概述
原子类一共可以分为以下这 6 类,我们来逐一介绍:
| 类型 | 具体类 |
|---|---|
| Atomic* 基本类型原子类 | AtomicInteger、AtomicLong、AtomicBoolean |
| Atomic*Array 数组类型原子类 | AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray |
| Atomic*Reference 引用类型原子类 | AtomicReference、AtomicStampedReference、AtomicMarkableReference |
| Atomic*FieldUpdater 升级类型原子类 | AtomicIntegerfieldupdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater |
| Adder 累加器 | LongAdder、DoubleAdder |
| Accumulator 积累器 | LongAccumulator、DoubleAccumulator |
AtomicInteger
AtomicInteger是Integer类型的线程安全原子类,可以在应用程序中以原子的方式更新int值。
创建
创建AtomicInteger的初始值为0。
public AtomicInteger()
创建AtomicInteger并且指定初始值,无参的AtomicInteger对象创建等价于AtomicInteger(0)
public AtomicInteger(int initialValue):
AtomicInteger 类有以下几个常用的方法:
| 方法 | 说明 |
|---|---|
| public final int get() | 获取当前的值 |
| public final int getAndSet(int newValue) | 获取当前的值,并设置新的值 |
| public final int getAndIncrement() | 获取当前的值,并自增 |
| public final int getAndDecrement() | 获取当前的值,并自减 |
| public final int getAndAdd(int delta) | 获取当前的值,并加上预期的值,getAndIncrement 和 getAndDecrement 修改的数值默认为 +1 或 -1,如果不能满足需求,我们就可以使用 getAndAdd 方法来直接一次性地加减我们想要的数值。 |
| boolean compareAndSet(int expect, int update) | 如果输入的数值等于预期值,则以原子方式将该值更新为输入值(update) |
Array 数组类型原子类
AtomicArray 数组类型原子类,数组里的元素,都可以保证其原子性,比如 AtomicIntegerArray 相当于把 AtomicInteger 聚合起来,组合成一个数组。这样一来,我们如果想用一个每一个元素都具备原子性的数组的话, 就可以使用 AtomicArray。
它一共分为 3 种,分别是:
- AtomicIntegerArray:整形数组原子类;
- AtomicLongArray:长整形数组原子类;
- AtomicReferenceArray :引用类型数组原子类。
AtomicReference引用类型原子类
AtomicReference 可以让一个对象保证原子性。 除了 AtomicReference 之外,还有:
除了 AtomicReference 之外,还有:
- AtomicStampedReference:它是对 AtomicReference 的升级,在此基础上还加了时间戳,用于解决 CAS 的 ABA 问题。
AtomicMarkableReference:和 AtomicReference 类似,多了一个绑定的布尔值,可以用于表示该对象已删除等场景。
Atomic包简介及源码分析
Atomic包中的类基本的特性就是在多线程环境下,当有多个线程同时对单个(包括基本类型及引用类型)变量进行操作时,具有排他性,即当多个线程同时对该变量的值进行更新时,仅有一个线程能成功,而未成功的线程可以向自旋锁一样,继续尝试,一直等到执行成功。<br /> Atomic系列的类中的核心方法都会调用unsafe类中的几个本地方法。我们需要先知道一个东西就是Unsafe类,全名为:sun.misc.Unsafe,这个类包含了大量的对C代码的操作,包括很多直接内存分配以及原子操作的调用,而它之所以标记为非安全的,是告诉你这个里面大量的方法调用都会存在安全隐患,需要小心使用,否则会导致严重的后果,例如在通过unsafe分配内存的时候,如果自己指定某些区域可能会导致一些类似C++一样的指针越界到其他进程的问题。<br /> Atomic包中的类按照操作的数据类型可以分成4组
AtomicBoolean,AtomicInteger,AtomicLong
线程安全的基本类型的原子性操作
AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
线程安全的数组类型的原子性操作,它操作的不是整个数组,而是数组中的单个元素
AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater
基于反射原理对象中的基本类型(长整型、整型和引用类型)进行线程安全的操作
AtomicReference ,AtomicMarkableReference,AtomicStampedReference
线程安全的引用类型及防止ABA问题的引用类型的原子操作
我们一般常用的AtomicInteger、AtomicReference和AtomicStampedReference。现在我们来分析一下Atomic包中AtomicInteger的源代码,其它类的源代码在原理上都比较类似。<br /> 1. 有参构造函数
public AtomicInteger(int initialValue) {value = initialValue;}
从构造函数函数可以看出,数值存放在成员变量value中
private volatile int value;
成员变量value声明为volatile类型,说明了多线程下的可见性,即任何一个线程的修改,在其它线程中都会被立刻看到<br /> 2. compareAndSet方法(value的值通过内部this和valueOffset传递)
public final boolean compareAndSet(int expect, int update) {return unsafe.compareAndSwapInt(this, valueOffset, expect, update);}
这个方法就是最核心的CAS操作 <br /> 3. getAndSet方法 , 在该方法中调用了compareAndSet方法
public final int getAndSet(int newValue) {for (;;) {int current = get();if (compareAndSet(current, newValue))return current;}}
