一、数据模型
znode是zookeeper中最小的数据单元,每个Znode上都可以保存数据,同时还可以挂载子节点,因此构成了一个层次化的命名空间,我们称之为树。
1.树
在Zookeeper中,每一个数据节点都被称为一个Znode,所有的Znode按层次化结构进行组织,形成一棵树。Znode的节点路径都是由一系列使用斜杠/进行分割的路径表示,开发人员可以这个节点中写入数据,也可以在节点下面创建子节点。
2.事务ID
在Zookeeper中,事务是指能够改变Zookeeper服务器状态的操作,也成为事务操作或更新操作。一般包括数据节点创建与删除、数据节点内容更新、客户端会话创建与失效等操作。对于每一个事务请求,Zookeeper都会为其分配一个全局唯一的事务ID,用ZXID表示,通常是一个64位的数字。每一个ZXID对应一次更新操作,从这些ZXID中可以间接的识别出Zookeeper处理这些更新操作请求的全局顺序。
二、节点特性
1.节点类型
在Zookeeper中,每个数据节点都是由生命周期的,其生命周期的长短取决于数据节点的节点类型。在Zookeeper中,节点类型分为持久节点(PERSISTENT)、临时节点(EPHEMERAL)、顺序节点(SEQUENTIAL)三大类,通过组合使用,可以生成四种组合型节点类型。
持久节点PERSISTENT
持久节点是zookeeper中最常见的一种节点类型。是指该数据节点被创建后,就会一直存在Zookeeper服务器上,直到由删除操作来主动清除这个节点。
持久顺序节点PERSISTENT_SEQUENTIAL
持久顺序节点的特性和顺序节点是一致的,额外的特性是表现在顺序性上。在Zookeeper中,每个父节点都会为它的第一级子节点维护一份顺序,用来记录每个子节点创建的先后顺序。在创建子节点的过程中,Zookeeper会自动为给定节点加上一个数字后缀,作为一个新的、完整的节点名。这个数字后缀的上限是整型的最大值。
临时节点EPHEMERAL
临时节点的生命周期和会话绑定在一起。如果客户端会话失效,那么这个节点就会被自动清理掉。客户端会话失效并非是TCP连接断开。Zookeeper规定了不能基于临时节点来创建子节点,即临时节点只能作为叶子节点。
临时顺序节点EPHEMERAL_SEQUENTIAL
2.状态信息
每个数据节点除了存储了数据内容之外,还存储了数据节点本身的一些状态信息。
三、版本-保证分布式数据原子性操作
Zookeeper中为数据节点引入了版本的概念,每个数据节点都有三种类型的版本信息,对数据节点的任何更新操作都会引起版本号的变化。
| 版本类型 | 说明 |
|---|---|
| version | 当前数据节点数据内容的版本号 |
| cversion | 当前数据节点子节点的版本号 |
| aversion | 当前数据节点ACL变更的版本号 |
Zookeeper中的版本表示的是对数据节点的数据内容、子节点列表、节点ACL信息的修改次数。即使前后两次变更没有修改数据内容的值,version的值依然会变更。
乐观锁控制事务分为三个阶段:数据读取、写入校验、数据写入,其中写入校验是整个乐观锁控制的关键所在。在zookeeper中,version属性正是用来实现乐观锁机制中写入校验的。
四、Watcher-数据变更的通知
Zookeeper提供了分布式数据发布/订阅功能。能够让多个订阅者同时监听某一个主题对象。当这个主题对象自身状态变化时,会通知所有订阅者,使他们能够做出相应的处理。在Zookeeper中,引入了Watcher机制来实现这种分布式的通知功能。Zookeeper允许客户端向服务端注册一个Watcher监听,当服务端的一些指定事件触发了这个Watcher,那么就会像指定客户端发送一个事件通知来实现分布式的通知功能。
