参考书: 算法(第四版)
优秀的算法因为能解决实际问题而变得尤为重要
高效算法的代码也可以很简单
理解某个实现的性能特点是一项有趣而令人满足的挑战
在解决同一个问题的多种算法之间进行选择时,科学方法时一种重要的工具
- 迭代式改进能让算法的效率越来越高
4 数据压缩
4.1 原因
主要是节省空间以及减少传输的时间
4.2 热身:基因组

一般而言,生物学家用字母A,C,G,T表示生物体DNA中的碱基。
但是上面这一串字符串一共有35个,每一个字符使用ASCII编码的话(8位),那么一共就是8*35 = 280位
4.2.1 压缩
不难看出,DNA碱基的字符串一共只有4个字符来组成,那么我们可以使用2位比特编码方式(种)
4.3 游程编码【Run-Length Encoding】
比特流中最常见的就是一长串重复的比特
游程编码的一个应用就是位图:

4.4 哈夫曼压缩
主要思想:
放弃文本保存的普通方式,用更短的比特保存出现频率较高的字符,用较多的比特保存出现频率较低的字符
简而言之,利用频率信息压缩数据

4.4.1 寻找最优前缀码

在这里插入图片描述
能否找到使得比特流最小的单词查找树?
——————哈夫曼编码
使用前缀码进行数据压缩需要进行五个步骤:
- 构造一棵编码单词查找树
- 将该树以字节流的形式写入输出,以便展开时使用
- 使用该树,将字节流编码为比特流
在展开时需要:
- 读取单词查找树(保存在比特流的开头)
- 使用该树将比特流解码
下面将按照难度逐步考察
4.4.2 单词查找树的节点

