 EventLoopGroup负责为每个新创建的Channel分配一个EventLoop。在当前实现中,使用顺序循环(round-robin)的方式进行分配以获取一个均衡的分布,并且相同的EventLoop可能会被分配给多个Channel。(这一点在将来的版本中可能会改变。) 一旦一个Channel被分配给一个EventLoop,它将在它的整个生命周期中都使用这个EventLoop(以及相关联的Thread)。请牢记这一点,因为它可以使你从担忧你的Channel- Handler实现中的线程安全和同步问题中解脱出来。 另外,需要注意的是,EventLoop的分配方式对ThreadLocal的使用的影响。因为一个EventLoop通常会被用于支撑多个Channel,所以对于所有相关联的Channel来说,ThreadLocal都将是一样的。这使得它对于实现状态追踪等功能来说是个糟糕的选择。然而,在一些无状态的上下文中,它仍然可以被用于在多个Channel之间共享一些重度的或者代价昂贵的对象,甚至是事件。 2.阻塞传输 用于像OIO(旧的阻塞I/O)这样的其他传输的设计略有不同,如图7-5所示。 这里每一个Channel都将被分配给一个EventLoop(以及它的Thread)。如果你开发的应用程序使用过java.io包中的阻塞I/O实现,你可能就遇到过这种模型。 图7-5 阻塞传输(如OIO)的EventLoop分配方式 但是,正如同之前一样,得到的保证是每个Channel的I/O事件都将只会被一个Thread(用于支撑该Channel的EventLoop的那个Thread)处理。这也是另一个Netty设计一致性的例子,它(这种设计上的一致性)对Netty的可靠性和易用性做出了巨大贡献。
7.5 小结
在本章中,你了解了通常的线程模型,并且特别深入地学习了Netty所采用的线程模型,我们详细探讨了其性能以及一致性。 你看到了如何在EventLoop(I/O Thread)中执行自己的任务,就如同Netty框架自身一样。你学习了如何调度任务以便推迟执行,并且我们还探讨了高负载下的伸缩性问题。你也看到了如何验证一个任务是否已被执行以及如何取消它。 通过我们对Netty框架的实现细节的研究所获得的这些信息,将帮助你在简化你的应用程序代码库的同时最大限度地提高它的性能。关于更多一般意义上的有关线程池和并发编程的详细信息,我们建议阅读由Brian Goetz编写的《Java并发编程实战》。他的书将会带你更加深入地理解多线程处理甚至是最复杂的多线程处理用例。 我们已经到达了一个令人兴奋的时刻——在下一章中我们将讨论引导,这是一个配置以及连接所有的Netty组件使你的应用程序运行起来的过程。
第8章 引导
本章主要内容
引导客户端和服务器
从Channel内引导客户端
添加ChannelHandler 使用ChannelOption和属性[1] 在深入地学习了ChannelPipeline、ChannelHandler和EventLoop之后,你接下来的问题可能是:“如何将这些部分组织起来,成为一个可实际运行的应用程序呢?”
答案是?“引导”(Bootstrapping)。
到目前为止,我们对这个术语的使用还比较含煳,现在已经到了精确定义它的时候了。简单来说,引导一个应用程序是指对它进行配置,并使它运行起来的过程——尽管该过程的具体细节可能并不如它的定义那样简单,尤其是对于一个网络应用程序来说。 和它对应用程序体系架构的做法[2]一致,Netty处理引导的方式使你的应用程序[3]和网络层相隔离,无论它是客户端还是服务器。正如同你将要看到的,所有的框架组件都将会在后台结合在一起并且启用。引导是我们一直以来都在组装的完整拼图[4]中缺失的那一块。当你把它放到正确的位置上时,你的Netty应用程序就完整了。
8.1 Bootstrap类
引导类的层次结构包括一个抽象的父类和两个具体的引导子类,如图8-1所示。
图8-1 引导类的层次结构
相对于将具体的引导类分别看作用于服务器和客户端的引导来说,记住它们的本意是用来支撑不同的应用程序的功能的将有所裨益。也就是说,服务器致力于使用一个父Channel来接受来自客户端的连接,并创建子Channel以用于它们之间的通信;而客户端将最可能只需要一个单独的、没有父Channel的Channel来用于所有的网络交互。(正如同我们将要看到的,这也适用于无连接的传输协议,如UDP,因为它们并不是每个连接都需要一个单独的Channel。) 我们在前面的几章中学习的几个Netty组件都参与了引导的过程,而且其中一些在客户端和服务器都有用到。
两种应用程序类型之间通用的引导步骤由AbstractBootstrap处理,而特定于客户端或者服务器的引导步骤则分别由Bootstrap或ServerBootstrap处理。
在本章中接下来的部分,我们将详细地探讨这两个类,首先从不那么复杂的Bootstrap类开始。
为什么引导类是Cloneable的
你有时可能会需要创建多个具有类似配置或者完全相同配置的Channel。为了支持这种模式而又不需要为每个Channel都创建并配置一个新的引导类实例,AbstractBootstrap被标记为了Cloneable[5]。在一个已经配置完成的引导类实例上调用clone()方法将返回另一个可以立即使用的引导类实例。 注意,这种方式只会创建引导类实例的EventLoopGroup的一个浅拷贝,所以,后者[6]将在所有克隆的Channel实例之间共享。这是可以接受的,因为通常这些克隆的Channel的生命周期都很短暂,一个典型的场景是——创建一个Channel以进行一次HTTP请求。
AbstractBootstrap类的完整声明是: public abstract class AbstractBootstrap ,C extends Channel> 在这个签名中,子类型B是其父类型的一个类型参数,因此可以返回到运行时实例的引用以支持方法的链式调用(也就是所谓的流式语法)。 其子类的声明如下: public class Bootstrap extends AbstractBootstrap
8.2 引导客户端和无连接协议
Bootstrap类被用于客户端或者使用了无连接协议的应用程序中。表8-1提供了该类的一个概览,其中许多方法都继承自AbstractBootstrap类。 表8-1 Bootstrap类的API 名 称 描 述 Bootstrap group(EventLoopGroup) 设置用于处理 Channel所有事件的EventLoopGroup Bootstrap channel( Class<? extends C>) Bootstrap channelFactory( ChannelFactory<? extends C>) channel()方法指定了Channel的实现类。如果该实现类没提供默认的构造函数[7],可以通过调用channel- Factory()方法来指定一个工厂类,它将会被bind()方法调用 Bootstrap localAddress( SocketAddress) 指定 Channel应该绑定到的本地地址。如果没有指定,则将由操作系统创建一个随机的地址。