文档级情感分类将一篇文章看为一个整体,并不研究文档内容中具体的实体和属性,是情感分析领域最为广泛研究的任务。该分类方式只能用于一种专门类型的观点文档。已有的关于文档级情感分类的文献都约定观点文档表达的观点仅针对一个单独实体,且只包含一个观点持有者的观点。
定义3.1(文档级情感分类):给定针对一个实体的观点文档 d,判断观点持有者对实体的整体的观点倾向性s。基于观点五元组的定义,这一任务特别对GENERAL属性(整个实体作为对象)表达的情感进行分类:( ,GENERAL, s, , _) 这里实体、观点持有者和观点的时间都已知或与问题无关,即这里仅需对s进行判别。如果 s取类别值就是一个分类问题。如果 s为数值或给定区间上的有序值,例如1~5星,这个问题就是回归问题。
文档级情感分类满足在线的产品和服务评论,因为在在线评论中,每则评论经常针对一个产品或服务,且也是由一个人写的。但对论坛讨论或者博客之类的场景就不一定成立了,因为这种类型的一篇文档中往往会包含多个观点,可以对多个实体进行评价且针对每个实体的观点倾向也可以不一样。
3.1 基于监督的情感分类
3.1.1 基于机器学习算法的情感分类
文本情感分类是一个文本分类问题,所以任何一种监督学习算法都可以直接应用,比如朴素贝叶斯分类或支持向量机(SVM)。和大多数监督学习应用一样,情感分类的关键还是抽取有效的特征。下面引出一些特征样例:
- 词和词频
- 词性:形容词是观点和情感的主要承载词。既可以把形容词当作专门的特征进行特别处理,也可以把词性标签和n-gram[1]作为特征混合使用。[2]
- 情感词和情感短语:是在语言中表达了正面或负面情感的词语。如:good、wonderful、bad、poor
- 观点的规则:很多文本结构或语言成分可以表示或隐含情感
- 情感转置词:可以反转文本中情感倾向的词语,如否定词。情感转置词需要特殊处理,因为并不是有这类词,句子情感就一定发生变化,如”not only … but also”
- 句法依存关系。确定句子的句法结构或者句子中词汇之间的依存关系。
此方向已经发表了大量文献,这里做一些简单介绍:
- Gamon(2004)针对顾客的反馈数据进行分类。这种数据相比评论信息来说,更短且含有更多的噪声。研究发现其深层语言特征同 n-gram类似。通过使用微软研究院的 NLPWin,他们获得了短语结构树并抽取了深层语言特征。这些特征包括POS trigram(词性三元组),特定文本成分的长度信息(句子、从句、形容词性和副词性短语、名字短语等的长度),句法树中每个成分基于上下文无关短语结构模式表示的成分结构(如DECL::NP VERB NP 表示一个由名词短语、动词、另一个名词短语依次组成的声明句),带语义关系的词性信息(如“Verb-Subject-Noun”表示一个动词谓语接名词主语)。
- Joshi和Penstein-Rose(2009)在词袋特征之外,把依存句法关系和相关衍生特征应用到分类过程中。句子的依存句法分析结果是一组三元组{reli, wj,wk},其中,reli是词 wj和 wk之间的依存句法关系。wj通常指首词( head word),wk 通常指修饰词( modifier word)。由这样的依存句法关系可以得到如 RELATION_HEAD_MODIFIER 形式的特征,这种形式的特征可以当作标准的词袋式二元特征,或基于计算频率的方式进行使用。比如“This is a great car”,在great和car之间有一个形容词限定(amod)句法关系,因此得到特征 amod_car_great。但是,这个特征针对性太强,我们可以对这一特征进行泛化,只使用首词的词性标签得到amod_N_great便可用到任意名词上。如果丢弃reli,amod_car_great就变成了两个特征N_great和car_J。
- 对于微博情感分类,Kouloumpis等(2011)使用了4种特征:(1)n-gram;(2)多角度问答(MPQA)主观性词典(Wilson et al.,2009);(3)动词、副词、形容词、名词和其他词性的数量统计;(4)正面、负面、中性的表情符号以及缩写和强调(如全部大写或字母重复)的二元特征。