Zookeeper的Watcher机制,主要包含客户端线程、客户端WatchManager和Zookeeper服务器三个部分。客户端在向Zookeeper服务器注册Watcher的同时,会将Watcher对象存储在WatchManager中。当Zookeeper服务端触发Watcher事件后,会向客户端发送通知,客户端线程从WatchManager中取出对应的Watcher对象来执行回调逻辑。注意:Watcher设置后,一旦触发一次后就会失效,如果想要一直监听,需要在process回调函数重新注册相同的Watcher。
1.Watcher接口
在Zookeeper中,接口Watcher用于表示一个标准的事件处理器,定义了事件通知的相关逻辑,包含了KeeperState和EventType两个枚举类,分别代表了通知状态和事件类型,同时定义了事件的回调方法process(WatcherEvent event)。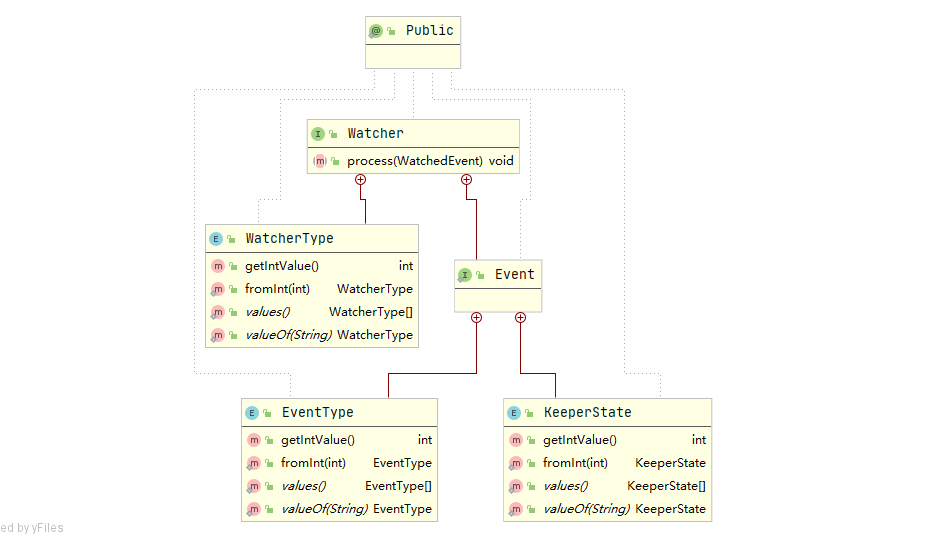
watcher事件
同一个事件类型在不同的通知状态中代表的含义不同。
| KeeperState | EventType | 触发条件 | 说明 |
|---|---|---|---|
| SyncConnected(3) | None(-1) | 客户端和服务端成功建立会话 | 此时,客户端和服务器处于连接状态 |
| NodeCreated(1) | Watcher监听的对应数据节点被创建 | ||
| NodeDeleted(2) | Watcher监听的对应数据节点被删除 | ||
| NodeDataChanged(3) | Watcher监听的对应数据节点的数据内容发生改变 | ||
| NodeChildrenChanged(4) | Watcher监听的对应数据节点的子节点列表发生改变 | ||
| Disconnected(0) | None(-1) | 客户端和服务器断开连接 | 客户端和服务器处于断开连接状态 |
| Expired(-112) | None(-1) | 会话超时 | 客户端会话失效,抛出异常 |
| AuthFailed(4) | None(-1) | 1.使用错误的scheme进行权限检查 2.SASL权限检查失败 |
同时也会收到AuthFailedException异常 |
回调方法process
process()方法是Watcher接口中的一个回调方法,当Zookeeper向客户端发送一个Watcher事件通知时,客户端就会对相应的process()方法进行回调,从而实现对事件的处理。
process()的参数为WatchedEvent。WatchedEvent包含了一个事件的三个基本属性:通知状态、事件类型、节点路径。Zookeeper使用WatchedEvent对象封装服务端事件并传递给Watcher,从而方便回调方法process对服务端事件进行处理。
public class WatchedEvent {private final KeeperState keeperState;//通知状态private final EventType eventType;//事件类型private String path;//节点路径public WatcherEvent getWrapper() {return new WatcherEvent(eventType.getIntValue(), keeperState.getIntValue(), path);}}
WatchedEvent和WatcherEvent