或者,也可以通过bind()或者connect()方法指定localAddress Bootstrap option( ChannelOption option, T value) 设置 ChannelOption,其将被应用到每个新创建的Channel的ChannelConfig。这些选项将会通过bind()或者connect()方法设置到Channel,不管哪个先被调用。这个方法在Channel已经被创建后再调用将不会有任何的效果。支持的ChannelOption取决于使用的Channel类型。参见8.6节以及ChannelConfig的API文档,了解所使用的Channel类型 Bootstrap attr( Attribute key, T value) 指定新创建的 Channel的属性值。这些属性值是通过bind()或者connect()方法设置到Channel的,具体取决于谁最先被调用。这个方法在Channel被创建后将不会有任何的效果。参见8.6节 Bootstrap handler(ChannelHandler) 设置将被添加到 ChannelPipeline以接收事件通知的ChannelHandler Bootstrap clone() 创建一个当前 Bootstrap的克隆,其具有和原始的Bootstrap相同的设置信息 Bootstrap remoteAddress( SocketAddress) 设置远程地址。或者,也可以通过 connect()方法来指定它 ChannelFuture connect() 连接到远程节点并返回一个 ChannelFuture,其将会在连接操作完成后接收到通知 ChannelFuture bind() 绑定 Channel并返回一个ChannelFuture,其将会在绑定操作完成后接收到通知,在那之后必须调用Channel. connect()方法来创建连接 下一节将一步一步地讲解客户端的引导过程。我们也将讨论在选择可用的组件实现时保持兼容性的问题。
8.2.1 引导客户端
Bootstrap类负责为客户端和使用无连接协议的应用程序创建Channel,如图8-2所示。 图8-2 引导过程 代码清单8-1中的代码引导了一个使用NIO TCP传输的客户端。 代码清单8-1 引导一个客户端 EventLoopGroup group = new NioEventLoopGroup(); Bootstrap bootstrap = new Bootstrap(); ← — 创建一个Bootstrap类的实例以创建和连接新的客户端Channel bootstrap.group(group) ← — 设置EventLoopGroup,提供用于处理Channel事件的EventLoop .channel(NioSocketChannel.class) ← — 指定要使用的Channel 实现 .handler(new SimpleChannelInboundHandler() { ← — 设置用于Channel 事件和数据的ChannelInboundHandler @Override protected void channeRead0( ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf) throws Exception { System.out.println(“Received data”); } } ); ChannelFuture future = bootstrap.connect( new InetSocketAddress(“www.manning.com”, 80)); ← — 连接到远程主机 future.addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture channelFuture) throws Exception { if (channelFuture.isSuccess()) { System.out.println(“Connection established”); } else { System.err.println(“Connection attempt failed”); channelFuture.cause().printStackTrace(); } } } ); 这个示例使用了前面提到的流式语法;这些方法(除了connect()方法以外)将通过每次方法调用所返回的对Bootstrap实例的引用链接在一起。
8.2.2 Channel和EventLoopGroup的兼容性
代码清单8-2所示的目录清单来自io.netty.channel包。你可以从包名以及与其相对应的类名的前缀看到,对于NIO以及OIO传输两者来说,都有相关的EventLoopGroup和Channel实现。 代码清单8-2 相互兼容的EventLoopGroup和Channel channel ├───nio │ NioEventLoopGroup ├───oio │ OioEventLoopGroup └───socket ├───nio │ NioDatagramChannel │ NioServerSocketChannel │ NioSocketChannel └───oio OioDatagramChannel OioServerSocketChannel OioSocketChannel 必须保持这种兼容性,不能混用具有不同前缀的组件,如NioEventLoopGroup和OioSocketChannel。代码清单8-3展示了试图这样做的一个例子。 代码清单8-3 不兼容的Channel和EventLoopGroup EventLoopGroup group = new NioEventLoopGroup(); Bootstrap bootstrap = new Bootstrap(); ← — 创建一个新的Bootstrap类的实例,以创建新的客户端Channel bootstrap.group(group) ← — 指定一个适用于NIO 的EventLoopGroup 实现 .channel(OioSocketChannel.class) ← — 指定一个适用于OIO 的Channel实现类 .handler(new SimpleChannelInboundHandler() { ← — 设置一个用于处理Channel的I/O 事件和数据的ChannelInboundHandler @Override protected void channelRead0( ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf) throws Exception { System.out.println(“Received data”); } } ); ChannelFuture future = bootstrap.connect( new InetSocketAddress(“www.manning.com”, 80)); ← — 尝试连接到远程节点 future.syncUninterruptibly(); 这段代码将会导致IllegalStateException,因为它混用了不兼容的传输。 Exception in thread “main” java.lang.IllegalStateException: incompatible event loop type: io.netty.channel.nio.NioEventLoop at io.netty.channel.AbstractChannel$AbstractUnsafe.register( AbstractChannel.java:571) 关于IllegalStateException的更多讨论 在引导的过程中,在调用bind()或者connect()方法之前,必须调用以下方法来设置所需的组件: group(); channel()或者channelFactory(); handler()。 如果不这样做,则将会导致IllegalStateException。对handler()方法的调用尤其重要,因为它需要配置好ChannelPipeline。
