systemd
http://www.ruanyifeng.com/blog/2016/03/systemd-tutorial-commands.html
systemctl
systemd的control cli
systemctl enable nginx.servicesystemctl disable nginx.servicesystemctl start nginx.servicesystemctl restart nginx.servicesystemctl list-units --type=service # 查看所有服务
/proc/pid
- linux以文件系统的访问方式提供了各个进程状态的访问
readlink -e /proc/pid/cwd // 获取进程的cwd 等价于 lsof -p pid | grep cwd
建立服务
vim /usr/lib/systemd/system/nginx.service
[Unit]Description=nginx - high performance web serverAfter=network.target remote-fs.target nss-lookup.target[Service]Type=forkingExecStart= /www/server/nginx /sbin/nginx -c /www/server/nginx /conf/nginx.confExecReload= /www/server/nginx /sbin/nginx -s reloadExecStop= /www/server/nginx /sbin/nginx -s stop[Install]WantedBy=multi-user.target
Type
- Type=simple(默认值):systemd认为该服务将立即启动。服务进程不会fork。如果该服务要启动其他服务,不要使用此类型启动,除非该服务是socket激活型。Type=forking:systemd认为当该服务进程fork,且父进程退出后服务启动成功。对于常规的守护进程(daemon),除非你确定此启动方式无法满足需求,使用此类型启动即可。使用此启动类型应同时指定 PIDFile=,以便systemd能够跟踪服务的主进程。
- Type=oneshot:这一选项适用于只执行一项任务、随后立即退出的服务。可能需要同时设置 RemainAfterExit=yes使得systemd在服务进程退出之后仍然认为服务处于激活状态
- Type=notify:与 Type=simple相同,但约定服务会在就绪后向systemd发送一个信号。这一通知的实现由 libsystemd-daemon.so提供。
- Type=dbus:若以此方式启动,当指定的 BusName 出现在DBus系统总线上时,systemd认为服务就绪
ssh
使用的协议为SSL/TLS,先使用非对称加密进行协商,之后使用对称加密进行数据的传输
使用上一步生成的shared key 以及非对称加密进行authentification
每一次链接的shared key都不一样,但是用于authentification的key是一样的
所以才可以免密登录,将客户端的pub_key写到服务端的authorized_keys中
~/.ssh/known_hosts 中记录的链接过的服务端的pub_key
~/.ssh/authorized_keys 中记录了无需密码验证的客户端的pub_key
- 服务端:每次有客户端链接的时候会先查询authorized_keys中有无记录,如果有记录的话验证通过,不再需要密码输入以及互传pub_keys
- 客户端:每次链接服务端的时候,会查询服务端的pub_key是否存在于known_hosts中,如果不存在,用户需要输入YES讲服务端的pub_key保存到known_hosts中
命令
```bash /etc/init.d/sshd restart # 启动ssh服务端
debug
$(which sshd) -Ddp 10222
配置服务端
vim /etc/ssh/sshd_config
修改端口
Port 23
禁止Root用户ssh登录
PermitRootLogin no
客户端
ssh -f -o no -p 23 name@ip command -o no #可以自动将服务端的pub_key加入到known_host中,而无需输入yes -f #无需等待服务端的命令执行完毕,让其后台运行。 -p #指定端口,默认是22
执行命令
ssh adm@$host \ “if [ ! -d ~/.ssh ]; then ssh-keygen -t rsa -P ‘’; fi “
传输数据并执行命令
cat ~/.ssh/id_rsa.pub | ssh adm@$host \ “cat >> ~/.ssh/authorized_keys && chmod 600 ~/.ssh/authorized_keys”
<a name="FYBes"></a>##### SFTP使用SSH进行文件的传输,交互式<br /><a name="6O6NT"></a>##### SSH通道加密无加密的服务wait<a name="pTDzp"></a># apt<a name="GsclK"></a>##### 添加源后apt update报key认证的错- 需要手动向服务器申请认证```bashapt install xxx // error# The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 7EA0A9C3F273FCD8sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 7EA0A9C3F273FCD8apt install xxx // ok
screen
A terminal multiplexer.