- Pang和Lee(2004)提出只利用每条评论的主观部分作为特征进行情感分类。文档中临近的句子具有一定的语义关系,相邻的文本片段可能表达同样的主观性状态(主观或客观),其他方面在临近句子间也具有一致性。设评论中的句子序列为x1,…,xn。每个句子属于C1(主观)和C2(客观)中的其中一类。
- 个体的主观性得分 indj(xi)。基于每个xi内部的特征,判断其属于 Cj的非负估计。
- 联合得分 assoc(xi ,xk)。对于 xi和 xk 属于同一类的可能性的非负估计。
使用这些信息构造一个无向图 G,包括顶点{v1,…,vn,s,t},其中,v1,…,vn表示所有句子,s和t分别表示正类和负类。算法向图中添加了n条边(s,vi),每条边权重为ind1(xi),以及另外n条边(vi,t),每条边权重为ind2(xi)。最后我们加入了#card=math&code=%5Cleft%28%20%5Cbegin%7Barray%7D%20%7B%20l%20%7D%20%7B%20n%20%7D%20%5C%5C%20%7B%202%20%7D%20%5Cend%7Barray%7D%20%5Cright%29&id=PnhYU)条边(vi,vk),每条边权重为 assoc(xi,xk )。分类任务就变为寻找这张图上的一个最小割的优化问题。个体的主观性得分 ind1(xi)由句子级主客观分类器给出,例如,朴素贝叶斯可以给出当前句子属于每个类的概率,联合得分assoc(xi,xk)则基于两个句子间的距离计算得到。这种分类方法比使用所有评论得出的分类结果更准确。
- Liu 等(2010)研究了两种提升博客文本上情感分类准确性的办法。一种是基于信息检索的方法,找出每篇博客中与给定主题相关的句子,分类时不考虑那些与主题信息不相关的句子。另一种方法是采用简单的领域适应技术,该方法先从评论领域训练几个分类器,然后利用训练得到的分类器对博客领域的文本进行分类,并把结果作为额外特征加入博客数据的训练过程之中。
- 现有方法都使用了 n-gram 特征(通常是词袋),并使用信息检索领域中不同的方法来计算特征权重。Kim等(2009)比较了不同的权重计算方法组合的效果,包括:PRESENCE(看是否出现二元指标)、TF(词频)、VS.TF(向量空间模型(VS)中的归一化词频)、BM25.TF(使用BM25 中的归一化词频;Robertson and Zaragoza,2009)、IDF(逆文档频率)、VS.IDF(VS中的归一化 IDF 值)、BM25. IDF(BM25 模型中归一化的 IDF 值)。结果显示 PRESENCE 类型的特征效果非常好。Martineau和Finin(2009)提出的Delta TFIDF方法能更好地代表文档中的词在情感分类时的重要程度。
- Li等(2010)把个人句定义为句子的主语是(或者代表了)某人,而非个人句的主语则不代表人。他们分别使用个人句、非个人句和所有句子训练了f1、f2 和f3这三个分类器。这三个基本分类器分别使用他们的后验概率将其结果进行加权合并,用于最终类别的判别。
- Qiu等(2009)将基于词典和自学习的方法相结合,基于词典的方法使用了已给定情感词和情感短语来判别当前文档或句子的情感倾向。算法包括两个步骤:第一步使用了基于词典的迭代方法,先初步用情感词典把一些评论进行分类,再用正负类样例的比例控制来迭代地判别其他评论的类别。第二步是在训练分类器的时候,利用第一步得到的分类结果作为训练数据。再用这个分类器去修正第一步中的分类结果。这个方法的优点在于它不需要标注数据,所以它实际上是一个使用监督技术的无监督方法,因此可以用到任何领域中。
3.1.2 使用自定义打分函数的情感分类
研究者还提出了专门用于评论的情感分析技术,Dave等(2003)提出的打分函数就是其中之一。它基于正面和负面评论词,主要包含如下两步:
第一步。用下面的等式为训练集中的每个词(unigram或n-gram)进行打分:%20%3D%20%5Cfrac%20%7B%20%5Coperatorname%20%7B%20Pr%20%7D%20(%20t%20%20%7B%20i%20%7D%20%7C%20C%20)%20-%20%5Coperatorname%20%7B%20Pr%20%7D%20(%20t%20%20%7B%20i%20%7D%20%7C%20C%20%5E%20%7B%20%5Cprime%20%7D%20)%20%7D%20%7B%20%5Coperatorname%20%7B%20Pr%20%7D%20(%20t%20%20%7B%20i%20%7D%20%7C%20C%20)%20%2B%20%5Coperatorname%20%7B%20Pr%20%7D%20(%20t%20%20%7B%20i%20%7D%20%7C%20C%20%5E%20%7B%20%5Cprime%20%7D%20)%20%7D%0A#card=math&code=score%28%20t%20%20%7B%20i%20%7D%20%29%20%3D%20%5Cfrac%20%7B%20%5Coperatorname%20%7B%20Pr%20%7D%20%28%20t%20%20%7B%20i%20%7D%20%7C%20C%20%29%20-%20%5Coperatorname%20%7B%20Pr%20%7D%20%28%20t%20%20%7B%20i%20%7D%20%7C%20C%20%5E%20%7B%20%5Cprime%20%7D%20%29%20%7D%20%7B%20%5Coperatorname%20%7B%20Pr%20%7D%20%28%20t%20%20%7B%20i%20%7D%20%7C%20C%20%29%20%2B%20%5Coperatorname%20%7B%20Pr%20%7D%20%28%20t%20%20%7B%20i%20%7D%20%7C%20C%20%5E%20%7B%20%5Cprime%20%7D%20%29%20%7D%0A&id=ItaAs)
其中,t是一个词,C是一个类别,C’是它的补集,即非C,Pr(ti |C)是词 ti属于类别C的条件概率,通过将出现了ti的C类别文档数除以C类的总评论数计算得到。一个词的得分就是这个词对某个倾向类别相关度的度量,取值范围为-1到1。
第二步。将一个新文档di =t1…tn,所有词的情感倾向性得分加起来,根据得分求得这篇文档的分类:
%20%3D%20%5Cleft%5C%7B%20%5Cbegin%7Barray%7D%20%7B%20l%20l%20%7D%20%7B%20C%20%7D%20%26%20%7B%20%5Csum%20%20%7B%20j%20%7D%20%5Ctext%20%7B%20score%20%7D%20(%20t%20%20%7B%20j%20%7D%20)%3E0%20%20%7D%20%5C%5C%20%7B%20C%20%5E%20%7B%20%5Cprime%20%7D%20%7D%20%26%20%7B%20%5Ctext%20%7B%20%E5%85%B6%E4%BB%96%20%7D%20%7D%20%5Cend%7Barray%7D%20%5Cright.%0A#card=math&code=%5Coperatorname%20%7B%20class%20%7D%20%28%20d%20%20%7B%20i%20%7D%20%29%20%3D%20%5Cleft%5C%7B%20%5Cbegin%7Barray%7D%20%7B%20l%20l%20%7D%20%7B%20C%20%7D%20%26%20%7B%20%5Csum%20%20%7B%20j%20%7D%20%5Ctext%20%7B%20score%20%7D%20%28%20t%20_%20%7B%20j%20%7D%20%29%3E0%20%20%7D%20%5C%5C%20%7B%20C%20%5E%20%7B%20%5Cprime%20%7D%20%7D%20%26%20%7B%20%5Ctext%20%7B%20%E5%85%B6%E4%BB%96%20%7D%20%7D%20%5Cend%7Barray%7D%20%5Cright.%0A&id=bAPZt)