8.3 引导服务器
我们将从ServerBootstrap API的概要视图开始我们对服务器引导过程的概述。然后,我们将会探讨引导服务器过程中所涉及的几个步骤,以及几个相关的主题,包含从一个ServerChannel的子Channel中引导一个客户端这样的特殊情况。
8.3.1 ServerBootstrap类
表8-2列出了ServerBootstrap类的方法。 表8-2 ServerBootstrap类的方法 名 称 描 述 group 设置 ServerBootstrap要用的EventLoopGroup。这个EventLoopGroup将用于ServerChannel和被接受的子Channel的I/O处理 channel 设置将要被实例化的 ServerChannel类 channelFactory 如果不能通过默认的构造函数 [8]创建Channel,那么可以提供一个Channel- Factory localAddress 指定 ServerChannel应该绑定到的本地地址。如果没有指定,则将由操作系统使用一个随机地址。或者,可以通过bind()方法来指定该localAddress option 指定要应用到新创建的 ServerChannel的ChannelConfig的Channel- Option。这些选项将会通过bind()方法设置到Channel。在bind()方法被调用之后,设置或者改变ChannelOption都不会有任何的效果。所支持的ChannelOption取决于所使用的Channel类型。参见正在使用的ChannelConfig的API文档 childOption 指定当子 Channel被接受时,应用到子Channel的ChannelConfig的ChannelOption。所支持的ChannelOption取决于所使用的Channel的类型。参见正在使用的ChannelConfig的API文档 attr 指定 ServerChannel上的属性,属性将会通过bind()方法设置给Channel。在调用bind()方法之后改变它们将不会有任何的效果 childAttr 将属性设置给已经被接受的子 Channel。接下来的调用将不会有任何的效果 handler 设置被添加到 ServerChannel的ChannelPipeline中的ChannelHandler。更加常用的方法参见childHandler() childHandler 设置将被添加到已被接受的子 Channel的ChannelPipeline中的Channel- Handler。handler()方法和childHandler()方法之间的区别是:前者所添加的ChannelHandler由接受子Channel的ServerChannel处理,而childHandler()方法所添加的ChannelHandler将由已被接受的子Channel处理,其代表一个绑定到远程节点的套接字 clone 克隆一个设置和原始的 ServerBootstrap相同的ServerBootstrap bind 绑定 ServerChannel并且返回一个ChannelFuture,其将会在绑定操作完成后收到通知(带着成功或者失败的结果) 下一节将介绍服务器引导的详细过程。
8.3.2 引导服务器
你可能已经注意到了,表8-2中列出了一些在表8-1中不存在的方法:childHandler()、childAttr()和childOption()。这些调用支持特别用于服务器应用程序的操作。具体来说,ServerChannel的实现负责创建子Channel,这些子Channel代表了已被接受的连接。因此,负责引导ServerChannel的ServerBootstrap提供了这些方法,以简化将设置应用到已被接受的子Channel的ChannelConfig的任务。 图8-3展示了ServerBootstrap在bind()方法被调用时创建了一个ServerChannel,并且该ServerChannel管理了多个子Channel。 图8-3 ServerBootstrap和ServerChannel 代码清单8-4中的代码实现了图8-3中所展示的服务器的引导过程。 代码清单8-4 引导服务器 NioEventLoopGroup group = new NioEventLoopGroup(); ServerBootstrap bootstrap = new ServerBootstrap(); ← — 创建ServerBootstrap bootstrap.group(group) ← — 设置EventLoopGroup,其提供了用于处理Channel 事件的EventLoop .channel(NioServerSocketChannel.class) ← — 指定要使用的Channel 实现 .childHandler(new SimpleChannelInboundHandler() { ← — 设 置用于处理已被接受的子Channel的I/O及数据的ChannelInbound-Handler @Override protected void channelRead0(ChannelHandlerContext ctx, ByteBuf byteBuf) throws Exception { System.out.println(“Received data”); } } ); ChannelFuture future = bootstrap.bind(new InetSocketAddress(8080)); ← — 通过配置好的ServerBootstrap的实例绑定该Channel future.addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture channelFuture) throws Exception { if (channelFuture.isSuccess()) { System.out.println(“Server bound”); } else { System.err.println(“Bound attempt failed”); channelFuture.cause().printStackTrace(); } } } );
8.4 从Channel引导客户端
