一、数据发布订阅(配置中心)
Zookeeper实现配置中心:znode能存储数据、Watch能监听数据改变。
配置方式:一个配置项一个znode、一个配置文件一个znode
配置信息通常具有三个特点:
1.数据量通常比较小
2.数据内容在运行时会发生动态变化
3.集群中各机器共享,配置一致
二、命名服务
zookeeper提供的命名服务功能,使应用系统通过一个资源引用的方式来实现资源的定位和使用。在分布式环境中,上层引用仅仅需要一个全局唯一的名字,类似于数据库中唯一的主键ID。而通过zookeeper可以创建一个顺序节点,并返回这个节点完整的名字。利用这个特性,就可以借助zookeeper生成一个全局唯一的ID。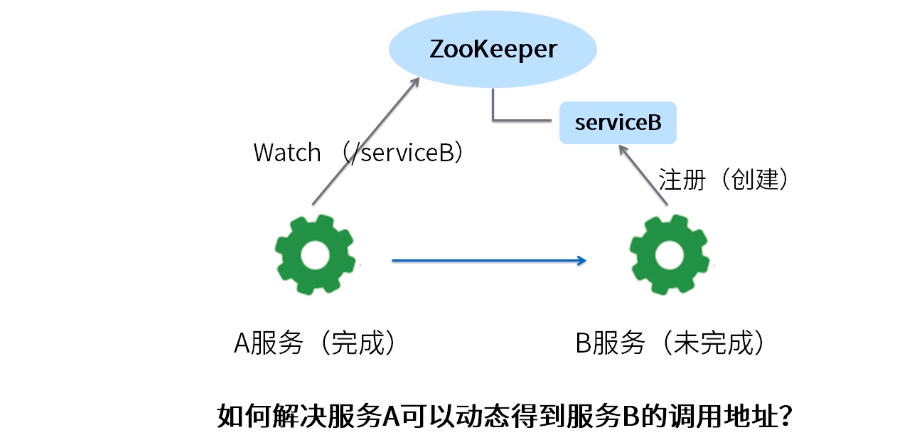
三、Master选举
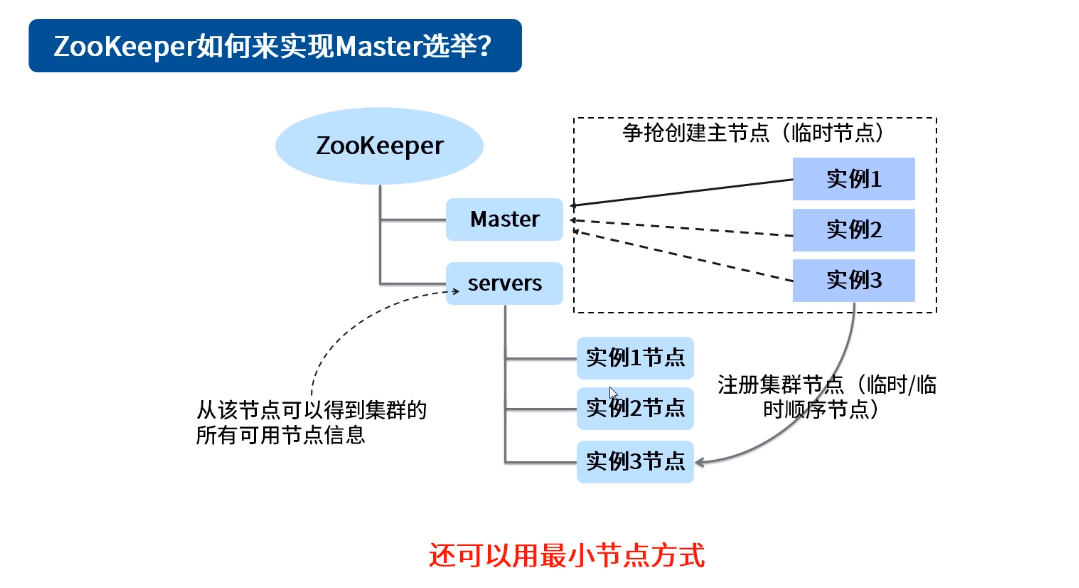
四、集群管理
集群管理包括集群监控和集群控制两大块。前者侧重对集群运行时状态的收集,后者则是对集群进行操作与控制。
zookeeper具有一下两大特性:
1.客户端如果对zookeeper一个数据节点注册Watcher监听,那么当该数据节点的内容或是其子节点列表发生变更时,zookeeper服务器就会向订阅的客户端发送变更通知。
2.对在zookeeper上创建的临时节点,一旦客户端与服务器之间的会话失效,那么该临时节点也会被自动清除。
利用zookeeper这两种特性,就可以实现一种集群机器存活性监控的系统。
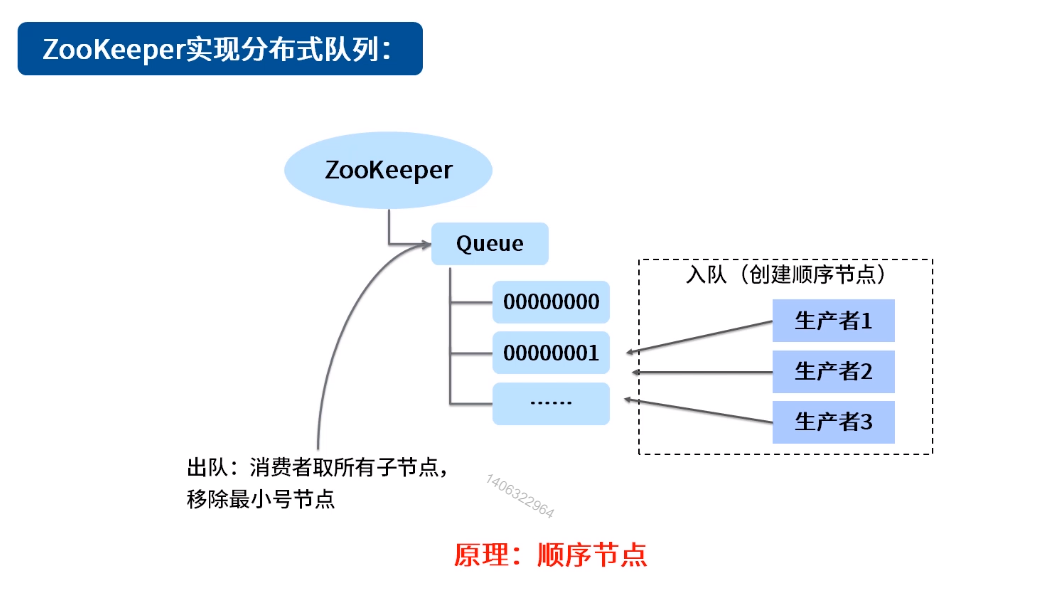
五、分布式队列
分布式队列,简单的分为两大类:一种是常规的先入先出队列,一种是要等到队列元素集聚之后才统一安排执行的Barrier模型。
1.FIFO
使用zookeeper实现FIFO队列和共享锁的实现非常类似。所有的客户端都会到/queue_fifo节点下面创建一个临时顺序节点。创建完成后根据如下步骤确定执行顺序。
(1)通过调用getChildrean()接口来获取/queue_fifo节点下面的所有子节点,即获取队列中所有的元素。
(2)确定自己节点在所有节点中的顺序。