public class WatcherEvent implements Record {
private int type;
private int state;
private String path;
public void serialize(OutputArchive a_, String tag) throws IOException {
a_.startRecord(this, tag);
a_.writeInt(this.type, "type");
a_.writeInt(this.state, "state");
a_.writeString(this.path, "path");
a_.endRecord(this, tag);
}
public void deserialize(InputArchive a_, String tag) throws IOException {
a_.startRecord(tag);
this.type = a_.readInt("type");
this.state = a_.readInt("state");
this.path = a_.readString("path");
a_.endRecord(tag);
}
}
WatchedEvent是一个逻辑事件,用于服务端和客户端程序执行过程中所需的逻辑对象。而WatcherEvent实现了序列化接口,因此可以用来进行网络传输。
服务端在生成WatchedEvent事件后,会调用getWrapper方法,将自己包装为一个可序列化的WatcherEvent事件,以便通过网络传输到客户端。客户端在接收到服务端的这个事件对象后,首先将WatcherEvent事件还原为WatchedEvent事件,并传递给process方法进行处理。WatchedEvent和WatcherEvent都是对Zookeeper服务端事件及其简单的封装。客户端无法从该事件中获取到对应数据节点的原始数据内容以及变更后的新数据内容,而时需要客户端主动的去重新获取数据-这也是Zookeeper Watcher机制的一个非常重要的特性。
工作机制
Zookeeper的Watcher机制可以概括为三个过程:客户端注册Watcher、服务端处理Watcher、客户端回调Watcher。各组件之间关系图: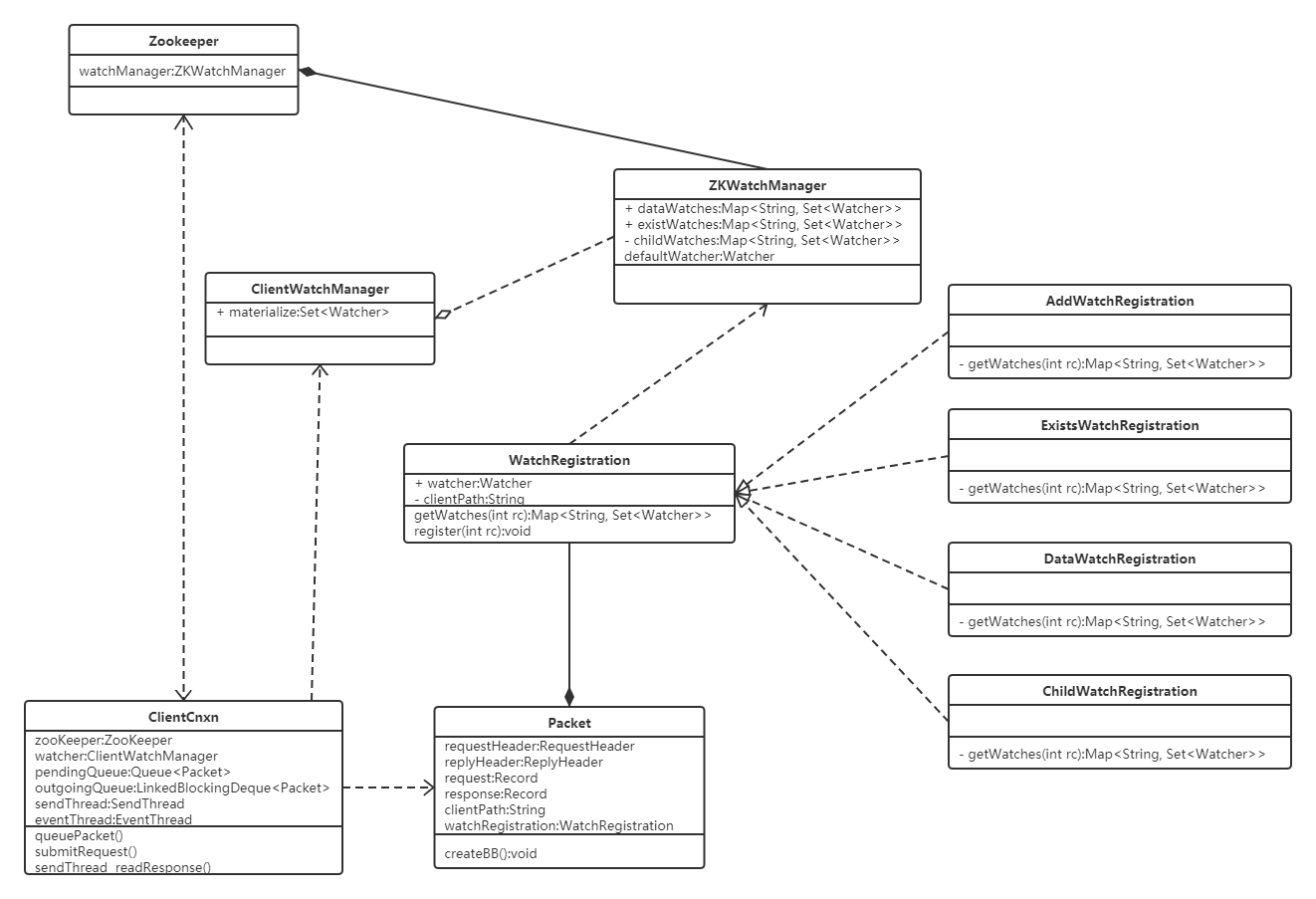
客户端注册Watcher
客户端注册watcher的方法: 实例化zookeeper时,构造方法传入、也可以通过getDate、getChildren和exist接口注册watcher。通过构造方法注册的Watcher将作为整个Zookeeper会话期间的默认watcher,会一直被保存在客户端ZkWatchManager的defaultWatcher中。
通过getData方法注册Watcher:
1.在向getData接口注册Watcher后,客户端首先会对当前客户端请求request进行标记,将其设置为使用Watcher监听,同时会封装一个Watcher的注册信息WatchRegistration对象,用于暂存数据节点路径和Watcher的对应关系。
public byte[] getData(final String path, Watcher watcher, Stat stat)
throws KeeperException, InterruptedException {
//创建数据内容注册信息
WatchRegistration wcb = null;
if (watcher != null) {
wcb = new DataWatchRegistration(watcher, clientPath);