假设你的服务器正在处理一个客户端的请求,这个请求需要它充当第三方系统的客户端。当一个应用程序(如一个代理服务器)必须要和组织现有的系统(如Web服务或者数据库)集成时,就可能发生这种情况。在这种情况下,将需要从已经被接受的子Channel中引导一个客户端Channel。 你可以按照8.2.1节中所描述的方式创建新的Bootstrap实例,但是这并不是最高效的解决方案,因为它将要求你为每个新创建的客户端Channel定义另一个EventLoop。这会产生额外的线程,以及在已被接受的子Channel和客户端Channel之间交换数据时不可避免的上下文切换。 一个更好的解决方案是:通过将已被接受的子Channel的EventLoop传递给Bootstrap的group()方法来共享该EventLoop。因为分配给EventLoop的所有Channel都使用同一个线程,所以这避免了额外的线程创建,以及前面所提到的相关的上下文切换。这个共享的解决方案如图8-4所示。 图8-4 在两个Channel之间共享EventLoop 实现EventLoop共享涉及通过调用group()方法来设置EventLoop,如代码清单8-5所示。 代码清单8-5 引导服务器 ServerBootstrap bootstrap = new ServerBootstrap(); ← — 创建ServerBootstrap 以创建ServerSocketChannel,并绑定它 bootstrap.group(new NioEventLoopGroup(), new NioEventLoopGroup()) ← — 设置EventLoopGroup,其将提供用以处理Channel 事件的EventLoop .channel(NioServerSocketChannel.class) ← — 指定要使用的Channel 实现 .childHandler( ← — 设置用于处理已被接受的子Channel 的I/O 和数据的ChannelInboundHandler new SimpleChannelInboundHandler() { ChannelFuture connectFuture; @Override public void channelActive(ChannelHandlerContext ctx) throws Exception { Bootstrap bootstrap = new Bootstrap(); ← — 创建一个Bootstrap类的实例以连接到远程主机 bootstrap.channel(NioSocketChannel.class).handler( ← — 指定Channel的实现 new SimpleChannelInboundHandler () { ← — 为入站I/O 设置ChannelInboundHandler @Override protected void channelRead0( ChannelHandlerContext ctx, ByteBuf in) throws Exception { System.out.println(“Received data”); } } ); bootstrap.group(ctx.channel().eventLoop()); ← — 使用与分配给已被接受的子Channel 相同的EventLoop connectFuture = bootstrap.connect( new InetSocketAddress(“www.manning.com”, 80)); ← — 连接到远程节点 } @Override protected void channelRead0( ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf) throws Exception { if (connectFuture.isDone()) { // do something with the data ← — 当连接完成时,执行一些数据操作(如代理) } } } ); ChannelFuture future = bootstrap.bind(new InetSocketAddress(8080)); ← — 通过配置好的ServerBootstrap绑定该Server-SocketChannel future.addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture channelFuture) throws Exception { if (channelFuture.isSuccess()) { System.out.println(“Server bound”); } else { System.err.println(“Bind attempt failed”); channelFuture.cause().printStackTrace(); } } } ); 我们在这一节中所讨论的主题以及所提出的解决方案都反映了编写Netty应用程序的一个一般准则:尽可能地重用EventLoop,以减少线程创建所带来的开销。
8.5 在引导过程中添加多个ChannelHandler
在所有我们展示过的代码示例中,我们都在引导的过程中调用了handler()或者child- Handler()方法来添加单个的ChannelHandler。这对于简单的应用程序来说可能已经足够了,但是它不能满足更加复杂的需求。例如,一个必须要支持多种协议的应用程序将会有很多的ChannelHandler,而不会是一个庞大而又笨重的类。 正如你经常所看到的一样,你可以根据需要,通过在ChannelPipeline中将它们链接在一起来部署尽可能多的ChannelHandler。但是,如果在引导的过程中你只能设置一个ChannelHandler,那么你应该怎么做到这一点呢? 正是针对于这个用例,Netty提供了一个特殊的ChannelInboundHandlerAdapter子类: public abstract class ChannelInitializer extends ChannelInboundHandlerAdapter 它定义了下面的方法: protected abstract void initChannel(C ch) throws Exception; 这个方法提供了一种将多个ChannelHandler添加到一个ChannelPipeline中的简便方法。你只需要简单地向Bootstrap或ServerBootstrap的实例提供你的Channel-Initializer实现即可,并且一旦Channel被注册到了它的EventLoop之后,就会调用你的initChannel()版本。在该方法返回之后,ChannelInitializer的实例将会从Channel-Pipeline中移除它自己。 代码清单8-6定义了ChannelInitializerImpl类,并通过ServerBootstrap的childHandler()方法注册它[9]。你可以看到,这个看似复杂的操作实际上是相当简单直接的。 