MySQL对索引的定义:索引index是帮助MySQL高效获取数据的数据结构;
全表扫描:会将整张表全部扫描一遍,这样的话非常低;mysql支持Hash,平衡二叉树,B树,B+树;最牛的是B+树;Hash索引:<br /> 优点:通过字段的值计算的hash值,定位数据非常快;<br /> 缺点:不支持范围查询,因为底层数据结构是散列的,无法进行比较大小;平衡二叉树:<br /> 优点:查询效率还可以;<br /> 缺点:虽然支持范围查询,但是回旋查询效率低;B树:<br /> 因为B树节点元素比平衡二叉树要多,所以B树数据结构相比平衡二叉树数据结构实现减少磁盘IO的操作<br /> 查询是比平衡二叉树要快了点,但是范围查询依然比较慢;B+树<br /> B+树相比B树,新增了叶子结点与非叶子节点的关系,叶子结点包含了key和value,非叶子节点中只有key,不包含value;<br /> 所有相邻的叶子结点包含非叶子节点,使用链表进行结合,有一定的顺序排序,从而范围查询效率非常高;MyISAM和InnoDB都是应用B+树来实现的,只是有所不同的是,MyISAM的B+树中的叶子结点的value为数据记录的地址,而Innodb中的叶子结点的value是数据记录本身;<br />[全面解密MySQL索引实现原理.pptx](https://www.yuque.com/attachments/yuque/0/2019/pptx/233760/1573028843452-23aed94f-56f7-431d-8e8f-bb05619d6083.pptx?_lake_card=%7B%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2019%2Fpptx%2F233760%2F1573028843452-23aed94f-56f7-431d-8e8f-bb05619d6083.pptx%22%2C%22name%22%3A%22%E5%85%A8%E9%9D%A2%E8%A7%A3%E5%AF%86MySQL%E7%B4%A2%E5%BC%95%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86.pptx%22%2C%22size%22%3A254568259%2C%22type%22%3A%22application%2Fvnd.openxmlformats-officedocument.presentationml.presentation%22%2C%22ext%22%3A%22pptx%22%2C%22source%22%3A%22%22%2C%22status%22%3A%22done%22%2C%22mode%22%3A%22title%22%2C%22download%22%3Atrue%2C%22uid%22%3A%221573028697061-0%22%2C%22progress%22%3A%7B%22percent%22%3A0%7D%2C%22percent%22%3A0%2C%22id%22%3A%22HnJO5%22%2C%22card%22%3A%22file%22%7D)
1、where 是用于前边的过滤 而having是用于groupby后的过滤,两者可结合使用
2、索引操作:
增加一个普通索引:MUL
alter table tableName add index indexName(fieldName);
增加一个唯一索引:UNI 唯一且可以为null
alter table tableName add unique index indexName(fieldName);
alter ignore ….. 是在表中某个字段已经存在大量相同的值,但是我们依然需要忽略而创建唯一索引;
创建主键索引:PRI 唯一不允许为null