如果在执行if (compareAndSet(current, newValue) 之前其它线程更改了value的值,那么导致 value 的值必定和current的值不同,compareAndSet执行失败,只能重新获取value的值,然后继续比较,直到成功。<br /> 4. i++的实现
public final int getAndIncrement() {for (;;) {int current = get();int next = current + 1;if (compareAndSet(current, next))return current;}}
5. ++i的实现
public final int incrementAndGet() {for (;;) {int current = get();int next = current + 1;if (compareAndSet(current, next))return next;}}
下面的程序,利用AtomicInteger模拟卖票程序,运行结果中不会出现两个程序卖了同一张票,也不会卖到票为负数
package javaleanning;import java.util.concurrent.atomic.AtomicInteger;public class SellTickets {AtomicInteger tickets = new AtomicInteger(100);class Seller implements Runnable{@Overridepublic void run() {while(tickets.get() > 0){int tmp = tickets.get();if(tickets.compareAndSet(tmp, tmp-1)){System.out.println(Thread.currentThread().getName()+" "+tmp);}}}}public static void main(String[] args) {SellTickets st = new SellTickets();new Thread(st.new Seller(), "SellerA").start();new Thread(st.new Seller(), "SellerB").start();}}
ABA问题
上述的例子运行结果完全正确,这是基于两个(或多个)线程都是向同一个方向对数据进行操作,上面的例子中两个线程都是是对tickets进行递减操作。再比如,多个线程对一个共享队列都进行对象的入列操作,那么通过AtomicReference类也可以得到正确的结果(AQS中维护的队列其实就是这个情况),但是多个线程即可以入列也可以出列,也就是数据的操作方向不一致,那么可能出现ABA的情况。<br /> 我们现在拿一个比较好理解的例子来解释ABA问题,假设有两个线程T1和T2,这两个线程对同一个栈进行出栈和入栈的操作。<br /> 我们使用AtomicReference定义的tail来保存栈顶位置<br />AtomicReference<T> tail;<br />[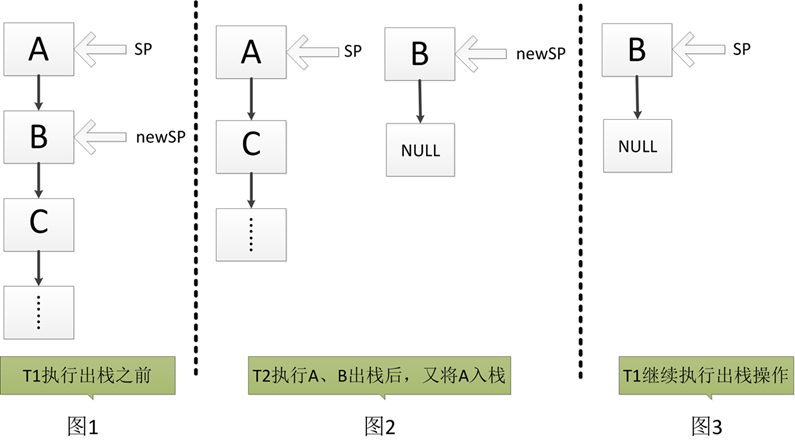](http://images2015.cnblogs.com/blog/834468/201512/834468-20151226122634906-973935795.png)<br /> 假设T1线程准备出栈,对于出栈操作我们只需要将栈顶位置由sp通过CAS操作更新为newSP即可,如图1所示。但是在T1线程执行tail.compareAndSet(sp, newSP)之前系统进行了线程调度,T2线程开始执行。T2执行了三个操作,A出栈,B出栈,然后又将A入栈。此时系统又开始调度,T1线程继续执行出栈操作,但是在T1线程看来,栈顶元素仍然为A,(即T1仍然认为B还是栈顶A的下一个元素),而实际上的情况如图2所示。T1会认为栈没有发生变化,所以tail.compareAndSet(sp, newSP)执行成功,栈顶指针被指向了B节点。而实际上B已经不存在于堆栈中,T1将A出栈后的结果如图3所示,这显然不是正确的结果。
ABA问题的解决方法
使用AtomicMarkableReference,AtomicStampedReference。使用上述两个Atomic类进行操作。他们在实现compareAndSet指令的时候除了要比较当对象的前值和预期值以外,还要比较当前(操作的)戳值和预期(操作的)戳值,当全部相同时,compareAndSet方法才能成功。每次更新成功,戳值都会发生变化,戳值的设置是由编程人员自己控制的。
public boolean compareAndSet(V expectedReference, V newReference,int expectedStamp,int newStamp) {Pair<V> current = pair;return expectedReference == current.reference &&expectedStamp == current.stamp &&((newReference == current.reference && newStamp == current.stamp) ||casPair(current, Pair.of(newReference, newStamp)));}
这时的compareAndSet 方法需要四个参数expectedReference, newReference, expectedStamp, newStamp,我们在使用这个方法时要保证期望的戳值和要更新戳值不能一样,通常 newStamp = expectedStamp + 1 <br /> 还拿上述的例子 <br /> 假设线程T1在弹栈之前: sp指向A,戳值为100。<br /> 线程T2执行: 将A出栈后,sp指向B,戳值变为101,<br /> B出栈后,sp指向C,戳值变为102,<br /> A入栈后,sp指向A,戳值变为103,<br /> 线程T1继续执行compareAndSet语句,发现sp虽然还是指向A,但是戳值的预期值100和当前值103不同,所以compareAndSet失败,需要从新获取newSP的值(此时newSP就会指向C),以及戳的预期值103,然后再次进行compareAndSet操作,这样A成功出栈,sp会指向C。<br /> 注意,由于compareAndSet只能一次改变一个值,无法同时改变newReference和newStamp,所以在实现的时候,在内部定义了一个类Pair类将newReference和newStamp变成一个对象,进行CAS操作的时候,实际上是对Pair对象的操作
private static class Pair<T> {final T reference;final int stamp;private Pair(T reference, int stamp) {this.reference = reference;this.stamp = stamp;}static <T> Pair<T> of(T reference, int stamp) {return new Pair<T>(reference, stamp);}}
对于AtomicMarkableReference而言,戳值是一个布尔类型的变量,而AtomicStampedReference中戳值是一个整型变量。

若有收获,就点个赞吧
0 人点赞
