应用架构指南
本指南面向的是已掌握开发应用基础知识、有志于学习最佳实践和推荐架构的开发者,以满足构建满足生产质量要求的稳健应用。
本节假设您已经熟悉 Android 开发框架。如果您是刚开始学习应用开发的新手,请查阅 Android 简介 (请选择简体中文) 的训练教程专题,它覆盖了本指南的必备知识基础。
应用开发者的常见问题
和大多数情况下都只有单一入口(entry point)并以单一进程(monolithic process)运行的桌面应用不同,Android 应用有着复杂得多的结构。一个典型的 Android 应用是由多个应用组件(App components) (请选择简体中文) 构成的,即:Activity、Fragment、服务(Service)、内容提供程序(Content Provider)和广播接收器(Broadcast Receiver)。
大多数这样的应用组件是在应用清单(App manifest)中声明的,Android 操作系统将通过这份应用清单来决定如何把您的应用整合进用户的交互体验中。如前所述,桌面应用传统上都以单一进程运行,然而一个实现良好的 Android 应用需要比这还要灵活得多,以便用户在不同的应用之间交替切换流程(flow)或任务(task)。
例如,考虑当您在最喜爱的社交网络应用上分享一张照片的情境:该应用触发一个意图(Intent),Android 操作系统便启动一个相机应用来处理这个意图的请求。此时,用户已经离开社交网络应用,但其操作体验仍然是无缝衔接的;另一方面,相机应用也可能触发其他意图,例如启动文件管理器,而后者进而又可能启动其他应用,诸如此类。最终,用户回到开始的社交网络应用,并完成分享照片的流程。此外,用户也可能在这个流程中的任意时刻被一通电话打断,并在接听电话完毕之后再次回到这个照片分享的流程中。
这种应用间跳跃(app-hopping)行为在 Android 中是很常见的,因此您的应用必须正确地处理这样的流程。请务必牢记一点:由于移动设备的资源很紧张,操作系统在任何时候都可能终止一些应用进程来为新的腾出资源。
上述一切的关键在于,您的应用组件能够被独立地、乱序地启动,并且在任意时刻都能被用户或操作系统终止。由于应用组件(被创建和销毁的)的生命周期很短暂且不受您的控制,您不应该在应用组件内存储任何应用数据,并且您的应用组件不应该依赖于彼此。
常见的架构原则
既然您无法在应用组件中存储应用数据和状态,那又该怎样组织应用的架构呢?
关键中的关键是关注点分离(separation of concerns)原则。将所有代码都写在 Activity 或 Fragment 中是很常见的错误——这些类不应包含任何不处理 UI 或操作系统交互的代码,将它们保持尽可能精简有助于避免许多生命周期相关的问题。请不要忘记:您并不拥有这些类,他们只不过是将您的应用接合到操作系统的胶水类(glue class),Android 操作系统可能基于用户交互或内存不足等情况随时销毁它们。为了更可靠的交互体验,请尽量减少您的应用对于这些类的依赖。
其次重要的是,您应当从数据模型(model)驱动您的 UI,最好是持久化数据模型(persistent model),因为:1、即使操作系统终止您的应用来腾出计算资源,用户也不会丢失数据;2、即使网络没有连接或不稳定,您的应用仍能正常工作。数据模型是负责处理应用数据的组件,它们独立于视图(View)和其他应用组件,因此不受后者生命周期的问题的影响。保持 UI 代码简洁且独立于应用业务,有助于维护管理;为数据模型类清楚指定其管理数据的职责,并将您的应用基于这些类之上,有助于保证应用的可测试性和一致性。
推荐的应用架构
在这一部分,我们将通过一个用例(use-case)来向您展示如何使用架构组件来构建一个应用的架构。
注意:并不存在一个在所有情况下都是最优解的万全之策,但即便如此,本例推荐的架构在大多数情况下仍然是不错的起点。如果您已经掌握了一种开发 Android 应用的好方法,那就毋须更改。
想像这样一个场景:我们正在开发一个 UI 用来展示用户资料,数据从后端服务器的 REST API 获取。
开发交互界面
这个 UI 将包含一个 fragment 类 UserProfileFragment.java 及其布局文件 user_profile_layout.xml。为了驱动它,我们的数据模型需要包含两个数据元素:
- 用户 ID:用户的唯一识别符。最好将其通过 fragment 参数(arguments)传入 fragment,这样的话即使 Android 操作系统销毁您的进程,这个识别符也会被保存下来并在下次您的应用启动时可用。
- 用户对象:一个存储用户数据的 POJO。
我们将基于 ViewModel 创建一个 UserProfileViewModel 类来存储这个数据。
ViewModel 将数据提供给特定的 UI 组件,例如一个 fragment 或者 activity,并且处理和数据绑定的业务逻辑部分的通信,例如调用其他组件来加载数据或者转发用户的修改操作。ViewModel 并不知道视图(View)的细节,也不受配置变更(configuration changes)的影响,例如旋转屏幕导致的 activity 重建。
现在我们有了三个文件:
user_profile.xml:界面的 UI 定义。UserProfileViewModel.java:为 UI 准备数据的类。UserProfileFragment.java:展示 ViewModel 内的数据并与用户交互的 UI 控制器。
如下是初始的代码实现(布局文件略去不表):
public class UserProfileViewModel extends ViewModel {private String userId;private User user;public void init(String userId) {this.userId = userId;}public User getUser() {return user;}}
public class UserProfileFragment extends Fragment {private static final String UID_KEY = "uid";private UserProfileViewModel viewModel;@Overridepublic void onActivityCreated(@Nullable Bundle savedInstanceState) {super.onActivityCreated(savedInstanceState);String userId = getArguments().getString(UID_KEY);viewModel = ViewModelProviders.of(this).get(UserProfileViewModel.class);viewModel.init(userId);}@Overridepublic View onCreateView(LayoutInflater inflater,@Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {return inflater.inflate(R.layout.user_profile, container, false);}}
现在我们已经有了这三个代码模块,那应该如何将它们彼此联系起来呢?毕竟,当 ViewModel 的用户字段被更新时,我们需要一种通知 UI 的手段。这就是 LiveData 大显身手之处了。
LiveData 是可观察数据(observable data)的容器,它允许您应用中的组件观察 LiveData 对象的变化,而毋须创建对其的显式强依赖。LiveData 还会根据您的应用组件(如:activity、fragment、服务,等等)的生命周期状态,采取恰当的措施防止内存泄漏。
注意:如果您已经在使用 RxJava 或 Agera 等类库,那么您完全可以继续使用它们而无需换到 LiveData 上,但请务必恰当地处理生命周期:当相应的 LifecycleOwner 停止或销毁时,您的数据流也应当停止或销毁。您也可以添加
android.arch.lifecycle:reactivestreams的 artifact 依赖来和其他的响应式流(reactive streams)类库一同使用 LiveData,例如 RxJava2。
现在我们将 UserProfileViewModel 内的 User 字段换成 LiveData<User>,以便 fragment 在数据更新时收到通知。LiveData 非常暖心的一点是:它洞悉组件的生命周期,因而能在引用(references)不再有用时自动清理掉它们。
public class UserProfileViewModel extends ViewModel {...private LiveData<User> user; // private User user;public LiveData<User> getUser() {return user;}}
接着再修改 UserProfileFragment ,使其观察数据并更新 UI。
@Overridepublic void onActivityCreated(@Nullable Bundle savedInstanceState) {super.onActivityCreated(savedInstanceState);viewModel.getUser().observe(this, user -> {// 更新 UI。});}
每当用户数据被更新的时候,onChanged) 回调函数都会被触发,从而更新 UI。
您如果了解其他使用响应式回调函数的类库,也许就已经注意到了一点:我们并不是必须要重写 fragment 的onStop()) 方法来停止对数据的观察:因为 LiveData 洞悉生命周期,也就是说只要 fragment 不在一个活动的状态(收到了 onStart()) 但还没收到 onStop())),它就不会触发回调函数;当 fragment 收到onDestroy())的时候,LiveData 能够自动移除其观察者。
我们也并没有专门费心处理例如用户旋转屏幕等配置变更的情况:ViewModel 在配置变更的时候会自动恢复,因而新的 fragment 在进入生命周期的那一刻,就会收到完全相同的 ViewModel 实例,且回调函数也会被立即用最新的数据触发。——这就是 ViewModel 不应直接引用视图对象的原因:它的生命周期可以比视图对象的更长。请参阅:ViewModel 的生命周期