screen -S name // create a session-ls // list all sessions-r name // attach this session
nprsh
execute commands in multiple nodes in parallele
mprsh -on node1..12 uptime
pscp
pscp -h client_list /etc/password /etc/password
iftop
top for networks
- B denotes bytes, are used in storage area
- b denotes bits, are used in networking area
- for example: we say 10G nc, it’s 10 000 Mbps, when converted to what we talk in storage area, it’s 10G/8 = 1.25GB/s
- RX/TX denotes receive and transmit respectively.
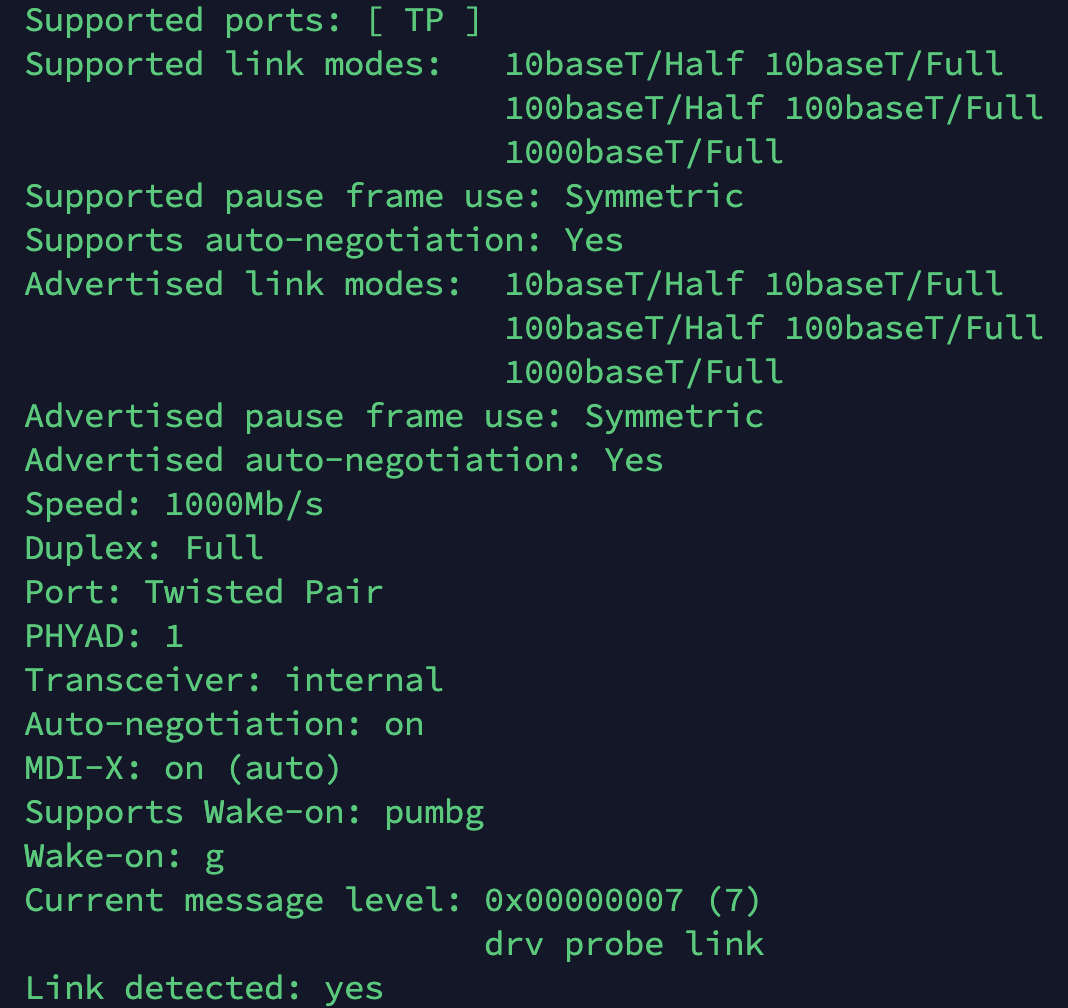
ethtool
configure nic devices
- wake on lan
- https://wiki.archlinux.org/index.php/Wake-on-LAN
- states: d(disabled), b(broadcast), a(arp), g(magic packet, must be open to let wol work)
- need use other softwares to send magic packets, for example:
wol,powerwake - can cross NAT
- speed
permanent
vim /etc/network/interfaces
post-up ethtool -s eno1 xxxxxx
or
ETHTOOL_OPTS=”speed 1000 duplex full autoneg on”
<a name="AAePj"></a># Raid<a name="kFFyU"></a>### RAID 0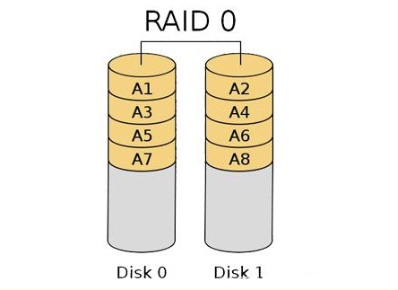<br />数据分块在不同磁盘中<br />利用率100%<br />读写:N<br />冗余无<a name="1gAIZ"></a># RAID 1数据做镜像备份<br />利用率50%<br />读: 1 写: < 1<br />冗余:有,只要存在镜像盘就可重建<a name="0KGaO"></a>### RAID 5最少3块盘,可以加热备盘,这样<br />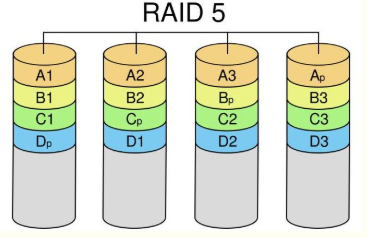<br />数据分块,存在奇偶校验,奇偶校验与数据存在不同的盘里,一块盘损坏,可以用其他盘奇偶校验重建<br />利用率: (N-1)/N<br />读: N -1 写: <1<br />冗余:只能损坏一块盘,多加N热备盘,则总共可以损失N个盘(坏后重建后再坏),注意重建必须要要有新的空盘(热备盘或者重新插入的健康盘),如果没有新盘的话,虽然数据没损失,但不存在冗余了。另外,可以强制将RAID重新分配,这样就可以不需要新盘了,但耗费时间且须停机。