代码清单8-6 引导和使用ChannelInitializer ServerBootstrap bootstrap = new ServerBootstrap(); ← — 创建ServerBootstrap 以创建和绑定新的Channel bootstrap.group(new NioEventLoopGroup(), new NioEventLoopGroup()) ← — 设置EventLoopGroup,其将提供用以处理Channel 事件的EventLoop .channel(NioServerSocketChannel.class) ← — 指定Channel 的实现 .childHandler(new ChannelInitializerImpl()); ← — 注册一个ChannelInitializerImpl 的实例来设置ChannelPipeline ChannelFuture future = bootstrap.bind(new InetSocketAddress(8080)); ← — 绑定到地址 future.sync(); final class ChannelInitializerImpl extends ChannelInitializer {[10] ← — 用以设置ChannelPipeline 的自定义ChannelInitializerImpl 实现 @Override protected void initChannel(Channel ch) throws Exception { ← — 将所需的ChannelHandler添加到ChannelPipeline ChannelPipeline pipeline = ch.pipeline(); pipeline.addLast(new HttpClientCodec()); pipeline.addLast(new HttpObjectAggregator(Integer.MAX_VALUE)); } } 如果你的应用程序使用了多个ChannelHandler,请定义你自己的ChannelInitializer实现来将它们安装到ChannelPipeline中。
8.6 使用Netty的ChannelOption和属性
在每个Channel创建时都手动配置它可能会变得相当乏味。幸运的是,你不必这样做。相反,你可以使用option()方法来将ChannelOption应用到引导。你所提供的值将会被自动应用到引导所创建的所有Channel。可用的ChannelOption包括了底层连接的详细信息,如keep-alive或者超时属性以及缓冲区设置。 Netty应用程序通常与组织的专有软件集成在一起,而像Channel这样的组件可能甚至会在正常的Netty生命周期之外被使用。在某些常用的属性和数据不可用时,Netty提供了AttributeMap抽象(一个由Channel和引导类提供的集合)以及AttributeKey(一个用于插入和获取属性值的泛型类)。使用这些工具,便可以安全地将任何类型的数据项与客户端和服务器Channel(包含ServerChannel的子Channel)相关联了。 例如,考虑一个用于跟踪用户和Channel之间的关系的服务器应用程序。这可以通过将用户的ID存储为Channel的一个属性来完成。类似的技术可以被用来基于用户的ID将消息路由给用户,或者关闭活动较少的Channel。 代码清单8-7展示了可以如何使用ChannelOption来配置Channel,以及如果使用属性来存储整型值。 代码清单8-7 使用属性值 final AttributeKey id = AttributeKey.newInstance(“ID”); [11] ← — 创建一个AttributeKey以标识该属性 Bootstrap bootstrap = new Bootstrap(); ← — 创建一个Bootstrap 类的实例以创建客户端Channel 并连接它们 bootstrap.group(new NioEventLoopGroup()) ← — 设置EventLoopGroup,其提供了用以处理Channel事件的EventLoop .channel(NioSocketChannel.class) ← — 指定Channel的实现 .handler( new SimpleChannelInboundHandler() { ← — 设置用以处理Channel 的I/O 以及数据的Channel-InboundHandler @Override public void channelRegistered(ChannelHandlerContext ctx) throws Exception { Integer idValue = ctx.channel().attr(id).get(); ← — 使用AttributeKey 检索属性以及它的值 // do something with the idValue } @Override protected void channelRead0( ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf) throws Exception { System.out.println(“Received data”); } } ); bootstrap.option(ChannelOption.SO_KEEPALIVE,true) .option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000); ← — 设置ChannelOption,其将在connect()或者bind()方法被调用时被设置到已经创建的Channel 上 bootstrap.attr(id, 123456); ← — 存储该id 属性 ChannelFuture future = bootstrap.connect( new InetSocketAddress(“www.manning.com”, 80)); ← — 使用配置好的Bootstrap实例连接到远程主机 future.syncUninterruptibly();
8.7 引导DatagramChannel
前面的引导代码示例使用的都是基于TCP协议的SocketChannel,但是Bootstrap类也可以被用于无连接的协议。为此,Netty提供了各种DatagramChannel的实现。唯一区别就是,不再调用connect()方法,而是只调用bind()方法,如代码清单8-8所示。 