}
final String serverPath = prependChroot(clientPath);
RequestHeader h = new RequestHeader();
h.setType(ZooDefs.OpCode.getData);
GetDataRequest request = new GetDataRequest();
request.setPath(serverPath);
//设置请求使用监听
request.setWatch(watcher != null);
GetDataResponse response = new GetDataResponse();
ReplyHeader r = cnxn.submitRequest(h, request, response, wcb);
...
}
2.在Zookeeper中,Packet是一个最小的通信协议单元,用于进行客户端和服务端的网络传输,任何需要传输的对象都需要包装成一个Packet对象。WatchRegistration会被封装到Packet中,然后放入发送队列中等待客户端发送。
public ReplyHeader submitRequest(
....
Packet packet = queuePacket(h,r,request,response, null, null,null,null,
watchRegistration, watchDeregistration);
....
synchronized (packet) {
if (requestTimeout > 0) {
// Wait for request completion with timeout
waitForPacketFinish(r, packet);
} else {
// Wait for request completion infinitely
while (!packet.finished) {
packet.wait();
}
}
}
if (r.getErr() == Code.REQUESTTIMEOUT.intValue()) {
sendThread.cleanAndNotifyState();
}
return r;
}
queuePacket方法
public Packet queuePacket( RequestHeader h, ReplyHeader r,Record request,Record response,
AsyncCallback cb, String clientPath,String serverPath, Object ctx,
WatchRegistration watchRegistration, WatchDeregistration watchDeregistration) {
Packet packet = null;
//watchRegistration监听注册信息封装到Packet中
packet = new Packet(h, r, request, response, watchRegistration);
// The synchronized block here is for two purpose:
// 1. synchronize with the final cleanup() in SendThread.run() to avoid race
// 2. synchronized against each packet. So if a closeSession packet is added,
// later packet will be notified.