(3)如果自己不是序号最小的节点,就进入等待,同时向比自己序号小的最后一个节点注册Watcher监听。
(4)接收到Watcher通知后,重复步骤一。
2.Barrier:分布式屏障
在分布式系统中,指系统之间的一个协调条件,规定了一个队列的元素必须都集聚后才能统一进行安排,否则一致等待。往往出现在大规模分布式并行计算的应用场景:最终的合并计算需要基于很多并行计算的子结果来进行。这些队列实在FIFO队列上面进行了增强。设计思想如下:开始时,/queue_barrier是一个已经存在的默认节点,并且将其节点的数据内容赋值为一个数字n来代表barrier的值,只有达到数值n后,才能开启barrier。之后所有的客户端都会到/queue_barrier节点下面创建一个临时节点。创建完成之后,按照如下步骤确定执行顺序。
(1)通过调用getData()接口,获取/queue_barrier节点的数据内容,即获取barrier的值。
(2)通过调用getChildren()接口获取/queue_barrier节点下面的所有子节点,同时注册对子节点列表变更的Watcher监听。
(3)统计子节点个数。
(4)如果子节点的个数小于n,进入等待。
(5)接收到Watcher通知后,重复步骤二
六、分布式锁
1.排他锁
1.1定义锁
通过zookeeper上的数据节点来表示一个锁,比如:/exclusive_lock/lock节点就可以被定义为一个锁。
1.2获取锁
在需要获取排他锁时,所有的客户端都会试图通过调用reate()接口,在锁节点下面创建临时节点,zookeeper能够保证,在所有的客户端中,只有一个客户端能够创建成功,那么就可以认为这个客户端获取到了锁。同时,没有获取到锁的客户端就需要到锁节点上注册一个子节点变更的Watcher监听,以便实时监听到lock节点的变更情况。
1.3释放锁
由于lock节点是临时节点,存在两种情况:
(1)当前获取到锁的客户端机器发生宕机,临时节点就会被移除。
(2)正常执行完业务逻辑后,客户端就会主动将自己创建的临时节点删除。
无论什么情况下删除了lock节点,zookeeper都会通知所有在/exclusive_lock上注册了子节点变更Watcher监听的客户端,这些客户端接收到通知,就可以重新发起获取分布式锁。
