5 replication
好处:
- 地理上可靠近用户
- 可故障冗余,哪怕系统一部分出了问题,不影响整体
- 横向扩展,提高读吞吐
single-leader replication
也叫master/slave, primary/secondary,mysql, pg都是这样
同步复制和异步复制
同步的好处就是能保证从节点的数据是新的,但一个节点出问题,就会导致写出问题;
异步复制没有上述问题,但是从节点数据可能是stale; 且如果leader 故障,则可能导致已经响应给client的写丢失;
增加new followers
直接拷贝 数据 是不行的(什么叫直接拷贝,mongo物理加节点不也行吗),写在不断进行;
通常的手段是:
- 对leader 做无锁的snapshot
- 将snapshot copy 到follower
- follower连接leader去获取snapshot期间的更新 (那么snapshot必然有个位置)
- follower处理完backlog,就已经 caught up了,可以继续了
具体db的动作可能相差很大;
应对node故障
follower故障:
重启,从上一个点开始追
leader故障:
发生failover
- 检测leader确实failed了(很多系统用超时机制)
- choose new leader
- reconfig system to use the new leader (要确保老的leader起来后,step down)
让所有的nodes同意一个新的leader,这是consensus问题!
failover可能发生事
- 如果使用异步复制,则若新Leader 没有收到old leader所有的写,则当old leader重新 加入时,会发生 什么 ? 往往会选择discard old leader’s writes,这样影响 了durability
- 在某些场景下,可能两个节点都 认为自己是Leader,此种称为
split brain,是危险 的。作者说一些系统 有机制在出现 两个leaders时,关闭其中一个(怎么检验的??) - 检测dead leader的timeout 多长合适呢?不好说
replication logs的实现
statement-based replication
leader把每个 write请求都 log,然后把语句log发给Followers
缺陷:存在不确定性情况,比如语句中的Now(), Rand() 调用
WAL shipping
这里的WAL 是append-only seq of bytes,包含对db的writes(说的应该是serialized mutaion)
pg和oracle都这样用,但缺陷:
log data太过底层,可以产生二进制不兼容(新版本做到与老版本不就行了??),若不兼容,则升级可能 需要 downtime
row-based log replication
mysql 配置成 此模式时,binlog就是所谓的 Logical log ,它和引擎层解耦了,这样允许 leader, follower跑不同版本,甚至不同引擎
且logical log这种格式更有利于外部系统 使用,比如将 更新导入到warhouse,change data capture等
7 事务
P227
要用批判的态度看待理论上的保证
P230
事务是指把对多个objects的多个操作组合成一个单元 ,而像CAS这样的操作不是事务
P232
无主系统 没有事务 commit/abort 这样的哲学 ,它们是基于 “best-effort”,因此不会回滚,需要app负责恢复 ??
abort 事务并不是完美的。因为:
- 如果事务实际上成功了,但没有成功给客户端确认(比如 网络故障),这样客户会重试,就会执行两次
- 如果错误是过载,那重试会加剧问题。因此服务端要限流,控制并发/重试次数等
- 如果是transient error,重试是有用的(比如mongo的
TransientTransactionError);但如果是永久错误,则重试无用 - 如果事务在db外还有一些副作用,比如发了邮件,那么即使事务回滚,那副作用也已经发生了
weak isolation level
原子写操作
像mongo 的update, findAndModify 属于原子写,经常是对对象采取独占锁实现的;
在FDB record layer 论文里,说RMW 操作似乎是跑在事务里,不会被回滚;因此它们适合实现counter
dirty write强调覆盖了uncommitted writes;
而lost update强调覆盖了committed writes,但是违反了场景的invariant(前面的写不该丢失而丢失了)
实现read committed
最简单做法就是对object 加锁直到提交;但如果碰到long-running write tx 将会阻塞读事务
repeatable read
银行转帐,Alice 从帐户1转100到帐户2(两帐户最初都有500),如果Alice在转账过程中快速查看,可能发现一个帐户是400,一个帐户是500,好像少了100.
