Flask-SQLAlchemy
简介与安装
SQLAlchemy是一个强大的关系型数据库框架,支持多种数据库后台。SQLAlchemy提供了高层ORM,也提供了使用数据库原生SQL的低层功能
alchemy 读作#ˈælkəmi
安装:pip install flask-sqlalchemy
FLask-SQLAlchemy数据库URL
| 数据库引擎 | URI | eg |
|---|---|---|
| MySQL | mysql://username:password@hostname/database | |
| Postgres | postgresql://username:password@hostname/database | |
| SQLite(Unix) | SQLITE:////absolute/path/to/database | |
| SQLite(Windows) | SQLITE:////c:/absolute/path/to/database | SQLITE:////G:\blog\data.sqlite |
SQLite 数据库不需要使用服务器,因此不用指定 hostname、username 和password。
URL 中的 database 是硬盘上文件的文件名
SQLAlchemy常用列类型
| 类型名 | Python类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | secimalDecimal | 定点数 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长 Unicode 字符串 |
| UnicodeText | unicode | 变长 Unicode 字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 日期 |
| Time | datetime.time | 时间 |
| DateTime | datetime.datetime | 日期和时间 |
| Interval | datetime.timedelta | 时间间隔 |
| Enum | str | 一组字符串 |
| PickleTrype | 任何python对象 | 自动使用Pickle序列化 |
| LargeBinary | str | 二进制文件 |
SQLAlchemy常用列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果设为 True,这列就是表的主键 |
| unique | 如果设为 True,这列不允许出现重复的值 |
| index | 如果设为 True,为这列创建索引,提升查询效率 |
| nullable | 如果设为 True,这列允许使用空值;如果设为 False,这列不允许使用空值 |
| default | 为这列定义默认值 |
SQLAlchemy常用关系
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一个模型中添加反向引用 |
| primaryjoin | 明确指定两个模型之间使用的联结条件。只在模棱两可的关系中需要指定 |
| lazy | 指定如何加载相关记录。可选值有 select(首次访问时按需加载)、immediate(源对象加载后就加载)、joined(加载记录,但使用联结)、subquery(立即加载,但使用子查询), noload(永不加载)和 dynamic(不加载记录,但提供加载记录的查询) |
| uselist | 如果设为 Fales,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定 多对多 关系中关系表的名字 |
| secondaryjoin | 指定 多对多 关系中关系表的名字 |
配置信息
必须配置 SQLALCHEMY_DATABASE_URI
建议将SQLALCHEMY_TRADE_CONDIFITION 设为False,降低内存消耗
from flask import Flaskimport osfrom flask_sqlalchemy import SQLAlchemyapp = Flask(__file__)basedir = os.path.asbpath(os.path.dirname(__file__))app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + basedir + '\\dev-data.sqlite'app.config['SQLALCHEMY_TRADE_CONDIFITION'] = False
创建db实例
# ...db = SQLAlchemy(app)
定义模型

定义表名及表字段
hello.py
#...class Role(db.model):__tabelname__ = "roles" #表名,如果未设置,SQLAlchemy会使用一个默认名字id = db.Column(db.Integer, primary_key=True) #行,id,主键name = db.Column(db.String(64), unique=True) #name字段,唯一users = db.relationship('User', backref='role') # backref定义的值,是后续创建user外键行时需要参数def __perp__(self):return "<Role %r>', % self.nameclass User(db.model):__tablename__ = "users"id = db.column(db.Integer, primary_key=True)username = db.Column(db.String(64), unique=True, index=True)role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))def __perp__(self):return "<User %r>', % self.username
