es 安装
docker 安装 es
docker pull docker.io/elasticsearch:7.6.1service docker start
- 运行容器启动 Elasticsearch
docker run -d --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" b0e9f9f047e6
Docker安装Elasticsearch、Kibana
1. 下载镜像文件
存储和检索数据 docker pull elasticsearch:7.4.2 # 可视化检索数据 docker pull kibana:7.4.2
2. 配置挂载数据文件夹
# 创建配置文件目录mkdir -p /mydata/elasticsearch/config# 创建数据目录mkdir -p /mydata/elasticsearch/data# 将/mydata/elasticsearch/文件夹中文件都可读可写chmod -R 777 /mydata/elasticsearch/# 配置任意机器可以访问echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
3. 启动Elasticsearch
命令后面的 \是换行符,注意前面有空格
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e"discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ -v/mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \-d elasticsearch:7.6.1
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.6.1
- -p 9200:9200 -p 9300:9300:向外暴露两个端口,9200用于HTTP REST API请求,9300 ES 在分布式集群状态下 ES 之间的通信端口;
- -e “discovery.type=single-node”:es 以单节点运行
- -e ES_JAVA_OPTS=”-Xms64m -Xmx512m”:设置启动占用内存,不设置可能会占用当前系统所有内存
- -v:挂载容器中的配置文件、数据文件、插件数据到本机的文件夹;
- -d elasticsearch:7.6.1:指定要启动的镜像
访问 IP:9200 看到返回的 json 数据说明启动成功。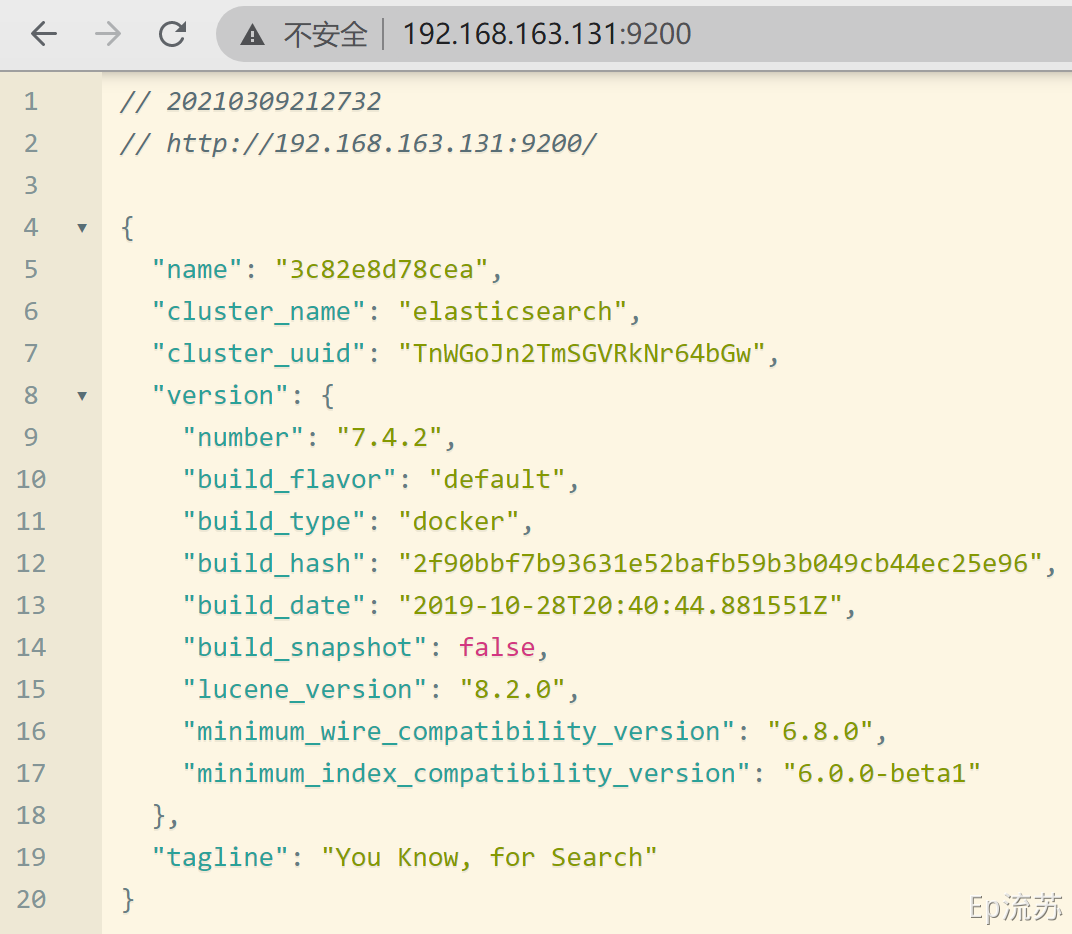
4. 设置 Elasticsearch 随Docker启动
当前 Docker 开机自启,所以 ES 现在也是开机自启 docker update elasticsearch —restart=always
5. 启动可视化Kibana
docker run --name kibana \ -e ELASTICSEARCH_HOSTS=http://120.77.34.253:9200 \-p 5601:5601 \ -d kibana:7.6.1
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://120.77.34.253:9200 -p 5601:5601 -d kibana:7.6.1
-e ELASTICSEARCH_HOSTS=http://192.168.163.131:9200: 这里要设置成自己的虚拟机IP地址
浏览器输入192.168.163.131:5601 测试: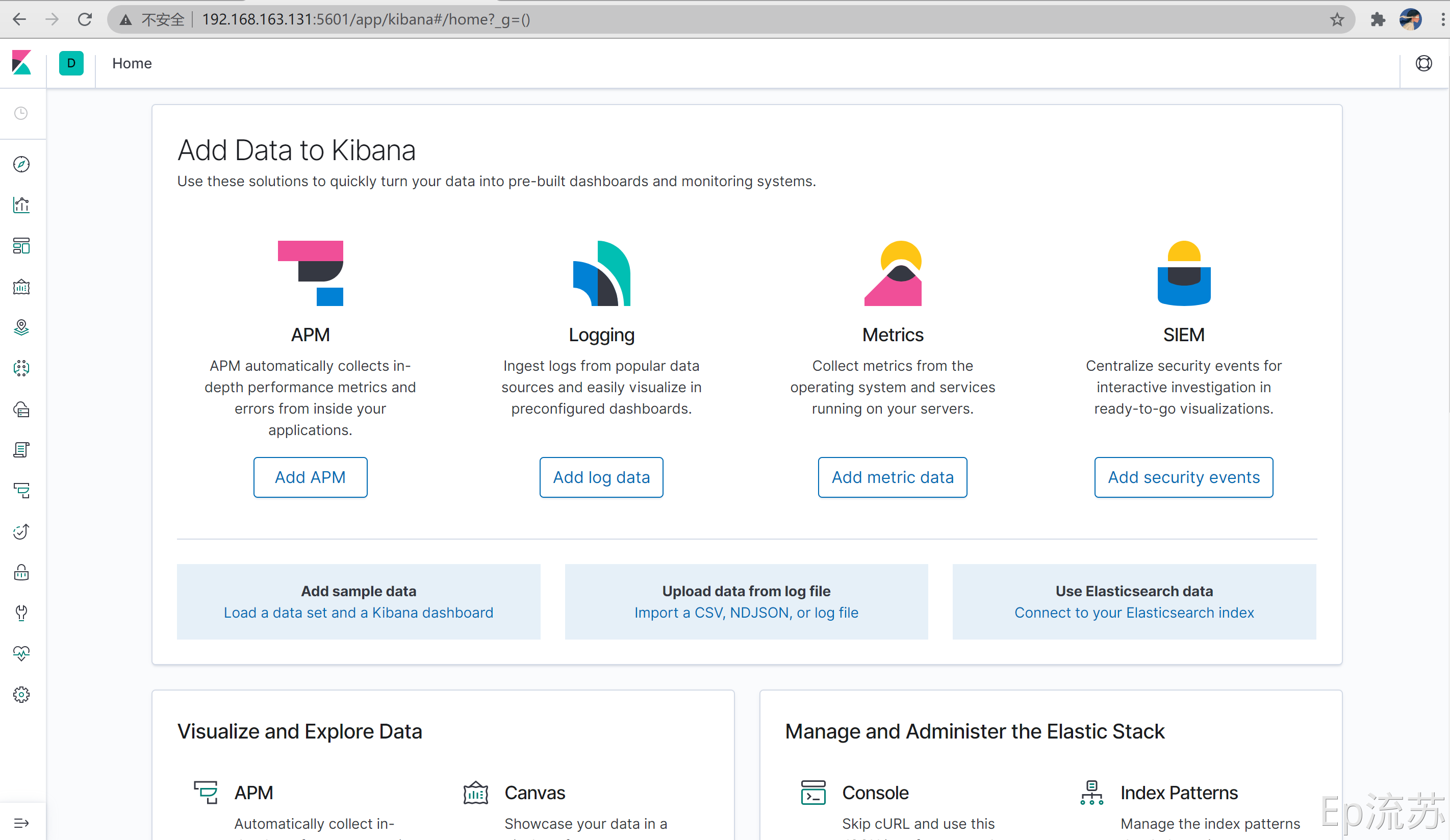
6. 设置 Kibana 随Docker启动
当前 Docker 开机自启,所以 kibana 现在也是开机自启 docker update kibana —restart=always
index 操作
搜索
使用 match_all 来查询全部数据
GET _search{"_source": ["account_number", "balance"], // 指定返回的字段内容"query": {"match_all": {}}"from" 0,"size": 10 ,"sort": { // 指定排序字段和排序顺序"balance": {"order": "desc"}}