获取数据
现在我们已经把 ViewModel 连接到了 fragment,那么接下来又该如何让 ViewModel 获取用户数据呢?在这个例子里,假设我们有一个后端服务器来提供 REST API。我们将使用 Retrofit 这个库来连接到后端,尽管您也可以使用其他的库来完成同样的工作。
如下所示的 Retrofit Webservice 用来和后端通信:
public interface Webservice {/*** @GET 声明一个 HTTP GET 请求。* @Path("user") 该注解标于参数 userId 之上,标明该参数是 @GET 路径中 {user} 的占位符。*/@GET("/users/{user}")Call<User> getUser(@Path("user") String userId);}
关于如何实现这个 ViewModel,一个容易想到的点子可能是直接调用 Webservice 来获取数据并将其赋值给用户对象。尽管这样做也能起效,但您的应用会随着规模变大而愈发不可维护:其一,它违反了我们前面提到的 关注点分离(separation of concerns) 原则,因为ViewModel 类承担了太多责任。其二,ViewModel 的作用域是和 Activity 或 Fragment 绑定的,所以当其生命周期结束的时候所有数据都会丢失,导致很差的用户体验。考虑到这些因素,我们的 ViewModel 将把上述工作委托(delegate)给一个新的 Repository 模块。
Repository 模块负责处理数据操作:它为应用内其他模块提供一个整洁的 API,还知道从哪里调用什么 API 来获取数据。您可以把它当做不同数据源(持久数据模型、Web服务、缓存等)之间的协调者。
如下所示的 UserRepository 使用 Webservice 来获取用户数据项。
public class UserRepository {private Webservice webservice;// ...public LiveData<User> getUser(int userId) {// 这并不是最佳的实现,我们接下来就会改进它。final MutableLiveData<User> data = new MutableLiveData<>();webservice.getUser(userId).enqueue(new Callback<User>() {@Overridepublic void onResponse(Call<User> call, Response<User> response) {// 错误的情况已省略。data.setValue(response.body());}});return data;}}
尽管 repository 模块看起来并不是必需的,它却有着将数据源从应用中抽象出来的重要作用。现在我们的 ViewModel 并不知道数据是从 Webservice 获取的,也就是说我们可以在必要的时候将其替换成别的实现。
注意:为了简洁,我们将网络错误的情况省略掉了。您可以参阅下面的“附录:显示网络状态”。
管理组件间的依赖关系
上述的 UserRespository 类需要一个 Webservice 的实例来完成其工作,但如果是直接创建一个这样的实例的话,就不得不知道其依赖关系。这将使代码变得极其复杂和冗余,因为每个需要 Webservice 实例的类都需要知道如何使用其依赖关系来创建它。此外,UserRepository 也可能不是唯一需要使用 Webservice 的类,如果每个类都创建一个新的 Webservice 实例的话就会消耗太多资源。
这个问题的解决思路有两种:
- 依赖注入(Dependency Injection):依赖注入允许类定义各自的依赖关系,同时又毋须创建它们。在运行时,另一个类将负责提供这些依赖。我们推荐谷歌的 Dagger 2 库来实现 Android 应用的依赖注入,它通过遍历依赖树的方式自动构建对象,并保证依赖的编译时间。
- 服务定位(Service Locator):服务定位提供一个注册表,供类获取各自的依赖关系,同时又毋须创建它们。相对于依赖注入而言,它实现起来比较容易,因此您如果并不熟悉依赖注入,请使用服务定位。
这两种模式提供了在不造成代码冗余和复杂度的前提下管理依赖关系的清楚的范式,使您能够维护应用的规模增长。另一个主要的优点是,它们还允许您替换具体的实现用于测试。
在这个例子中,我们将使用 Dagger 2 来管理依赖关系。
将 ViewModel 连接到 repository
现在修改 UserProfileViewModel 的代码来使用 repository:
public class UserProfileViewModel extends ViewModel {private LiveData<User> user;private UserRepository userRepo;@Inject // UserRepository 参数由 Dagger 2 提供。public UserProfileViewModel(UserRepository userRepo) {this.userRepo = userRepo;}public void init(String userId) {if (this.user != null) {// ViewModel 是从每个 Fragment 新建的,// 所以我们知道 userId 是不会改变的。return;}user = userRepo.getUser(userId);}public LiveData<User> getUser() {return this.user;}}
缓存数据
上述的 repository 实现能够很好地抽象出对 Web 服务的调用,然而仍然不是非常实用,因为它只支持一个数据源。
上述 UserRepository 的实现有一个问题:它在获取到数据之后,没有把数据存放到任何地方!如果用户离开了 UserProfileFragment 之后再次回来,那么应用就得重新获取数据。这种做法导致了两个缺陷:其一,它浪费了宝贵的数据带宽;其二,在新查询执行的过程中,用户只能傻等。为了弥补上述缺陷,我们将添加一个新的数据源到我们的 UserRepository,用于将 User 对象缓存到内存中。
@Singleton // 告知 Dagger 这个类是单例。public class UserRepository {private Webservice webservice;// 缓存实现的细节已省略。private UserCache userCache;public LiveData<User> getUser(String userId) {LiveData<User> cached = userCache.get(userId);if (cached != null) {return cached;}final MutableLiveData<User> data = new MutableLiveData<>();userCache.put(userId, data);// 这仍然不是最佳的实现,但比之前好多了。// 一个完整的实现必须处理错误的情况。webservice.getUser(userId).enqueue(new Callback<User>() {@Overridepublic void onResponse(Call<User> call, Response<User> response) {data.setValue(response.body());}});return data;}}
数据持久化
在我们当前的实现中,如果用户旋转屏幕,又或者离开后返回应用,由于 repository 从内存中的缓存里获取数据,已有的 UI 将立即就绪。但如果用户离开应用后几个小时才返回,而 Android 操作系统已经杀死了该应用的进程呢?
根据现有的实现,我们得重新从网络获取数据,这不仅给用户造成了很差的体验,更是浪费了资源,毕竟同样的数据之前已经使用移动网络请求过一遍了。您当然可以通过缓存网络请求来改善这一点,可如果相同的用户数据以另一种请求的形式出现呢?比如获取一个好友列表?那么您的应用可能会显示不一致的数据,从而使用户倍感迷惑。例如,不同地方出现的相同的用户数据可能不一样,因为好友列表的请求与用户的请求有可能是在不同的时间点执行的。为了避免这种不一致,您的应用就需要将它们合并。
合适的解决思路是使用数据持久化模型,这就是 Room 库力挽狂澜之时了。
Room 是一个对象映射(object mapping)的库,用于用最少的八股代码提供数据持久化的功能。在编译时,它按照数据库的 schema 比对每一次的查询,以便让错误的 SQL 查询直接抛出编译错误,而非等到运行时才产生异常。Room 抽象并分离出部分关于原始 SQL 数据表和查询的底层实现,还允许观察数据库内数据的变化,并通过 LiveData 对象将其展现出来。此外,通过显示地定义对线程的约束条件,Room 解决了诸如在主线程上访问存储等常见的问题。
注意:如果您的应用已经使用了其他数据持久化的解决方案,例如 SQLite 对象关系映射(Object-relational mapping, ORM),那么您就不需要用 Room 来替代它们。然而,如果您在开发一个新的应用、或者重构现有的应用,我们仍然推荐您使用 Room 来持久化您应用的数据,以便利用其抽象和查询验证等功能。
为了使用 Room,我们需要定义本地的 schema。首先,用@Entity 来注解 User 类,以将其标记为您数据库中的一个表。
@Entityclass User {@PrimaryKeyprivate int id;private String name;private String lastName;// 各字段的 getter 和 setter。}
然后,创建一个继承了 RoomDatabase 的数据库类。
@Database(entities = {User.class}, version = 1)public abstract class MyDatabase extends RoomDatabase {}
