安装&编译
https://dev.mysql.com/doc/refman/8.0/en/linux-installation-yum-repo.html#yum-repo-installing-mysql
修改password policy时,名称与5.7不同了,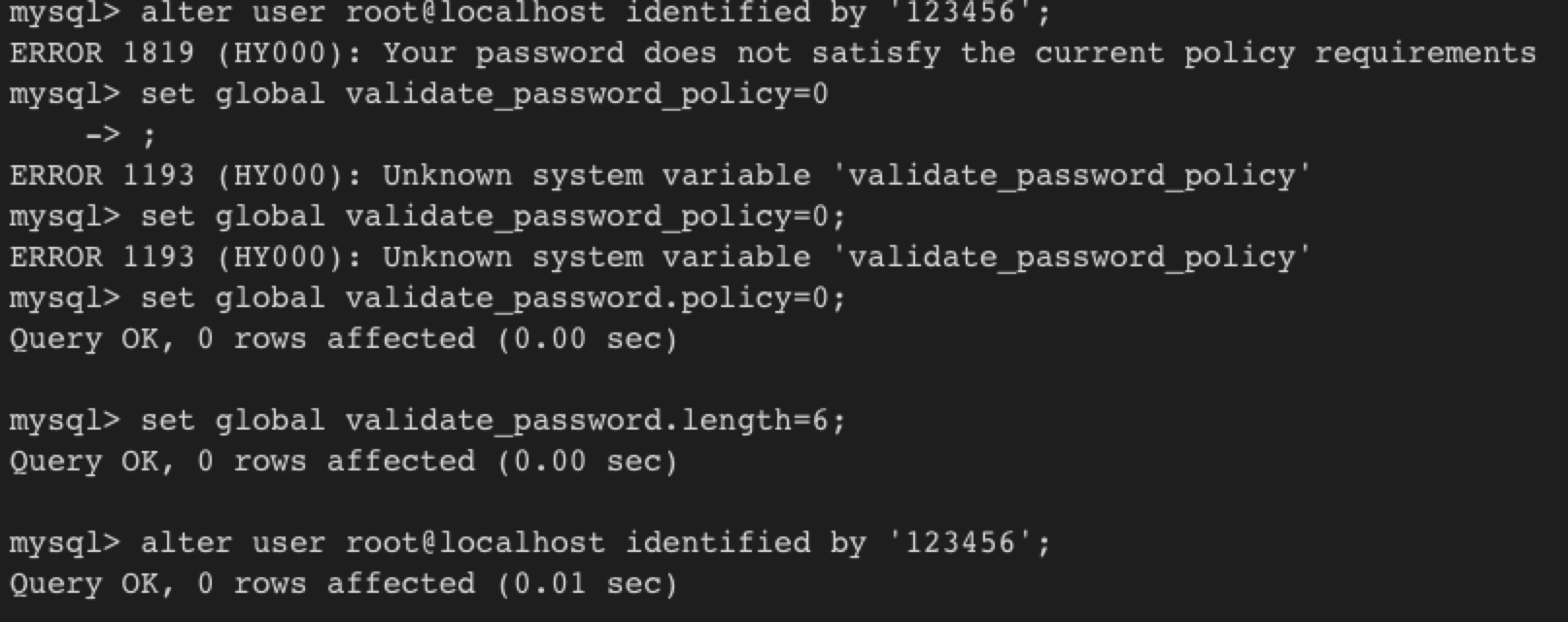
8.0源码编译
cmake .. -G Ninja -DWITH_DEBUG=1 -DCMAKE_INSTALL_PREFIX=/opt/mysql
ninja-build
换成Ninja要快很多
gdb 调试
mysql 启动时,用 mysqld --user=mysql
当在update 写log 时加断点: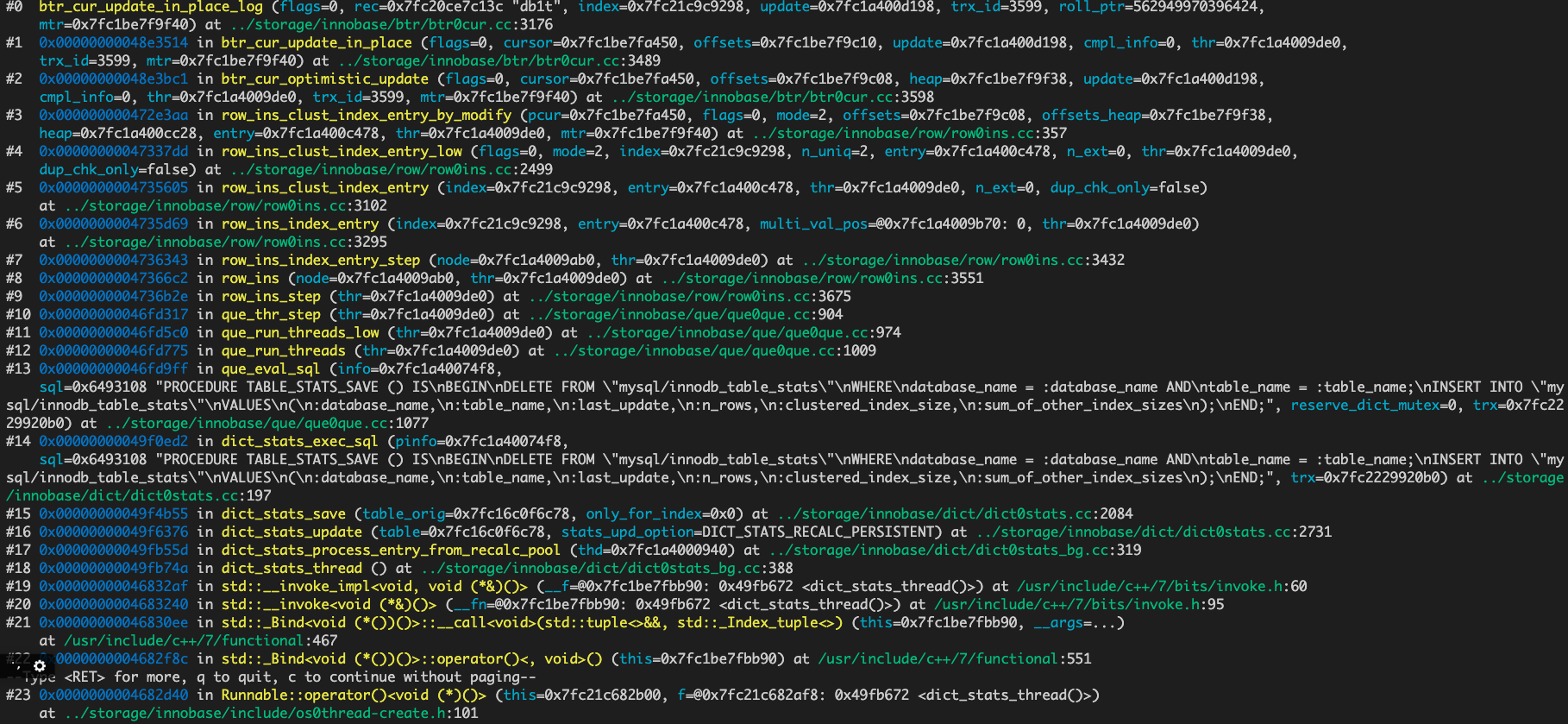
写log 
Usage
mysql> create table too_large_table(c varchar(65535)) CHARSET=ascii ROW_FORMAT=Compact;ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
如果改为65532就可以了。Innodb对一行数据(除开blob)有大小限制
而innodb_page_size默认是16KB,
show global status like 'innodb_page_size';------------------+-------+| Variable_name | Value |+------------------+-------+| Innodb_page_size | 16384 |+------------------+-------+1 row in set (0.00 sec)
一行数据就可能span across multiple pages。
小的page size适用于有很多small writes的workload,这样一个页有很多条记录造成竞争加大。
Page/File Structure
b站培训视频:https://www.bilibili.com/video/BV1f4411y7R6?t=194 鲁班学院 周瑜(他的md笔记看着不错,使用processon画图也很熟练)
详细illustrate了page内的record如何存储、page directory用以快速找到某个row; 以及用父页将查询导向某个页,逐步引到了B+-tree上。讲得不错。。
对于secondary index,也是一颗树,但其leaf node存储的不再是数据,而是存主键索引值(注意结点的 key 可以是由多个column组成,即为联合索引); 当用secondary index进行查询时,先查询二级索引树找到主键,再回表到主键索引树上找数据
但如果通过辅助索引找到的主键太多了,可能还不如全表扫,此时查询计划给出的方案可以是不使用索引而全表扫
例如:在t1表a上有主键索引,b,c,d有联合索引,
select from t1 where b=1 这个是可以用到(b,c,d)索引的,本来就能比较
select from t1 where c=1 这不能用到(b,c,d)索引,没法比较,很可能多个子树上都存在这样的c
select * from t1 where b like ‘%101’; 这也不能,%不知道是啥,没法walk tree; 去掉%可以
对于like ‘%.com’ 这样的查询,由于无法利用到索引而inefficient; 这时可以考虑将url网址取反后才存入db,这样就可 select * from where url like ‘com.’; 这样查了。属于一种技巧。
事务
flat txn
In a flat transaction, each transaction is decoupled from and independent of other transactions in the system. Another transaction cannot start in the same thread until the current transaction ends
flat txn的缺陷在于不能回滚事务的一部分,有时代价比较高,
flat txn with savepoints
chained txn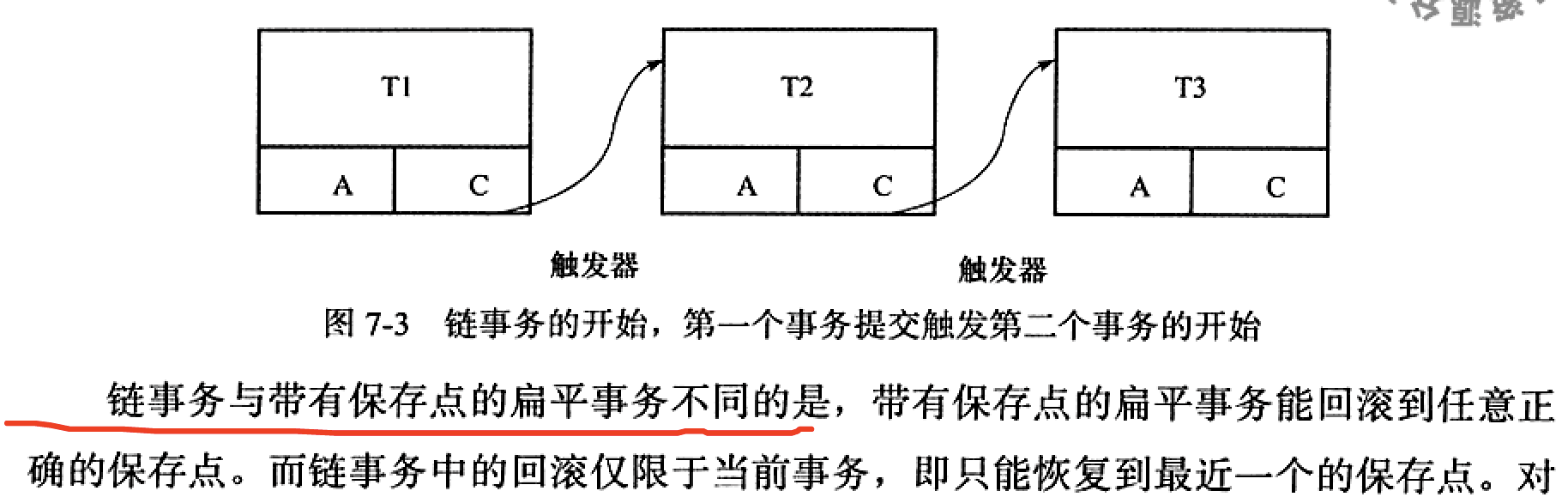
下图是实验:
当completion_type=1,则commit work和commit就不再一样了,前者表示立即开始一个chained txn。当回滚它时,2 就不在表中了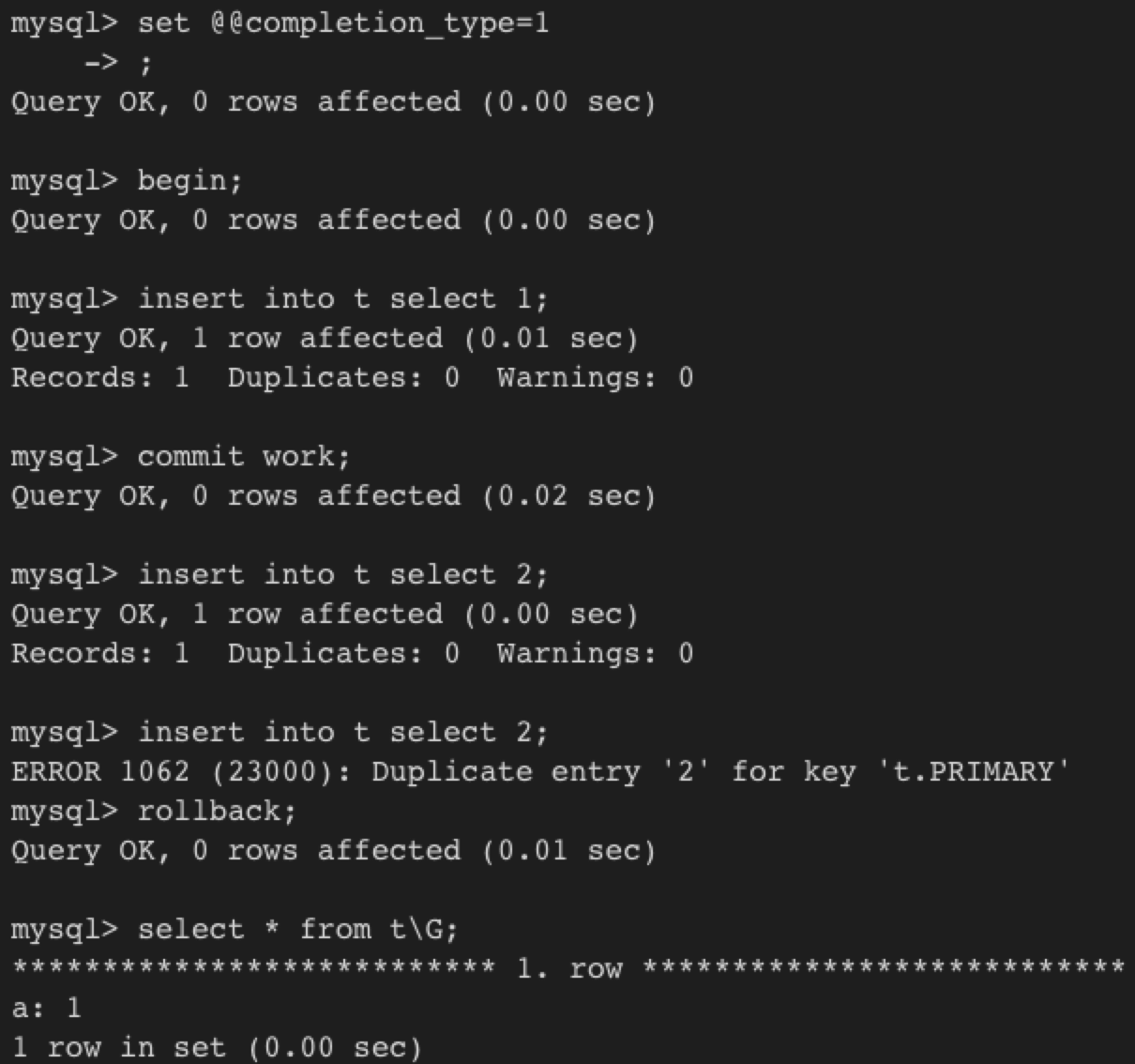
nested txn
- 任何子事务在父事务提交后才真正地提交(变得可见)
- 任何事务回滚都会导致其子事务回滚,故子事务不具有durability特性
可以通过txn with savepoints来模拟nested txn
InnoDB支持flat txn, txn with savepoints, chained txn,原生并不支持nested txn
事务实现
redo log
官方doxygen 文档