过几秒后再读,就好了。
SSI
检测 stale MVCC reads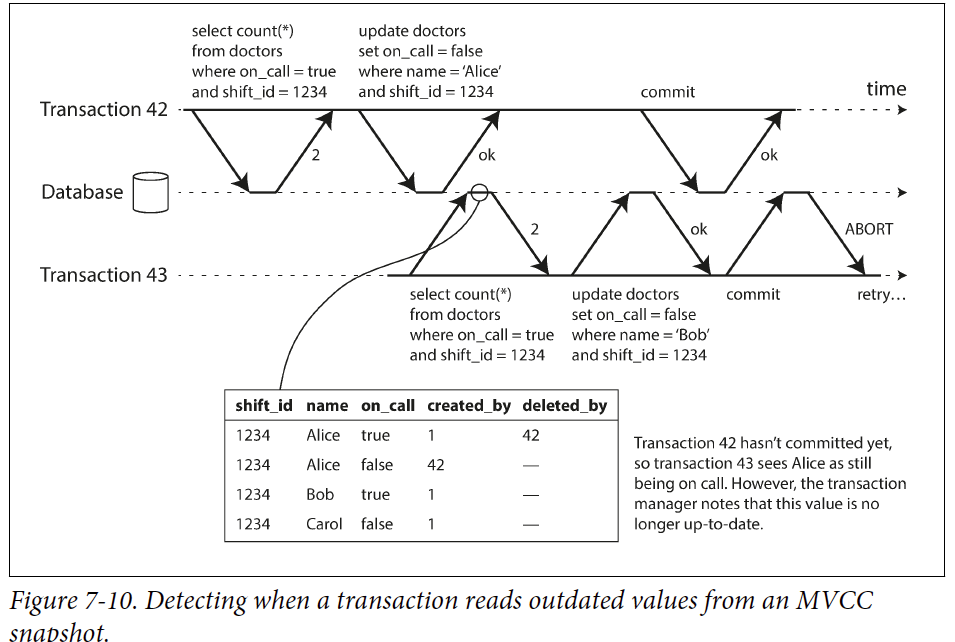
检测影响先前的读的写: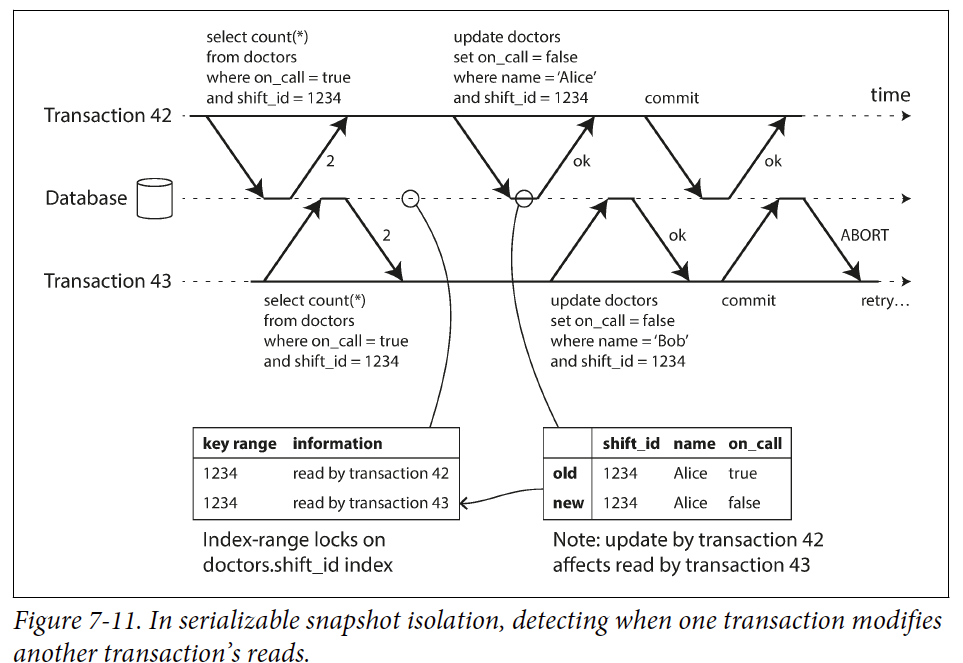
In some cases, it’s okay for a tx to read information that was overwritten by another tx: depending on what else happened
那实际中该如何判断读有没有受到影响呢?
PG SSI example
https://wiki.postgresql.org/wiki/SSI
这里讲述了一个很contrived 的例子,两个事务的写互相影响了彼此的读;
还列举了一个只读事务引起anomaly 的情况!