2.共享锁
2.1定义锁
用zookeeper上一个数据节点来表示,例如一个类似于/share_lock/[hostname]-请求类型-序号的临时顺序节点。
2.2获取锁
在需要获取锁的时候,所有的客户端都会到/share_lock下面创建一个临时顺序节点,如果当前是读请求,那么就会创建/share_lock/[hostname]-R-序号的节点,如果是写请求,那么就会创建/share_lock/[hostname]-W-序号的节点。
2.2.1判断读写顺序
根据共享锁定义,不同的事务都可以同时对同一个数据对象进行读取操作。而更新操作必须在当前没有任何事务进行读操作的情况下进行。基于这个原则,可以通过如下步骤来确定分布式读写顺序。
(1)创建完节点后,获取/share_lock节点下所有的子节点,并对该节点注册子节点变更的Watcher监听。
(2)确定自己节点在所有子节点中的顺序。
(3)对于读请求,如果没有比自己序号小的子节点,或是所有比自己小的子节点都是读请求,那么就表明自己已经获取到了共享锁,同时开始执行读取逻辑。如果比自己小的子节点有写请求,就进入等待。
对于写请求,如果自己不是序号最小的子节点,就进入等待。
(4)接收到Watcher通知后,就重复步骤一。
2.3释放锁
释放锁的逻辑和排他锁是一致的。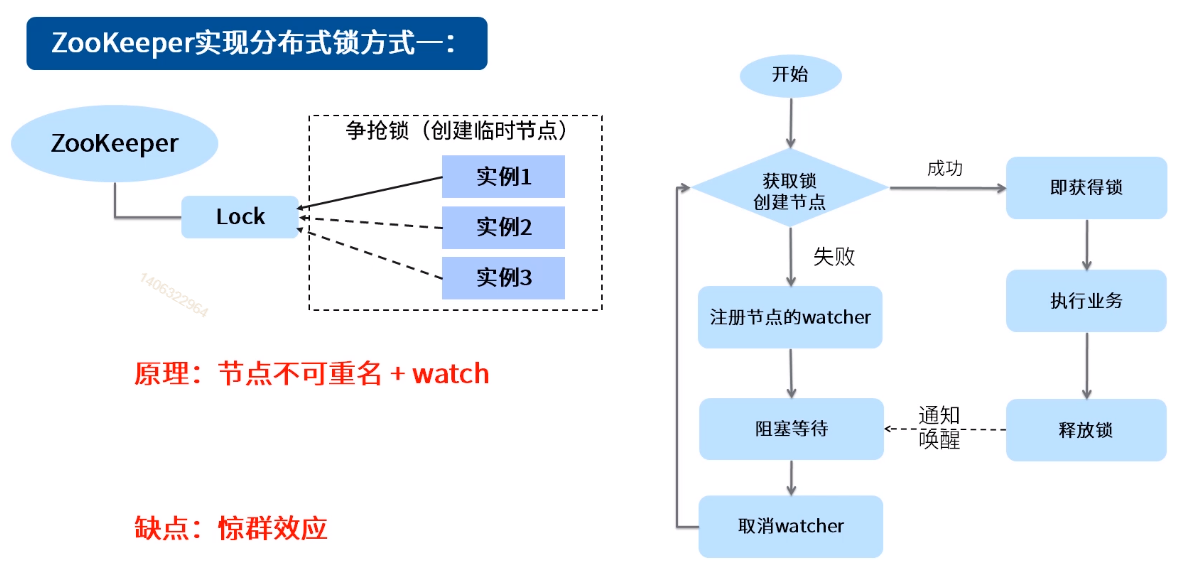

七、负载均衡
1.域名配置
2.域名解析
通常应用会从域名节点获取一份IP地址和端口的配置,进行自行解析。同时,应用还会再域名节点上注册一个数据变更Watcher的监听,以便收到域名变更的通知。
3.域名变更
对指定的域名节点进行变更操作,zookeeper会向订阅的客户端发送事件通知。应用接收到变更通知后,会重新获取域名配置。
八、分布式ID生成器
在分布式系统中,为每一个数据资源提供唯一性的ID标识功能。
在分布式系统中,分布式ID生成器的使用场景非常之多:
·大量的数据记录,需要分布式ID。
·大量的系统消息,需要分布式ID。
·大量的请求日志,如RESTful的操作记录,需要唯一标识,以便进 行后续的用户行为分析和调用链路分析。