条件搜索
使用match 表示匹配条件
GET _search{"query": {"match": {"account_number": 20}}}
组合搜索
组合搜索,使用bool 来进行组合,相当于 SQL where 关键字,must 表示同时满足条件
GET _search{"query": {"match": {"bool": {"must": [{ "match": { "address": "mill"}},{"match": { "address": "mills"}}]}}}}
should 表示满足其中任意一个条件
GET _search{"query": {"match": {"bool": {"should": [{ "match": { "address": "mill"}},{"match": { "address": "mills"}}]}}}}
过滤搜索
搜索过滤,使用 filter 来表示,一般用于范围查询。
gt: greater than 大于
gte: greater than or equal 大于等于
lt: less than 小于
lte: less than or equal 小于等于
GET _search{"query": {"match": {"bool": {"should": [{ "match": { "address": "mill"}},{"match": { "address": "mills"}}],"filter": {"range": {"count": { //count 字段"gte": 2000, //"lte": 3000}}}}
搜索聚合
对搜索结果进行聚合,使用aggs (aggregation) 组合 表示,类似于MySQL中的 group by ,例如对state 字段进行聚合,统计出相同 state 的文档数量
GET _search{"size": 0,"aggs" {"group_by_state": { // 分组名"term": {"field": "state.keyword"}}}}
嵌套聚合,例如对state 字段进行聚合,统计出相同 state 的文档数量,再统计出balance 的平均值
GET _search{"size": 0,"aggs" {"group_by_state": {"term": {"field": "state.keyword"},"aggs": {"average": {"avg":{"field": "balance"}}}}}
public class TestEs {private String clusterName ="es-smk-sit";private String clusterNode = "192.168.23.10";private String clusterPort ="9301";private String poolSize = "10";private boolean snf = true;private String index = "smk-label";private String type = "label";public TransportClient transportClient() {TransportClient transportClient = null;try {Settings esSetting = Settings.builder().put("cluster.name", clusterName) //集群名字.put("client.transport.sniff", snf)//增加嗅探机制,找到ES集群.put("thread_pool.search.size", Integer.parseInt(poolSize))//增加线程池个数,暂时设为5.build();//配置信息Settings自定义transportClient = new PreBuiltTransportClient(esSetting);TransportAddress transportAddress = new