https://dev.mysql.com/doc/dev/mysql-server/latest/PAGE_INNODB_REDO_LOG.html
Single mtr can cover changes to multiple pages. In case of crash, either the whole set of changes from a given mtr is recovered or none of the changes.
Whenever we refer to data bytes, we mean actual bytes of log records - not bytes of headers and footers of log blocks
讲得很细,说到了各种lsn 间的关系
- 先在log buffer, log files中预留 lsn ranges,如果log writer 做得不够,则user 线程等待其将log buffer 写到system buffers,从而可以回收一些空间;
- 拷贝数据到 reserved space。 log buffer 是ring buffer,对给定lsn 的byte 是 lsn % size(buffer),这样并发度更高,不需要shifting (shifting 需要独占锁); user 线程无锁拷贝 mtr 内部buffer的数据到 log buffer
- 可能会造成在log buffer 里有空洞,这没关系,由
log writer 线程来保证写log时是连续的
- 可能会造成在log buffer 里有空洞,这没关系,由
- 往recent written buffer 里添加 links
- 它负责跟踪有哪些并发写在操作 log buffer,它们有没有完成;它允许
log writer 线程更新log.buf_ready_for_write_lsn - 如果recent writter buffer 太小会导致user 线程等待有多余的空间
- log writer 从links 获取到信息,更新
log.buf_ready_for_write_lsn - 必须要保证:先写log buffer,后写 recent written buffer
- 如果log writer 线程发现missing links,它会等待
- 它负责跟踪有哪些并发写在操作 log buffer,它们有没有完成;它允许
- 当所有的dirty pages 都加到 flush list中后,user 线程在
recent_closed里设置 links (有个 log closer thread ,跟踪 recent closed buffer;当slot 可用后又可标注为重用)
有四个线程
log writer
log flusher
fsync后,它会更新 log.flushed_to_disk_lsn
log flush_notifier
通过user 线程 log.flushed_to_disk_lsn >= lsn
log writer_notifier
通知user 线程 write_lsn >= lsn
log checkpointer
更新 log.available_for_checkpoint_lsn
阿里云文章
https://www.bookstack.cn/read/aliyun-rds-core/70c5b3509a44f40e.md
redo log 保证A 和 D,undo log保证C
redo log 用来保证事务的持久性, undo log用来帮助事务回滚及MVCC功能
日志刷盘时要fsync,fsync的效率取决于磁盘性能;
允许配置不在提交时fsync,这样可显著提高性能,但丢失最后一段时间的事务;
参数 innodb_flush_log_at_trx_commit 用来控制此策略:
1 : 默认值,提交时必须调用一次fsync;
0: 提交时不会将log buffer中的日志写入到os buffer,更不会fsync,默认每隔一秒才做一次
2: 每次提交都写入到page cache,但不fsync,每隔一秒fsync
innodb_flush_log_at_timeout 控制频率,它与commit动作无关!
不同值的性能差异测试:
与binlog的区别
- binlog对应的是mysql语句,是逻辑日志; 而redo log是物理格式日志,记录每个页的修改
- redo log是循环写,空间固定,没有归档功能; binlog是追加写,空间不受限制,有归档功能
redo log是幂等的,binlog不是幂等
如某记录id初始为2,通过update设置成3,然后又设置成2,在redo log中的将是无变化的页,重启时无需恢复; 但binlog会记录下两次update,恢复更慢
写入时间不一样,binlog在事务提交时写入(这是叫deferred-modification吗?),所以其记录方式与提交顺序有关,一次提交对应一次记录; redo log在事务活跃时就在写,且是并发写,实际顺序不一定是各事务开始的顺序
- 崩溃恢复过程不写binlog(可能需要读binlog)
log block
