基础数据结构
String
最简单的字符串结构,一个常见的用途就是缓存用户信息(JSON)。
redis的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。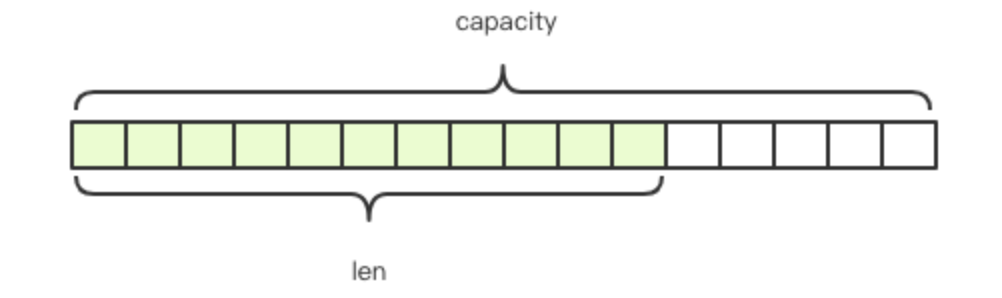
如图中所示,内部为当前字符串实际分配的空间 capacity 一般要高于实际字符串长度 len。当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是字符串最大长度为 512M。
- 计数 命令: incr
如果value是一个整数,可以进行自增操作,它的范围是singed long 的最大最小值。
list
底层结构为链表(快速链表)而不是数组,增删快O(1),查找慢O(n)。
普通链表需要的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。
- 右进左出: 队列 rpush lpop
- 右进右出: 栈 rpush rpop
- 慢操作
- lindex (慎用O(n)): 相当于java链表的get(index) 方法,需对链表进行遍历,性能随着参数index增大而变差。
- ltrim (慎用(O(n)))
hash(字典)
set(集合)
无序,唯一
应用场景: 存储活动中奖的用户id。zset(有序集合)
有序,唯一,类似于javaSortedSet和HashMap的结合体。内部实现用的是一种叫做[跳跃列表]的数据结构
场景:
存储粉丝列表,value值是粉丝的用户ID,score是关注时间。可以对粉丝列表按照关注时间进行排序。
存储学生的成绩,value是学生的ID,score是他的考试成绩。对成绩按照分数进行排序就可以得到他的名次。
特别注意的地方是如果一个字符串已经设置了过期时间,然后你调用了 set 方法修改了它,它的过期时间会消失
127.0.0.1:6379> set codehole yoyoOK127.0.0.1:6379> expire codehole 600(integer) 1127.0.0.1:6379> ttl codehole(integer) 597127.0.0.1:6379> set codehole yoyoOK127.0.0.1:6379> ttl codehole(integer) -1
高级的数据结构有4种
HyperLogLog: 通常用于基数统计。使用少量固定大小内存,来统计集合中唯一元素的数量。统计结果不是精确值,而是带有0.81%标准差的近似值。所以,HyperLogLog适用于一些对于统计结果精确度要求不是特别高的场景,例如网站的UV统计。
Geo: redis3.2版本的新特性。可以将用户给定的地理位置信息存储起来,并对这些信息进行操作: 获取2个位置的距离、根据给定地理位置左表获取指定范围内的地理位置集合。
Bitmap: 位图
Stream: 主要用于消息队列,类似于kafka,可以认为是pub/subd改进版。提供了消息的持久化和主被复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
分布式锁
占坑一般是使用 setnx(set if not exists) 指令,只允许被一个客户端占坑