实验使用了包括7种产品超过13000 多条评论的数据集。结果显示选用bigram(两个连续词)和trigram(三个连续词)特征能够达到最高的准确率(84.6%~88.3%)。他们也尝试使用WordNet、词干归一化、否定词、搭配词等语言学的处理方式,但是实验结果表明:这些操作并不那么有效,反而会降低分类的准确性。3.2 基于无监督的情感分类
情感词常常主导情感分类结果,因此可以将它们以无监督的方式进行情感分类。3.2.1 使用句法模板和网页检索的情感分类

第一步。按照表3-2中所给的基于词性标记的模板在评论文本中抽取符合模板的两个连续的词。比如,模式2表示要抽取的两个连续词中第一个是副词,第二个是形容词,且后面跟着的词不能是名词。
第二步。用互信息(Pointwise Mutual Information,PMI)来估计所抽取短语的情感倾向性(SO):%20%3D%20%5Coperatorname%20%7B%20log%20%7D%20%20%7B%202%20%7D%20(%20%5Cfrac%20%7B%20Pr%20(%20%5Coperatorname%20%7B%20term%20%7D%20%20%7B%201%20%7D%20%5Cwedge%20%7Bterm%7D%7B2%7D%20)%20%7D%20%7B%20Pr%20(%20%7B%20term%20%7D%20%20%7B1%7D)Pr(%7Bterm%7D%7B2%7D)%20%7D%20)%0A#card=math&code=P%20M%20I%20%28%20%5Coperatorname%20%7B%20term%20%7D%20%20%7B%201%20%7D%20%2C%20%5Coperatorname%20%7B%20term%20%7D%20%20%7B%202%20%7D%20%29%20%3D%20%5Coperatorname%20%7B%20log%20%7D%20%20%7B%202%20%7D%20%28%20%5Cfrac%20%7B%20Pr%20%28%20%5Coperatorname%20%7B%20term%20%7D%20%20%7B%201%20%7D%20%5Cwedge%20%7Bterm%7D%7B2%7D%20%29%20%7D%20%7B%20Pr%20%28%20%7B%20term%20%7D%20%20%7B1%7D%29Pr%28%7Bterm%7D%7B2%7D%29%20%7D%20%29%0A&id=UegJB)
PMI衡量的是两个词之间统计上的依存程度。此处 Pr( term1 ∧ term2 )是词 term1和 term2 的真实共现概率,如果这两个词之间相互独立,则 Pr(term1)Pr(term2)是两个词的共现概率。短语的情感倾向SO用它们与正面情感词excellent和负面情感词poor间的关联度计算得到:%20%3D%20PMI(phrase%2C%22excellent%22)%20-%20PMI(phrase%2C%22poor%22)%0A#card=math&code=SO%28phrase%29%20%3D%20PMI%28phrase%2C%22excellent%22%29%20-%20PMI%28phrase%2C%22poor%22%29%0A&id=bVs4W)
概率值可以通过将这两个词作为 query提交给搜索引擎,并统计返回文档数的方法进行计算。对于每个查询,搜索引擎会给出相关文档的数目,我们称之为命中数。因此,通过合起来搜索两个词,以及分别搜索每个词,就能统计(3)中的概率。Turney(2002)在其方法中使用了AltaVista 搜索引擎,因为它有一个NEAR操作符可以限制两个词在文档中间隔的距离不超过10个词。将命中数记为hits(query),则(4)可以写为:
第三步。给定一个评论,计算所有短语的 SO 值,如果平均 SO 值为正,则该评论的情感为褒义,反之为贬义情感。
