Redis 为什么那么快
1. 高速的存储介质
redis 使用内存作为存储介质,内存的随机访问速度比硬盘快
2. 优良的底层数据结构
3. 高效的线程模型
4. 高效的网络IO模型
Redis 数据结构
SDS (simple dynamic string)
主要解决
- C语言以 \0 空字符串的结束符,不用遍历就可以获得字符串长度
- 减少String类型频繁修改时,内存需要重新不断分配的问题
- 内存溢出的问题
SDS示例struct sdshdr {//记录数组中所使用的字节数,相当于字符串的长度int len ;//记录数组中未使用的字节数量int free;//字节数组,保存字符串char buf[];}
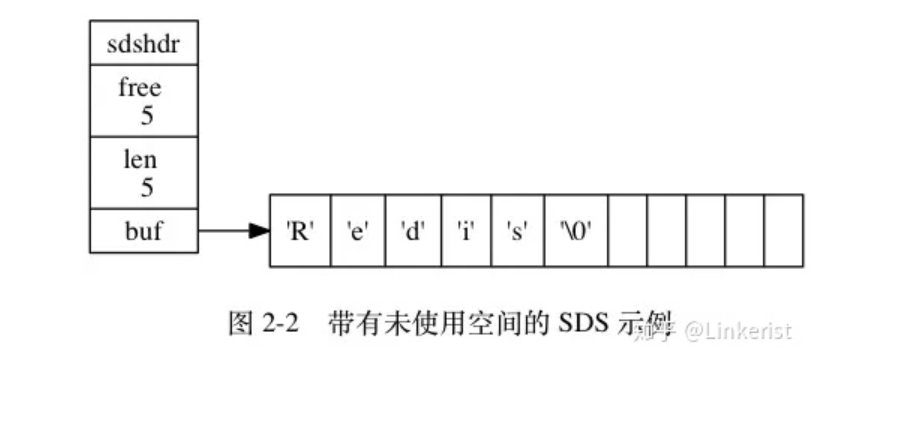
SDS 在执行拼接操作时,先会去检查给定的SDS 的空间是否足够,如果不够,先去扩展SDS空间,再进行拼接操作。
减少修改字符串时带来内存冲分配次数
因为C的字符串长度和底层数据长度存在相关联。增长或缩短一个C 字符串都会进行一次内存重分配。
hash 表
ziplist 压缩列表
skipList 跳表
跳跃表的实现比平衡树更简单,跳表主要解决单链表遍历效率慢的问题,同一个跳跃表中,各个节点保存的成员对象必须是唯一的,当时多个节点保存的分值可以是相同的,分值相同的节点将按照成员对象在字典序中的大小进行排序,成员对象大小进行排序
quicklist 快速列表
Redis 有5种基础数据类型,string (字符串),list(列表),set(集合),hash(哈希),zset(有序集合)
同一种数据类型,可以有多种不同编码作为底层实现,同一种编码也可以作为多种数据类型上层实现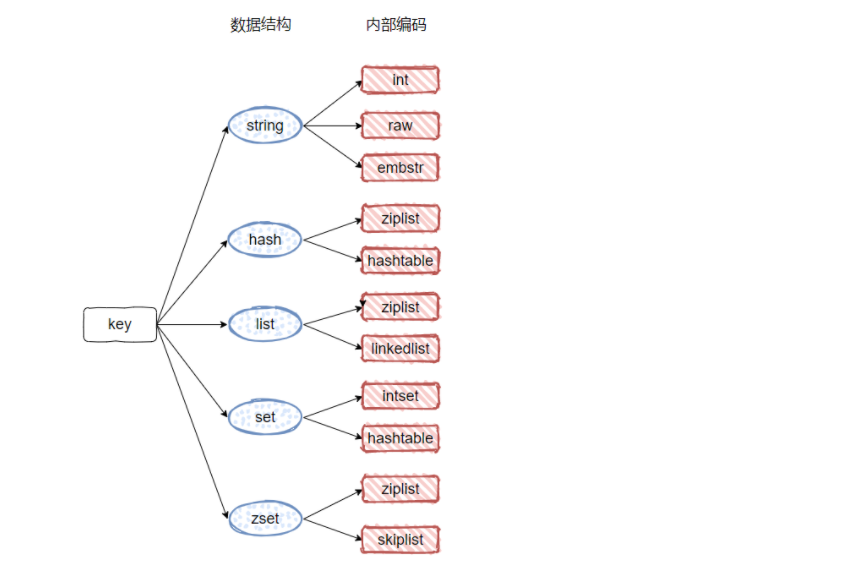
5种基本数据类型
string
string 是Redis 最简单的数据结构,Redis 所有的数据结构都以唯一字符串Key作为名称,然后通过唯一的Key 来获取相应的value 数据, value 可以是json 数据
> set name helloOK> sadd name helloset(error) WRONGTYPE Operation against a key holding the wrong kind of value
string 数据类型使用非常广泛,一个常见的用途就是缓存用户信息,我们将用户信息结构体使用JSON 序列化成字符串,然后将序列化后的字符串塞进Redis来缓存,同样,去用户信息会经过一次反序列化的过程。
键值对
> set name dapengOK> get name"dapeng"> del name(integer) 1> get name(nil)
批量键值对
可以批量对字符串进行读写,可以节省网络开销
> set name1 oneOK> set name2 towOK> set name2 twoOK> mget name11) "one"> mget name1 name21) "one"2) "two"> mset name1 one name2 #必须给每一个key 配有对应的value值(error) ERR wrong number of arguments for MSET> mset name1 one name2 twoOK
过期和 set 命令扩展
可以对 key 设置过期时间,到点自动删除,这个功能常用来控制缓存的失效时间。不过这个「自动删除」的机制是比较复杂的,
> set name dapengOK> get name"dapeng"> expire name 5 # 5s后过期(integer) 1> get name(nil)> setex name 5 dapeng # 相当于 set + expireOK> get name"dapeng"> get name(nil)> setnx name dapeng(integer) 1> get name"dapeng"> setnx name dapeng(integer) 0> get name"dapeng"> setnx name dalin # 因为name已经存在,所有set创建不成功(integer) 0