其中还有两个新的变量:
- ch————表示叶子节点上的字符
- freq————叶子节点:当前字符在输入中出现频率;内部节点:两个子节点频率之和;根节点的频率 = 字符的数量
4.4.3 展开
展开的过程十分简单:从根节点开始移动,读到0——左移,1——右移
如果到达了叶子节点x,直接输出x.ch
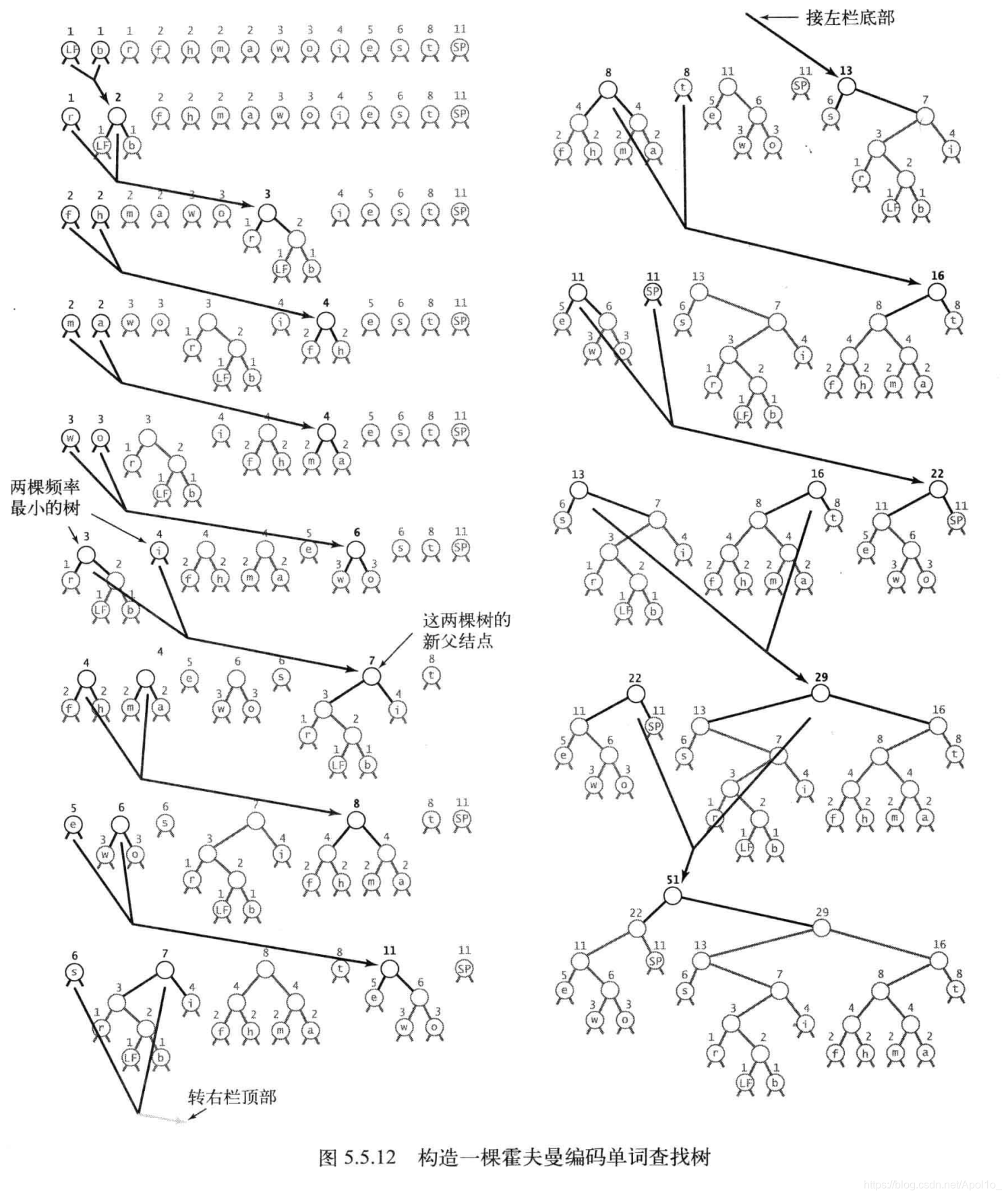
4.4.4 单词查找树的构造
以下面的输入为例观察一棵单词查找树的构造过程:
it was the best of times it was the worst of times
首先,我们需要将需要编码的字符都放置于叶子节点,并记录每个字符在原文中出现的频率
在本例中,有8个t,5个e,11个空格等
【注】:
需要得到这些频率,需要扫描一遍输入流————哈夫曼编码是一个两轮算法,需要预先读取输入流后再压缩
接下来,将按照频率大小构造这个单词查找树
构造过程如下:
- 首先找到两个频率最小的节点,创建一个以两者作为子节点的新节点(新节点的频率 = 两子节点之和)
- 这个操作,会使森林中的树的数量-1
- 然后不断重复这个过程
问题来了,如何才能知道频率最小的节点呢?————优先队列
按照这样一个过程构造的单词查找树最终一定是:
- 频率较低的节点被安排在底层
- 频率较高的节点被安排在靠近根节点的位置
/**构造哈夫曼编码单词查找树**/private static Node buildTree(int[] freq){//将要编码的字符插入优先队列MinPQ<Node> pq = new MinPQ<Node>();for(char = 0; c < R; c++){if(freq[c] > 0)pq.insert(new Node(c, freq[c], null, null));}//构造单词查找树while(pq.size() > 1){Node x = pq.delMin();Node y = pq.delMin();Node parent = new Node('\0', freq[x]+freq[y], x, y);pq.insert(parent);}//返回根节点return pq.delMin();}
4.4.5 构造编译表
使用递归方法构造编译表
private static String[] buildCode(Node root){String[] st = new String[R];buildCode(st, root, "");}private static String[] buileCode(String[] st, Node x, String s){if(x.isLeaf()){ //如果是叶子节点,x.ch写入编译表st[x.ch] = s;return;}buileCode(st, x.left, s+'0');buileCode(st, x.right, s+'1');}

若有收获,就点个赞吧
0 人点赞
