并查集
合并
if(find(x) != find(y))p[find(x)] = find(y);
查询操作
if (find(x) == find(y)) puts("Yes");else puts("No");
这两个操作都离不开find()
其中find使用了路径压缩的方法,每次调用find 都会把多层路径压缩成两层,因此并查集过程中可能出现三层,但是查询操作后就会压缩到两层
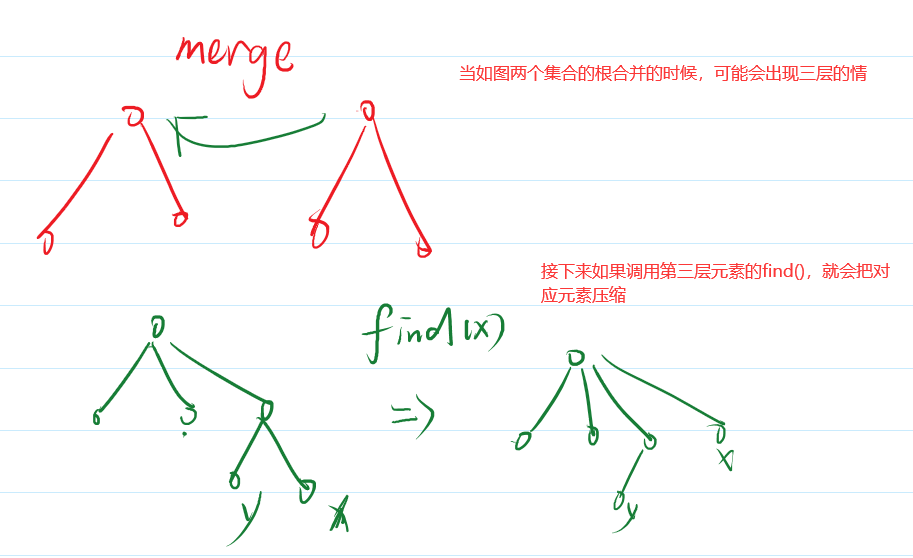
每次操作都是o(1)的
int find(int x){if(x != p[x]) p[x] = find(p[x]);return p[x];}
题目练习
「力扣」第 547 题:省份数量(中等);
「力扣」第 684 题:冗余连接(中等);
「力扣」第 1319 题:连通网络的操作次数(中等);
「力扣」第 1631 题:最小体力消耗路径(中等);
「力扣」第 959 题:由斜杠划分区域(中等);
「力扣」第 1202 题:交换字符串中的元素(中等);
「力扣」第 947 题:移除最多的同行或同列石头(中等);
「力扣」第 721 题:账户合并(中等);
「力扣」第 803 题:打砖块(困难);
「力扣」第 1579 题:保证图可完全遍历(困难);
「力扣」第 778 题:水位上升的泳池中游泳(困难)。
HashSet+剪枝 /并查集 128. 最长连续序列
思路1HashSet o(n)
我原本的想法是
使用数组排序,然后枚举每个起点,更新连续的长度。
但是这样没有考虑到重复的情况,排完序后,重复的数会影响连续的性质
因此,使用HashSet
循环数组,判断当前 数要满足是某一段连续的起点 (在hash中存在,前一个数不存在),这样相当于剪枝了)
更新连续的数的长度,并且要注意
把hash中遍历过的点都删除,这样是为了避免 : 数组中有重复元素的时,重复地从相同元素起点开始做无用遍历
class Solution {public int longestConsecutive(int[] nums) {HashSet<Integer> hash = new HashSet<Integer>();int res = 0;for (int i = 0; i < nums.length; i ++)hash.add(nums[i]);for (int i = 0; i < nums.length; i ++){if (hash.contains(nums[i]) && !hash.contains(nums[i] - 1)){hash.remove(nums[i]);int y = nums[i] + 1;while (hash.contains(y)){hash.remove(y);y++;}res = Math.max(res, y - nums[i]);}}return res;}}
思路2o(n)
使用并查集 + HashMap
HashMap key:当前数 value:当前数最远到达的数。
连续的数作为一个集合。
可以进行剪枝 + 去重
循环数组,判断当前 数要满足是某一段连续的起点 (在hash中存在,前一个数不存在),这样相当于剪枝了)
更新连续的数的长度,并且要注意
把hash中遍历过的点都删除,这样是为了避免 : 数组中有重复元素的时,重复地从相同元素起点开始做无用遍历
class Solution {HashMap<Integer, Integer> hash;public int longestConsecutive(int[] nums) {hash = new HashMap<Integer, Integer>();int n = nums.length, res = 0;for(int i = 0; i < n; i ++) hash.put(nums[i], nums[i] + 1);for (int i = 0; i < n; i ++){int x= nums[i];if (hash.containsKey(x) && !hash.containsKey(x - 1)){int y = find(x);res = Math.max(res, y - x);}}return res;}public int find(int x){if (hash.containsKey(x)){int value = hash.get(x);hash.remove(x);return find(value);}elsereturn x;}}
加入权值的并查集 399. 除法求值
思路
预处理并查集
对
equations这个数组中每个String类型的节点,我们使用HashMap指定一个唯一的id,表示该节点初始化
HashMap,把equations中每个点都加进来通过
UnionFind.union使用并查集把euqations中有比值关系的两个点都放入一个UnionFind中UnionFind.union表示把两个点加入到一个集合中
除了路径压缩的
find(),这道题并查集还需要更新对应点的weight


- 从
queries中查询,如果两个点有关系,返回对应的权值(比值);如果没有关系或者没有对应点 返回-1.0d
class Solution {public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {int equationSize = equations.size();HashMap<String, Integer> hash = new HashMap<String, Integer>();UnionFind unionFind = new UnionFind(2 * equationSize);int id = 0;for (int i = 0; i < equationSize; i ++){String a = equations.get(i).get(0), b = equations.get(i).get(1);if (!hash.containsKey(a))hash.put(a, id++);if (!hash.containsKey(b))hash.put(b, id++);//合并unionFind.union(hash.get(a), hash.get(b), values[i]);}double[] res = new double[queries.size()];//查询操作for (int i = 0; i < queries.size(); i ++){int a = hash.getOrDefault(queries.get(i).get(0), -1), b = hash.getOrDefault(queries.get(i).get(1), -1);if (a == -1 || b == -1) res[i] = -1.0;else {res[i] = unionFind.isConnected(a, b);}}return res;}//并查集class UnionFind{public int nodeSize;public double[] w;public int[] p;//初始把父节点设置为自己, 每个点到父节点的权值设置为1 表示a/a = 1public UnionFind(int nodeSize){this.nodeSize = nodeSize;this.w = new double[nodeSize];this.p = new int[nodeSize];for (int i = 0; i < nodeSize; i ++){w[i] = 1.0d;p[i] = i;}}//合并操作,更新根节点的权值public void union(int a, int b, double value){int rootA = find(a);int rootB = find(b);if (rootA != rootB){p[rootA] = rootB;w[rootA] = value * w[b] / w[a];}}//路径压缩的查询操作,更新权值public int find(int a){if (a != p[a]){int origin = p[a];p[a] = find(p[a]);w[a] *= w[origin];}return p[a];}//判断两个点是否连接,返回点之间的权值public double isConnected(int a, int b){int rootA = find(a);int rootB = find(b);if (rootA == rootB){return w[a] / w[b];}else return -1.0d;}}}
普通路径压缩547. 省份数量
思路
典型的并查集,如果城市相连,把两个城市加入一个集合中
查询操作中,如果两个城市不在一个集合中,省份数量 + 1
class Solution {
public int findCircleNum(int[][] isConnected) {
int m = isConnected.length, n = isConnected[0].length;
UnionFind unionFind = new UnionFind(n);
int proNum = 0;
for (int i = 0; i < m; i ++){
for (int j = i + 1; j < n; j ++){
if (i == j) continue;
if (isConnected[i][j] == 1)
unionFind.union(i, j);
}
}
boolean[] notProvince = new boolean[n];
for (int i = 0; i < m; i ++){
for (int j = 0; j < n; j ++){
if (i == j) continue;
if (unionFind.isUnion(i, j)) notProvince[j] = true;
}
if (!notProvince[i])
proNum++;
}
return proNum;
}
class UnionFind{
public int[] p;
public int unionSize;
UnionFind(int size){
this.unionSize = size;
p = new int[size];
for (int i = 0; i < size; i ++)
p[i] = i;
}
public int find(int a){
if (a != p[a]){
p[a] = find(p[a]);
}
return p[a];
}
public void union(int a, int b){
int rootA = find(a), rootB = find(b);
if (rootA != rootB){
p[rootA] = rootB;
}
}
public boolean isUnion(int a, int b){
return find(a) == find(b);
}
}
}
无向图转树684. 冗余连接
思路
遍历 edges,如果其中的两个点都包含在一个并查集中,说明这条边就是冗余的; 否则加入并查集中,表示两个点在一棵树中
class Solution {
public int[] findRedundantConnection(int[][] edges) {
int m = edges.length;
int[] res = new int[2];
UnionFind unionFind = new UnionFind(2 * m);
for (int i = 0; i< m; i ++){
int a = edges[i][0], b = edges[i][1];
if (unionFind.isConnected(a, b)){
res[0] = a; res[1] = b;
}
else{
unionFind.union(a, b);
}
}
return res;
}
class UnionFind{
public int[] p;
public int unionSize;
public UnionFind(int unionSize){
this.unionSize = unionSize;
p = new int[unionSize];
for (int i = 0; i < unionSize; i ++)
p[i] = i;
}
public void union(int a, int b){
int rootA = find(a), rootB = find(b);
if (rootA != rootB) p[rootA] = rootB;
}
public int find(int a){