redo log 都是以512B 进行存储的,与扇区大小一样,因此日志的写入保证原子性(??),不需要doublewrite(log刷盘每次只写 512B ???)
分为 log block header + log body + log block tailer组成
当T1 日志占762 B, T2占100B时,log block的日志占用如下图:(前者会占用两个log block)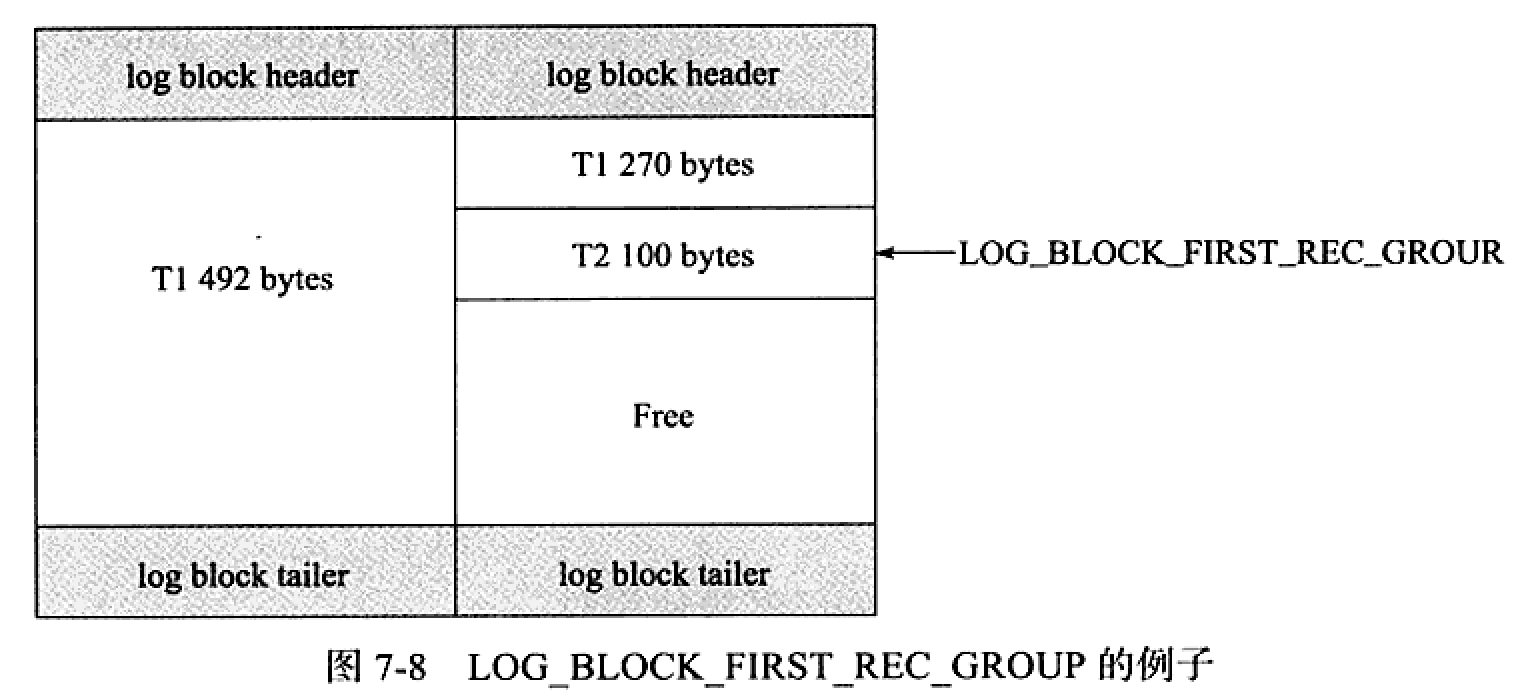
log group
==========
log group是一个逻辑上的概念,由多个redo log file 组成,每个file大小相同; file里保存的是log buffer中的log block,每个块的大小也是512B,根据如下规则 flush log to disk:
- when txn commits
- when half space of log buffer is used
- when checkpoint
log group 与log file, log block的结构关系如下: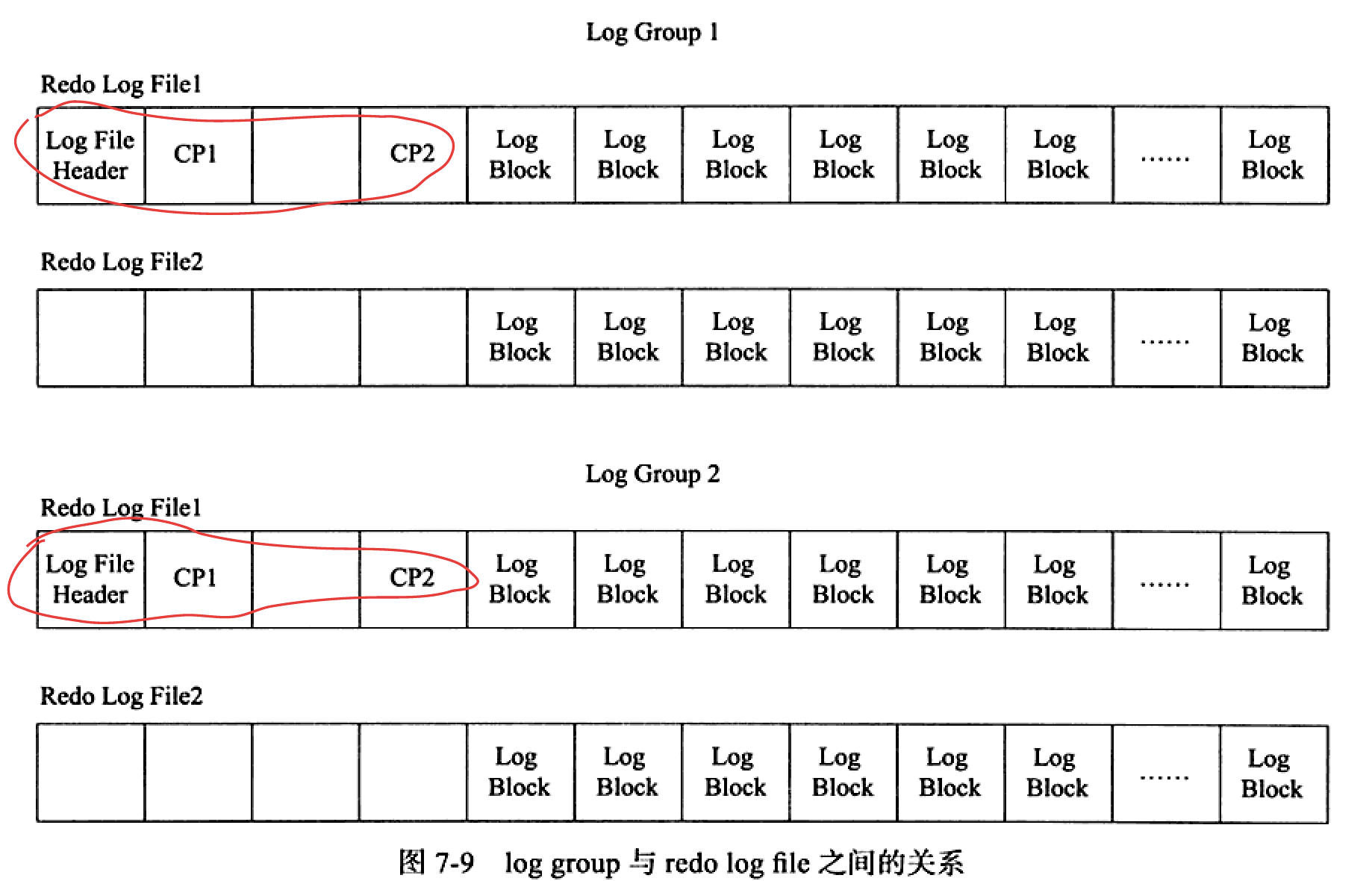
每个log group的文件前有2KB的信息,对于group里的第一个file,2KB的数据特别点。由此可看出,对log file 的刷盘并不是完全顺序写入,也得更新前 2KB的信息。
查看log配置变量:
mysql> show variables like '%innodb_log%';+------------------------------------+----------+| Variable_name | Value |+------------------------------------+----------+| innodb_log_buffer_size | 16777216 || innodb_log_checksums | ON || innodb_log_compressed_pages | ON || innodb_log_file_size | 50331648 || innodb_log_files_in_group | 2 || innodb_log_group_home_dir | ./ || innodb_log_spin_cpu_abs_lwm | 80 || innodb_log_spin_cpu_pct_hwm | 50 || innodb_log_wait_for_flush_spin_hwm | 400 || innodb_log_write_ahead_size | 8192 |+------------------------------------+----------+
在data dir下可发现有2个logfile*, 对应着innnodblog_files_in_group, ibdata1是没有开启file-per-table的共享表空间;
当将log buffer中的redo log block写入到log file时,是以追加写入的方式循环轮循写入,即先在ib_logfile0的尾部追加写,满了后向ib_logfile1写 (这样写的好处?为何rocksdb的WAL不这样呢?_)
格式
=============
到InnoDB1.2,一共有51种日志类型。
LSN
含义:
redo log写入的总量
若当前redo log LSN=1000,T1写了100B 的log,则LSN=1100
LSN不仅记录在redo log中,还存在于每个页中,在页的头部有一个 FIL_PAGE_LSN,表示该页最后刷新时的LSN大小,若比redo log LSN要小,则db需要进行recovercheckpoint的位置
- 页的版本
查看Innodb的LSN状态
show engine innodb status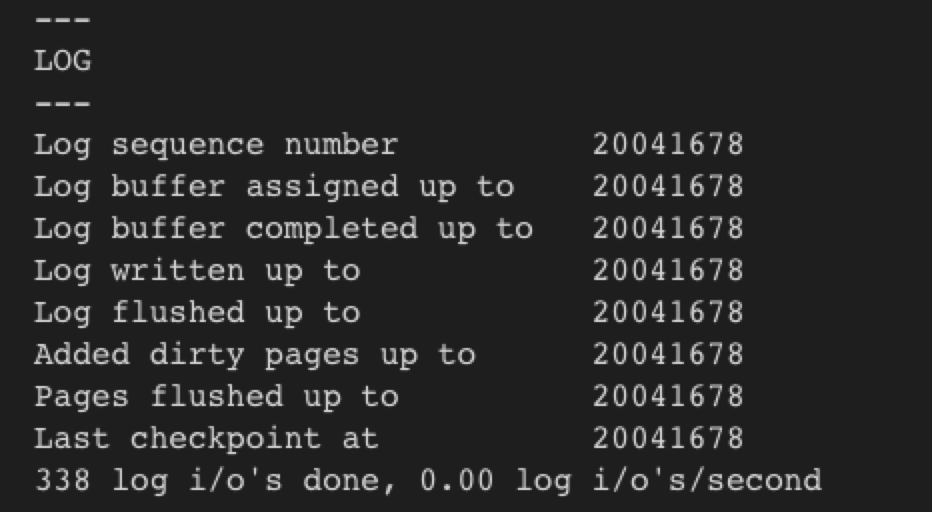
- log sequence number表示当前的 redo log(in buffer)中的 LSN(不妨记为redolog_in_buffer_lsn)(内存里不是有多个log buffer吗?这个是指全局值吗?_)
- log flushed up to表示刷新到redo log file 中的LSN (redo_log_on_disk_lsn)
- page flushed up to : 已经刷盘磁盘数据页上的LSN (data_page_on_disk_lsn)
- last checkpoint at:表示上一次checkpoint所在位置的LSN (checkpointlsn) (记录在哪里,redo log吗?_)
LSN变化时序图
来自 https://www.cnblogs.com/f-ck-need-u/p/9010872.html
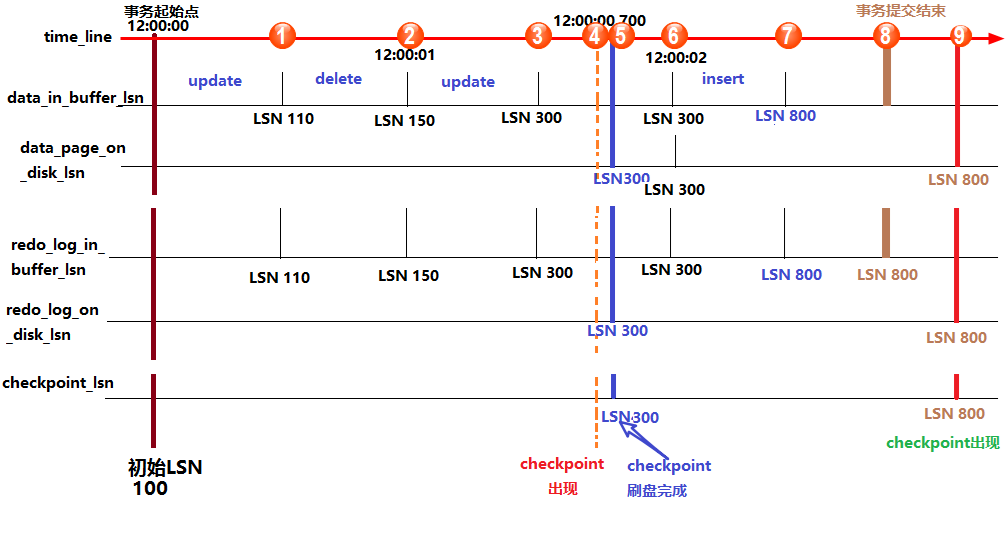
LSN与恢复
速度比 binlog 快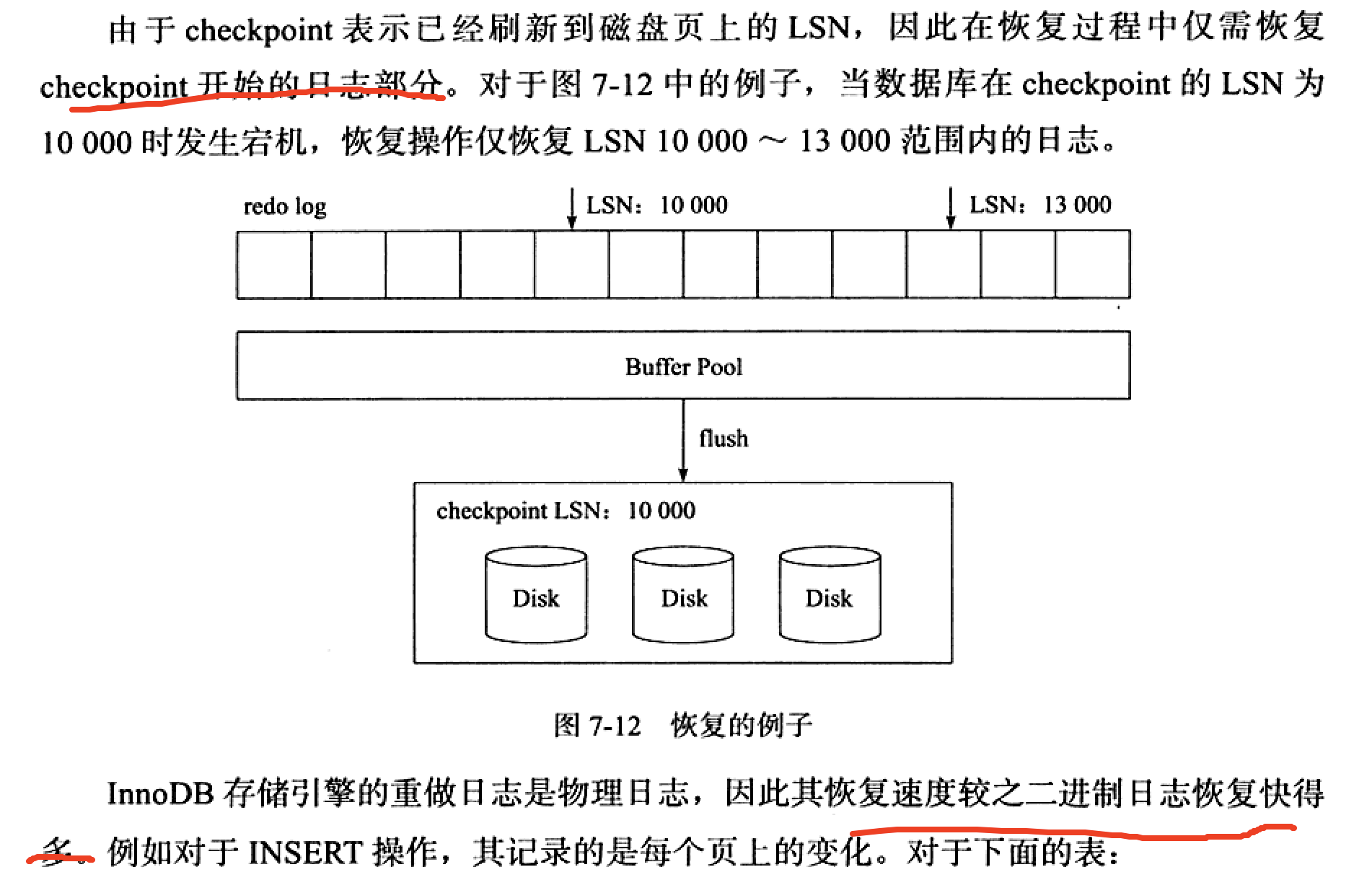
insert操作在二进制日志中就不是幂等的,重复执行可能会插入多条重复的记录,而insert 操作的redo log是幂等的;
问:binlog 与oplog区别?幂等性比较??