synchronized (state) {
if (!state.isAlive() || closing) {
conLossPacket(packet);
} else {
// If the client is asking to close the session then
// mark as closing
if (h.getType() == OpCode.closeSession) {
closing = true;
}
//放入发送队列类型为LinkedBlockingDeque,等待客户端发送
outgoingQueue.add(packet);
}
}
sendThread.getClientCnxnSocket().packetAdded();
return packet;
}
void packetAdded() {
wakeupCnxn();
}
private synchronized void wakeupCnxn() {
selector.wakeup();
}
Zookeeper客户端就会向服务端发送这个请求,同时等待请求返回。完成请求发送后,由客户端SendThread线程的readResponse方法负责接收来自服务端的响应。finishPacket方法会从Packet中取出对应的Watcher并注册到ZKManager中。
if (p.watchRegistration != null) {
p.watchRegistration.register(err);
}
客户端将Watcher封装在WatchRegistration对象中,需要获取Watcher对象。
public void register(int rc) {
if (shouldAddWatch(rc)) {
Map<String, Set<Watcher>> watches = getWatches(rc);
synchronized (watches) {
Set<Watcher> watchers = watches.get(clientPath);
if (watchers == null) {
watchers = new HashSet<Watcher>();
watches.put(clientPath, watchers);
}
watchers.add(watcher);
}
}
}
在register方法中,客户端会将watcher保存在ZKManager.dataWatches中。dataWatches是一个Map
在底层网络传输序列化过程中,并没有将WatchRegistration对象完全序列化到底层字节数组中。只序列化了requestHeader和request。
public void createBB() {
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos);
boa.writeInt(-1, "len"); // We'll fill this in later
if (requestHeader != null) {
requestHeader.serialize(boa, "header");
}
if (request instanceof ConnectRequest) {
request.serialize(boa, "connect");
// append "am-I-allowed-to-be-readonly" flag
boa.writeBool(readOnly, "readOnly");
} else if (request != null) {
request.serialize(boa, "request");
}
baos.close();
this.bb = ByteBuffer.wrap(baos.toByteArray());
this.bb.putInt(this.bb.capacity() - 4);
this.bb.rewind();
} catch (IOException e) {
LOG.warn("Unexpected exception", e);
}
}
服务端处理Watcher

ServerCnxn存储
服务端在接收到来自客户端的请求后,在FinalRequestProcessor.processRequest()判断当前请求是否需要注册Watcher。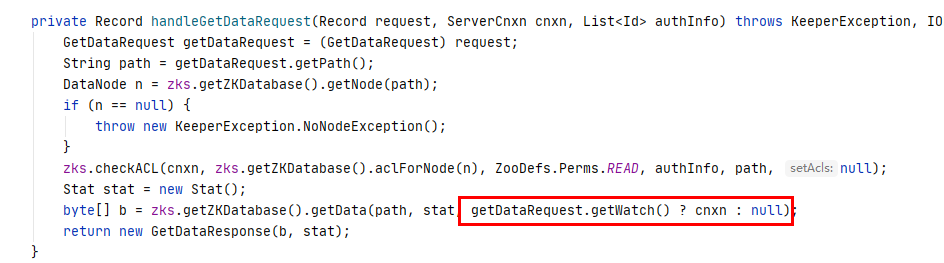
当getDataRequest.getWatch()为true的时候,Zookeeper就认为当前客户端请求需要进行Watcher注册。就会将当前节点路径path和ServerCnxn对象传入到getData方法中去。ServerCnxn是一个Zookeeper客户端和服务器之间的连接接口,代表了一个客户端和服务器的连接。ServerCnxn的默认实现是NIOServerCnxn,并且实现了Watcher的process接口,可以把ServerCnxn看作一个Watcher对象。数据节点的节点路径和ServerCnxn会被存储在WatchManager的watchTable和watch2Paths中。WatchManager还负责watcher事件的触发,并移除那些已经被触发的Watcher。在服务端,DataTree中会托管两个WatchManager,分别是DataWatches和childWatches,分别对应数据变更watcher和子节点变更watcher。
Watcher触发
对于标记了watcher注册的请求,Zookeeper会将其对应的ServerCnxn存储到WatchManager中。指定节点更新后,会通过WatchManager的triggerWatch方法来触发相关的事件。Watcher触发步骤如下:
1.封装WatchedEvent
首先将通知状态(KeeperState)、事件类型(EventType)以及节点路径(Path)封装成一个WatchedEvent对象。
2.查询Watcher
根据数据节点的节点路径从watchesTable取出对应的Watcher。如果没有找到Watcher。说明没有任何客户端在该数据节点上注册过Watcher,直接退出。如果找到了这个Watcher,会将其提取出来,同时会从watchesTable和watch2Paths中将其删除,所以Watcher在服务端是一次性的,触发一次就失效了。
3.调用process方法来触发Watcher
在这一步,会逐个一次调用步骤2中找出的所有watcher的process方法。实际上就是调用NIOServerCnxn的process方法。
