AAAI 2020 multi-task learning activation function matrix regularization SBU BUPT Tencent
Problem
对Multi Task Learning任务,我们希望找到一个能够灵活共享的结构,让网络在多任务适配上更加灵活高效。
这篇文章提出了一个能够根据任务进行调整的网络框架:主要将激活函数按照不同任务做了区分,并通过regularization约束不同任务之间的激活函数超参,让神经网络适用于不同的任务。
Method
由于网络权重共享, 那么区分不同的task自然想到的就是通过不同的激活函数完成。
正常的神经网络前向:
论文参考了APL激活函数,在这上面做了改进,关于APL激活函数,长这样:
Adaptive Piecewise Linear(APL)
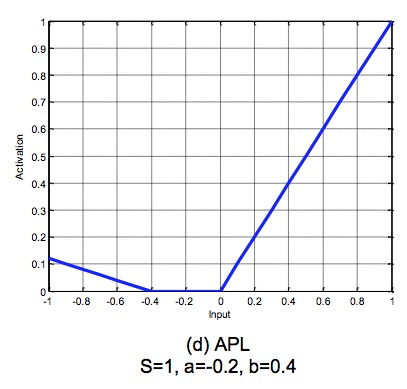
其中,左半边就是ReLU,右半边 是自定义的超参,表示激活函数的数量(Bagging思想),
是自定义的超参,表示激活函数的数量(Bagging思想), 和
和 是每个激活函数下的训练参数。
是每个激活函数下的训练参数。
APL :Learning activation functions to improve deep neural networks.
论文改进后:
核心思想:原先是一个网络的激活函数有个超参,现在有 个,相当于对任务做了区分。
个,相当于对任务做了区分。
这个改进不知道是否是真比区分network训练,然后在network上加参数约束更好,如果更好,说明了对激活函数的改动优于对网络参数的改动。 否则本质上使用不共享网络参数的方法,理论上也可以做到。
接下来,论文证明了这种改进会让基函数变得失去正交归一且无界,从而让参数 跑飞,即使不跑飞,这种分布的分散性,也会让不同Task之间的关联性丢失或不那么容易捕获,因此后面又用两种正则方法做一些修正。
跑飞,即使不跑飞,这种分布的分散性,也会让不同Task之间的关联性丢失或不那么容易捕获,因此后面又用两种正则方法做一些修正。
基准:只做正则
改进一:Task间正则

改进二:增加距离正则

**
和函数
的计算方式参考论文
Experiment
在
- CV的视频多标签分
- 手写字母识别
这两个领域做了实验
另外这个文章还顺带把激活函数的超参数(本质是distance matrix)做了可视化。
Conclusion
一直想做动态网络结构的Multi-Task模型,这个文章从激活函数出发,修改为多任务的激活函数,并加了个正则项做多任务的约束,顺带还做了迁移可解释性,算是一种不错的思路。
要是能动态决定网络结构就更好了,可能需要往Auto-ML的角度再看看。

若有收获,就点个赞吧
0 人点赞