最终最高准确率出现在汽车评论领域内,为84%,最低准确率出现在电影评论领域内,为66%。3.2.2 使用情感词典的情感分类
另一种无监督的方法是基于情感词典的分类方法。该种方法基于一个包含已标注的情感词和短语的词典,每篇文档的情感得分还需要结合情感加强词和否定词来进行计算。这种方法对于表达了正面情感的文本表达(词或短语)都赋予了一个正的SO值,而每个表达了负面情感的文本表达都赋予一个负的SO值。基本形式是将文档中所有情感表达的SO值求和,通过SO值的正、零、负,将文档判定为包含正面、中性、负面情感。该方法有很多变种,主要的不同在于每个情感的表达被赋予什么样的值,否定词如何处理,是否考虑新增信息等。
Kennedy和Inkpen(2006)研究了情感加强词和减弱词。该论文将所有的正面情感赋值为2。如果前面有同一从句中出现加强词,就赋值为3。如果前面有同一从句的减弱词,值就为1。
Taboada等(2011)对于上述方法进行扩展,进一步考虑更精细的情形。每个情感表达的SO值范围是-5(极度否定)到+5(极度肯定)。每个加强词和减弱词都有一个或正或负的权重百分比。例如,slightly 是-50,somewhat 是-30,,而(the)most是+100。加强词和减弱词从最靠近情感表示开始,顺序地逐步加入SO值的计算:如果good的SO值为3,则really very good的SO值就为[3 x(100% +25%)] x(100% +15%)=4.3。
在很多情况下,当遇到否定词时,简单反转SO 值会有问题。比如excellent是一个SO值为+5 的形容词;如果将其与否定词搭配就变成not excellent,其SO 值为-5。实际上,not excellent 看起来比 not good 还要偏向正面的情感倾向,给一个-3之类的值
就可以。为了捕获这样的实际感觉,SO 值会向着相反极性方向移动一个固定值(如4)。因此一个情感倾向值为+2的形容词,当遇到一个否定词时,其情感倾向会被否定到-2。因此,否定词从某种意义上来说也变成了一个情感减弱词。
Kennedy和Inkpen(2006)还注意到,基于词典的情感分类器通常会偏向正的情感倾向。为了抹平这种误差,Taboada等(2011)为所有负面的最终SO值增加了50%,从而为相对少见的负面词赋予了更多的权重。3.3 两种方法的对比
监督学习用一个领域数据训练得到的分类器不能用到另一个领域(见3.4节)。因此,每个应用领域都需要训练数据才能获得精准的分类。而基于词典的方法不需要训练数据,因而相对于监督学习的方法更具优势。3.4 情感评分预测
预测评论打分(如1~5星)一般被形式化为回归问题。但并不是所有研究者都采用回归的方法解决这一问题。
Pang和Lee(2005)尝试了SVM回归、基于一对多(One-Versus-All,OVA)策略的SVM多类分类,以及被称作度量标注的元学习的不同方法。结果显示基于OVA的分类比其他两者效果差得多。这一结论也比较容易理解,毕竟数值化的打分不是类别值。Goldberg 和Zhu(2006)将评分预测问题建模为基于图的半监督学习问题,既带有标注数据也有未标注数据。未标注数据是需要进行预测打分的评论。在这个图中,每个节点是一个评论文档,两个节点之间连接的权重是两个文档的相似度。相似度很高表明两个文档的评分很相近。
Qiu等(2010)修改了传统的词袋表示,引入了文档的“观点袋”(bag-of-opinion)表示,以捕获观点中n-gram的情感强度。他们认为每个观点都是一个三元组,包含情感词、修饰词和否定词。对于两类情感分类,观点修饰词、否定词不太重要,但对于评分预测就很有用了。他们利用有约束的岭回归(ridge regression)算法在领域无关语料中学习观点强度或情感得分。
Long等(2010)用了与Pang和Lee(2005)类似的方法,但他们使用了贝叶斯网络分类器来预测每个属性的评分。为了得到较好的准确率,他们没有对每一篇评论都进行预测,而是只关注那些对于属性进行了全面评价的评论,并从中预测出针对属性的评分。然后利用机器学习算法对所选评论的属性进行评分预测,训练用到的特征仅来自于属性相关的句子。3.5 跨领域情感分析