<a name="tjo1E"></a>### RAID6与RAID5相比新增另一奇偶校验块,可同时损坏两块盘<a name="oWrdE"></a>### RAID10 1+0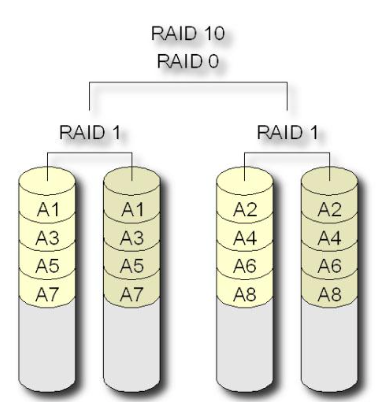<br />使用RAID0的分块,RAID1的镜像备份<br />磁盘利用率: 50%<br />读写: N/2<br />冗余:只要存在镜像盘就可重建<a name="wXzTt"></a># 分布式存储系统hdfs是将多个节点组合在一起,而raid是在单机上实现的<a name="x0yno"></a>## sar```bashsar -q load avrage-u cpu-r history memory usage
Send messages to users
wall "Message" // will send this message to all logged users// pts/15 is the tty opened by the user, can be feteched by ps auxwrite username pts/15 [Enter] messages [Ctrl + D]
SAN and NAS
- san: 存储设备通过光纤通道Fibre Channel与客户机使用FCP协议传输SCSI协议进行通信,block level storage
- 直接使用IO线路进行通信
- nas: 通过以太网与客户机使用TCP/IP进行通信, file level storage
block level storage
可以通过SCSI(FCP)/iSCSI(TCP)/SRP(IB)/iSER(TCP, RDMA)协议与远端主机通信,远端主机再使用 SCSI协议与真正的硬盘通信,这使得客户机就好像在与真正的硬盘进行通信,可访问磁盘的各个扇区
如果要使用文件系统的话,每个客户机都需要有自己的(可以不一样)文件系统
比如某些数据库公司(oracle)的产品为了提高速率(减少中间层),会直接访问硬盘,而不是访问文件系统
file level storage
通过远程主机提供的客户端使用其文件系统,客户端driver/软件通过TCP/IP,IB,ROCE,iWrap等协议与远程主机的文件系统服务端通信
文件系统只安装在远端主机,远端主机内部也是通过SCSI或者其他协议访问本地/远端block level storage
每个客户机只需要安装文件系统提供的客户端driver并挂载该文件系统即可,并不包含真正的文件系统
与block level的区别是,除非使用了RDMA技术,否则,服务器存储设备的文件需要经过SCSI总线,PCIE总线,系统总线,再拷贝到内存中,之后再原路返回到网卡中,期中还需要cpu参与拆解包,而block level不需要cpu参与,网卡通过PCIE总线直接发送SCSI命令到SCSI总线,再到存储设备,获取数据后直接返回。
存储的层次
hard drive -> raid -> disk subsystem ——scsi——> filesystem —-local or remote—-> opearting system
File system
比如FAT32/ext4等文件系统
文件系统相比于block level的好处是由于文件都是有组织形式的,可以准确快速的prefetch file,提高读速率
Protocols

FCP