·分布式节点的命名服务,往往也需要分布式ID。
传统的数据库自增主键或者单体的自增主键,已经不能满足需求。在分布式系统环境中,迫切需要一种全新的唯一ID系统,这种系统需要满足以下需求:
(1)全局唯一:不能出现重复ID。
(2)高可用:ID生成系统是基础系统,被许多关键系统调用,一旦宕机,就会造成严重影响。
分布式ID生成方案
1.Java的UUID
UUID是经由一定的算法机器生成的,为了保证UUID的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机 或伪随机数、时序等元素,以及从这些元素生成UUID的算法。UUID只能由计算机生成。
一个UUID是16字节长的数字,一共128位。转成字符串之后,它会 变成一个36字节的字符串,例如:3F2504E0-4F89-11D3-9A0C0305E82C3301。使用的时候,可以把中间的4个连字符去掉,剩下32字 节的字符串。
UUID的优点是本地生成ID,不需要进行远程调用,时延低,性能高。
UUID的缺点是UUID过长,16字节共128位,通常以36字节长的字符串来表示,在很多应用场景不适用,例如,由于UUID没有排序,无法保证趋势递增,因此用于数据库索引字段的效率就很低,添加记录存储入库时性能差。
所以,对于高并发和大数据量的系统,不建议使用UUID。
2.分布式缓存Redis生成ID:利用Redis的原子操作INCR和INCRBY, 生成全局唯一的ID。
3.Twitter的SnowFlake算法
Twitter(推特)的SnowFlake算法是一种著名的分布式服务器用户 ID生成算法。SnowFlake算法所生成的ID是一个64bit的长整型数字,如图10-2所示。这个64bit被划分成四个部分,其中后面三个部分分别表示 时间戳、工作机器ID、序列号。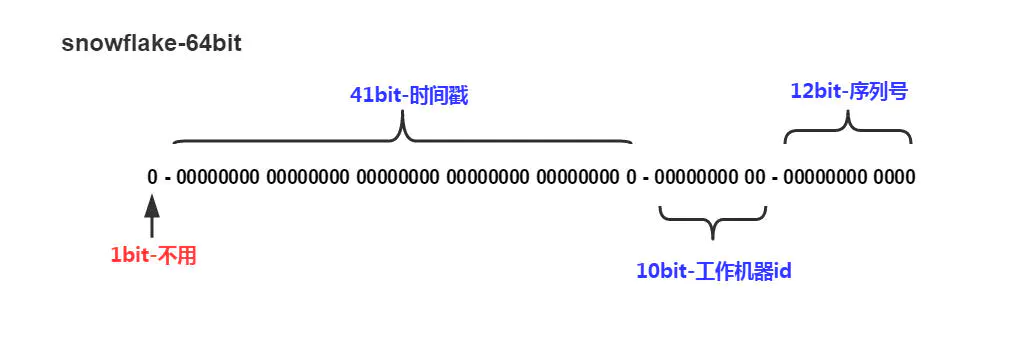
SnowFlakeID的四个部分,具体介绍如下:
(1)第一位 占用1 bit,其值始终是0,没有实际作用。因为二进制最高位表示符号位,0为正数。
(2)时间戳 占用41 bit,精确到毫秒。41位可以表示 个数字。也就是说41位可以表示