计数
如果value 值是一个整数,还可以对他进行自增操作,自增是有范围的,它的范围 signed long 的最大最小值,超过了这个值,Redis 会报错
> set age30OK> incr age # 对age +1(integer) 1> incrby age 5(integer) 6> incrby age -5(integer) 1> decrby age -5(integer) 6> decrby age 2(integer) 4> incr number #对未设置值的number 进行incr操作时 number默认为0(integer) 1> get number1(nil)
list(列表)
Redis 的list 相当于Java 中LikedList,这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n),这点让人非常意外。 list 能够存储大量的数据。
当列表弹出最后一个元素之后,该数据结构自动被删除,内存被回收
缺点: 由于list 底层使用的是双向链表,所以他的查询效率比较慢。
Redis 的列表结构常用来做异步队列使用,将需要延后处理的任务结构体序列化成字符串塞进 Reids 的列表,另一个线程从这个列表中轮询数据进行处理
> rpush books python java golang(integer) 3> llen books # 队列的长度(integer) 3> lpop books #左进右出"python"
快速列表
如果再深入一点,你会发现 Redis 底层存储的还不是一个简单的 linkedlist,而是称之为快速链表 quicklist 的一个结构。
- 首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是
**ziplist**,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。 - 当数据量比较多的时候才会改成
**quicklist**。因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。 - 所以 Redis 将链表和
ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
hash (字典)
Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典。内部实现结构上同 Java 的 HashMap 也是一致的,同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
hash value的值只能去String
> hset books java "think in java" # 命令行的字符串如果包含空格,要用引号括起来(integer) 1> hset books golang "concurrency in go"(integer) 1> hset books python "python cookbook"(integer) 1> hgetall books # entries(),key 和 value 间隔出现1) "java"2) "think in java"3) "golang"4) "concurrency in go"5) "python"6) "python cookbook"> hlen books(integer) 3> hget books java"think in java"> hset books golang "learning go programming" # 因为是更新操作,所以返回 0(integer) 0> hget books golang"learning go programming"> hmset books java "effective java" python "learning python" golang "modern golang programming" # 批量 setOK
set(集合)