与FC线,交换机,路由,网卡共同工作的传输协议,上层通过安装驱动以封装SCSI和IP接口,使得计算机把通过FCP连接的设备当做是正常的SCSI设备或者以太网设备
FCP SAN中就是使用FCP协议传输的SCSI命令
iSCSI
通过驱动的形式,封装SCSI接口,让SCSI协议通过TCP/IP进行传输,但是封装iSCSI和解包TCP/IP协议会占用cpu资源,所以有的主板还有专门的的iSCSI HBA卡/TOE卡,可以专门处理iSCSI和TCP/IP之间的转换,减轻CPU负担,或者有的主板上
无盘系统可以使用该协议进行启动
(注:TOE网卡还能处理一些TCP/IP协议栈的拆解包,比如原本在内核处理的IP分片、TCP分段、重组、checksum校验)
iFCP
定义了FCP与TCP/IP的映射,常用于网关上连接FCP网络和IP网络
mFCP
使用的是UDP/IP传输协议
FCIP
一种隧道协议,使用TCP/IP传输FCP协议,用与使用以太网连接两个FCP网络
FCOE
Fibre Channel over ethernet
与iSCI类似,定义的是FCP与ethernet的mapping,将FCP帧包在以太网帧中,而FCP和以前一样一般用于传输SCSI命令
使得内部网,存储网和以太网整合在同一线路上
注意与FCIP和iSCSI的区别是,FCIP使用的是TCP协议包装,而FCOE直接使用以太网帧,减少了IP/TCP拆解包,与之相反的是由于不是IP/TCP包装,FCOE不能被路由,用于本地的LAN
IPoIB
ip over ib, 这也是为什么ib卡可以配置一个ipv4的地址,且可以使用ping进行ping通的原因
DMA
https://zhuanlan.zhihu.com/p/55142557
Direct memory access
允许计算机主板上的设备(DMA Engine)直接把数据移动到内存中,无需CPU参与
RDMA
即多个计算机之间可以通过网络直接访问其他计算机的内存,即直接在内存空间进行数据传输,该技术的实施就是一套相关的API,不同主机间通信还需要传输层协议进行传输
- zero-copy 数据不会经过TCP/IP网络协议栈各层
- kernel bypass 应用直接在用户态传输数据,无需内核态和用户态上下文切换
- 无需CPU干预(比如拷贝buffer,复制等)
- 与TCP/IP发送字节流不同,RDMA操作消息队列
支持该技术的传输协议
- ifniniBand,物理连接层协议,需要专门的网卡和交换机
- SRP 定义了SCSI与RDMA的mapping,可以使用RDMA传输协议传输SCSI命令
- RDMA over Ethernet,UDP传输IB帧,需要网卡支持RoCE
- RDMA over TCP,可以硬件支持(支持iWARP的网卡)或者软件支持
- SDP or iWARP,封装了TCP/IP接口,内部调用RDMA OVER TCP技术,NFS/CIFS等使用TCP/IP的技术无需改动就可以享受到RMDA技术的优点
- 可以硬件支持或者软件支持,但是软件支持并不能提高bandwith,只能减少接收双方的负载
- iSER iSESI的拓展,使用TCP传输SCSI命令,且支持RDMA技术
- SDP or iWARP,封装了TCP/IP接口,内部调用RDMA OVER TCP技术,NFS/CIFS等使用TCP/IP的技术无需改动就可以享受到RMDA技术的优点
infiniband
https://blog.csdn.net/swingwang/article/details/72887367
是一种传输协议