create table tableName(id int primary key auto_increment,name varchar(20) not null defalut ‘’);
alter table tableName add primary key (fieldName);
复合索引:
create index indexName on tableName (field1,field2,field3);
alter table tablename add index indexname (field1,field2,field3)
怎样删除索引:
drop index indexname on tablename
全文索引 参考https://blog.csdn.net/dreamyuzhou/article/details/120432893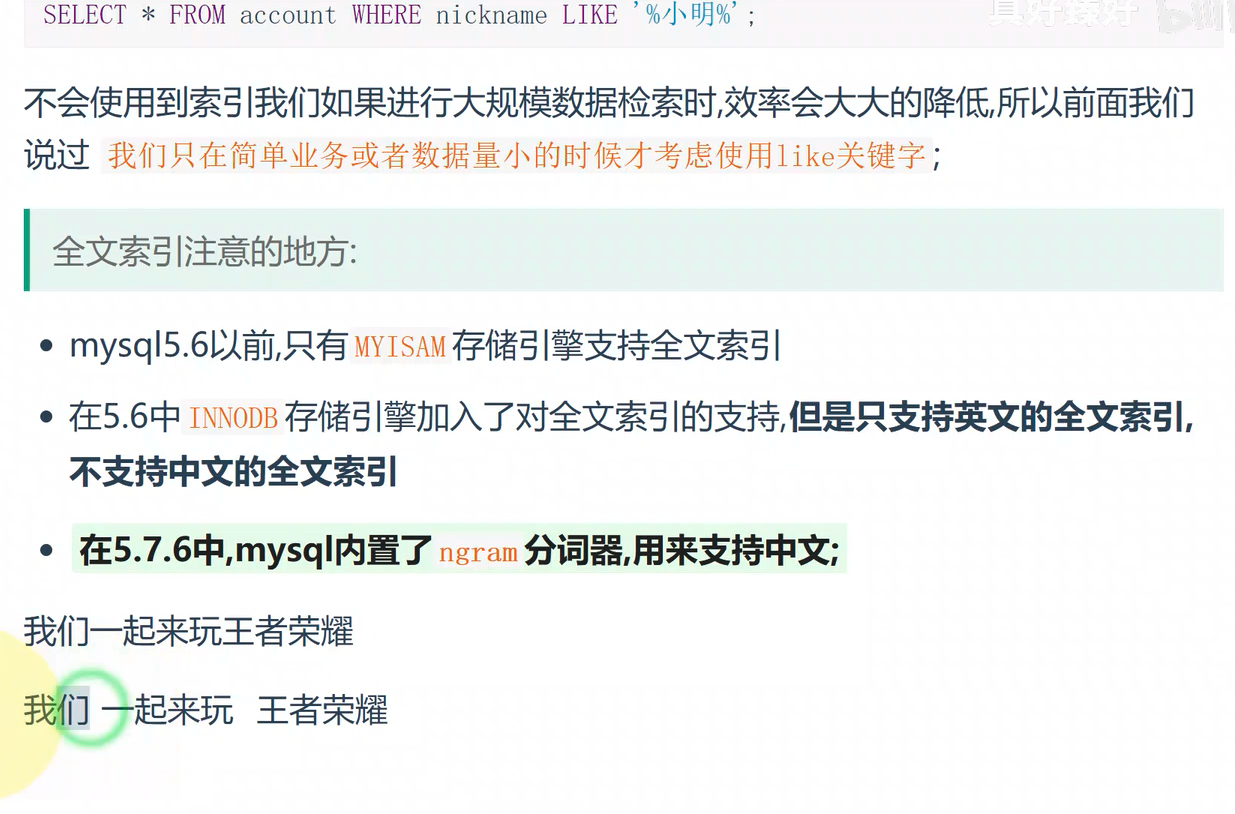
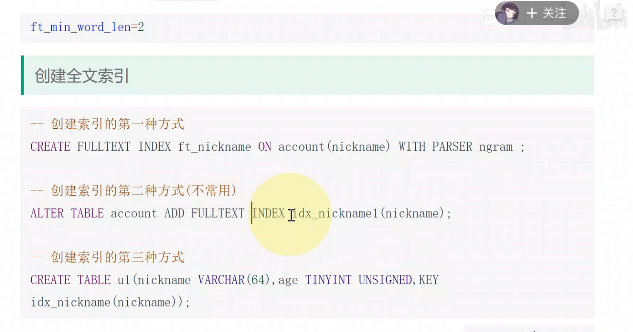
3、MySQL数据库配置慢查询
参数说明:
slow_query_log 慢查询开启状态
slow_query_log_file 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
long_query_time 查询超过多少秒才记录
1.查询慢查询配置
show variables like ‘slow_query%’;
2.查询慢查询限制时间
show variables like ‘long_query_time’;
3.将 slow_query_log 全局变量设置为“ON”状态
set global slow_query_log=’ON’;
4.查询超过1秒就记录
set global long_query_time=1;
5.查询cat /var/lib/mysql/localhost-slow.log
4、索引为什么会失效?注意那些事项?
1.索引无法存储null值 主索引成全表扫描,而普通索引无影响;唯一索引is null 1,is not null 全表
2.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
3.对于多列索引,不是使用的第一部分,则不会使用索引
4.like查询以%开头,主键索引和唯一索引前后都不可以,普通索引前不可以,后可以;
5.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
6.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
5、复合索引:
2 EXPLAIN select from user_details WHERE id=1
1 EXPLAIN select from user_details WHERE id=1 and user_name=’yushengjun1’;
6 select * from user_details WHERE user_name=’yushengjun1’;
因为索引底层采用B+树叶子节点顺序排列,必须通过左前缀索引才能定位到具体的节点范围;
怎样回答数据库索引实现原理:
第一点说一下、MyISAM与InnoDB都是采用B+树数据结构实现索引的只不过MyISAM的B+树中的叶子节点value存放的时候数据的地址,而InnoDB的B+树中的叶子节点value值存放的是真实的数据;B+树继承了B树的优点,你就查询某个节点较快,因为B树比平衡二叉树多了三节点的模型,每一层的节点变多,所以查询的效率就更快,同时B+树增加了叶子节点与非叶子节点的区别,叶子节点中包含了key和value,叶子节点包含了非叶子节点,都有序的存放在一个队列中,所以当我们按照范围区间来查询的时候比B树要快;
可视化数据结构:
https://www.cs.usfca.edu/

若有收获,就点个赞吧
0 人点赞