代码清单8-8 使用Bootstrap和DatagramChannel Bootstrap bootstrap = new Bootstrap(); ← — 创建一个Bootstrap 的实例以创建和绑定新的数据报Channel bootstrap.group(new OioEventLoopGroup()).channel( ← — 设置EventLoopGroup,其提供了用以处理Channel 事件的EventLoop OioDatagramChannel.class).handler( ← — 指定Channel的实现 new SimpleChannelInboundHandler(){ ← — 设置用以处理Channel 的I/O 以及数据的Channel-InboundHandler @Override public void channelRead0(ChannelHandlerContext ctx, DatagramPacket msg) throws Exception { // Do something with the packet } } ); ChannelFuture future = bootstrap.bind(new InetSocketAddress(0)); ← — 调用bind()方法,因为该协议是无连接的 future.addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture channelFuture) throws Exception { if (channelFuture.isSuccess()) { System.out.println(“Channel bound”); } else { System.err.println(“Bind attempt failed”); channelFuture.cause().printStackTrace(); } } });
8.8 关闭
引导使你的应用程序启动并且运行起来,但是迟早你都需要优雅地将它关闭。当然,你也可以让JVM在退出时处理好一切,但是这不符合优雅的定义,优雅是指干净地释放资源。关闭Netty应用程序并没有太多的魔法,但是还是有些事情需要记在心上。 最重要的是,你需要关闭EventLoopGroup,它将处理任何挂起的事件和任务,并且随后释放所有活动的线程。这就是调用EventLoopGroup.shutdownGracefully()方法的作用。这个方法调用将会返回一个Future,这个Future将在关闭完成时接收到通知。需要注意的是,shutdownGracefully()方法也是一个异步的操作,所以你需要阻塞等待直到它完成,或者向所返回的Future注册一个监听器以在关闭完成时获得通知。 代码清单8-9符合优雅关闭的定义。 代码清单8-9 优雅关闭 EventLoopGroup group = new NioEventLoopGroup(); ← — 创建处理I/O 的EventLoopGroup Bootstrap bootstrap = new Bootstrap(); ← — 创建一个Bootstrap类的实例并配置它 bootstrap.group(group) .channel(NioSocketChannel.class); … Future<?> future = group.shutdownGracefully(); ← — shutdownGracefully()方法将释放所有的资源,并且关闭所有的当前正在使用中的Channel // block until the group has shutdown future.syncUninterruptibly(); 或者,你也可以在调用EventLoopGroup.shutdownGracefully()方法之前,显式地在所有活动的Channel上调用Channel.close()方法。但是在任何情况下,都请记得关闭EventLoopGroup本身。
8.9 小结
在本章中,你学习了如何引导Netty服务器和客户端应用程序,包括那些使用无连接协议的应用程序。我们也涵盖了一些特殊情况,包括在服务器应用程序中引导客户端Channel,以及使用ChannelInitializer来处理引导过程中的多个ChannelHandler的安装。你看到了如何设置Channel的配置选项,以及如何使用属性来将信息附加到Channel。最后,你学习了如何优雅地关闭应用程序,以有序地释放所有的资源。 在下一章中,我们将研究Netty提供的帮助你测试你的ChannelHandler实现的工具。
第10章 编解码器框架
本章主要内容
解码器、编码器以及编解码器的概述
Netty的编解码器类
就像很多标准的架构模式都被各种专用框架所支持一样,常见的数据处理模式往往也是目标实现的很好的候选对象,它可以节省开发人员大量的时间和精力。
当然这也适应于本章的主题:编码和解码,或者数据从一种特定协议的格式到另一种格式的转换。这些任务将由通常称为编解码器的组件来处理。Netty提供了多种组件,简化了为了支持广泛的协议而创建自定义的编解码器的过程。例如,如果你正在构建一个基于Netty的邮件服务器,那么你将会发现Netty对于编解码器的支持对于实现POP3、IMAP和SMTP协议来说是多么的宝贵。
10.1 什么是编解码器
每个网络应用程序都必须定义如何解析在两个节点之间来回传输的原始字节,以及如何将其和目标应用程序的数据格式做相互转换。这种转换逻辑由编解码器处理,编解码器由编码器和解码器组成,它们每种都可以将字节流从一种格式转换为另一种格式。那么它们的区别是什么呢? 如果将消息看作是对于特定的应用程序具有具体含义的结构化的字节序列——它的数据。那么编码器是将消息转换为适合于传输的格式(最有可能的就是字节流);而对应的解码器则是将网络字节流转换回应用程序的消息格式。因此,编码器操作出站数据,而解码器处理入站数据。 记住这些背景信息,接下来让我们研究一下Netty所提供的用于实现这两种组件的类。
10.2 解码器
在这一节中,我们将研究Netty所提供的解码器类,并提供关于何时以及如何使用它们的具体示例。这些类覆盖了两个不同的用例: 将字节解码为消息——ByteToMessageDecoder和ReplayingDecoder; 将一种消息类型解码为另一种——MessageToMessageDecoder。 因为解码器是负责将入站数据从一种格式转换到另一种格式的,所以知道Netty的解码器实现了ChannelInboundHandler也不会让你感到意外。 什么时候会用到解码器呢?很简单:每当需要为ChannelPipeline中的下一个Channel-InboundHandler转换入站数据时会用到。此外,得益于ChannelPipeline的设计,可以将多个解码器链接在一起,以实现任意复杂的转换逻辑,这也是Netty是如何支持代码的模块化以及复用的一个很好的例子。
10.2.1 抽象类ByteToMessageDecoder
将字节解码为消息(或者另一个字节序列)是一项如此常见的任务,以至于Netty为它提供了一个抽象的基类:ByteToMessageDecoder。
由于你不可能知道远程节点是否会一次性地发送一个完整的消息,所以这个类会对入站数据进行缓冲,直到它准备好处理。表10-1解释了它最重要的两个方法。
表10-1
ByteToMessageDecoder API 方 法 描 述
decode( ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
这是你必须实现的唯一抽象方法。
decode()方法被调用时将会传入一个包含了传入数据的ByteBuf,以及一个用来添加解码消息的List。对这个方法的调用将会重复进行,直到确定没有新的元素被添加到该List,或者该ByteBuf中没有更多可读取的字节时为止。然后,如果该List不为空,那么它的内容将会被传递给ChannelPipeline中的下一个
ChannelInboundHandler decodeLast(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