undo
存放在db内部的一个特殊段中,undo segment
共享表空间:ibdata*文件中,用于放多个表数据
这样可查看undo page 的数量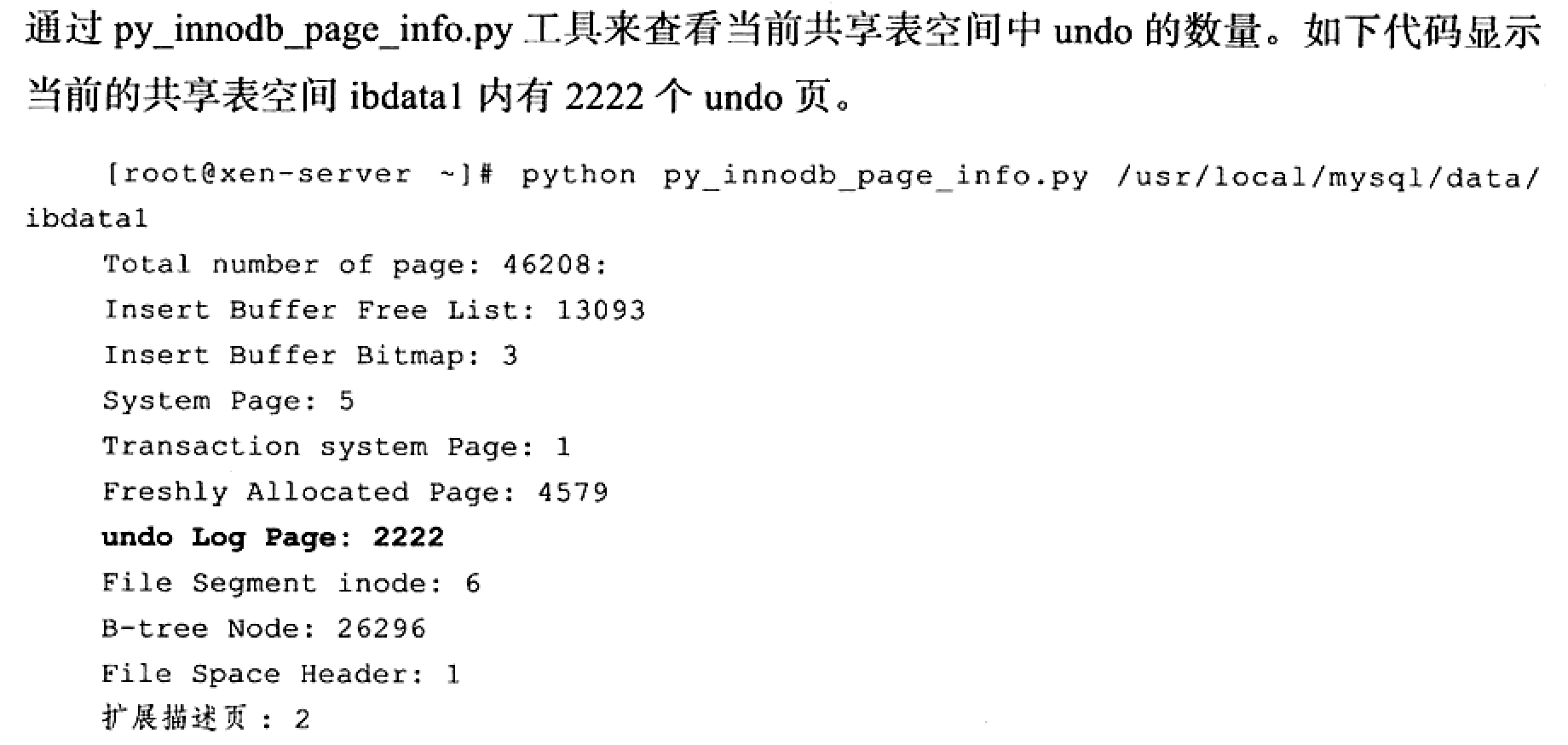
undo 是逻辑日志,只是将数据库逻辑地恢复到原来的样子。可以认为当delete一条记录时,undo log中会记录一条对应的insert,当update一条记录时,它记录一条对应相反的update;
用户执行了一个insert 10w条记录的事务,这个事务会导致分配一个新的段,即表空间增大,当rollback时,会将插入的事务回滚,但是表空间大小并不会因此而收缩。
undo另一个作用是实现MVCC;
undo log也会产生redo log,这在DSC中已经强调了,属于redo-only log.
undo存储管理
rollback segment记录了1024个undo log segment,每个undo log segment进行undo页的申请;
可配参数:
innodb_rollback_segments: rollback segments的个数(以前叫inndo_undo_logs)
innodb_undo_tablespaces: 最小为2,让rollback segment平均地分布在多个文件中
- 事务在undo log segment分配页并写入到undo log的这个过程同样需要写redo log;
- 事务提交后并不能马上删除undo log及undo log所在的页,这是因为可能还有其他事务需要通过undo 来得到记录前的版本; 故事务提交时将undo log放入链表中,供purge线程来判断
通过查看 show engine innodb status看undo log的数量,即History list length,在ref 8.0中解释:
a list of txns with delete-marked records scheduled to be processed by purge Operation. Recorded in the undo log. If the history list grows longer than the value of the
innodb_max_purge_lag, each DML op is delayed slightly to allow the purge to finish flushing the deleted records. 以上这句,听不懂为啥purge要flush ?? deleted records指什么??为啥要强调有delete-marked
undo log格式分为两类:
insert undo log: 在txn rollback时需要,在txn commits时可丢弃
update undo log: 可用于consistent reads中,但丢弃它的前提条件是:没有事务在consistent reads中被分配了一个snapshot,而它需要update undo log中的信息来建立行的早期版本 (来自ref 8.0 15.3)
8.0已没有这个表 INNODB_TRX_ROLLBACK_SEGMENT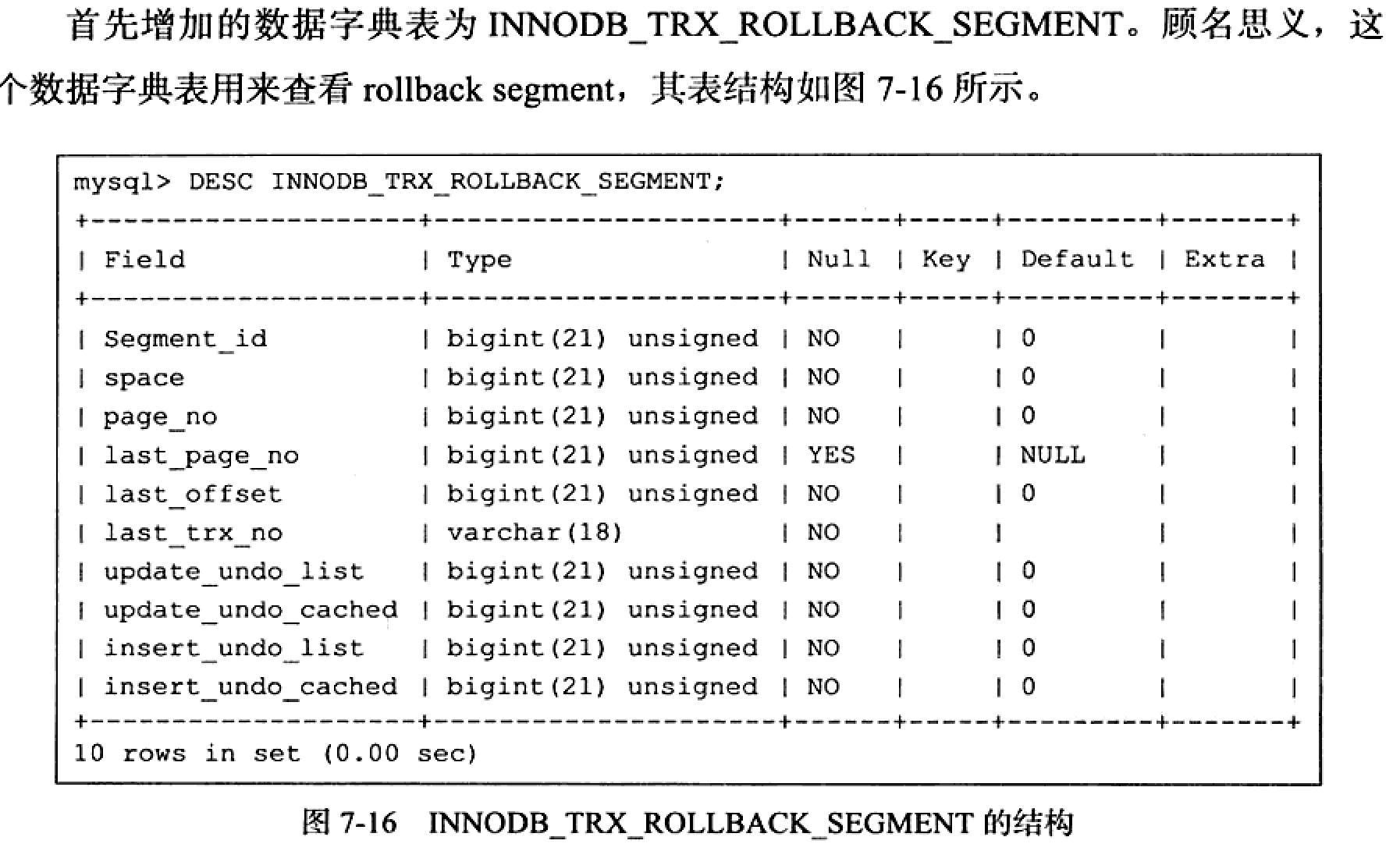
7.3 事务控制语句
mysql 默认设置下是自动提交的(auto commit),即执行sql语句后就会马上执行commit操作;
start transaction or begin
commit or commit work : 二者几乎等价,取决于completion_type的值
rollback
savepoint
release savepoint
rollback to [savepoint]
set transaction: 设置level
若使用rollback to savepoint,之后也得运行commit or rollback
隐式提交语句
查看commit, rollback统计
show global status like ‘com_commit’;
show global status like ‘com_rollback’;
隔离级别
Innodb默认级别是repeatable read,但与sql 标准不同的是,在RR下,使用Next-key Lock算法,可以避免幻读,所以其RR已达到sql标准所说的serializable
作者引用Jim Gray在transaction processing一书中说:RR与RC开销几乎一样。即使默认改成RC,用户也不会得到性能的很大提升。
查看session or global tx isolation level(以前叫tx_isolation)
select @@global.transaction_isolation;
7.7 分布式事务
Innodb提供了对XA事务的支持,并通过XA事务来支持分布式事务的实现;
在使用分布式事务时,Innodb的级别必须 设置为serializable (??
ref 5.7 Manual
14.9 表压缩
在create table时用 ROW_FORMAT=COMPRESSED 来控制在 file-per-table or system tablespaces下的表和索引的压缩
压缩表可以使用比 innodb_page_size 更小的on-disk page size (由 KEY_BLOCK_SIZE 决定);
在buffer pool中,同时存在compressed data & uncompressed data,所以可能要正确调整buffer pool 大小
SET GLOBAL innodb_file_per_table=1;SET GLOBAL innodb_file_format=Barracuda;CREATE TABLE t1(c1 INT PRIMARY KEY)ROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZE=8; (默认是innodb_page_size的一半;这里8 就暗含 FILE_BLOCK_SIZE=8K)
KEY_BLOCK_SIZE被视为一个hint,innodb若有必要,可以选择一个不同的size- 对于file-per-file 表空间,将KEY_BLOCK_SIZE高为 innodb_page_size 不会带来很大的压缩(不过仍可能有好处,比如存在很多text, varchar字段时); 对于general 表空间,不允许置为 innodb_page_size
- 压缩是针对 于表及其索引的,不是针对 于row的,尽管语句上称为 ROW_FORMAT
调优压缩
- 什么时候使用压缩?