setnx和expire指令可以一起执行,彻底解决分布式锁的乱象
> set lock:codehole true ex 5nx> del lock:codehole
可重入性
可重入性是指线程在持有锁的情况下再次请求加锁,如果一个锁支持同一个线程的多次加锁,那么这个锁就是可重入的。
面试题
redis是单线程的还是多线程
redis 4.0之前是完全单线程的
redis 4.0,引入了多线程,但额外的线程只是用于后台处理,例如删除对象,核心流程还是完全单线程的
redis 6.0又一次引入了多线程概念,这次的多线程会涉及到核心流程: 接受命令,解析命令,执行命令,返回结果。这次的多线程主要用于网络I/O阶段,也就是接收命令和写回结果阶段,而在执行命令阶段,还是由单线程串行执行,因此执行时无需考虑并发安全问题。
redis为什么使用单进程、单线程也很快
1) 基于内存的操作
2) 使用了I/O多路复用模型,select、epoll等,基于reactor模式开发了自己的网络事件处理器
3) 单线程可以避免不必要的上下文切换和竞争条件,减少了这方面的性能消耗
4) 以上三点是redis性能搞的主要原因,其他的还有一些小优化,例如: 对数据结构进行了优化,简单的动态字符串,压缩列表等。
项目中使用的redis版本
redis在项目中的使用场景
缓存,分布式锁,排行榜(zset),计数(incrby),消息队列(stream)、地理位置(geo)、访客统计(hyperloglog)等。
Sorted Set底层数据结构
Sorted Set(有序集合)当前有两种编码: ziplist、skiplist
ziplist: 使用压缩列表实现,当保存的元素长度都小于64字节,同时数量小于128时,使用该编码方式,否则会使用skiplist。这两个参数可以通过 zset-max-ziplist-entries、zset-max-ziplist-value 来自定义修改。
skiplist: zset实现,一个zset同时包含一个字典(dict)和一个跳跃表(zskiplist)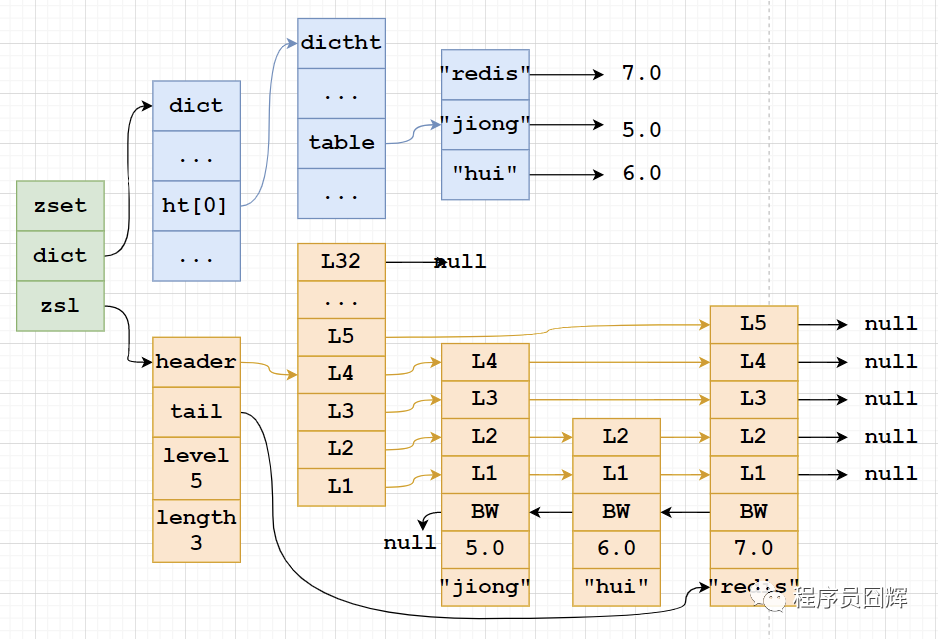
Sorted Set为什么同时使用字典和跳跃表?
主要是为了性能
单独使用字典: 在执行范围型操作,比如zrank,zrange,字典需要进行排序,至少需要O(NlogN)的时间复杂度及额外O(N)的内存空间。
单独使用跳跃表:根据成员查找分支操作的复杂度从O(1)上升为O(logN)。
Sorted Set为什么使用跳跃表,而不是红黑树?
Hash对象底层结构
Hash对象当前有两种编码: ziplist,hashtable
ziplist:使用压缩列表实现,每当有新的键值对要加入到哈希对象时,程序会先将保存了键的节点推入到压缩表的表尾,然后再将保存了值的节点推入到压缩列表表尾。 因此 1.保存了统一舰队之的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后; 2. 先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加的会被放在表尾方向。
todo
redis的set name value,name设置过期时间,如果再次set name value,过期时间会失效

若有收获,就点个赞吧
0 人点赞
