关于索引和倒排索引你是否有非常多的困惑,今天有幸看到一篇解释的非常简单明了的文章,特此开一篇文章记录一下。本文内容来自EddyLiu关于【倒排索引为什么叫倒排索引?】的回答👍👍 内容有点长,但是值得你耐心看完。
一、问题描述
倒排索引是搜索引擎的基础算法,在本文中我们以一个简单的例子来详细介绍倒排索引的思想和实现。
假设用户有个搜索query:“林俊杰2019演唱会行程”。百度的搜索结果如下: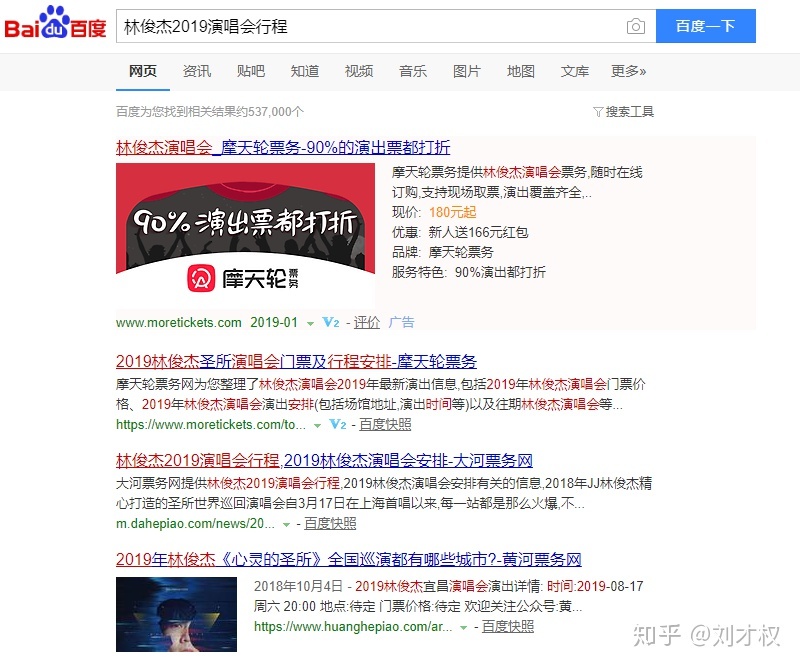
如果要求你来设计一个搜索引擎,来解决这个问题,你会如何着手呢?
二、问题简化
现在我们把这个问题具体化。我们除了有要查询的query:“林俊杰2019演唱会行程”。还有被查询的网页数据库。这里我们做个简化,假设我们的网页数据库内容只有如下4条:
- 网页一:
2019年,JJ林俊杰全球演唱会在北京首场演出,行程如下xxxxxxx;
- 网页二:
林俊杰,加拿大电鳗终于同框合影 ,惹粉丝们尖叫连连,xxxxx;
- 网页三:
蔡依林2019世界演唱会行程全曝光,xxxxx;
- 网页四:
告别2018,迎接崭新的2019,xxxxxx;
简单来说,就是从网页1~4中选取最理想的查询结果。你会怎么做呢?