注意到 MyDatabase 是抽象类。Room 将自动为其提供实现。欲了解更多细节,请参阅 Room 的文档。
现在我们需要一个将用户数据插入数据库的手段。为此,创建一个数据访问对象(data access object,DAO)。
@Daopublic interface UserDao {@Insert(onConflict = REPLACE)void save(User user);@Query("SELECT * FROM user WHERE id = :userId")LiveData<User> load(String userId);}
接着,从我们的数据库类中引用上述 DAO。
@Database(entities = {User.class}, version = 1)public abstract class MyDatabase extends RoomDatabase {public abstract UserDao userDao();}
注意到 load 方法返回一个 LiveData<User>。Room 观察并得知数据库被修改时,会自动通知所有处于活动状态的观察者。由于 Room 使用的是 LiveData ,它仅在至少有一个活动状态的观察者存在时才会更新数据,所以这个过程是高效的。
注意:Room 基于表的修改操作来检查数据是否过期,这也代表着它可能发出假阳性(false positive)的通知。
现在我们可以修改 UserRepository 来并入 Room 数据源了。
@Singletonpublic class UserRepository {private final Webservice webservice;private final UserDao userDao;private final Executor executor;@Injectpublic UserRepository(Webservice webservice, UserDao userDao, Executor executor) {this.webservice = webservice;this.userDao = userDao;this.executor = executor;}public LiveData<User> getUser(String userId) {refreshUser(userId);// 直接从数据库返回一个 LiveData。return userDao.load(userId);}private void refreshUser(final String userId) {executor.execute(() -> {// 在一个后台线程中运行,// 来检查该用户最近是否已被获取过。boolean userExists = userDao.hasUser(FRESH_TIMEOUT);if (!userExists) {// 刷新数据。Response response = webservice.getUser(userId).execute();// TODO:检查错误,等等。// LiveData 会自动更新,所以我们只需要更新数据库,其他什么都不用做。userDao.save(response.body());}});}}
请注意:即使 UserRepository 里的数据来源被更改了,我们也毋须更改 UserProfileViewModel 或者 UserProfileFragment——这就是抽象带来的灵活性。同时,这样也有利于测试,因为您可以在测试 UserProfileViewModel 时提供一个仿真的 UserRepository。
现在我们的代码已经完整了。如果用户几天后回到相同的界面,他们立刻就能看到用户信息,因为我们已将这些数据持久化过了;即使它们过期了,我们的 repository 也能自动在后台更新。当然,根据您的用例的具体情况,如果数据实在太陈旧,您也许就不展示它们了。
在一些诸如下拉刷新的用例中,当网络操作正在执行的时候,UI 应当把这种状态展示给用户。将 UI 操作和实际的数据隔离开是一件好习惯,因为后者可能会由于各种不同原因被更新,例如当我们获取好友列表时,相同的用户数据可能会被再次获取,从而触发 LiveData<User> 的更新。从 UI 的角度来看,正在执行的请求只不过是另一个数据点罢了,和其他任何数据(如 User 对象)没什么两样。
针对这种用例,一般有两种解决思路:
修改
getUser以使其返回一个包含网络状态的 LiveData。“附录:显示网络状态”中已经提供了一个实现的范例。为 repository 添加另一个公共方法用来返回刷新状态。如果您只想在显式用户操作(譬如下拉刷新)时展示网络状态,这个思路会更合适一些。
单一数据源(Single source of truth)
不同的 REST API 返回相同数据的情况并不少见,例如:如果我们的后端服务器有另一个返回好友列表的 endpoint,那么从两个不同的 API endpoint 返回就可能返回同样的用户数据对象,但数据精度也许会有差异。如果 UserRepository 要把 Webservice 收到的数据原封不动地返回,那么我们的 UI 就有呈现不一致数据的潜在风险,因为它们可能已经在这些请求执行的间隙被修改了。这就是为什么 UserRepository 的实现中,Web 服务的回调仅仅把数据存入数据库,之后这些数据库的操作才触发处于活动状态的 LiveData 对象的回调。