一般说来有大量字符串数据,且读远大小写时,用压缩。建议始终用特定workload进行测试
- 为决定是否为一个表开启压缩,就要做压测!比如可以基于文件的压缩工具压缩 ibdata文件,得到一个粗略的效果,它压缩的程度要比mysql内部压缩要大一点,因为内部是以page size 来压的
- 不要同时在应用层和db 层做压缩,很难再节省空间,反而是浪费CPU cycles
- 要不要压缩也依赖于workload。 根本上说,如果负载是I/O bound,有多余的CPU time,则压缩是合适的
- 分配更多内存的更有利于装载compressed data & uncompressed data
- 如何选择compressed page size ?
取决于数据类型和分布。但此大小要于最大的record 大小!一般合适选择是 8K or 4K
内部的压缩实现
- 一些OS在文件系统层实现了压缩,将固定大小的block压缩成可变大小的block,这样很容易带来碎片化; Mysql 使用成熟的zlib,可以通过调
innodb_compression_level来控制压缩程度与CPU消耗之间的平衡 - 所有的用户数据都是以组成b-tree index的page来存储的,二级索引也是b-tree
- 对b-tree page的压缩:为了减少b-tree node split和不断地解压和再压的开销,内部会为每个b-tree page维护modification log,当Log用得差不多时,再将页解压,apply modification,再压缩;
- 为了降低解压的开销,在buffer pool同时存在压缩页和非压缩页; 它俩都可以被evict
- Mysql 内有自适应的LRU算法来平衡压缩页和非压缩页的内存占用。目标是:当CPU busy时,避免解压工作;当有闲余的CPU时,就去做解压工作以避免IO操作;
当cpu bound时,选择evict both 压缩页和非压缩页,避免解压;
当IO bound时,仅evict 非压缩页
压缩OLTP workload
有以下参数可供调整:
- innodb_compression_level : 越大,压缩得越多
- 预备提高
innodb_buffer_pool_size
double write
https://www.cnblogs.com/geaozhang/p/7241744.html
ref 8.0 15 InnoDB 引擎
tablespace
data file that hold data for one or more innodb tables & its indexes
system tablespace
一个或多个data files (ibdata files),包含与innodb相关的对象的元数据,和change buffer,doublewrite buffer的存储areas 如果表创建在system tablespace而不是file-per-table or general tablespaces,则也包含这些表的table&index data 在5.6.7前,默认是把所有的innodb 表和索引都放在system tablespace,经常造成very large file. 由于system tablespace never shrinks, 所以有存储问题。 8.0把默认改为file-per-table,这样每个表和索引都存储在seperate .ibd file中 在5.7.6中引入了general tablespace,也是以.ibd files来表示。它们可以创建在data direcotory 外面,可以holding 多个tables
slow shutdown
也叫clean shutdown,关闭前会flushing,通过设置 set global innodb_fast_shutdown=0 控制 虽然耗时久一些,但有利于下次的重启
Clustered Index:
每一个InnoDB表都有一个特殊的索引,叫做clustered index,通常来讲,clustered index和primary key是同一个意思,InnoDB选择clustered index原则如下:
- 如果表上定义了primary key,则使用primary key作为clustered index
- 如果没有定义primary key,选择第一个非空的UNIQUE索引作为clustered index。所以,如果表只有一个非空的UNIQUE索引,那么InnoDB就把它当作主键了。
- 如果即没有primary key,也没有合适的UNIQUE索引,InnoDB内部产生一个隐藏列,这个列包含了每一行的row ID, row ID随着新行的插入而单调增加。然后在这个隐藏列上建立索引作为clustered index。
clustered index B+树叶子结点上存储着row record数据。
Secondary Index:
除了Clustered Index之外的索引都是Secondary Index,每一个Secondary Index的记录中除了索引列的值之外,还包含主键值。通过二级索引查询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键/聚簇索引找到相应的数据块。
info about old versions of changed rows is stored in tablespace in data structure called a rollback segment. Innodb使用这里面的信息来执行undo op, 也用来build earlier versions of a row for a consistent read
在内部,innodb给db每一行添加了三个fields, 6B DB_TRX_ID,修改该行的最后一个txn id; 7B DB_ROLL_PTR,指向rollback seg里的undo log record; 6B DB_ROW_ID,包含一个自增的row id
当sql delete一行时,并不是立即删掉它,而是等到其update undo log is discarded for the deletion. 这个removal op is called a purge. 当以相同速率执行insert,delete时,purge thread可能会lag behind,表示有越来越多的update undo log没有被清理。 这时也许要调小 innodb_max_purge_lag
innodb架构
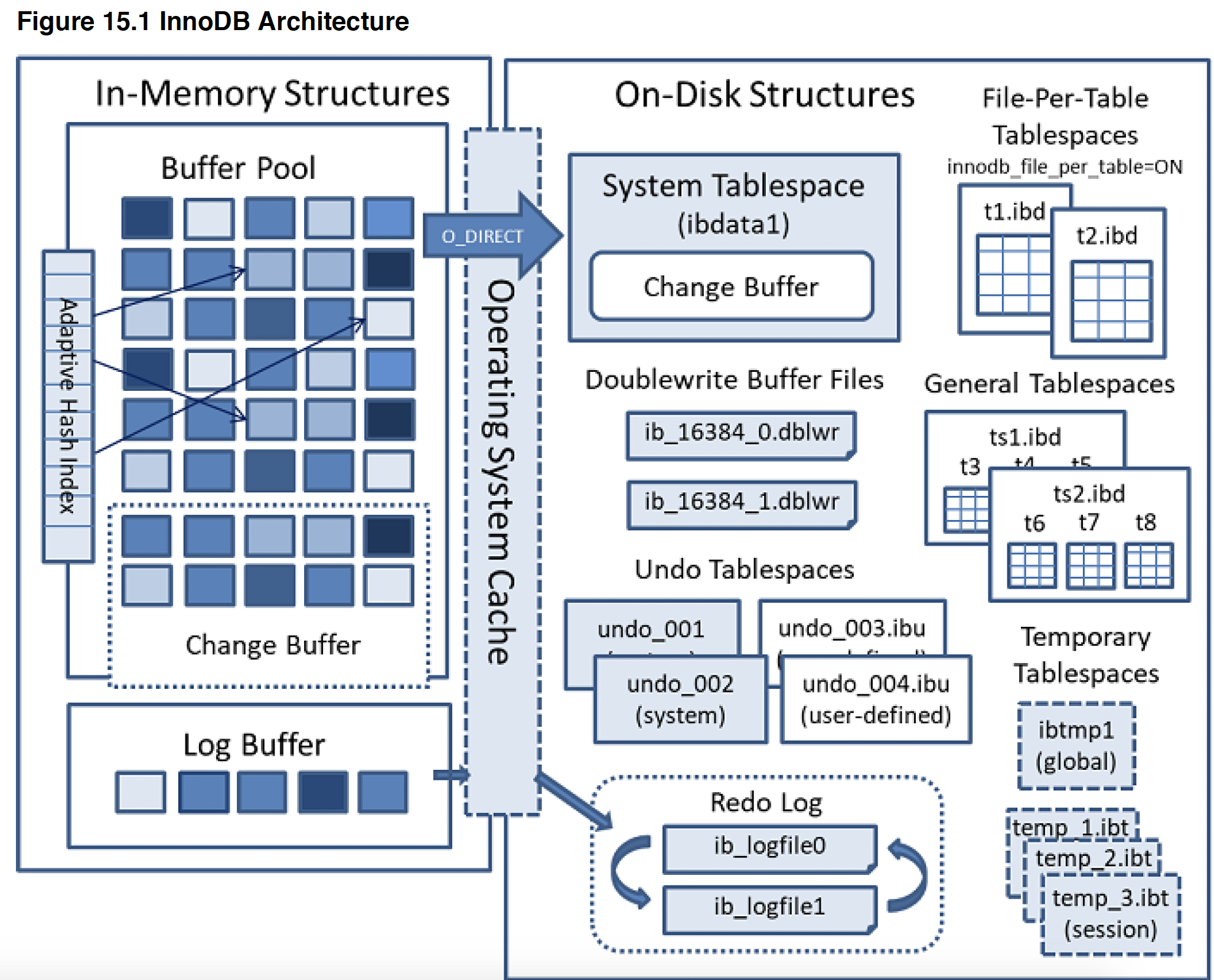
buffer pool
innodb用来cache table & index data, 一般80%的物理内存要分配给它;
为了高效读,buffer pool被分成pages,而buffer pool的实现是linked list of pages,使用LRU算法剔除
change buffer
secondary index 的相关pages若不在buffer pool中,则对它的changes会被放进change buffer,由INSERT,DELETE,UPDATE等造成,之后当有读op时,二级索引页被载入BP, 它会与BP里的pages merge.