个数字。也就是说41位可以表示 个毫秒的值,转化成单位年则是
个毫秒的值,转化成单位年则是 年
年
(3)工作机器id 占用10 bit。可以部署在 个节点,包括5位datacenterId和5位workerId
个节点,包括5位datacenterId和5位workerId
- 5位(bit)可以表示的最大正整数是 ,即可以用0、1、2、3、….31这32个数字,来表示不同的datecenterId或workerId。
,即可以用0、1、2、3、….31这32个数字,来表示不同的datecenterId或workerId。
(4)序列号 占用12 bit。最多可以累加到4095。这个值在同一毫 秒同一节点上从0开始不断累加。
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
SnowFlake算法的优点:
·生成ID时不依赖于数据库,完全在内存生成,高性能和高可用性。
·容量大,每秒可生成几百万个ID。
·ID呈趋势递增,后续插入数据库的索引树时,性能较高。
SnowFlake算法的缺点:
·依赖于系统时钟的一致性,如果某台机器的系统时钟回拨了,有可能造成ID冲突,或者ID乱序。
·在启动之前,如果这台机器的系统时间回拨过,那么有可能出现 ID重复的危险。
4.ZooKeeper生成ID:利用ZooKeeper的顺序节点,生成全局唯一的 ID
在ZooKeeper节点的四种类型中,其中有以下两种具备自动编号的能力:
·PERSISTENT_SEQUENTIAL 持久化顺序节点。
EPHEMERAL_SEQUENTIAL 临时顺序节点。
ZooKeeper的每一个节点都会为它的第一级子节点维护一份顺序编 号,会记录每个子节点创建的先后顺序,这个顺序编号是分布式同步的,也是全局唯一的。这个顺序值的最 大上限就是整型的最大值。
5.MongoDb的ObjectId
MongoDB是一个分布式的非结构化NoSQL数据库,每插入一条记录会自动生成全局唯一的一个“_id”字段值,它是一个12字节的字符串,可以作为分布式系统中全局唯一的ID。

若有收获,就点个赞吧
0 人点赞