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL(类似于 HashSet 的底层结构)。
> sadd lag java(integer) 1> sadd lag java pathon go(integer) 2> smembers lag # 与插入顺序并不一致,因为set是无序的1) "pathon"2) "java"3) "go"> sismember lag java # 查询某个 value 是否存在,相当于 contains(o)(integer) 1> scard lag #获取长度 相当于count()3> spop lag # 弹出一个"pathon"
Zset (有序集合)
zset 可能是 Redis 提供的最为特色的数据结构,它也是在面试中面试官最爱问的数据结构。它类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。它的内部实现用的是一种叫做「跳跃列表」的数据结构。
zset 中最后一个 value 被移除后,数据结构自动删除,内存被回收。
> zadd books 9.0 "think in java"(integer) 1> zadd books 8.9 "java concurrency"(integer) 1> zadd books 8.6 "java cookbook"(integer) 1> zrange books 0 -1 # 按 score 排序列出,参数区间为排名范围1) "java cookbook"2) "java concurrency"3) "think in java"> zrevrange books 0 -1 # 按 score 逆序列出,参数区间为排名范围1) "think in java"2) "java concurrency"3) "java cookbook"> zcard books # 相当于 count()(integer) 3> zscore books "java concurrency" # 获取指定 value 的 score"8.9000000000000004" # 内部 score 使用 double 类型进行存储,所以存在小数点精度问题> zrank books "java concurrency" # 排名(integer) 1> zrangebyscore books 0 8.91 # 根据分值区间遍历 zset1) "java cookbook"2) "java concurrency"> zrangebyscore books -inf 8.91 withscores # 根据分值区间 (-∞, 8.91] 遍历 zset,同时返回分值。inf 代表 infinite,无穷大的意思。1) "java cookbook"2) "8.5999999999999996"3) "java concurrency"4) "8.9000000000000004"> zrem books "java concurrency" # 删除 value(integer) 1> zrange books 0 -11) "java cookbook"2) "think in java"> zadd list 9.0 js #如果scor相同,那么按照value值进行排序(integer) 1> zrange list 0 -11) "javas"2) "java"3) "js"
容器型数据结构的通用规则
list/set/hash/zset 这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
create if not exists
如果容器不存在,那就创建一个,再进行操作。比如 rpush 操作刚开始是没有列表的,Redis 就会自动创建一个,然后再 rpush 进去新元素。drop if no elements
如果容器里元素没有了,那么立即删除元素,释放内存。这意味着 lpop 操作到最后一个元素,列表就消失了。
过期时间
一个需要特别注意的地方是如果一个字符串已经设置了过期时间,然后你调用了 set 方法修改了它,它的过期时间会消失。