这样做的好处是:由于更新二级索引往往是随机IO,会导致substantial IO,于是考虑将changes先cache住,待读操作把二级索引载入后再merge(也会在系统idle, slow shutdown时进行merge),之后再flush,这样对于索引的更新更为高效(P2764),适用于IO-bound workload such as bulk inserts
属于系统表空间,在db重启时remain buffered
涉及到change buffer的一系列features统称为change buffering
== 相关配置表示可能装什么样的change,和装多少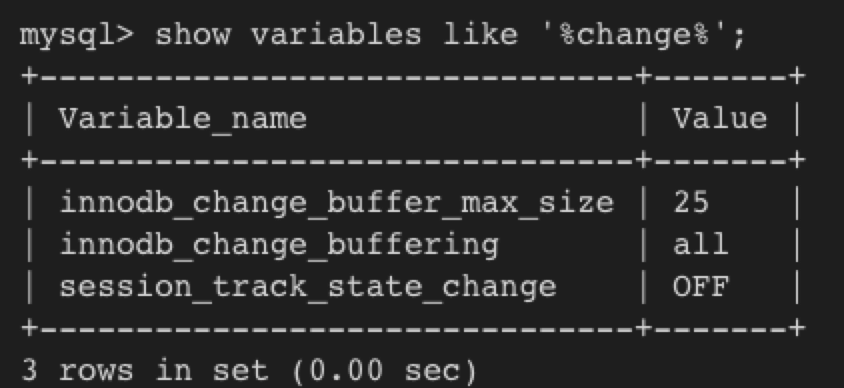
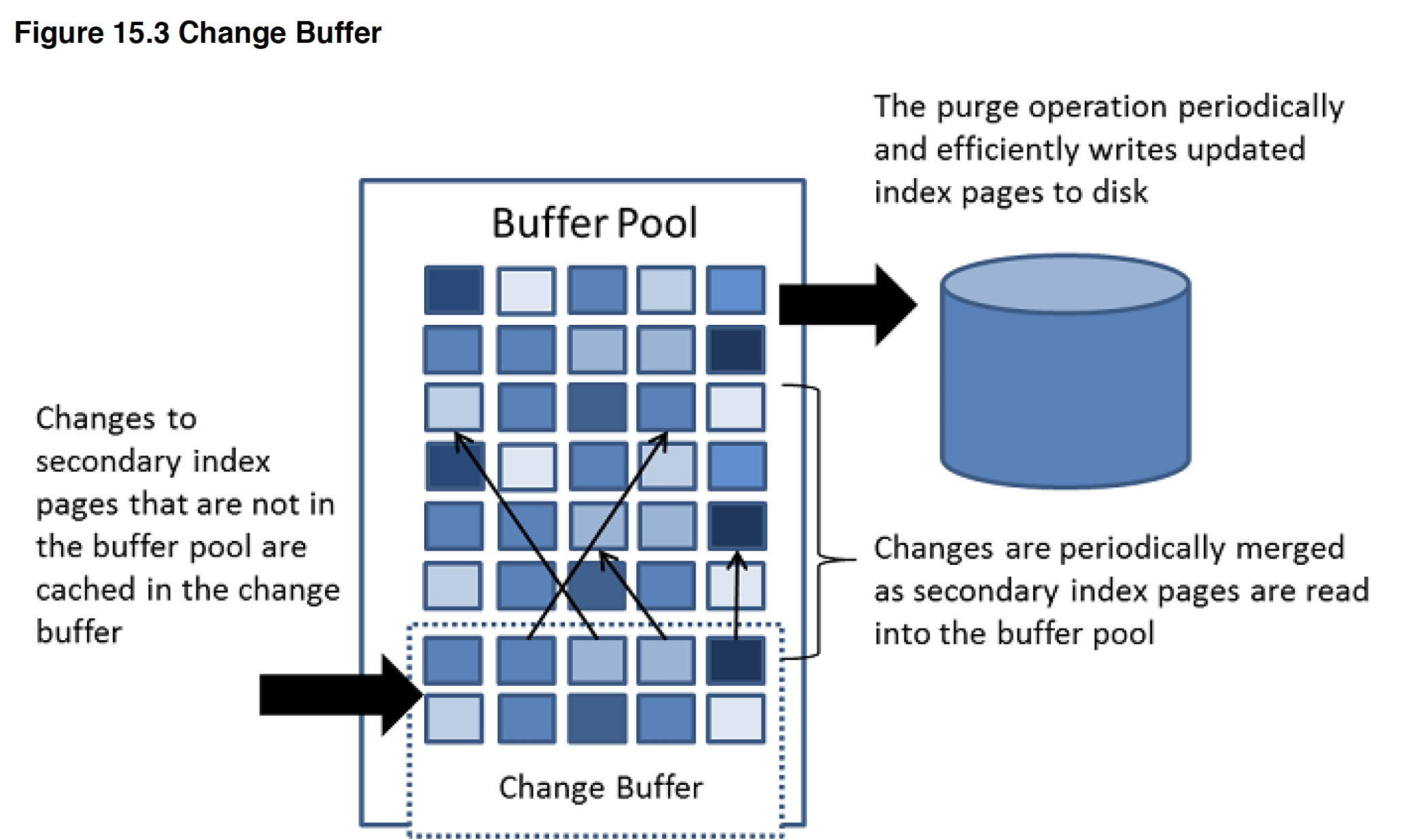
change buffer merging可以耗时很久,特别是在有很多affected rows and numerous secondary indexes to update.,此时disk io增加,会影响查询
这里(P2764)描述有问题:
In memory , the change buffer occupied part the buffer pool. (前面不是说当不在buffer pool中吗)
On disk, the change buffer is part of system tablespace. 当server关闭时,index changes会buffer在system tablespace (这里用词奇怪,当db关闭时,不是叫buffer,而是叫persisted in system tablespace??)
可以针对insert,update, delete给change buffering设置是否要enable. (innodb_change_buffering , 可用set global动态调整)
log buffer
size由innodb_log_buffer_size来定,默认16MB,如果有做大量CURD操作的事务,可以考虑增加log buffer,这样在事务提交前不必写disk
InnoDB on-disk structures
table
当创建表默认在file-per-table 表空间时,就会在data dir下创建一个ibd文件; 若disable了file-per-table,则会创建在系统表空间,仍使用某个存在的ibdata file; 如果创建在general 表空间,也是共享ibdata file,可以在data dir内或外
InnoDB locking and txn model
关于这部分内容,推荐看一个b站培训视频:https://www.bilibili.com/video/BV1x54y1979n?
实现的是standard row-level locking
intension locks are table-level locks that indicate which type of lock(shared or exclusive) a txn requires later for a row in a table.
意向锁的目的在于告诉外界有人即将在对表里的某行加某种类型的锁
意向锁协议:
- 在事务对a row in a table加S前,必须先获得对表的IS
- 在事务对a row in a table加X前,必须先获得对表的IX
compatability matrix
====================
我们最好把下面的record lock,gap lock, next-key lock看成锁的算法,而不是锁的类型(b站一个咕咪学院讲师说的,有道理)
Record Locks
查询条件中对unique indexed column执行等值查询,精准匹配时,使用record lock
对index record加锁,比如select c1 from t where c1=10 for update,这个就可阻止 其它 事务改变t.c1=10的行
它始终对index records加锁,哪怕表没有indexes,就会对隐藏的clustered index加锁
Gap Locks
A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record
比如select c1 from t where c1 between 10 and 20 for update; 这可阻止其它事务插入值15 (这不对吧,使用了for update自然其它事务插不了啊。。),但是其它事务还是可以select 这个range的
这种锁平衡性能和并发,只用于某些隔离级别下
当使用unique index去查找行时,这时不是加gap lock,而是record lock; 但若field is not indexed or has a nonunique index,就需加gap lock;
Gap lock惟一作用就是来阻止其它事务向gap 中插入,所以gap lock可以共存,A gap lock taken by one txn does not prevent another txn from taking a gap lock on the gap. S gap lock和 X gap lock也没有区别
gap所指向的区间是开区间!!
Next-Key Locks
a combination of a record lock on the index record and a gap lock on the gap before the index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record.

在RR下,innodb使用next-key lock去search and index scans,这可阻止phantom rows.
insert intention Lock
这是一种类型的gap lock,set by INSERT prior to row insertion. 这是在表达一种想插入的意图。比如当前index records 有4和 7, 现有T1 attemp to insert 5, T2 attemp to insert 6. 它俩在获得对inserted row的独占锁之前 ,会先对(4,7) 加gap lock,由于它俩插入的位置不一样,所以不冲突。
示例: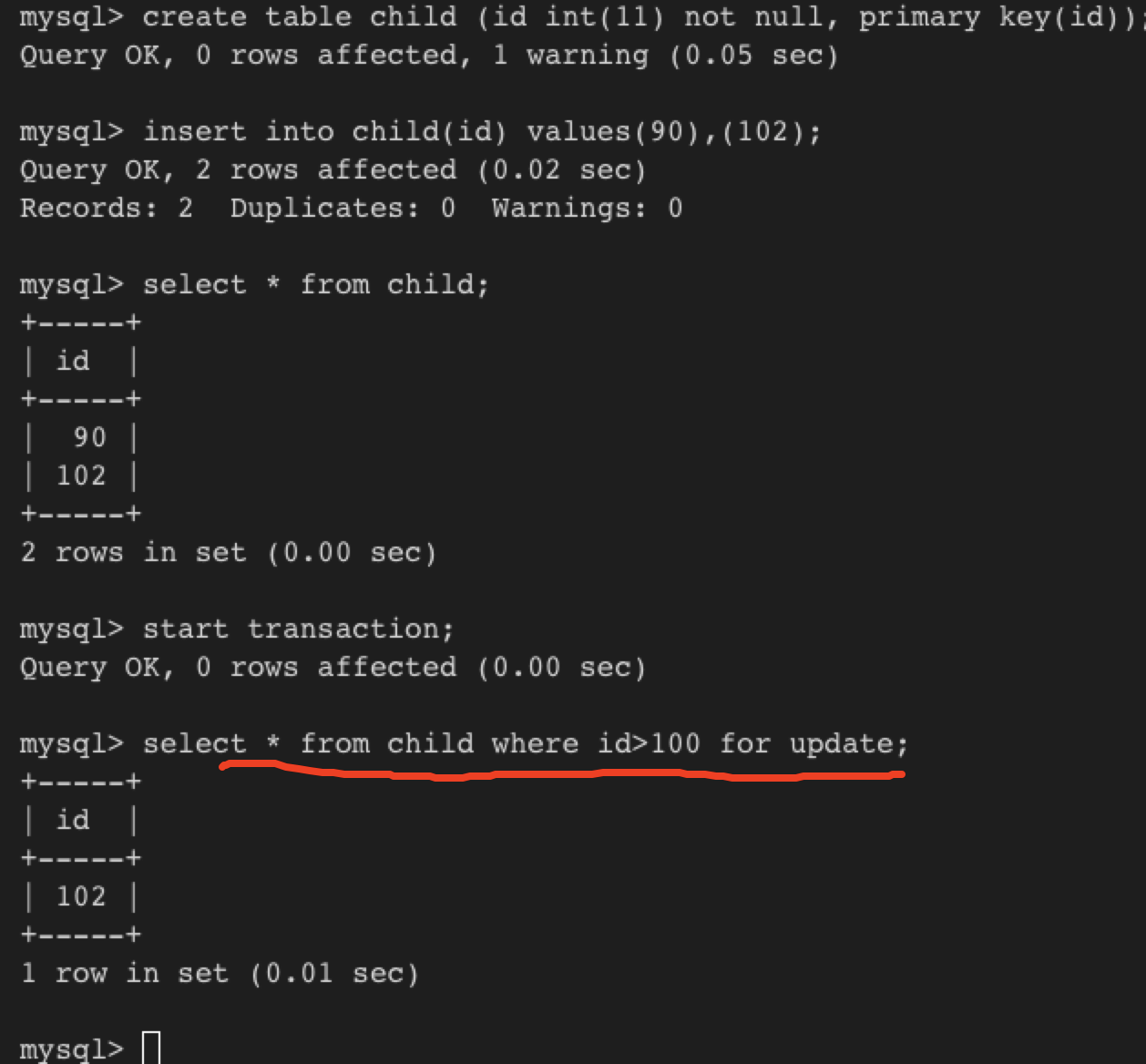
这个事务对>100的records加X lock 之前(因为有for update,所以查询才加了X lock),就加了gap lock before record 102
另外一端,有事务想插入101, 它会先取得insert intention lock for gap(90,102),然后等待X lock(下图我没操作所以等待超时)
AUTO-INC locks
是一种特殊的table-level lock taken by txn inserting into tables with AUTO_INCREMENT columns.
innodb_autoinc_lock_mode可控制auto-inc locking的算法,在predictable seq of auto-increment values and 最大并发度 间取得平衡。
InnoDB txn model
consistent read
A read op that uses snapshot info to presetn results based on a point in time, ragardless of changes performed by other txns running at the same time. 如果待查询的数据被其它事务修改了,原来的数据可以通过undo log来重建。(为什么通过undo log 而不是redo log? redo log里没有老数据?) 这就可避免reader wait for writer 当在RR下,the snapshot is based on the time when the first read op is performed. 当在RC下,snapshot is reset to the time of each consistent read op CR在RR,RC下是select语句的默认mode,因为CR既不对表加锁,也不妨碍其它事务修改。
locking read
select语句带有for update, for share。这有可能导致死锁,取决于IL. 相反就有non-locking read select for share是在8.0引入 ,以前叫select … lock in share mode
以下是不同IL下的行为:
- RR
同一个事务下的consistent reads使用first read时的snapshot,所以在同一个事务下发起的多个plain(nonlocking) select ,将会返回一致性的结果
For locking reads, update, delete,加的锁取决于有没有unique search condition
1 如果有unique index with a unique search condition,则只加record lock
2 如果是其它条件,则Innodb locks the index range scanned,using gap locks or next-key locks,这样可其它sessions不能往这个range下gap插入数据
- RC
- 同一个事务里的CR,都会有着全新的snapshot
- 对于locking reads, update, delete,只lock index records,not the gaps before them。这就意味着在操作期间允许其它事务更新adjacent records
- 由于gap locking is disabled** (gap lock 此时仅用于foreign-key constrain checking and duplicate-key checking),所以可能出现phatom rows**
- RC还有以下effects:
- 对于update, delete,Innodb holds locks only for rows that it updates or deletes. 对于那些不匹配的行,在解析了where条件之后,锁就会释放(RR下不释放)
- 对于update,如果a row 已经上锁,则先不立刻等锁,而是执行”semi-consistent” read,返回最新提交的版本,看看是否匹配where条件,如果匹配则再次读rows,接下来要么上锁要么等锁
As innodb executes each update, it first acquires an X lock for each row, and then determines whether to modify it. If Innodb does not modify the row, it releases the lock. Otherwise, InnoDB retains the lock until the end of txn.
