0x01:什么是匿名函数?
用lambda关键词能创建小型匿名函数。这种函数得名于省略了用def声明函数的标准步骤。
lambda 是Python 的一个关键字,用于声明一个匿名函数
匿名函数的难点不在于构建,而在于组合使用的一个难度
除了使用def 关键字定义一个函数以外,我们还能使用 lambda 表达式定义一个函数
匿名函数, 用来表达一个简单的函数,函数的调用次数很少,基本上就是调用一次
调用匿名函数的两种方式:
1. 给它定义一个名字,很少使用
mul = lambda a,b: a + b
print(mul(4,5))
2. 把这个函数当作参数传给另一个函数使用,使用场景比较多
def calc(a,b,fn):c = fn(a,b)return cx1 = calc(5,7,lambda x,y: x+y) # 给lambda 起了一个别名,然后再调用 lambda函数x2 = calc(12,7,lambda x,y: x-y)
0x02:常规函数和 匿名函数的区别
| 命名 | 必须 | 无需 |
|---|---|---|
| 多参数 | 支持 | 支持 |
| 功能 | 复杂/ 多行 | 简单 / 单行 / 表达式 |
| 作为参数传递 | 支持 | 支持 |
0x03:lambda 的语法格式
lambda函数的语法只包含一个语句,如下:
lambda 参数列表: 运算表达式
如下实例:
sum = lambda arg1, arg2: arg1 + arg2
# 调用sum函数
print("Value of total : %d" % sum( 10, 20 ))
print("Value of total : %d" % sum( 20, 20 ))
以上实例输出结果:
Value of total : 30
Value of total : 40
Lambda函数能接收任何数量的参数但只能返回一个表达式的值
匿名函数可以执行任意表达式(甚至print函数),但是一般认为表达式应该有一个计算结果供返回使用。
python在编写一些执行脚本的时候可以使用lambda,这样可以接受定义函数的过程,比如写一个简单的脚本管理服务器。
函数作为参数传递
>>> def fun(a, b, opt):
... print("a = " % a)
... print("b = " % b)
... print("result =" % opt(a, b))
...
>>> add = lambda x,y:x+y
>>> fun(1, 2, add) # 把 add 作为实参传递
a = 1
b = 2
result = 3
0x04: lambda函数的四兄弟
| 函数名或类名 | 功能 | 参数描述 |
|---|---|---|
| sorted函数 | 用来将一个无序列表进行排序 | 函数参数的返回值规定按照元素的哪个属性进行排序 |
| filter类 | 用来过滤一个列表里符合规定的所有元素,得到的结果是一个迭代器 | 函数参数的返回值指定元素满足的过滤条件 |
| map类 | 将列表里的每一项数据都执行相同的操作,得到的结果是一个迭代器 | 函数参数用来指定列表里元素所执行的操作 |
| reduce函数 | 对一个序列进行压缩运算,得到一个值。python3以后,这个方法被移到了functools模块 | 函数参数用来指定元素按照哪种方式合并 |
(1) sorted 函数:
sorted 内置函数,不会改变原有的数据,而是生成一个新的有序的列表。
字典和字典之间不能使用比较运算符
使用sort 方法进行排序**
def foo(ele):
print(ele)
return ele['age']
students = [
{'name':'lala','age':20,'score':98,'height':180},
{'name': 'haha', 'age': 18, 'score': 92, 'height': 170},
{'name': 'heihei', 'age': 30, 'score': 60, 'height': 165},
{'name': 'll', 'age': 25, 'score': 78, 'height': 150}
]
# 在sort函数内部实现的时候,调用了foo方法,并且传入了一个参数,参数就是列表里的元素
students.sort(key=foo)
# 使用lambda匿名函数进行sort 排序
students.sort(key=lambda ele: ele['height'])
print(students)
sorted(iterable,key=None,reverse=False)
* iterable 可迭代的数据类型,list列表、dict字典
* key 默认参数,默认值为None
* reverse 默认参数,默认值为False