TransportAddress(InetAddress.getByName(clusterNode), Integer.valueOf(clusterPort));transportClient.addTransportAddresses(transportAddress);} catch (Exception e) {e.printStackTrace();System.out.println("elasticsearch TransportClient create error!!");}System.out.println("es客户端创建成功");return transportClient;}public static String scrollId = "";/*** 第一次查询的方式* @param client* @return*/private Map<String,Object> my(TransportClient client){BoolQueryBuilder mustQuery = QueryBuilders.boolQuery();//设置查询条件mustQuery.must(QueryBuilders.matchQuery("sex","男"));mustQuery.must(QueryBuilders.matchQuery("city","杭州市"));SearchResponse rep = client.prepareSearch().setIndices(index) // 索引.setTypes(type) //类型.setQuery(mustQuery).setScroll(TimeValue.timeValueMinutes(2)) //设置游标有效期.setSize(100) //每页的大小.execute().actionGet();Map<String,Object> m = new HashMap<String,Object>();m.put("scrollId",rep.getScrollId());//获取返回的 游标值m.put("id", (rep.getHits().getHits())[0].getId());return m;}private Map<String,Object> my2(String scrollId,TransportClient client){SearchResponse rep1 = client.prepareSearchScroll(scrollId) //设置游标.setScroll(TimeValue.timeValueMinutes(2)) //设置游标有效期.execute().actionGet();Map<String,Object> m = new HashMap<String,Object>();m.put("scrollId",rep1.getScrollId());SearchHit[] s = rep1.getHits().getHits();if(s == null || s.length == 0){return null;}m.put("id", (rep1.getHits().getHits())[0].getId());return m;}public static void main(String[] args) {TestEs t = new TestEs();TransportClient client = t.transportClient();Map<String,Object> m1 = t.my(client);System.out.println("first:"+m1.get("id"));String s = m1.get("scrollId").toString();System.out.println("first:"+s);int i = 0;while (true){i++;Map<String,Object> m2 = t.my2(s,client);// 查询不到数据了,就表示查询完了if(m2 == null){break;}System.out.println("insert to mysql");}System.out.println("总次数:"+i);System.out.println("end");}}

若有收获,就点个赞吧
0 人点赞