Netty提供的这个默认实现只是简单地调用了 decode()方法。当Channel的状态变为非活动时,这个方法将会被调用一次。可以重写该方法以提供特殊的处理[1]
下面举一个如何使用这个类的示例,假设你接收了一个包含简单int的字节流,每个int都需要被单独处理。在这种情况下,你需要从入站ByteBuf中读取每个int,并将它传递给ChannelPipeline中的下一个ChannelInboundHandler。为了解码这个字节流,你要扩展ByteToMessageDecoder类。(需要注意的是,原始类型的int在被添加到List中时,会被自动装箱为Integer。) 该设计如图10-1所示。
每次从入站ByteBuf中读取4字节,将其解码为一个int,然后将它添加到一个List中。当没有更多的元素可以被添加到该List中时,它的内容将会被发送给下一个Channel-InboundHandler。
图10-1
ToIntegerDecoder 代码清单10-1展示了ToIntegerDecoder的代码。
代码清单10-1 ToIntegerDecoder类扩展了ByteToMessageDecoder
public class ToIntegerDecoder extends ByteToMessageDecoder {← -- 扩展ByteToMessage-Decoder 类,以将字节解码为特定的格式 @Overridepublic void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { if (in.readableBytes() >= 4) {← -- 检查是否至少有4字节可读(一个int的字节长度) out.add(in.readInt());← -- 从入站ByteBuf 中读取一个int,并将其添加到解码消息的List 中}}}
虽然ByteToMessageDecoder使得可以很简单地实现这种模式,但是你可能会发现,在调用readInt()方法前不得不验证所输入的ByteBuf是否具有足够的数据有点繁琐
。在下一节中,我们将讨论ReplayingDecoder,它是一个特殊的解码器,以少量的开销消除了这个步骤。 编解码器中的引用计数 正如我们在第5章和第6章中所提到的,引用计数需要特别的注意。对于编码器和解码器来说,其过程也是相当的简单:一旦消息被编码或者解码,它就会被ReferenceCountUtil.release(message)调用自动释放。如果你需要保留引用以便稍后使用,那么你可以调用ReferenceCountUtil.retain(message)方法。这将会增加该引用计数,从而防止该消息被释放。
10.2.2 抽象类ReplayingDecoder
ReplayingDecoder扩展了ByteToMessageDecoder类(如代码清单10-1所示),使得我们不必调用readableBytes()方法。它通过使用一个自定义的ByteBuf实现,ReplayingDecoderByteBuf,包装传入的ByteBuf实现了这一点,其将在内部执行该调用[2]。 这个类的完整声明是: public abstract class ReplayingDecoder~~ extends ByteToMessageDecoder 类型参数S指定了用于状态管理的类型,其中Void代表不需要状态管理。代码清单10-2展示了基于ReplayingDecoder重新实现的ToIntegerDecoder。 代码清单10-2 ToIntegerDecoder2类扩展了ReplayingDecoder public class ToIntegerDecoder2 extends ReplayingDecoder { ← — 扩展Replaying-Decoder以将字节解码为消息 [@Override ](/Override ) public void decode(ChannelHandlerContext ctx, ByteBuf in, ← — 传入的ByteBuf 是ReplayingDecoderByteBuf List ~~
10.2.3 抽象类MessageToMessageDecoder
在这一节中,我们将解释如何使用下面的抽象基类在两个消息格式之间进行转换(例如,从一种POJO类型转换为另一种): public abstract class MessageToMessageDecoder extends ChannelInboundHandlerAdapter 类型参数I指定了decode()方法的输入参数msg的类型,它是你必须实现的唯一方法。表10-2展示了这个方法的详细信息。 表10-2 MessageToMessageDecoder API 方 法 描 述 decode( ChannelHandlerContext ctx, I msg, List
10.2.4 TooLongFrameException类
由于Netty是一个异步框架,所以需要在字节可以解码之前在内存中缓冲它们。因此,不能让解码器缓冲大量的数据以至于耗尽可用的内存。为了解除这个常见的顾虑,Netty提供了TooLongFrameException类,其将由解码器在帧超出指定的大小限制时抛出。 为了避免这种情况,你可以设置一个最大字节数的阈值,如果超出该阈值,则会导致抛出一个TooLongFrameException(随后会被ChannelHandler.exceptionCaught()方法捕获)。然后,如何处理该异常则完全取决于该解码器的用户。某些协议(如HTTP)可能允许你返回一个特殊的响应。而在其他的情况下,唯一的选择可能就是关闭对应的连接。 代码清单10-4展示了ByteToMessageDecoder是如何使用TooLongFrameException来通知ChannelPipeline中的其他ChannelHandler发生了帧大小溢出的。需要注意的是,如果你正在使用一个可变帧大小的协议,那么这种保护措施将是尤为重要的。 代码清单10-4 TooLongFrameException public class SafeByteToMessageDecoder extends ByteToMessageDecoder { ← — 扩展ByteToMessageDecoder以将字节解码为消息 private static final int MAX_FRAME_SIZE = 1024; @Override public void decode(ChannelHandlerContext ctx, ByteBuf in, List
10.3 编码器
回顾一下我们先前的定义,编码器实现了ChannelOutboundHandler,并将出站数据从一种格式转换为另一种格式,和我们方才学习的解码器的功能正好相反。Netty提供了一组类,用于帮助你编写具有以下功能的编码器: 将消息编码为字节; 将消息编码为消息[4]。 我们将首先从抽象基类MessageToByteEncoder开始来对这些类进行考察。
10.3.1 抽象类MessageToByteEncoder