students = [
{'name':'lala','age':20,'score':98,'height':180},
{'name': 'haha', 'age': 18, 'score': 92, 'height': 170},
{'name': 'heihei', 'age': 30, 'score': 60, 'height': 165},
{'name': 'll', 'age': 25, 'score': 78, 'height': 150}
]
x = sorted(students,key=lambda d:d['age'],reverse=False)
print(x)
test = [[3,4,1],[3,3,3],[1,2,4],[9,1,0],[7,3,2]]
# 使用列表内得列表中得第一个元素进行升序排序
asc_test = sorted(test,key=lambda d:d[0],reverse=False)
print(asc_test)
# 增加一个条件,第一个元素排列完成,在用第二个元素排列
adc_test = sorted(test,key=lambda d:(d[0],d[1]),reverse=False)
(2) filter 函数:
filter 内置类的使用python2的时候是内置函数,python3修改成了一个内置类filter 可以给定两个参数,第一个参数是函数,第二个参数是可迭代对象
filter 对可迭代对象进行过滤,得到的是一个 filter 对象, 也是一个可以迭代的对象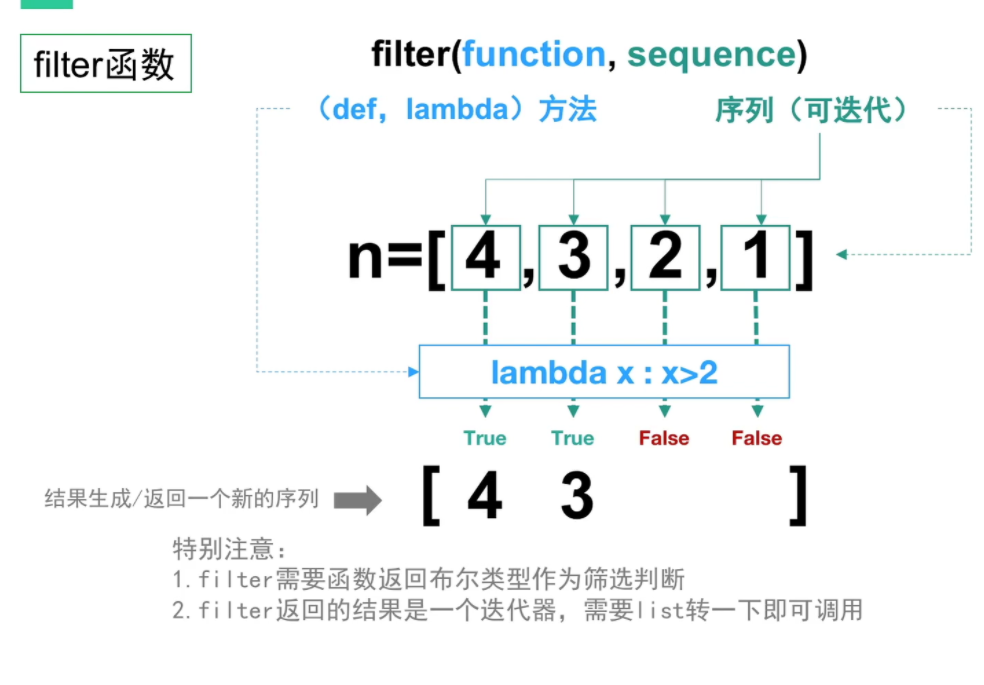
filter(function,sequence)
ages = [12,23,30,17,16,22,18]
x = filter(lambda ele: ele > 18, ages)
print(x)
for a in x:
print(a)
(3) map 函数:
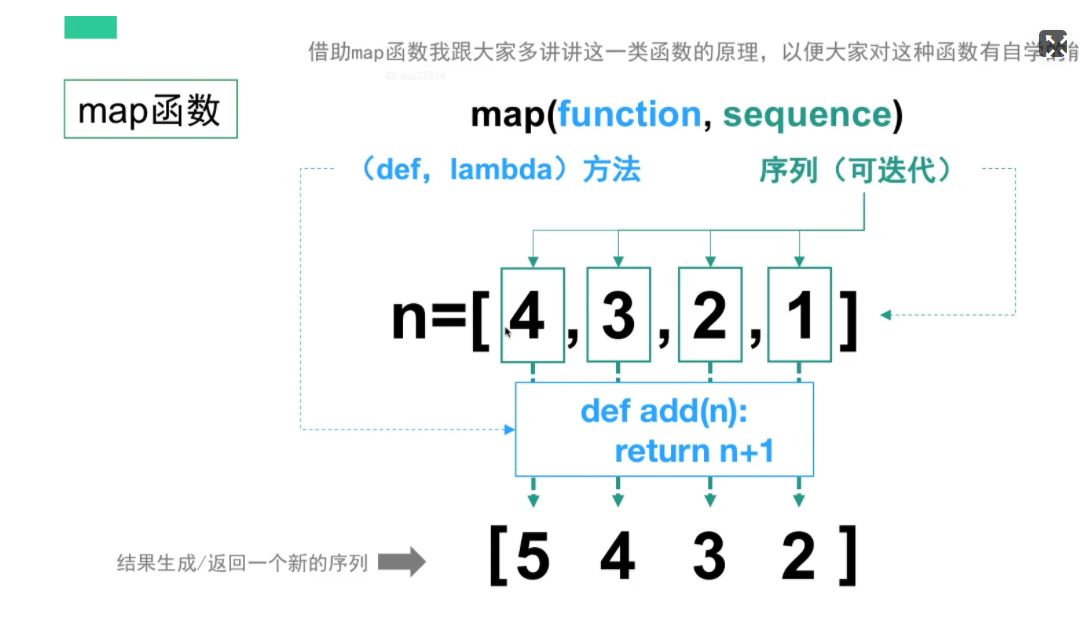
map函数的三种写法
传统的实现方式
data = [1,2,3,4]
new_l = []
for i in dada:
new_l.append(i+1)
传统函数+map
data = [1,2,3,4]
def func(n):
return n + 1
new_l = map(func,data)
new_l = list(new_l)
lambda+map
data = [1,2,3,4]
new_l = list(map(lambda n : n+1,data))
(4) reduce 函数

reduce 以前是一个内置函数,内置函数和内置类都要在 builtins.py 文件里,,现在使用需要调用模块
from functools import reduce
socres = [100,89,76,87]
def foo(x,y):
return x + y # x= 100 ,y=89; x = 189,y=76; x = 265, y=87
print(reduce(foo,scores))
print(reduce(lambda ele1, ele2: ele1 + ele2, socres))
计算总成绩
from functools import reduce
students = [
{'name':'lala','age':20,'score':98,'height':180},
{'name': 'haha', 'age': 18, 'score': 92, 'height': 170},
{'name': 'heihei', 'age': 30, 'score': 60, 'height': 165},
{'name': 'll', 'age': 25, 'score': 78, 'height': 150}
]
print(reduce(lambda ele1, ele2: ele1 + ele2['age'], students, 0)) ,此处的0代表x的初始的值

若有收获,就点个赞吧
0 人点赞