public void process(WatchedEvent event) {
ReplyHeader h = new ReplyHeader(ClientCnxn.NOTIFICATION_XID, -1L, 0);
if (LOG.isTraceEnabled()) {
ZooTrace.logTraceMessage(
LOG,
ZooTrace.EVENT_DELIVERY_TRACE_MASK,
"Deliver event " + event + " to 0x" + Long.toHexString(this.sessionId) + " through " + this);
}
// Convert WatchedEvent to a type that can be sent over the wire
WatcherEvent e = event.getWrapper();
sendResponse(h, e, "notification", null, null, ZooDefs.OpCode.error);
}
主要逻辑如下:
①在请求头中标记-1,表明这是一个通知。
②将WatchedEvent包装成一个WatcherEvent,以便进行网络传输序列化。
③向客户端发送该通知。
ServerCnxn的process方法逻辑非常简单,本质上并不是处理客户端Watcher真正的业务逻辑,而是借助当前客户端连接的ServerCnxn对象实现对客户端的WatchedEvent传递。真正的客户端Watcher回调与业务逻辑执行都在客户端。
客户端回调Watcher
SendThread接收事件通知
对于一个来自服务端的响应,客户端都是由SendThread的readResponse进行统一处理。
case NOTIFICATION_XID:
LOG.debug("Got notification session id: 0x{}",
Long.toHexString(sessionId));
WatcherEvent event = new WatcherEvent();
event.deserialize(bbia, "response");
// convert from a server path to a client path
if (chrootPath != null) {
String serverPath = event.getPath();
if (serverPath.compareTo(chrootPath) == 0) {
event.setPath("/");
} else if (serverPath.length() > chrootPath.length()) {
event.setPath(serverPath.substring(chrootPath.length()));
} else {
LOG.warn("Got server path {} which is too short for chroot path {}.",
event.getPath(), chrootPath);
}
}
WatchedEvent we = new WatchedEvent(event);
LOG.debug("Got {} for session id 0x{}", we, Long.toHexString(sessionId));
eventThread.queueEvent(we);
return;
如果响应头replyHdr.getXid()中标识了xid为-1,表明这是一个通知类型的响应,处理过程如下:
①反序列化
Zookeeper客户端接收到请求后,首先会将字节流转换成WatcherEvent对象。
②处理chrootpath
③还原WatchedEvent
④回调Watcher
将WatchedEvent交给eventThread进行处理。
EventThread处理事件通知
queueEvent会根据该通知事件,从ZKWatchManager中取出所有相关的Watcher
if (materializedWatchers == null) {
// materialize the watchers based on the event
watchers = watcher.materialize(event.getState(), event.getType(), event.getPath());
}
public Set<Watcher> materialize(
Watcher.Event.KeeperState state,
Watcher.Event.EventType type,
String clientPath) {
Set<Watcher> result = new HashSet<Watcher>();
switch (type) {
case None:
result.add(defaultWatcher);
boolean clear = disableAutoWatchReset && state != Watcher.Event.KeeperState.SyncConnected;
synchronized (dataWatches) {
for (Set<Watcher> ws : dataWatches.values()) {
result.addAll(ws);
}
if (clear) {
dataWatches.clear();
}
}
synchronized (existWatches) {
for (Set<Watcher> ws : existWatches.values()) {
result.addAll(ws);
}
if (clear) {
existWatches.clear();
}
}
synchronized (childWatches) {
for (Set<Watcher> ws : childWatches.values()) {
result.addAll(ws);
}
if (clear) {
childWatches.clear();
}
}
synchronized (persistentWatches) {
for (Set<Watcher> ws: persistentWatches.values()) {
result.addAll(ws);
}
}
synchronized (persistentRecursiveWatches) {
for (Set<Watcher> ws: persistentRecursiveWatches.values()) {
result.addAll(ws);
}
}
return result;