9 consistency and consensus
Linearizability
Linearizability 根本含义是说: 表现得就像系统只有一份数据拷贝一样,所有针对它的操作都是原子的;
但是如果真的弄成一份拷贝,又无能冗余故障。所以先看看第5章介绍的哪些 replication method 可以是linearizable
- single-leader replication
potentially linearizable
- consensus 算法
linearizable
- 多主复制
不是 Lin
- leaderless replication
probably not Lin
作者认为 基于LWW 的情况几乎不是Lin,且sloppy quorums and hinted handoff 也会破坏 Lin
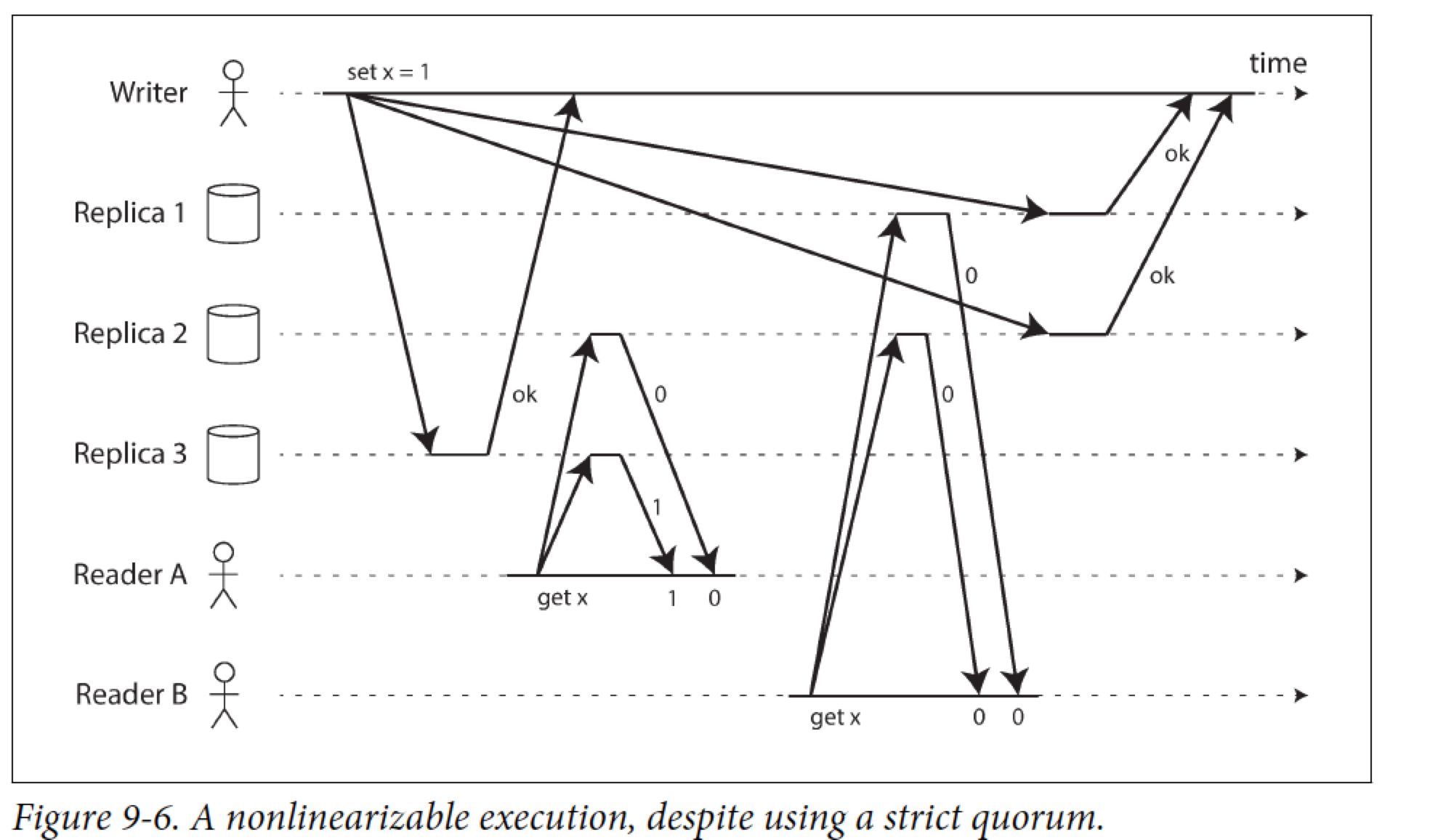
这个图在说明,即使用了quorum 读写,也不能保证Lin,因为B 不应该读到 0
P336强调了写和线性一致读 请求会被发送到 leader上(对于single-leader replication)
CAP 是不严谨的,已经有很多更加精确的results来代替它,所以我们尽量不要用这个词汇了;
P338 说明了CPU上的内存地址访问也不是Lin,这是为了性能考虑(读cache),而不是为了fault-tolerant
有作者证明,如果要求Lin,则有论文证明:读写请求的响应时间至少会和网络时延的不确定性正相关;
order
在ordering, Lin, consensus之间有着强烈的联系!