在这个模型中,数据库扮演了单一数据源的角色,而应用的其他部分通过 repository 来访问它。无论您使用硬盘缓存与否,我们都建议您为 repository 指定一个数据源来作为整个应用的单一数据源。
测试
我们之前提到过,关注点分离的好处之一是便于测试,接下来不妨看看应该如何测试每个模块吧。
- 用户界面和交互:这将是您唯一需要 Android UI 设备化测试的场景。测试 UI 代码的最好途径便是创建 Espresso 测试。您可以创建一个 fragment 并为其提供一个仿真(mock)的 ViewModel。既然 fragment 只和 ViewModel 交互,那么一个仿真的 ViewModel 就足够充分覆盖这部分 UI 测试了。
- ViewModel:ViewModel 可以使用 JUnit 进行单元测试,您只需要仿真
UserRepository即可。 - UserRepository:您同样可以使用 JUnit 来测试 UserRepository。您需要仿真
Webservice和数据访问对象。您可以测试它是否发起正确的 web 服务调用,是否将结果存储到了数据库中,当缓存中有最新的数据时,它是否不发起任何多余的请求。考虑到Webservice和UserDao都是接口类,您可以仿真它们,或者为更复杂的测试用例提供编造的实现。 - UserDao:测试数据访问对象的推荐做法是设备化测试。由于这些设备化测试并不需要任何 UI,它们执行起来并不费时。针对每个测试,您可以创建一个内存中的数据库,以确保这些测试不会有任何副作用(例如篡改硬盘中的数据库文件)。Room 同样支持指定不同的数据库的实现,以便您换用 SupportSQLiteOpenHelper 的 JUnit 实现来进行测试。这种方法通常是不推荐的,因为设备上运行的 SQLite 可能和您宿主机器上的 SQLite 版本不同。
- Webservice:测试应当独立于外部世界,因此您的 Webservice 应该避免对后端服务器发出真实的网络请求。有很多库都能帮助您实现这一点,例如 MockWebServer 就可以出色地帮助您创建一个仿真的本地服务器用于测试。
- 测试 Artifacts:架构组件(Architecture Components)提供了一个 Maven artifact 来控制后台线程。在
android.arch.core:core-testing这个 artifact 里有两个 JUnit 规则:InstantTaskExecutorRule:这条规则可用来强迫架构组件立即执行调用线程上的任何后台操作。CountingTaskExecutorRule:这条规则可用来在设备化测试中等待架构组件的后台操作完成,或者将其作为闲置资源连接到 Espresso。
最终架构
如下的图表展示了我们推荐的架构的所有模块及其相互连接的方式:

指导性原则
编程是充满创造力的领域,开发 Android 应用当然也不例外。无论是在多个 Activity 或 Fragment 之间通讯数据、获取远程数据并将其持久化以供离线模式使用、还是复杂应用的随便几个常见场景,解决问题的办法总有许多。
尽管下面推荐的原则并不是强制的,我们的经验已经证实了它们从长远看来有助于提升您代码库在稳健性、可测试性和可维护性。
- 您在应用清单(manifest)里定义的应用入口——Activity、服务、广播接收器,等等——并不是数据源,恰恰相反,它们应当仅仅协调处理与自己相关的部分数据。每个应用组件的生命周期很短,这取决于用户和设备的交互、运行时的整体状况,因此它们并不应该充当您的数据源。
- 在您应用的不同模块之间严格划分职责。譬如,在您的代码库中,不要把从网络加载数据的代码散布到多个类或包中。同样地,不要把不相关的职责(比如数据的缓存和数据的绑定)硬塞到同一个类中。
- 每个模块暴露出的接口越少越好。不要总想着搞一个捷径来暴露某个模块的内部实现。这样做可能使您在短期获得一点好处,但随着您代码库的增长,很快就到了偿还技术债(technical debt)的时候。
- 当您定义模块之间的交互时,请考虑到每个模块的独立测试性。例如,测试一个把数据持久化到本地数据库的模块时,如果您有一套定义明确的的从网络获取数据的 API,就能省去不少麻烦;反过来说,您要是把这两个模块的逻辑混在一起、或是把网络部分的代码分散到整个代码库中,那么测试起来必然充满了艰辛。
- 您应用的核心部分必然出类拔萃与众不同。因此,切勿浪费时间在重新创造轮子或者一遍遍写八股代码,而是应该把精力集中于如何使您的应用鹤立鸡群,并让 Android 架构组件和其他推荐的库来处理重复性八股。
- 趁着有网络连接的时候,尽可能多持久化一些相关的新鲜数据到本地,以便离线时也能派上用场。您也许时刻都有高速而稳定的网络连接,但您的用户可不一定这么幸运。
- 您的 repository 应当指定一个数据源作为单一数据源。每当您的应用需要获取某个数据的时候,这个数据都从这个单一数据源中产生。欲了解更多细节,请参阅单一数据源(Single source of truth)。