case NodeDataChanged:
case NodeCreated:
synchronized (dataWatches) {
addTo(dataWatches.remove(clientPath), result);
}
synchronized (existWatches) {
addTo(existWatches.remove(clientPath), result);
}
addPersistentWatches(clientPath, result);
break;
case NodeChildrenChanged:
synchronized (childWatches) {
addTo(childWatches.remove(clientPath), result);
}
addPersistentWatches(clientPath, result);
break;
case NodeDeleted:
synchronized (dataWatches) {
addTo(dataWatches.remove(clientPath), result);
}
// TODO This shouldn't be needed, but just in case
synchronized (existWatches) {
Set<Watcher> list = existWatches.remove(clientPath);
if (list != null) {
addTo(list, result);
LOG.warn("We are triggering an exists watch for delete! Shouldn't happen!");
}
}
synchronized (childWatches) {
addTo(childWatches.remove(clientPath), result);
}
addPersistentWatches(clientPath, result);
break;
default:
String errorMsg = String.format(
"Unhandled watch event type %s with state %s on path %s",
type,
state,
clientPath);
LOG.error(errorMsg);
throw new RuntimeException(errorMsg);
}
return result;
}
客户端在识别出事件类型后,会从相应的Watcher存储中去除对应的Watcher。此处使用的是remove接口,因此客户端的Watcher也是一次性的,一旦被触发后,该Watcher就失效了。获取到所有Watcher后会放入waitingEvents队列中。waitingEvents是一个待处理Watcher的队列。EventThread的run方法会不断的对该方法进行处理。
public void run() {
try {
isRunning = true;
while (true) {
Object event = waitingEvents.take();
if (event == eventOfDeath) {
wasKilled = true;
} else {
processEvent(event);
}
if (wasKilled) {
synchronized (waitingEvents) {
if (waitingEvents.isEmpty()) {
isRunning = false;
break;
}
}
}
}
} catch (InterruptedException e) {
LOG.error("Event thread exiting due to interruption", e);
}
LOG.info("EventThread shut down for session: 0x{}", Long.toHexString(getSessionId()));
}
五、Watcher特性
一次性
无论是客户端还是服务端,一旦一个Watcher被触发,Zookeeper都会将其从相应的存储中移除。因此需要进行反复注册
客户端串行执行
客户端Watcher的回调过程是一个串行同步的过程,这为我们保证了顺序。
轻量
WatchedEvent是Zookeeper整个Watcher通知机制的最小通知单元,这个数据结构只包含了三部分内容:通知状态、事件类型、节点路径。
客户端向服务端注册Watcher的时候,并不会把真实的Watcher对象传递到服务端,仅仅是在客户端请求中使用boolean类型属性进行标记,同时服务端也仅仅只是保存了当前连接的ServerCnxn对象。
六、ACL-保障数据的安全
Zookeeper提供了一套完善的ACL权限控制机制来保障数据的安全。
在Linux文件系统中使用的,也是目前应用最广泛的权限控制方式-UGO权限控制机制。UGO针对一个文件或者目录,对创建者(User)、创建者所在组(Group)、其他用户(Other)分别配置不同的权限。UGO是一种粗粒度的权限控制。
另一种典型的权限控制方式ACL,即访问控制列表,是一种更细粒度的权限管理方式,可以针对任意用户和组进行细粒度的权限控制。
ACL介绍
Zookeeper的ACL权限控制是通过权限模式(Scheme)、授权对象(id)和权限(Permission),来标识一个有效的ACL信息。
权限模式(Scheme)
权限模式用来确定权限验证过程中使用的校验策略。在Zookeeper中,开发人员使用最多的就是以下四种权限模式。
IP

Digest
Digest是最常用的权限控制模式,类似于”username:password”形式的权限标识来进行权限配置,便于区分不同应用来进行权限控制。
当我们通过”username:password”形式配置了权限标识后,zookeeper会对其进行两次编码处理,分别是SHA-1算法加密和BASE64编码。
World

Super

授权对象ID
授权对象指的是权限赋予的用户或一个指定的实体,例如IP地址或是机器等,在不同的权限模式下,授权对象是不同的。
权限Permission
权限就是指那些通过权限检查后可以被允许执行的操作。在Zookeeper中,所有对数据操作的权限分为以下五大类:
CREATE(C)
DELETE(D)
READ(R)
数据节点的读取权限,允许授权对象访问该数据节点并读取其数据内容或子节点列表。
WRITE(W)
ADMIN(A)
数据节点的管理权限,允许授权对象对该数据节点进行ACL相关的设置操作。

若有收获,就点个赞吧
0 人点赞