ordering 重要的一个因素就是 causality
如果 一个系统 遵从由causality 施加的ordering,则我们说它是 causally consistent
在snapshot isolation中,我们说读一个consistent snapshot , 这里的consistent 指什么? 就是指 consistent with causality : 如果快照中包含 answer ,那它一定得包含 此answer 的question
total order: 说的是任何两个元素可以compare
但是比如数学集合就无法比较,它们属于 partially ordered
对于Lin,
我们说它有total order of operations,因为每个操作是原子的,必然有先后顺序;
因此在时空图上,Lin 的操作连起来只有一条single timeline
对于Causality,
有的事件间有happen before关系,有的没有,所以causality定义的是partial order
那它们俩什么关系呢?
Lin implies causality
Q:因果一致性为何不受网络延迟影响?
但保持Lin代价昂贵,所以很多data system放弃Lin,好消息是不是只有Lin 才能实现 causality。实际上, causal consistency 是一致性模型中最强的一个model,即使面对network delay和failures,它也不会slow down或者不可用[2,42] ??
因此,有学者正在探索保持causality,而不损失性能的新型database
capturing causal dep
作者没说太细,大致勾勒一下:
为了maintain causality,每个replica都需要知道哪些op是concurrent ,哪些是 happen before ,对于后者,就是保证later ops要等preceding ops完成才能继续进行;
那如何决定哪个op在哪个之前 呢? version vector是一种方式;
另外,为保持因果序,db很可能需要知道什么事务读了什么对象等等这样的信息; 因为在fig 5-13里,客户端会把先前op的版本再传给db
sequence number ordering
实际情况下,要维护所有的因果关系是不实际的,有太多的读写了,但是有一种方式可以更好地做到: sequence number or timestamps
往往使用logical clock,counter来自增每一个op,它们提供了一种total order : 每个op都有seq num,你可以比较来判断谁在前谁在后,这样创建出的total order要 consistent with causality
(作者举了例子:创建一个total order其与因果序无关,是很简单的,比如用UUID来为每一个op编号 ,每个UUID可以按字符比较,但无法看出哪个op在前,哪个在后)
在single-leader 复制中,主维护的 total order of writes就是和因果序一致的,其中为每个op生成了seq num,那Follower收到后按照seq num来apply,结果必然和leader 一致
但是在多主系统,或无主系统中,如何生成causally-consistent sn 呢?关键是要能给不同Node间的op 赋予因果 序
Lamport Timestamp
一个simpel pair , (counter , node id)
要求一点:客户端与node 都去维护一个迄今为止看到的最大的counter,这样就能保证由lamport ts 生成的total order 是causally consistent
Q:是否要求driver 得维护一个max counter? mongo driver 的clusterTime 会发给server,是一个思想吗?
Lamport ts的不足
能比较ts的前提是,当前node 已经收集了系统所有的相关op,但是倘若当前正准备执行uniqueness 约束这样的op时(如创建唯一的username),不知道其它节点是否也在做,这样就无法比较ts 了;如果采取 check 每个其它节点是否在做相同的事情 ,代价有点高,而且不允许有网络故障,否则就无法做下去了
这时候就需要total order broadcast
Q: 唯一性约束问题会在单主系统中出现吗?
total order broadcast
前一节说:
the idea of knowing when total order is finalized is captured in the topic of total order broadcast
Q: 这一节好像是在描述单主系统下的多播,如果是无主呢?各节点该如何同步total order ?
TOB一个重要的方面是,在消息被delivered后,total order is fixed(finalized),不能在order中插入一个更早的op ; 像zk, etcd都实现了TOB
TOB 也有助于实现锁服务, 提供fencing tokens,像zk 中的zxid
作者最后说,线性化的compare-and-set 操作与TOB 是 等价的, 很令人意外的结论!(没看懂,要调研下)
分布式事务
2PC
如果 coordinator 挂了,且participant 收到了prepare,则它要无限等待下去
coordinator 发commit/abort 前,得把 commit log/abort log 写入到disk,以防止coordinator crash情况
3PC
3PC 可以使得2PC 不再阻塞,但是它假设network with bounded delay, ndoes with bounded response time,这在实际中不现实
它需要一个完美的failure detector,无法准确判断节点挂了没有
所以2PC continue to be used
实际中的分布式事务

若有收获,就点个赞吧
0 人点赞