三、关键词匹配
最容易想到的方法就是关键词匹配了,简单的来说,就是网页中包含查询的关键词越多,网页和查询query的相关度也就越大。在做关键词查询前,一般文本会先进行预处理。这里的预处理主要包括去停用词和分词。
去停用词
去除和查询不相关的内容,比如本例子中的标点符号。在其他场景中,除了标点符号也会去除一些特别的字或词。
分词
分词主要目的是将句子切长短语或关键字,这样才利于查询匹配。比如“林俊杰2019演唱会行程”可以分词成,
林俊杰/2019/演唱会/行程
当然网页也需要这样进行分词:
- 网页一:
2019/年/JJ/林俊杰/全球/演唱会/在/北京/首场/演出/行程/如下/xxxxxxx
- 网页二:
林俊杰/加拿大电鳗/终于/同框/合影 /惹/粉丝们/尖叫/连连/xxxxx
- 网页三:
蔡依林/2019/世界/演唱会/行程/全曝光/xxxxx
- 网页四:
告别/2018/迎接/崭新/的/2019/xxxxxx;
分词是一项专门的技术,在实际工程中可以至今借助工具来完成,比如jieba分词。
分词处理后,我们用查询query中的关键词在网页数据库中进行关键词匹配,并统计匹配数目: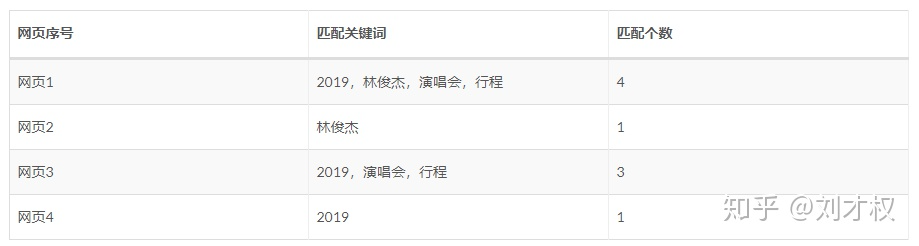
从“匹配个数”中很容易确定,网页1就是和查询query最匹配的网页。
四、倒排索引
讲到这里大家可能会疑问,这和倒排索引有什么关系?实际上,如果仔细考虑上面的关键词查询过程,会发现这种方法有个很大的效率问题:我们的例子中只有4个待查询的网页,而实际的互联网世界的网页数目是非常巨大的。假设互联网世界的网页数据为N,那么使用关键词查询的时间复杂度就是O(N),显然,这样的时间复杂度还是太大了,而倒排索引就很好的优化了这个问题。
从倒排索引这个名字很容易联想出它的实现,关键就是“倒排”的“索引”。在前面的讲解中,我们的索引(key)是网页,内容(value)是关键字。倒排索引就是反过来:内容关键字作为索引(key),所在网页作为内容(value)。前面的表格就可以改写成,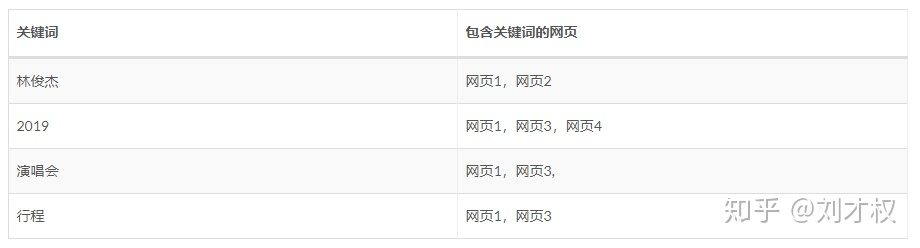
通过上面的表格,很明显网页1是包含最多关键词的网页,也是和查询query相关度最高的网页。采用倒排索引的方法,搜索的时间复杂度得到了明显的降低。
五、搜索引擎框架
有了倒排索引的知识,我们就可以搭建简单的搜索引擎了,
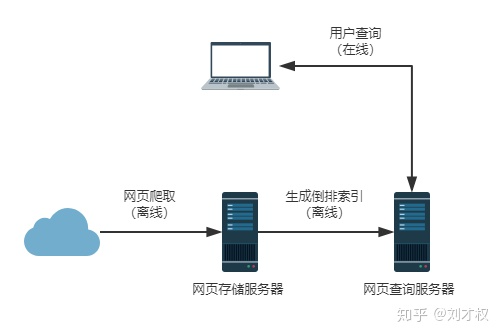
具体步骤包括:
- 步骤一:网页抓取,主要是借助网络爬虫,来抓取网络世界的所有网页,并进行存储。网络爬虫是一项专门的技术,目前工程上也有很多现成的开源工具。
- 步骤二:倒排索引生产,将抓取后的网页经过预处理后,整理生成倒排索引。
- 步骤三:用户在线查询,借助倒排索引,搜索引擎能够满足用户的实时在线查询。
前两个步骤是不用考虑实时性的,可以离线进行,而用户的在线查询则需要保证实时性。
小结
本文通过一个搜索查询的例子,引出关键词查询的方案,及遇到的问题。进而介绍了倒排索引的原理,和搜索引擎的整体框架。现代搜索引擎是一个非常庞大和复杂的系统工程,这里的例子只是为了方便大家理解做了特别的简化。文中提到的分词和网络爬虫也是专门的文本处理技术,在后续的文章后,会根据需要专门展开。

若有收获,就点个赞吧
0 人点赞