数据库操作
生成表
不存在数据库时,会生成数据库。
如果已存在数据表,db.create_all()将不会重新创建或者更新对应的表
# flask shell 进入交互界面from hello import db # 是在hello中定义的模型db.create_all()
删除表
修改模型后,需要更新表,则需要删除所有表,然后再重新生成。
但是该种方式会将数据库中原有数据都清除
db.drop_all()db.create_all()
会话(db.session)
对数据库的改动通过会话进行管理,把数据写入库之前,需要先添加到会话中
db.session.add(xxx) # 添加会话db.session.add_all([xxx,aaa])db.session.commit() # 将会话中的数据提交到数据库db.session.rollback() # 添加到数据库会话中的所有对象都还原到数据库中的状态
增加行
from hello import Role, Useradmin_role = Role(name='admin')user_role = Role(username='user', role=admin_role)db.session.add(admin_role)db.session.add(user_role)# 批量添加db.session.add_all([admin_role , user_role])db.session.commit()
修改行
admin_role.name = 'administrator'db.session.add(admin_role)db.session.commit()
删除行
db.session.delete(user_role)db.session.commit()#若要重新创建user_role字段,使用db.sesson.transient(user_role)恢复,后再add\commit
查询行
>>>Role.query.all()[<Role 'admin'>, <Role 'Moderator'>, <Role 'User'>]Role.query.first()<Role 'admin'>User.query.filter_by(role=user_role).all()[<User 'admin'>]>>> Role.query.limit(2).all()[<Role 'admin'>, <Role 'Moderator'>]>>>admin_role = Role.query.filter_by(name='admin').first()>>>admin_role.users # Role模型中,users未添加lazy=dynamic属性时,会默认自动执行all(),此时query对象隐藏起来了,无法增加精确筛选[<User 'admin'>]
常用的查询过滤器
| 过滤器 | 说明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit() | 使用指定的值限制原查询返回的结果数量,返回一个新查询 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
最常使用的查询执行函数
| 方法 | 说明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果没有结果,则返回 None |
| first_or_404() | 返回查询的第一个结果,如果没有结果,则终止请求,返回 404 错误响应 |
| get() | 返回指定主键对应的行,如果没有对应的行,则返回 None |
| get_or_404() | 返回指定主键对应的行,如果没找到指定的主键,则终止请求,返回 404 错误响应 |
| count() | 返回查询结果的数量 |
| paginate() | 返回一个 Paginate 对象,它包含指定范围内的结果 |
集成python shell
每次启动shell都要导入数据库实例和模型,避免重复工作,我们可以做些配置自动导入这些对象。
hello.py
# ...@app.shell_context_processordef make_shell_context():return dict(db=db, User=User, Role=Role)
flask shell>>> app<Flask 'hello'>>>> db
数据库迁移
在开发过程中需要对数据库结构进行修改,修改完模型后,需要更新数据库。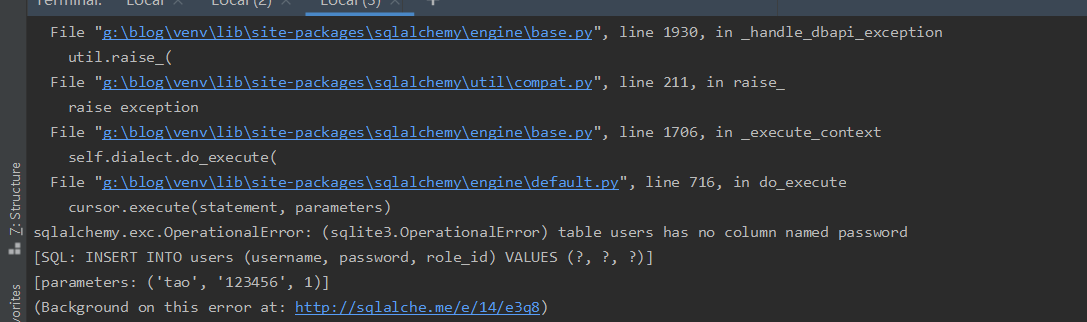
db.create_all()在存在表时,不会重新生成表,必须db.drop_all()后重新生成,但是这样会清除历史数据。
安装与初始化
pip install flask-migrate
from flask_migrate import Migrate# ...migrate = Migrate(app, db)
新项目中增加数据库迁移
(venv) set FLASK_APP=hello.py(venv) set FLASK_DEBUG=1(venv) flask db init
更新数据库
修改模型
class User(db.model):# ...password = db.Column(db.String())
在flask shello环境中执行 set FLASK_APP=hello.py
- 执行flask db migrate,创建一个迁移脚本
- 检查自动生成的脚本,根据模型实际改动调整(SQLite问题处理)
- 比如重命名一列,如果使用自动迁移,会删除一列,再新增一列,导致该列数据被清空
- flask db upgrade 迁移应用到数据库中
>>> set FLASK_APP=hello.py>>> flask db migrate>>> flask db upgrade

若有收获,就点个赞吧
0 人点赞