Aue 和 Gamon(2005)结合目标领域的少量标注数据和大量未标注数据(传统的半监督学习方式)。这种策略使用期望最大化(Expectation Maximization,EM)的半监督学习(Nigam et al.,2000)。他们的实验表明,这种策略的效果非常好。
Yang等(2006)提出了一种基于特征选择的简单策略,用于句子级分类的迁移学习任务。他们先用了两个领域内充分的标注数据来选出两个领域都有效的特征。这些特征被视为领域无关的,用它们构造的分类器被认为能用到任何目标领域。
Blitzer等(2007)早期提出结构化对应学习的方法(Structural Correspondence Learning,, SCL)(Blitzer et al.,2006)来做领域自适应。给定源领域的标注数据和未标注数据,以及目标领域的未标注数据,SCL算法先选择了两个领域都频繁出现的m个特征,它们对源领域预测效果最好。其次,SCL计算每个中轴特征和每个领域的非中轴特征的相关性,得到相关矩阵W,建立起两个领域的特征对应关系。之后使用SVD分解计算W的一个低维线性近似。最终用来训练和测试的特征就是原始特征
及其变换后的
,即 k个实值特征。基于这一特征集和源领域的标记数据所构建的分类器可以在源领域和目标领域都取得很好的结果。
Bollegala 等(2011)提出一种方法可以用多个源领域的标注和非标注数据构造一个基于情感信息的同义词库,这样便于找到不同领域中具有相似情感的词之间的联系。这个同义词库可以用来扩展原始特征向量,用于训练一个两类情感的分类器。Yoshida等(2011)通过识别领域相关、领域无关的情感词,给出了一种从多个源领域到多个目标领域的情感迁移方法。
Wu等(2009)提出一种基于图的方法来做领域迁移。这个图中每个文档是一个节点,每条边表示文档间的相似度。每个源领域的文档标签值初始化为+1或-1,每个目标领域的标签值则可以基于一个普通情感分类器训练得到。之后算法就进行迭代,针对每个目标领域i,通过找出其上个源领域的最近邻和k个新领域的最近邻,将这些邻居的标签得分进行线性组合,以此来更新当前样本i的标签值。整个算法当标签值收敛时停止迭代。目标领域的情感倾向标签依据它们的文档标签得分进行确定。结论显示,基于图的方法在领域适应问题上给出了很有竞争力的结果。3.6 跨语言情感分类
已有大部分研究工作都是针对英语的,我们可以利用机器翻译和现有的英语情感分析系统资源和工具来构建其他语言的类似系统。
Wan(2008)利用英语的情感资源做中文的评论分类。第一步是用多个翻译引擎把每条中文评论都翻译为英文,得到多个不同的英语版本。之后他们用基于词典的情感分类方法对每份英语翻译进行分类。最后把评论中所有情感表达在考虑了情感加强和情感否定之后的情感得分加起来来判定情感倾向。然后,他们用不同的组合方法对评论不同翻译的得分进行组合(平均、最大值、加权平均等)获取情感分类结果。
Wan(2009)提出了一种用英语标注语料进行协同训练的方法,通过监督学习的手段进行中文评论分类,而该方法没有用到任何中文资源。在训练时,输入为一组有标注的英文评论和一组未标注的中文评论。有标注的英文评论会被翻译成中文,而未标注的中文评论会被翻译成英文。于是每条评论就都有一个英文版本和中文版本。英文特征和中文特征被看作同一评论的两个独立而冗余的不同表示。之后该方法使用基于SVM的协同训练方法训练出两个分类器,之后再合并为一个分类器。测试时每条未标注的中文评论都先翻译为英文,再用上述训练得到的分类器将其分为正面的情感或负面的情感。Wan(2013)使用了一个协同回归的方法预测跨语言评论的打分,该方法也用了协同训练的想法。
[1] 词袋模型,即N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段(gram)序列,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
[2] 本书中使用宾州树库词性标签集表示不同的词性。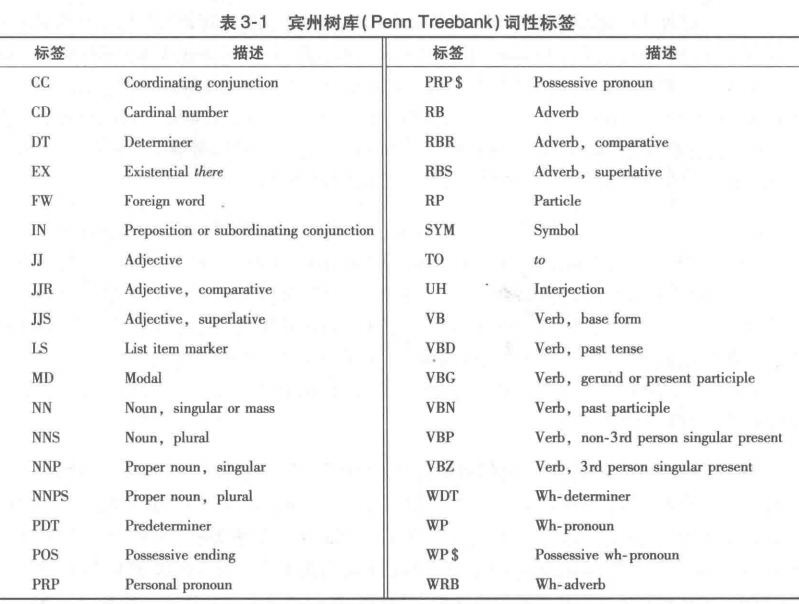

若有收获,就点个赞吧
0 人点赞