127.0.0.1:6379> set codehole yoyoOK127.0.0.1:6379> expire codehole 600(integer) 1127.0.0.1:6379> ttl codehole(integer) 597127.0.0.1:6379> set codehole yoyoOK127.0.0.1:6379> ttl codehole(integer) -1
Redis持久化
如果服务器突然碰到断电的情况,由于Redis 的数据都在内存中,防止数据丢失,确保数据安全性,
RDB 是一个紧凑压缩的二进制文件,存储效率较高。
RBD 恢复数据要比AOF 快的多
RDB 无法做到实时持久化,具有较大的可能性丢失数据
RDB
Redis 以快照的方式,将当前数据状态进行保存。
save
手动执行一次保存操作,默认文件为 dump.rdb
save 指令的执行会阻塞当前Redis 服务器,直到当前RDB 过程完成为止,可以会造成长时间的阻塞,
bgsave
手动启动后台保存操作,但不是立即执行,会启动一个子线程进行持久化操作,针对save 阻塞问题进行优化。
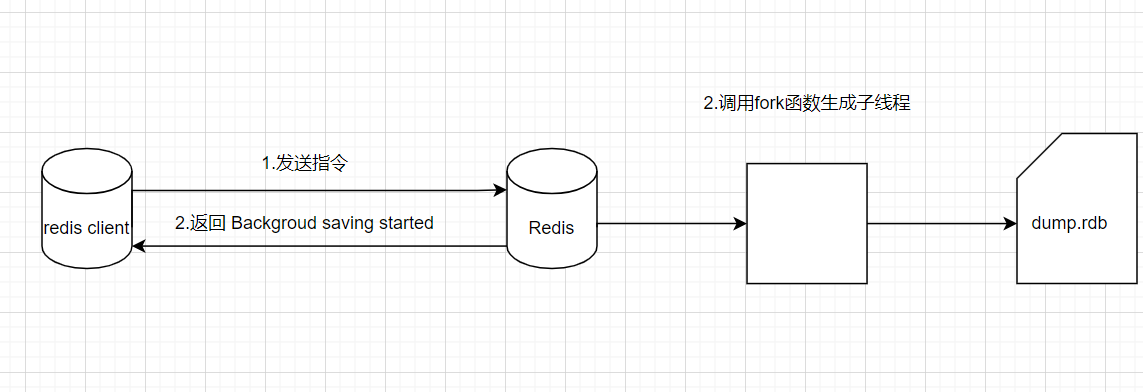
RDB自动保存
save second changes
满足限定时间范围内key 的变化数量达到指定数量即进行持久化。
缺点
- 存储数据量较大,效率较低,基于快照思想,每次读写都是全部数据,当数据量巨大,效率非常低。
- 大数据量下IO 效率较低
- 基于fork 创建子线程,内存产生额外消耗。
- 宕机会带来数据丢失风险
AOF
AOF (append only file) 持久化,以独立的日志的方式记录每次写命令,重启时再重新执行AOF文件中命令,达到恢复数据的目的。主要作用是解决了数据持久化的实时性。AOF将写命令刷新到缓冲区,将命令同步到AOF 文件中,
AOF 写数据的三种策略(appendfsync)
always(每次)
每次写入操作均同步到AOF 文件中,数量零误差,性能较差。
everysec(每秒)默认
no (系统控制)
AOF 重写
随着命令不断写入AOF ,文件会越来越大,为了解决这个问题,Redis 引入了AOF 重写机制压缩文件体积,
- 降低磁盘占用率,提交磁盘利用率
- 提高持久化效率,降低持久化写时间,提交IO 性能
- 降低数据恢复用时,提交数据恢复效率
事务
Redis 在执行的过程中,多条连续执行的指令被干扰,打断,插入,Redis 事务就是一个命令执行的队列,将一系列预定义包装成一个整体,当执行时,一次性按照添加顺序依次执行,中间不会被打断或者干扰。
multi 开启事务
exec 执行事务
discard 取消事务
如果语法错误,所有命令都不会执行,如果出现命令错误,运行错误的命令不会被执行,如对list 进行 incr操作
watch
对key 添加监视锁,在执行exec 前如果key 发生了变化,终止事务执行,
watch key1 [key2]
取消对所有key 的监视
uwatch
删除策略
过期数据不是马上删除,数据删除策略在内存占用和CPU占用之间寻找一种平衡,
惰性删除
数据到达过期时间,不做处理,等下次访问该数据时,再去判断数据是否过期,
这样操作会导致内存压力较大,
定时删除
逐出算法
当新数据进入redis ,内存不足,就要逐出一段内存
Redis 删除大key
所谓大key 就是某个key的value 比较大,本质上是value比较大的问题,
key 可以有程序自行设置的,value往往不受程序控制
因为Redis 的核心工作线程是单线程,删除大key 是一个比较耗时的操作,会阻塞线程,并发量下降,
在大于redis 4 版本中,redis可以使用unlike 会计算删除key 的成本,从而做出同步或异步删除的选择,实现异步删除
del 命令是同步
来源
https://zhuanlan.zhihu.com/p/473930220
https://www.redis.com.cn/commands/unlink.html
Redis 分布式锁
Redis 哨兵模式
缓存一致性问题
Redis主从复制
Redis集群

若有收获,就点个赞吧
0 人点赞