return p[a] = p[a] != a ? find(p[a]) : p[a];
}
public boolean isConnected(int a, int b){
return find(a) == find(b);
}
}
}
获取统一集群的所有元素 + 两个HashMap映射 + 普通并查集 721. 账户合并
思路
写晕了。。。。
emailToIndex存放邮箱和index的对应
emailToName存放邮箱和账户名的对应
遍历accounts
- 将当前的 email 和 name 对应起来, email 和 idx对应起来
再遍历accounts
- 从
emailToIndex取idx,将同一个account的邮箱合并此时如果下一个account 中有和上一个相同的邮箱,那么就会这两个account的邮箱合并到一起
遍历emailToIndex.keySet()得到每个邮箱的地址
- 创建
EmailGroup - 利用email 的idx 从并查集中找到同一集群的根节点idx(作为同一集群的特征)
- 把email添加入地址列表中
- 将idx和新的地址列表存入
EmailGroup,表示同一个人的所有邮箱地址
遍历EmailGroup.values()
- 得到第一个邮箱地址,在
emailToName找到对应的账户名 - 存入最终的结果中
class Solution {
public List<List<String>> accountsMerge(List<List<String>> accounts) {
HashMap<String, Integer> emailToIndex = new HashMap<String, Integer>();
HashMap<String, String> emailToName = new HashMap<String, String>();
int idx = 0;
for (int i = 0; i < accounts.size(); i ++){
List<String> account = accounts.get(i);
String name = account.get(0);
for (int j = 1; j < account.size(); j ++){
String email = account.get(j);
if (!emailToIndex.containsKey(email))
emailToIndex.put(email, idx++);
if (!emailToName.containsKey(email))
emailToName.put(email, name);
}
}
//归并
int emailsSize = emailToIndex.size();
UnionFind unionFind = new UnionFind(emailsSize);
for (int i = 0 ; i < accounts.size(); i ++){
List<String> account = accounts.get(i);
int fEmailIdx = emailToIndex.get(account.get(1));
for (int j = 2; j < account.size(); j++){
int lEmailIdx = emailToIndex.get(account.get(j));
unionFind.union(fEmailIdx, lEmailIdx);
}
}
//存放相同集合的所有邮箱
HashMap<Integer ,List<String>> emailGroup = new HashMap<Integer ,List<String>>();
for (String email : emailToIndex.keySet()){
//利用email 的idx 从并查集中找到同一集群的根节点idx(作为同一集群的特征)
int rootIdx = unionFind.find(emailToIndex.get(email));
List<String> emails = emailGroup.getOrDefault(rootIdx, new ArrayList<String>());
//把email添加入地址列表中
emails.add(email);
//将idx和新的地址列表存入EmailGroup,表示同一个人的所有邮箱地址
emailGroup.put(rootIdx, emails);
}
//进行邮箱排序,和账户名的添加
List<List<String>> res = new ArrayList<List<String>>();
for (List<String> emails : emailGroup.values()){
Collections.sort(emails);
String email = emails.get(0);
String name = emailToName.get(email);
List<String> account = new ArrayList<String>();
account.add(name);
account.addAll(emails);
res.add(account);
}
return res;
}
class UnionFind{
public int[] p;
public int unionSize;
public UnionFind(int unionSize){
this.unionSize = unionSize;
p = new int[unionSize];
for (int i = 0; i < unionSize; i ++)
p[i] = i;
}
public void union(int a, int b){
int rootA = find(a), rootB = find(b);
if (rootA != rootB) p[rootA] = rootB;
}
public int find(int a){
return p[a] = p[a] != a ? find(p[a]) : p[a];
}
public boolean isConnected(int a, int b){
return find(a) == find(b);
}
}
}

若有收获,就点个赞吧
0 人点赞
