一、介绍一下你对事务的理解
实际工作中对于事务的使用大部分场景都是在 Spring 中使用@Transicational注解来开启,所以本题的答案我这里直接贴出我在 Spring 相关章节整理的内容,点进去一探究竟吧。
二、MySQL 的 ACID 靠什么保证的呢?
- 原子性(Atomicity): 由undo log日志保证,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的 SQL
- 一致性(Consistency) :一般由代码层面来保证,根据实际业务来决定
- 隔离性(Isolation): 由 MVCC 来保证
持久性(Durability) :由内存+redo log来保证,mysql修改数据同时在内存和redo log记录这次操作,事务提交的时候通过redo log刷盘,宕机的时候可以从redo log恢复
InnoDB 和 MyISAM 的区别
事务方面:InnoDB 支持事务,而 MyISAM 不支持事务。
- 外键方面:InnoDB 支持外键,而 MyISAM 不支持外键。
- 锁方面:InnoDB 支持表锁和行锁,而 MyISAM 仅支持表锁。
- 索引方面:InnoDB 和 MyISAM 的索引都是基于b+树,但他们具体实现不一样,InnoDB 的b+树的叶子节点是存放数据的,MyISAM 的b+树的叶子节点是存放指针的。
其他:InnoDB 不存储表的行数,所以
select count(*)的时候会全表查询,而 MyISAM 会存放表的行数,执行select count(*)时候时间复杂度是O(n)。介绍一下 MySQL 都有哪些索引
首先,索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
B+Tree 索引:是大多数 MySQL 存储引擎的默认索引类型。
- 哈希索引:
- 哈希索引能以 O(1) 时间进行查找,但是失去了有序性。
- InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
- 全文索引:
- MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
- 全文索引一般使用倒排索引实现,它记录着关键词到其所在文档的映射。
- InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
- 空间数据索引:MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
介绍一下什么是B+Tree?
B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能。在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。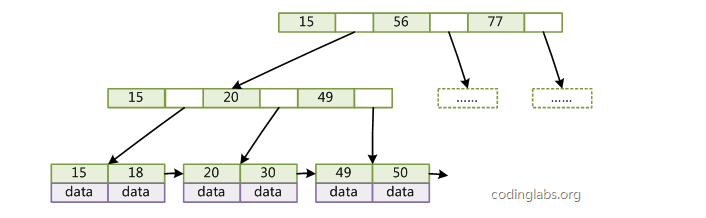
为什么选择B+Tree作为索引的结构?
- 为了减少磁盘读取次数,决定了树的高度不能高,所以必须是先B-Tree;
- 以页为单位读取使得一次 I/O 就能完全载入一个节点,且相邻的节点也能够被预先载入;所以数据放在叶子节点,本质上是一个Page页;
- 为了支持范围查询以及关联关系, 页中数据需要有序,且页的尾部节点指向下个页的头部;
介绍一下B+Tree实现的聚簇索引和非聚簇索引的区别

如上图所示,左侧为聚簇索引右侧为非聚簇索引,主键索引的叶子节点保存的是真正的数据,而非聚簇索引叶子节点的数据区保存的是主键索引关键字的值。
假如要查询name = C 的数据,其搜索过程如下:a) 先在辅助索引中通过C查询最后找到主键id = 9; b) 在主键索引中搜索id为9的数据,最终在主键索引的叶子节点中获取到真正的数据。所以通过辅助索引进行检索,需要检索两次索引。
之所以这样设计,一个原因就是:如果和MyISAM一样在主键索引和辅助索引的叶子节点中都存放数据行指针,一旦数据发生迁移,则需要去重新组织维护所有的索引。
介绍一下什么是索引覆盖和回表
覆盖索引指的是在一次查询中,如果一个索引包含或者说覆盖所有需要查询的字段的值,我们就称之为覆盖索引,而不再需要回表查询。
首先我们知道在一个非聚簇索引中,B+Tree的叶子节点保存的是主键+【非聚簇索引字段值】,那么当一个查询语句使用到这个非聚簇索引时,如果非聚簇索引的叶子节点中的数据刚好满足SELECT语句中的字段,那么就没有必要浪费服务器资源再去聚簇索引中取数据了,以上便是判单是否需要回表的思路。
要确定一个查询是否是覆盖索引,我们还可以使用explain sql语句看Extra的结果是否是“Using index”。
-- 假设user表有一个根据字段id,age生成的非聚簇索引explain select * from user where age=1; // 查询的name无法从索引数据获取explain select id,age from user where age=1; //可以直接从索引获取
介绍一下 SQL 优化的思路
介绍一下索引优化的思路
四、BufferPool、RedoLogBuffer 和undo log、redo log、bin log 概念以及关系?

若有收获,就点个赞吧
0 人点赞