- read uncommitted
- select语句以nonlocking方式运行,可能dirty read
- serializable
- 和RR差不多,但当autocommit disabled时,隐式地将plain select 语句调整为select … for share
autocommit, commit and rollback
在InnoDB,所以user activity occurs inside a txn.如果允许autocommit,每一个sql 语句都组成了独立的txn;
默认mysql为每个连接创建一个session,并enable autocommit;
commit and rollback都会释放当前txn设置的Locks
consistent nonlocking reads
前面也谈到过,在RR,RC下select的模式是consistent read(CR). 这时Innodb gives your txn a timepoint according to which your querys see the database.
像下面这样例子,在RR下,A 是看不到B的提交的,因为timepoint 还处在B commit之前
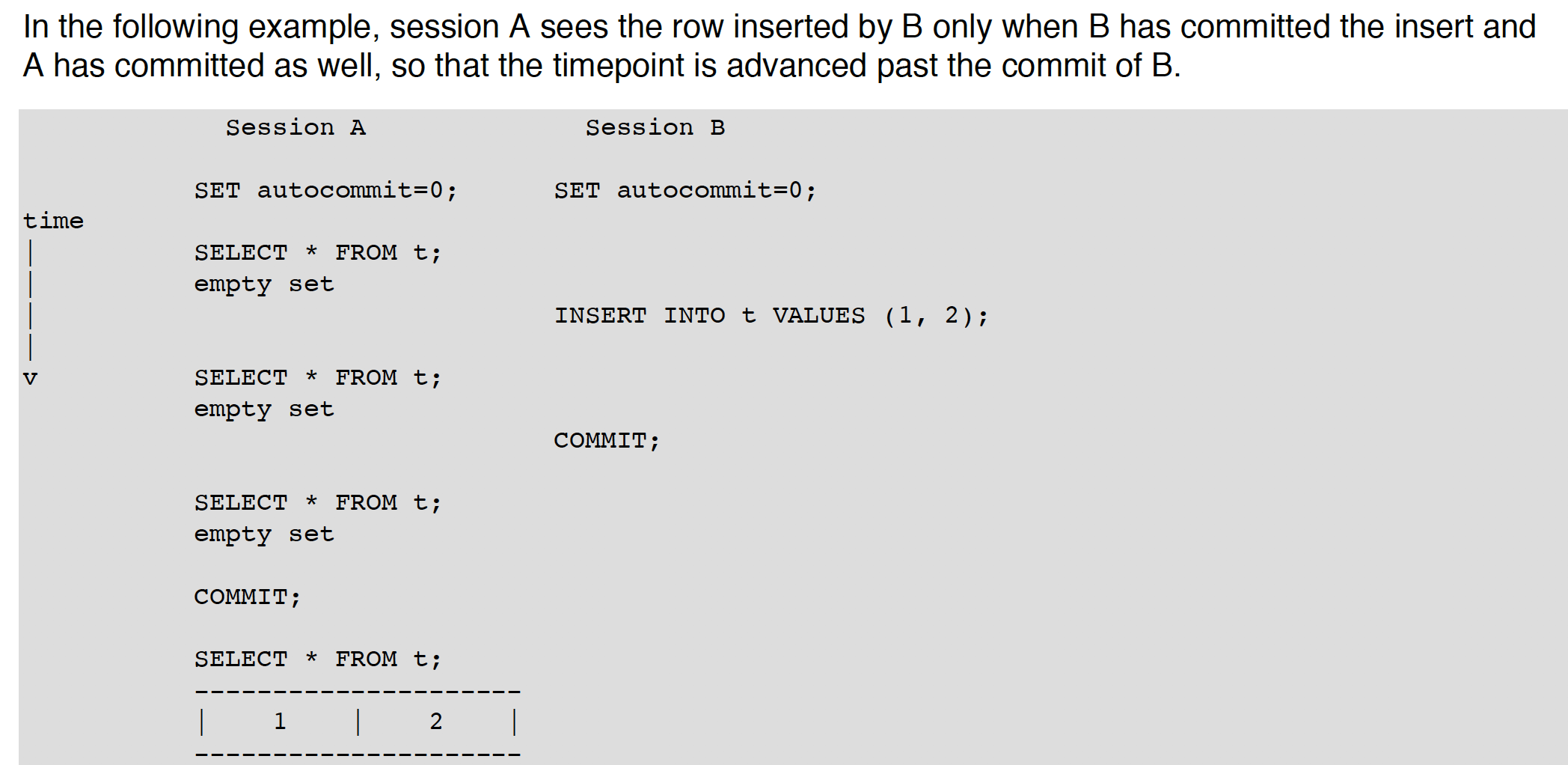
如果想看到最新的状态,用RC,或者使用locking read:
select * from t for share;
因为当for share指定时,它会阻塞,直到writing txn ends,这样等待返回后即是最新数据。
在某些DDL语句上,consistent read不奏效。如drop table, alter table
locking reads
select … for share
sets a shared mode lock on any rows that are read. Other sessions can read the rows, but cannot modify them until your txn commits. If any of these rows were changed by another txn that has not yet committed, your query waits until that txn ends and then use the latest values.
locking reads are only possible when autocommit is disabled (either by beginning txn with start Transaction or by setting autocmmit to 0)
外层的locking read clause不会造成内层的subquery也是locking read,
select * from t1 where c1=(select c1 from t2) for update;
Locks Set by different sql statements
描述了在不同的IL, sql语句下,加的是什么样的锁。
此小节待更新……
txn scheduling
使用Contention-Aware transaction scheduling(CATS)算法来调度等待锁的事务。给每个waiting txn分配scheduling weight,which is computed based on the number of txns that a txn blocks. 如果权重相同,则优先取等待最长的txn
在8.0.20前,还有个叫FIFO调度算法,CATS仅在剧烈锁竞争环境下使用。但是在8.0.20上 ,CATS得到了增强,已不再需要FIFO