与TCP/IP一样,也是分层协议,但是传输层,网络层,链路层都通过网卡进行操作
传输层上有各种上层协议
- SDP 允许传输TCP/IP
- SRP 传输SCSI命令
- iSER 存储协议
计算机设备
https://zhuanlan.zhihu.com/p/54029324
PCIE

新一代IO总线接口标准(旧称3GIO),也包含相应的协议
PCIE可以接显卡,网卡,SCSI卡等。。。
SATA
Serial ATA 用于存储设备的总线接口
SCSI
总线接口和协议,用于与外部存储设备进行通信
SCSI协议可以使用多种传输协议进行传输
SAS
Serial SCSI ,串行SCSI总线接口标准,兼容SATA接口设备
SDRAM
同步动态随机存取内存
SRAM
静态随机访问存储器,常作为CPU的高速缓存,现一般继承于CPU中
BIOS
存在于主板闪存中的程序
MBR
硬盘第一个扇区,称为主引导扇区,存储了分区表
UEFI
用于替代BIOS的软件,使用GPT取代MBR(但MBR区还在),存储了分区表的位置信息(而MBR模式下分区信息直接存在在MBR区)
查看存储
# 查看文件系统以及挂载点file -Ls /dev/sda1df -T# 查看block level设备,以及各自的扇区,磁道等数量lsblk
Beegfs

Management server
- 需要两个分区,一个mgmtd和meta,使用ext4系统,使用beegfs-setup-mgmtd和beegfs-setup-meta进行初始化这两目录
-
Storage node
存储为xfs系统,挂在后使用beegfs-setup-storage -p /beegfs_ost01 -s 1 -i 101 -m ibmds01 -f分别指示storage目录和manager节点,之后会自动寻找management节点
-
Client node
build客户端内核(如果使用以太网会自动build),开启beegfs-helperd和beegfs-client服务
所有节点都是都会自动寻找manage节点,然后client和storage server再与Metadata server进行通信
tune
https://www.beegfs.io/wiki/TuningAdvancedConfiguration
rstudio server docker
docker run -d -p 8787:8787 -p 3838:3838 -e ROOT=TRUE -v /store:/store -e ADD=shiny rocker/rstudio# rocker/rstudio:4.0.0docker exec ID -it /bin/bashapt update && apt install -y rpcbind nisecho domain NIS_DOMAIN server NIS_SERVER_IP >> /etc/yp.confvim /etct/nsswitch.conf # add nis to back of each line## start.shdocker container start 426e41dc7d4edocker exec 426e41dc7d4e rpcbinddocker exec 426e41dc7d4e ypbindcrontab -e@reboot /root/start_rstudio_server_docker.sh

若有收获,就点个赞吧
0 人点赞
