备注:本文根据网上的一些资料,修改并整理。代码使用numpy库。
欧氏距离(Euclidean distance)
欧氏距离也叫L2范数,是最易于理解的一种距离计算方法,源自于欧氏空间中两点间的距离公式<br />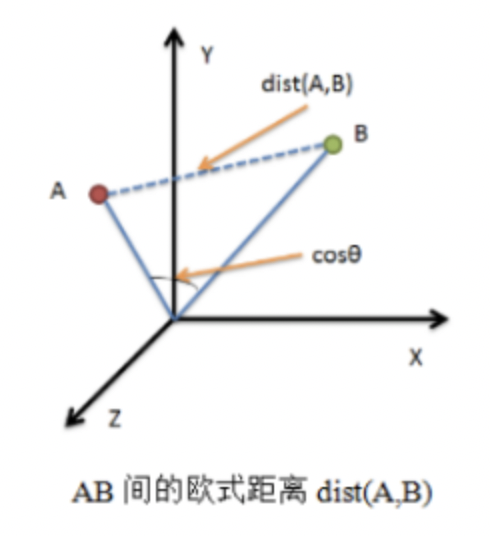
(1)二维平面上两点 与
与 间的欧氏距离:
间的欧氏距离:

(2)两个n维向量 与
与 间的欧氏距离:
间的欧氏距离:

也可以用向量表示,向量A与向量B的距离:

(3)代码实现
import numpy as npdef euclidean_distance(a, b):return np.sqrt(np.sum(np.square(a - b)))a = np.array([1, 2, 3])b = np.array([4, 5, 6])print(euclidean_distance(a, b))#输出结果5.196152422706632
曼哈顿距离(Manhattan distance)
曼哈顿距离,也叫L1范数绝对值。从名字就可以猜出这种距离的计算方法了。想象你在紧哈顿要从一个十字路口开车到另一个十字路口,驾驶距离是两点的直线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个“曼哈顿距离”。而这也是曼哈顿距离名称的由来。曼哈顿距离也称为城市街区距离(City Block distance)
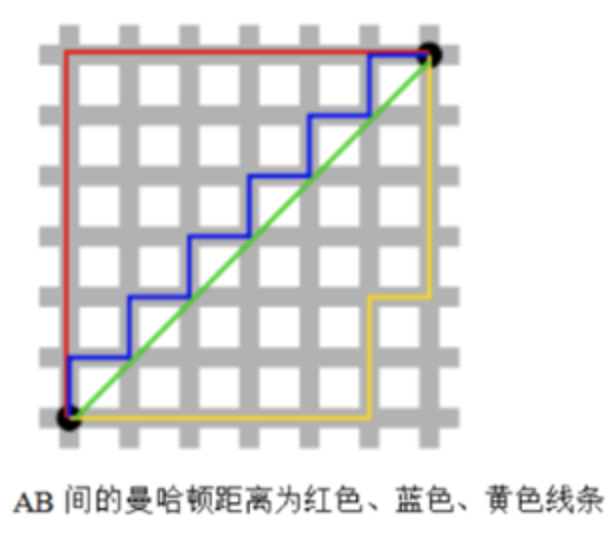
(1)二维平面两点与间的曼哈顿距离:

(2)两个n维向量与间的曼哈顿距离:

(3)代码实现
import numpy as npdef manhattan_distance(a, b):return np.sum(np.abs(a - b))a = np.array([1, 2, 3])b = np.array([4, 5, 6])print(manhattan_distance(a, b))#输出结果9.0
切比雪夫距离(Chebyshev distance)
国际象棋玩过么?国王走一步能移动到相邻的8个方格中的任意一个。那么国王从格子
 走到格子
走到格子 最少需要多少步?自己走走试试。你会发现最少步数总是
最少需要多少步?自己走走试试。你会发现最少步数总是 步。有一种类似的一种距离度量方法叫切比雪夫距离。如下图棋盘,每个格子里的值为到f6格子的切比雪夫距离:
步。有一种类似的一种距离度量方法叫切比雪夫距离。如下图棋盘,每个格子里的值为到f6格子的切比雪夫距离:
(1)二维平面两点与间的切比雪夫距离:
(2)两个n维向量与间的切比雪夫距离:
(3)代码实现
import numpy as npdef chebyshev_distance(a, b):return np.max(np.abs(a - b))a = np.array([1, 2, 3])b = np.array([4, 5, 6])print(chebyshev_distance(a, b))#输出结果3
闵可夫斯基距离(Minkowski distance)
闵氏距离不是一种距离,而是一组距离的定义。
(1)闵氏距离的定义
两个n维向量与间的闵可夫斯基距离定义为:

其中p是一个变参数。
当 时,就是曼哈顿距离
时,就是曼哈顿距离
当 时,就是欧氏距离
时,就是欧氏距离
当 时,就是切比雪夫距离
时,就是切比雪夫距离
根据参数的不同,闵氏距离可以表示一类的距离
(2)闵氏距离的缺点
闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在显示的缺点。
举个例子:二维样本(身高,体重)。其中身高范围是150~190,体重范围是50~60,有三个样本: 。那么a与b之间的闵氏距离(无论是曼哈顿距离、欧氏距离和切比雪夫距离)等于a与c之间的距离,但是身高的10cm真的等价于体重的10kg吗?因此用闵氏距离来衡量这些样本间的相似度很有问题。
。那么a与b之间的闵氏距离(无论是曼哈顿距离、欧氏距离和切比雪夫距离)等于a与c之间的距离,但是身高的10cm真的等价于体重的10kg吗?因此用闵氏距离来衡量这些样本间的相似度很有问题。
简单来说,闵区距离的缺点主要有两个
- 将各个分量的量纳(scale),也就是“单位”当作相同的看待了。
- 没有考虑各个分量的分布(期望、方差等)可能是不同的。
(4)代码实现
import numpy as npdef minkowski_distance(a, b, p):return np.power(np.sum(np.power(np.abs(a - b), p)), 1 / p)a = np.array([1, 2, 3])b = np.array([4, 5, 6])print(minkowski_distance(a, b, 1)) #曼哈顿距离print(minkowski_distance(a, b, 2)) #欧氏距离#输出结果9.05.196152422706632
- 标准化欧氏距离(Standardized Euclidean distance)
(1)标准欧氏距离的定义
标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路是将均值标准化为0,方差标准化为1 。用公式描述为:

两个n维向量与间的标准欧氏距离为:

如果将方差的倒数看成是一个权重,这个公式可以看成一种加权欧氏距离(Weighted Euclidean distance)。
(2)代码实现
import numpy as np#对数据进行标准化def normalize(x):return (x - x.mean()) / x.std()#计算欧氏距离def euclidean_distance(a, b):return np.sqrt(np.sum(np.square(a - b)))#计算标准欧氏距离def standard_euclidean_distance(a, b):return euclidean_distance(normalize(a), normalize(b))a = np.array([1,2,3])b = np.array([4,7,9])print(standard_euclidean_distance(a, b))#计算结果0.19900852546386769
- 马氏距离(Mahalanobis distance)
(1)马氏距离定义
有M个样本向量 ,协方差矩阵记为Σ,均值记为向量μ,则其中样本向量X到μ的马氏距离表示为:
,协方差矩阵记为Σ,均值记为向量μ,则其中样本向量X到μ的马氏距离表示为:

而其中向量 之间的马氏距离定义为:
之间的马氏距离定义为:

若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则公式就成了:

就是欧氏距离了。
若协方差距阵是对角矩阵,公式变成了标准化欧氏距离。
(2)马氏距离的优缺点
量纲无关,排除变量之间的相关性的干扰。
(3)代码实现
import numpy as np#生成协方差矩阵def covariance_matrix(a, b):#两个维度的数据按列组合X = np.vstack((a, b))#计算协方差矩阵return np.cov(X.T)#计算马氏距离def mahalanobis_distance(a, b):#协方差的倒数sigma_r = np.linalg.inv(covariance_matrix(a, b))return np.sqrt(np.dot(np.dot((a - b), sigma_r), (a - b).T))a = np.array([42, 52, 48, 58])b = np.array([4, 5, 4, 3])print(mahalanobis_distance(a, b))#输出结果8.234093292719414e+16
- 余弦夹角(Cosine)
几何中余弦夹角可用来衡量两个向量方向组成的角度,机器学习中借用这一概念来衡量样本向量之间的差异。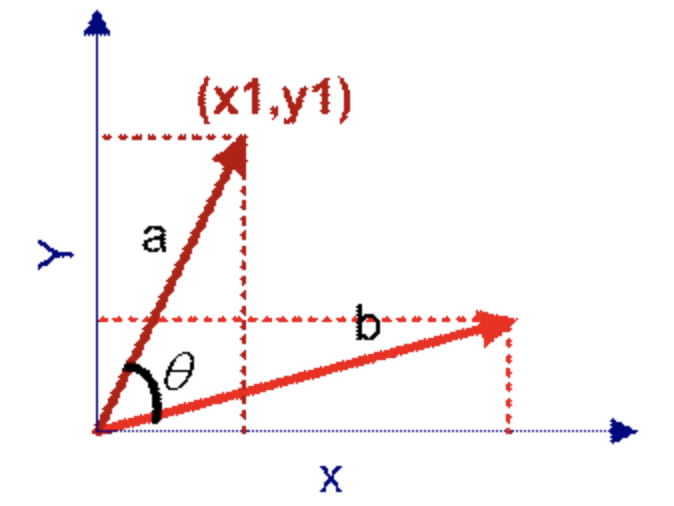
(1)在二维空间中向量 :
:
两个向量的点积公式: ,则有
,则有

其中||a||, ||b||为范数,公式为:  ,那么余弦夹角公式为:
,那么余弦夹角公式为:

(2)两个n维向量与间余弦夹角为:
余弦夹角的取值范围为[-1, 1]。余弦夹角值越大表示两个向量的夹角越小,值越小表示向量夹夹角越大。当两个向量的方向重合时值为最大值1,当两个向量的方向完全相反时,值取最小值-1。
(3)代码实现
import numpy as npdef get_cos_theta(a, b):return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))a = np.array([1, 2, 3])b = np.array([4, 5, 6])print(get_cos_theta(a, b))#输出结果0.9746318461970762
- 汉明距离(Hamming Distance)
(1)汉明距离的定义
两个等长字符串 之间的汉明距离定义为将其中一个变为另一个所需要做的最小替换次数。例如:字符串”1111”与”1001”之间的汉明距离为2。
之间的汉明距离定义为将其中一个变为另一个所需要做的最小替换次数。例如:字符串”1111”与”1001”之间的汉明距离为2。
应用:信息编码(为了增强容错性,应使得编码间的最小汉明距离尽可能大)
(2)代码实现
#计算汉明距离#如果是字符串,可以用以下方法进行计算#如果是数字的距离对比,可以先转换成二进制求异或,并统计为1的值的个数#以下函数只针对字符串进行比对def hamming_distance(a, b):len_a = len(a)len_b = len(b)if len_a != len_b:return -1distance = 0for i in range(len_a):if a[i] != b[i]:distance += 1return distancea = "this is a string"b = "this as i strong"print(hamming_distance(a, b))#输出结果3
- 杰卡德相似系数(Jaccard similarity coefficient)
(1)杰卡德相似系数
两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。
杰卡德相似系数是衡量两个集合相似度的一种指标。
(2)杰卡德距离
与杰卡德相似系数相反的概念是杰卡德距离(Jaccard distance)。杰卡德距离可用如下公式表示:
杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
(3)杰卡德相似系数与杰卡德距离的应用
可将杰卡德相似系数用在衡量样本的相似度上。
样本A与样本B是两个n维向量,而且所有维度的取值都是0或1.例如:A(0111)和B(1011)。我们将样本看成是一个集合,1表示集合包含该元素,0表示集合不包含该元素。 :样本A与B都是1的维度的个数
:样本A与B都是1的维度的个数 :样本A是1,样本B是0的维度的个数
:样本A是1,样本B是0的维度的个数 :样本A是0,样本B是1的维度的个数
:样本A是0,样本B是1的维度的个数 :样本A与B都是0的维度的个数
:样本A与B都是0的维度的个数
那么样本A与样本B的杰卡德相似系数可以表示为:

杰卡德向相似距离可以表示为:
(4)代码实现
import numpy as npdef jaccard_distance(a, b):#intersect1d会做set+intersect+排序操作intersect_num = len(np.intersect1d(a, b))union_num = len(np.union1d(a, b))return (union_num - intersect_num) / union_numa = np.array([[2, 4, 5, 8, 8, 4]])b = np.array([3, 5, 7, 9, 2])print(jaccard_distance(a, b))#输出结果0.7142857142857143
- 相关距离(Corrlelation distance)
(1)相关系数的定义
 式(1)
式(1)
 表示A与B的协方差
表示A与B的协方差
 表示A的方差
表示A的方差
 表示B的方差
表示B的方差
(2)相关距离的定义
(3)代码实现
import numpy as np#计算相关距离-方法1#为了便于理解相关系数的计算,我们使用式(1)的公式def corrlelation_distance_1(a, b):r_value = np.mean((x - x.mean()) *(y-y.mean())) / (x.std() * y.std())return (1 - r_value)#计算相关距离-方法2#此方法直接使用numpy的相关系数矩阵计算方法def corrlelation_distance_2(a, b):#np.corrcoef计算出相关系数矩阵r_matrix = np.corrcoef(x,y)#为方便理解,打印相关系数矩阵,看看长啥样print(r_matrix)return (1 - r_matrix[0][1])a = np.array([1, 2, 3])b = np.array([4, 7, 9])print(corrlelation_distance_1(a, b))print(corrlelation_distance_2(a, b))#输出结果0.006600732201217263[[1. 0.99339927][0.99339927 1. ]]0.006600732201217152
- 相对熵(Relative Entropy)
关于信息熵,交叉熵,相对熵的解释可以看:如何理解交叉熵和相对熵
(1)信息熵
信息熵的公式如下:
(2)相对熵
相对熵(relative entropy)就是KL散度(Kullback–Leibler divergence),用于衡量两个概率分布之间的差异。
两个概念分布P(x)与Q(x)的相对熵的计算公式:

(3)实现代码
import numpy as npdef entropy(x):num = len(x)unique_x = np.unique(x)ent = 0.0for v in unique_x:p = float(len(x[x==v]) / num)log_p = np.log2(p)ent -= p * log_preturn ent#计算相对熵,即b与a的信息熵的差def relative_entropy(a, b):return entropy(b) - entropy(a)a = np.array(['a','b','c','a','a','b'])b = np.array(['a','c','c','a','a','b'])print(entropy(a))print(entropy(b))print(relative_entropy(a, b))#输出结果1.45914791702724481.4591479170272446-2.220446049250313e-16

若有收获,就点个赞吧
0 人点赞