前面我们看到了如何使用ByteToMessageDecoder来将字节转换为消息。现在我们将使用MessageToByteEncoder来做逆向的事情。
表10-3展示了该API。 表10-3 MessageToByteEncoder API 方 法 描 述 encode( ChannelHandlerContext ctx, I msg, ByteBuf out) encode()方法是你需要实现的唯一抽象方法。它被调用时将会传入要被该类编码为ByteBuf的(类型为I的)出站消息。该ByteBuf随后将会被转发给ChannelPipeline中的下一个ChannelOutboundHandler 你可能已经注意到了,这个类只有一个方法,而解码器有两个。原因是解码器通常需要在Channel关闭之后产生最后一个消息(因此也就有了decodeLast()方法)。这显然不适用于编码器的场景——在连接被关闭之后仍然产生一个消息是毫无意义的。 图10-3展示了ShortToByteEncoder,其接受一个Short类型的实例作为消息,将它编码为Short的原始类型值,并将它写入ByteBuf中,其将随后被转发给ChannelPipeline中的下一个ChannelOutboundHandler。每个传出的Short值都将会占用ByteBuf中的2字节。 ShortToByteEncoder的实现如代码清单10-5所示。 代码清单10-5 ShortToByteEncoder类 public class ShortToByteEncoder extends MessageToByteEncoder { ← — 扩展了MessageToByteEncoder @Override public void encode(ChannelHandlerContext ctx, Short msg, ByteBuf out) throws Exception { out.writeShort(msg); ← — 将Short 写入ByteBuf 中 } } Netty提供了一些专门化的MessageToByteEncoder,你可以基于它们实现自己的编码器。WebSocket08FrameEncoder类提供了一个很好的实例。你可以在io.netty.handler. codec.http.websocketx包中找到它。 图10-3 ShortToByteEncoder
10.3.2 抽象类MessageToMessageEncoder
你已经看到了如何将入站数据从一种消息格式解码为另一种。为了完善这幅图,我们将展示对于出站数据将如何从一种消息编码为另一种。MessageToMessageEncoder类的encode()方法提供了这种能力,如表10-4所示。 表10-4 MessageToMessageEncoder API 名 称 描 述 encode( ChannelHandlerContext ctx, I msg, List
10.4 抽象的编解码器类
虽然我们一直将解码器和编码器作为单独的实体讨论,但是你有时将会发现在同一个类中管理入站和出站数据和消息的转换是很有用的。Netty的抽象编解码器类正好用于这个目的,因为它们每个都将捆绑一个解码器/编码器对,以处理我们一直在学习的这两种类型的操作。正如同你可能已经猜想到的,这些类同时实现了ChannelInboundHandler和ChannelOutboundHandler接口。 为什么我们并没有一直优先於单独的解码器和编码器使用这些复合类呢?因为通过尽可能地将这两种功能分开,最大化了代码的可重用性和可扩展性,这是Netty设计的一个基本原则。 在我们查看这些抽象的编解码器类时,我们将会把它们与相应的单独的解码器和编码器进行比较和参照。
10.4.1 抽象类ByteToMessageCodec
让我们来研究这样的一个场景:我们需要将字节解码为某种形式的消息,可能是POJO,随后再次对它进行编码。ByteToMessageCodec将为我们处理好这一切,因为它结合了ByteToMessageDecoder以及它的逆向——MessageToByteEncoder。表10-5列出了其中重要的方法。 任何的请求/响应协议都可以作为使用ByteToMessageCodec的理想选择。例如,在某个SMTP的实现中,编解码器将读取传入字节,并将它们解码为一个自定义的消息类型,如SmtpRequest[5]。而在接收端,当一个响应被创建时,将会产生一个SmtpResponse,其将被编码回字节以便进行传输。 表10-5 ByteToMessageCodec API 方 法 名 称 描 述 decode( ChannelHandlerContext ctx, ByteBuf in, List
10.4.2 抽象类MessageToMessageCodec
在10.3.1节中,你看到了一个扩展了MessageToMessageEncoder以将一种消息格式转换为另外一种消息格式的例子。通过使用MessageToMessageCodec,我们可以在一个单个的类中实现该转换的往返过程。MessageToMessageCodec是一个参数化的类,定义如下: public abstract class MessageToMessageCodec
10.4.3 CombinedChannelDuplexHandler类
正如我们前面所提到的,结合一个解码器和编码器可能会对可重用性造成影响。但是,有一种方法既能够避免这种惩罚,又不会牺牲将一个解码器和一个编码器作为一个单独的单元部署所带来的便利性。CombinedChannelDuplexHandler提供了这个解决方案,其声明为: public class CombinedChannelDuplexHandler 这个类充当了ChannelInboundHandler和ChannelOutboundHandler(该类的类型参数I和O)的容器。通过提供分别继承了解码器类和编码器类的类型,我们可以实现一个编解码器,而又不必直接扩展抽象的编解码器类。我们将在下面的示例中说明这一点。 首先,让我们研究代码清单10-8中的ByteToCharDecoder。注意,该实现扩展了ByteTo-MessageDecoder,因为它要从ByteBuf中读取字符。 代码清单10-8 ByteToCharDecoder类 public class ByteToCharDecoder extends ByteToMessageDecoder { ← — 扩展了ByteToMessageDecoder @Override public void decode(ChannelHandlerContext ctx, ByteBuf in, List
10.5 小结
在本章中,我们学习了如何使用Netty的编解码器API来编写解码器和编码器。你也了解了为什么使用这个API相对于直接使用ChannelHandlerAPI更好。 你看到了抽象的编解码器类是如何为在一个实现中处理解码和编码提供支持的。如果你需要更大的灵活性,或者希望重用现有的实现,那么你还可以选择结合他们,而无需扩展任何抽象的编解码器类。 在下一章中,我们将讨论作为Netty框架本身的一部分的ChannelHandler实现和编解码器,你可以利用它们来处理特定的协议和任务。

若有收获,就点个赞吧
0 人点赞