内部XA事务
XA是由X/OPEN组织提出的分布式事务的规范,主要定义了事务管理器和资源管理器之间的接口;
使用mysql的XA事务实现分布式事务时,必须使用serializable IL
最为常见的内部XA事务存在于binlog与InnoDB之间(server本身作为TM,引擎作为RM),事务提交时,先写binlog,再写redo,要保证上述两操作是原子的;
https://blog.51cto.com/linzhijian/1909702
MySQL通过两阶段提交(内部XA的两阶段提交)很好地解决了这一问题(binlog和redo log一致性):第一阶段:InnoDB prepare,持有prepare_commit_mutex,并且write/sync redo log;将回滚段设置为Prepared状态,binlog不作任何操作;第二阶段:包含两步,1> write/sync Binlog; 2> InnoDB commit ,更新undo状态,fsync redo&undo, 写COMMIT log, 释放prepare_commit_mutex;以 binlog 的写入与否作为事务提交成功与否的标志,innodb commit标志并不是事务成功与否的标志。因为此时的事务崩溃恢复过程如下:1> 崩溃恢复时,扫描最后一个Binlog文件,提取其中的xid;2> InnoDB维持了状态为Prepare的事务链表,将这些事务的xid和Binlog中记录的xid做比较,如果在Binlog中存在,则提交,否则回滚事务。通过这种方式,可以让InnoDB和Binlog中的事务状态保持一致。如果在写入innodb commit标志时崩溃,则恢复时,会重新对commit标志进行写入;在prepare阶段崩溃,则会回滚,在write/sync binlog阶段崩溃,也会回滚。这种事务提交的实现是MySQL5.6之前的实现。
但write/sync binlog,这在5.6之前有性能缺陷。在5.6中采用binlog group commit;
在5.7中引入 MTS,多线程slave 复制,在binlog组提交时,给每一个组提交打上一个seqno,然后在slave中就可以按照master中一样按照seqno 大小顺序,进行事务组提交了。
Disk I/O and file spaces
checkpointing
使用fuzzy checkpointing,每次Flush modified pages from buffer pool in small batches.
在重启恢复时,从最新的checkpoint点 scan log files forward and apply the logged modifications to the db.
触发checkpoint的条件
以下来自 https://www.cnblogs.com/f-ck-need-u/p/9010872.html

sourcecode 8.0.19
上面说的yum安装,没想到mysqld是带有符号的,所以也可不用自己编译就能直接用gdb
在trx_commit处加断点,show tables时,有: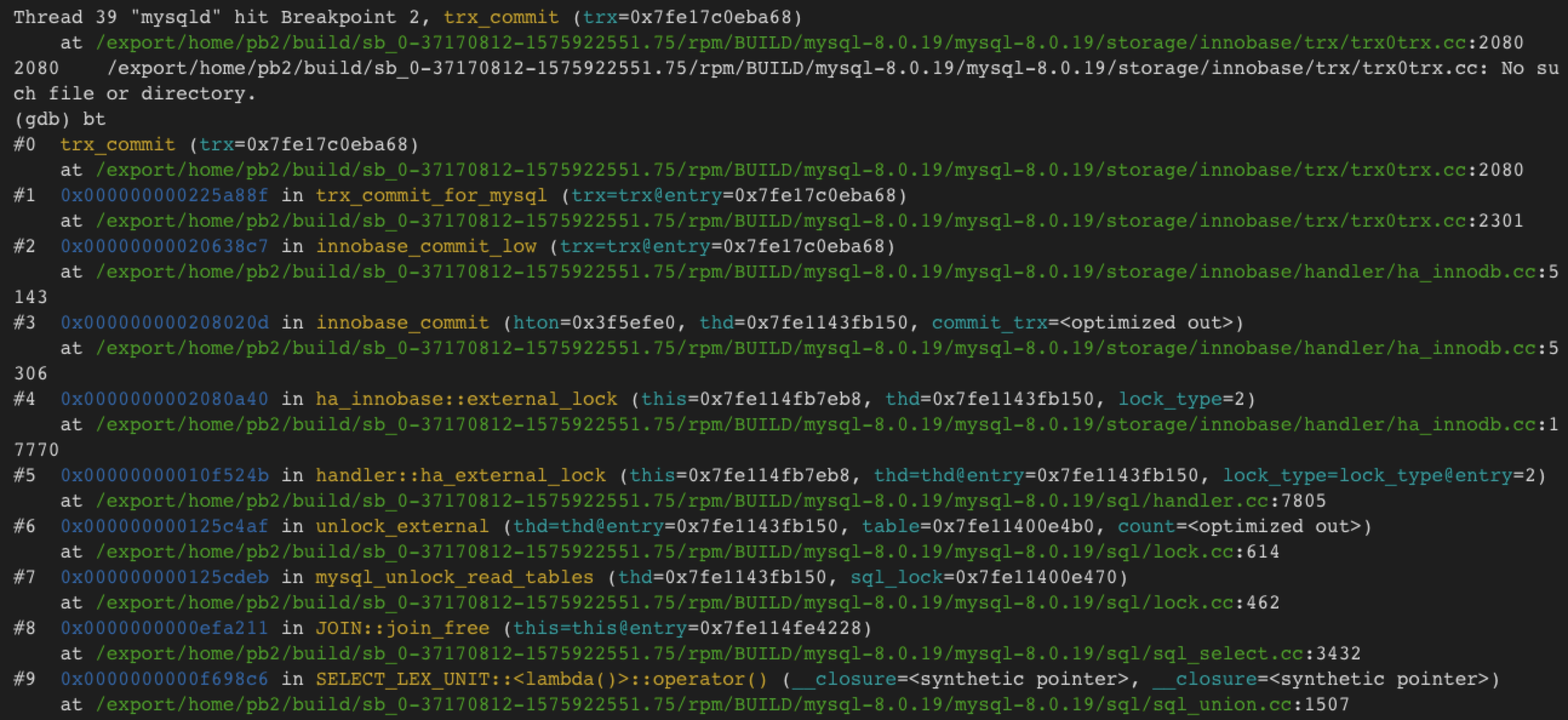

insert into t values(250),有:
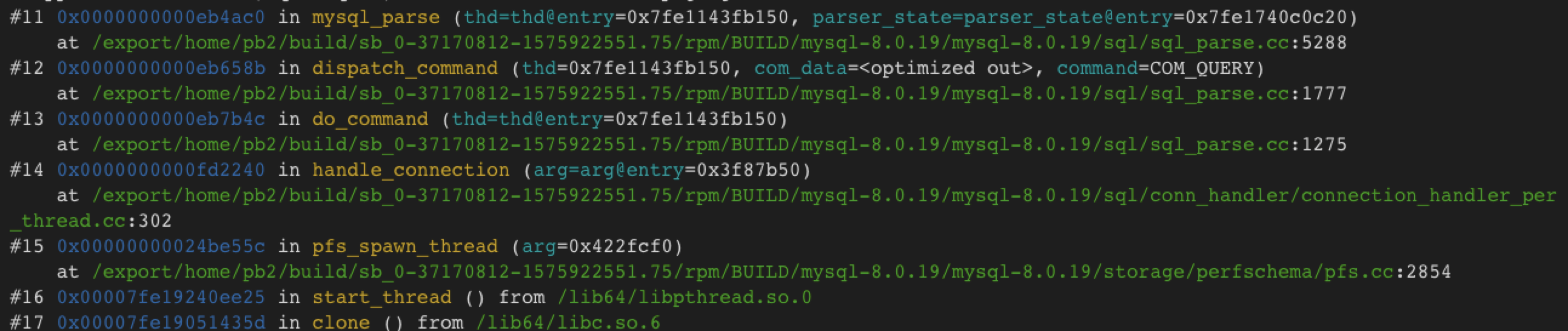
select * from t;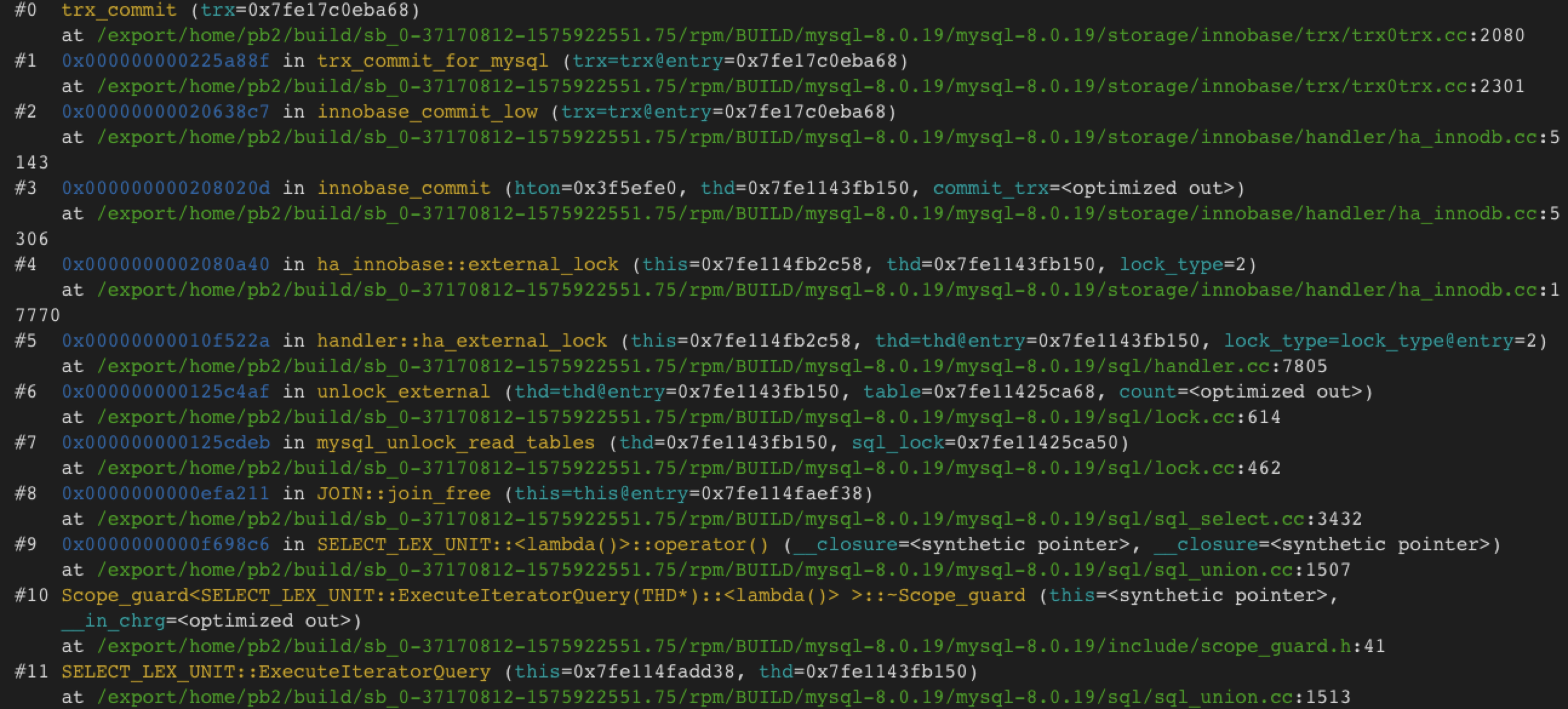
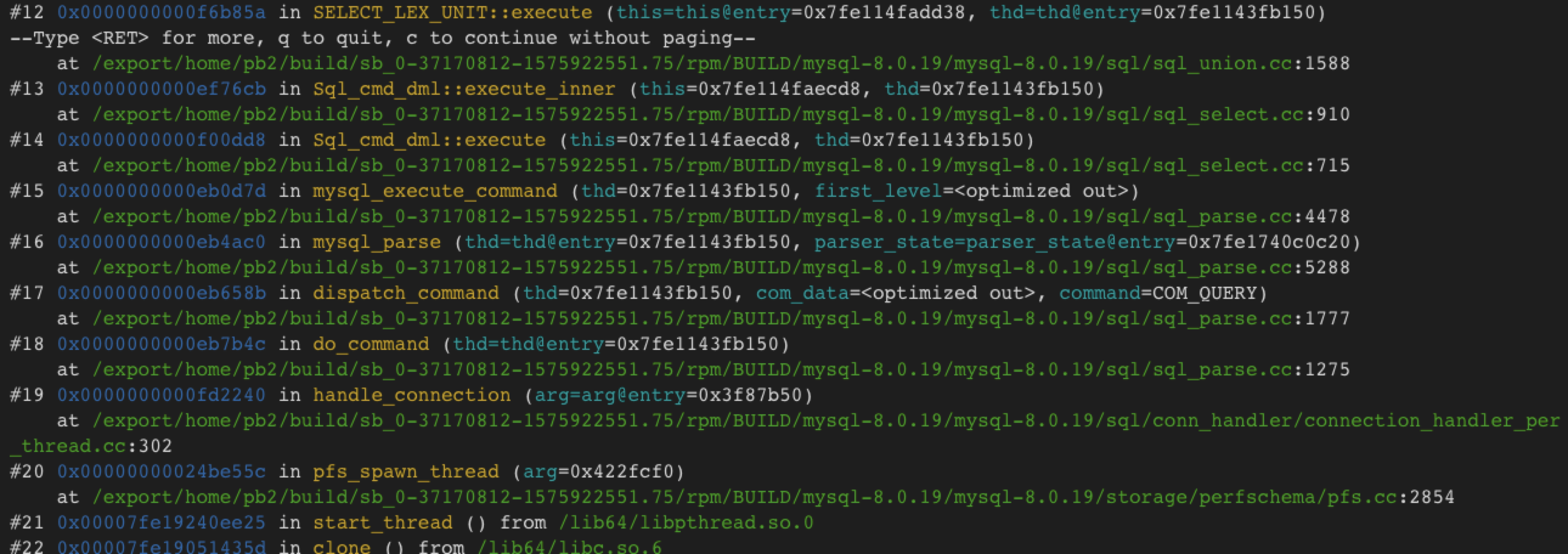
下面的统计线程也时不时调了trx_commit,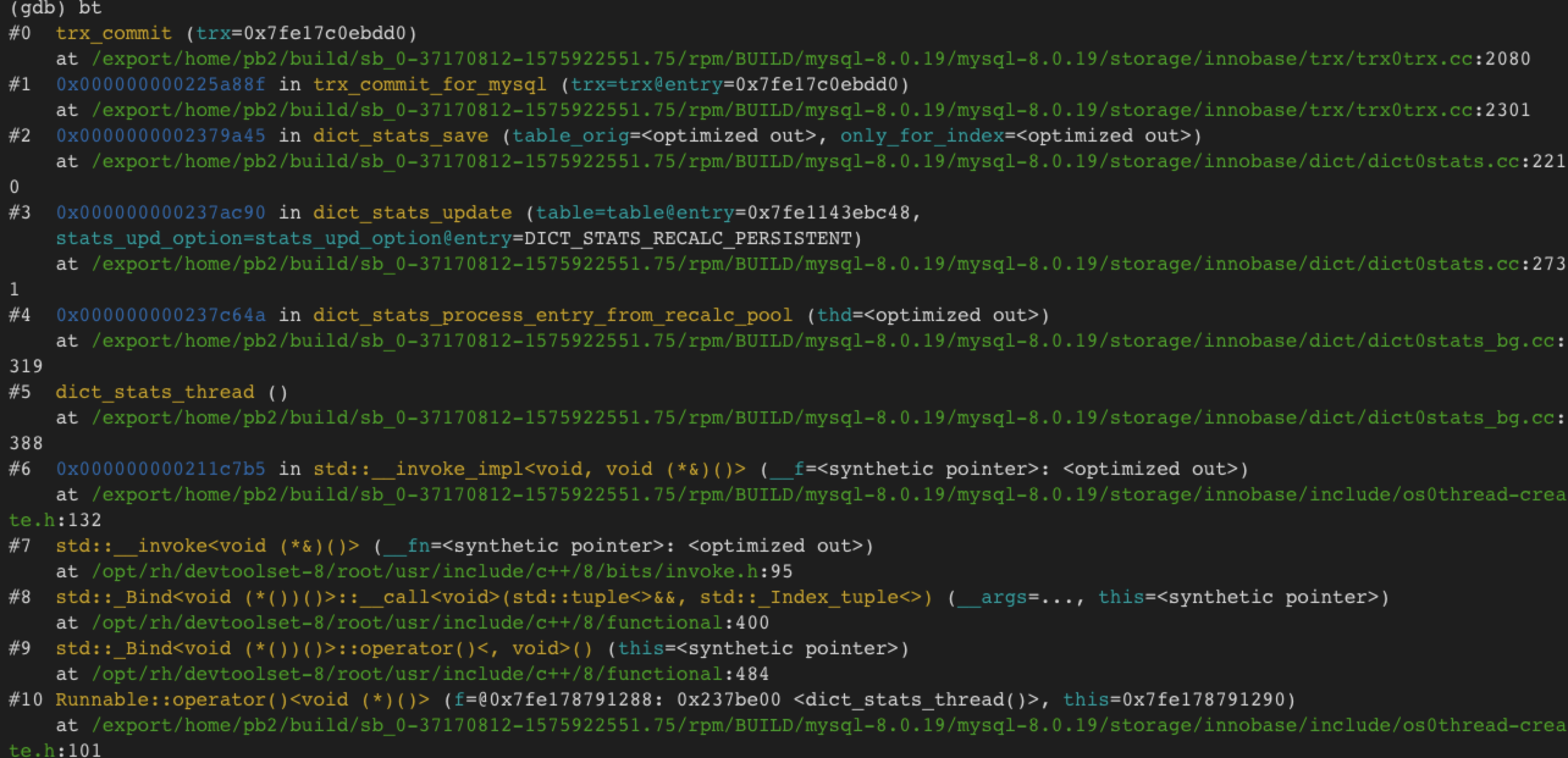

若有收获,就点个赞吧
0 人点赞