附录:显示网络状态
在上面的“推荐的应用架构”小节,为了简化范例代码,我们故意省略了网络错误和加载状态。在这个小节,我们将展示一种使用 Resource 类来封装数据及其状态,从而展示网络状态的方法。
如下是范例实现:
// 一个泛型类,用来描述一个数据及其状态。public class Resource<T> {@NonNull public final Status status;@Nullable public final T data;@Nullable public final String message;private Resource(@NonNull Status status, @Nullable T data, @Nullable String message) {this.status = status;this.data = data;this.message = message;}public static <T> Resource<T> success(@NonNull T data) {return new Resource<>(SUCCESS, data, null);}public static <T> Resource<T> error(String msg, @Nullable T data) {return new Resource<>(ERROR, data, msg);}public static <T> Resource<T> loading(@Nullable T data) {return new Resource<>(LOADING, data, null);}}
由于一个常见的用例是在从硬盘读取数据的同时从网络加载,我们将创建一个可以在不同场合复用的助手类(helper class),名为 NetworkBoundResource。 如下所示的是 NetworkBoundResource 的决策树:
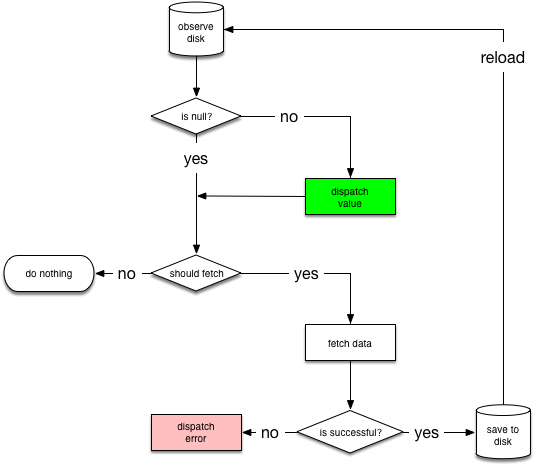
这个决策树从观察资源的数据库开始。当数据第一次从数据库读取出来的时候,NetworkBoundResource 检查该结果是否满足需求,否则需要从网络重新获取。注意这两者可能同时发生,因为您可能想要在网络请求执行的时候,先临时展示缓存的旧数据。
如果网络请求被成功执行,NetworkBoundResource 将结果存储到数据库中,并重新启动这个流程,否则直接分发失败消息。
注意:将新的数据存储到硬盘之后,我们重新启动这个流程,然而通常情况下并不需要再从数据库开始一遍,因为数据会分发变动的消息;另一方面,依赖数据库分发变动消息也有副作用:如果数据没有变动的话,流程就会中断。并且,我们也不应该分发网络获取的结果,因为这违背了单一数据源的原则(也许数据库设置有触发器,用来在数据存入数据库时对其进行修改)。此外,我们更不应该分发并未包含新数据的成功信息,因为这将把错误的信息传递给客户端。
如下所示的是 NetworkBoundResource 类提供给其子类的公共 API:
// ResultType: Resource 数据的类型// RequestType: API 结果的类型public abstract class NetworkBoundResource<ResultType, RequestType> {// 用来将 API 结果存储到数据库中@WorkerThreadprotected abstract void saveCallResult(@NonNull RequestType item);// 接收数据库中的数据,并判定其是否应当从网络重新获取@MainThreadprotected abstract boolean shouldFetch(@Nullable ResultType data);// 用来从数据库中获取已缓存的数据@NonNull @MainThreadprotected abstract LiveData<ResultType> loadFromDb();// 用来创建 API 调用@NonNull @MainThreadprotected abstract LiveData<ApiResponse<RequestType>> createCall();// 当网络请求失败时调用。// 子类可能会重置限制器等组件。@MainThreadprotected void onFetchFailed() {}// 返回一个代表 resource 的 LiveData。// 已在基类中实现。public final LiveData<Resource<ResultType>> getAsLiveData();}
请注意,上述类定义了两个参数(ResultType,RequestType) ,这是因为 API 返回的数据类型可能和本地使用的并不相同。
还请注意,上述代码使用 ApiResponse 来表示网络请求的结果。 ApiResponse 是 Retrofit2.Call 的一个简单的包装类,用于将其返回值转换成 LiveData。
如下所示的是 NetworkBoundResource 类的实现:
public abstract class NetworkBoundResource<ResultType, RequestType> {private final MediatorLiveData<Resource<ResultType>> result = new MediatorLiveData<>();@MainThreadNetworkBoundResource() {result.setValue(Resource.loading(null));LiveData<ResultType> dbSource = loadFromDb();result.addSource(dbSource, data -> {result.removeSource(dbSource);if (shouldFetch(data)) {fetchFromNetwork(dbSource);} else {result.addSource(dbSource,newData -> result.setValue(Resource.success(newData)));}});}private void fetchFromNetwork(final LiveData<ResultType> dbSource) {LiveData<ApiResponse<RequestType>> apiResponse = createCall();// 我们将 dbSource 作为新的数据源重新连接,// 它就会很快分发最新的数据。result.addSource(dbSource,newData -> result.setValue(Resource.loading(newData)));result.addSource(apiResponse, response -> {result.removeSource(apiResponse);result.removeSource(dbSource);//noinspection ConstantConditionsif (response.isSuccessful()) {saveResultAndReInit(response);} else {onFetchFailed();result.addSource(dbSource,newData -> result.setValue(Resource.error(response.errorMessage, newData)));}});}@MainThreadprivate void saveResultAndReInit(ApiResponse<RequestType> response) {new AsyncTask<Void, Void, Void>() {@Overrideprotected Void doInBackground(Void... voids) {saveCallResult(response.body);return null;}@Overrideprotected void onPostExecute(Void aVoid) {// 这里我们特意请求的是 live data,// 不这样做的话就会立即得到上一次缓存的数据,// 而这个缓存的数据可能没有用从网络获取的最新数据更新过。result.addSource(loadFromDb(),newData -> result.setValue(Resource.success(newData)));}}.execute();}public final LiveData<Resource<ResultType>> getAsLiveData() {return result;}}
现在我们就可以用这个 NetworkBoundResource 来实现 repository 中 User 数据的硬盘+网络混合加载了。
class UserRepository {Webservice webservice;UserDao userDao;public LiveData<Resource<User>> loadUser(final String userId) {return new NetworkBoundResource<User,User>() {@Overrideprotected void saveCallResult(@NonNull User item) {userDao.insert(item);}@Overrideprotected boolean shouldFetch(@Nullable User data) {return rateLimiter.canFetch(userId) && (data == null || !isFresh(data));}@NonNull @Overrideprotected LiveData<User> loadFromDb() {return userDao.load(userId);}@NonNull @Overrideprotected LiveData<ApiResponse<User>> createCall() {return webservice.getUser(userId);}}.getAsLiveData();}}

若有收获,就点个赞吧
0 人点赞
