关于xss里编码绕过,这个我一直不太清楚,虽然我总结了,但是我不喜欢xss。所以也没有记住。但是还是把别人写好的总结的放上来。
首先声明这篇文章主要是摘抄自这几位兄台
https://www.cnblogs.com/yunen/p/13561433.html
http://bobao.360.cn/learning/detail/292.html
1|_0_0x00 前言
之前在学习XSS的时候总感觉不是很系统,许多技巧背后原理都没有理解,光是会用罢了,如部分绕过编码技巧。
今天打算花时间来补补基础。
2|_0_0x00 基础知识
2|_1_HTML基础
常见的字符实体
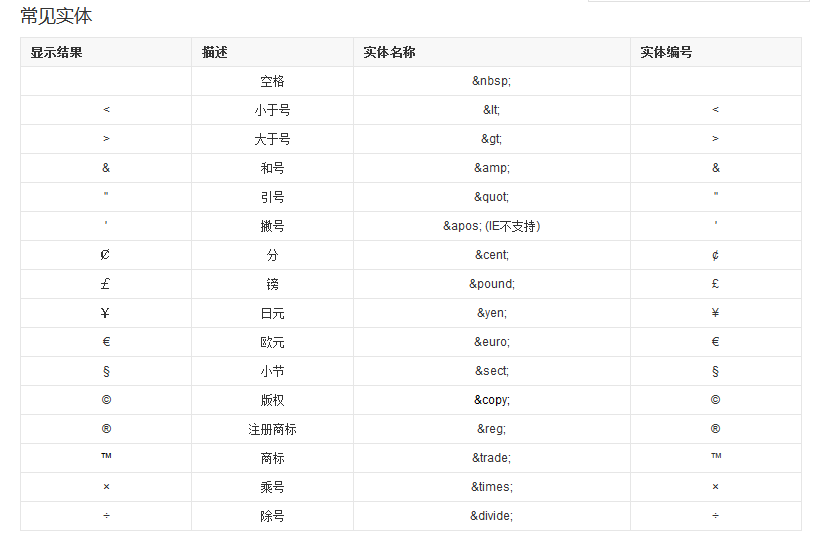
部分具有特定名称的字符实体
而对于其他没有特定名称的实体来说:
- 十进制:对应符号的Ascii的值前加上&#,后以;结尾
- 十六进制:对应符号的Ascii的值换算成16进制前加上&#x,后以;结尾
注意:字符实体解码后得到的值为字符串型,HTML解析器只将其当做字符串文本处理。
HTML元素
共有5种元素:空元素、原始文本元素、RCDATA元素、外来元素以及常规元素。
- 空元素:area、base、br、col、command、embed、hr、img、input、keygen、link、meta、param、source、track、wbr
- 原始文本元素:script、style
- RCDATA元素:textarea、title
- 外来元素:来自MathML命名空间和SVG命名空间的元素。
- 常规元素:其他HTML允许的元素都称为常规元素。
原始文本、RCDATA以及常规元素都有一个开始标签来表示开始,一个结束标签来表示结束。某些元素的开始和结束标签是可以省略的,如果规定标签不能被省略,那么就绝对不能省略它。空元素只有一个开始标签,且不能为空元素设置结束标签。外来元素可以有一个开始标签和配对的结束标签,或者只有一个自闭合的开始标签,且后者情况下该元素不能有结束标签。
元素内容限制
空元素不能有任何内容(因为空元素没有结束标签,自然没办法在开始标签和结束标签之间放内容)。
原始文本元素只可以包含文本
RCDATA元素可以包含文本和字符引用,但是文本中不能包含意义不明的符号。
对于外来元素,当开始标签自闭合时,不能包含任何内容(因为没有结束标签,所以不能在开始标签和结束标签之间放内容)。当开始标签不自闭合时,其内容可以包含文本、字符引用、CDATA块、其他元素和注释,但是文本不能包含编码为U+003C的小于符号(<)或者意义不明的符号。
2|2浏览器显示页面流程:
先逐行加载页面,并将引用的外部文件下载下来->接着逐行解析页面,解析一部分后会将已解析的部分进行渲染,实现边解析边渲染。
2|3浏览器解析机制
一个HTML解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时候它只要遇到一个’<’符号(后面没有跟’/‘符号)就会进入”标签开始状态(Tag open state)”。然后转变到”标签名状态(Tag name state)”,”前属性名状态(before attribute name state)”……最后进入”数据状态(Data state)” 并释放当前标签的token。当解析器处于”数据状态(Data state)”时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
引自:深入理解浏览器解析机制和XSS向量编码
1.标签a解析例子
1)起始标签a
范围:
DataState:碰到<,进入TagOpenState状态
TagOpenState:碰到a,进入TagNameState状态(HTMLToken的type为StartTag)
TagNameState:碰到空格,进入BeforeAttributeNameState状态(HTMLToken的m_data为a)
BeforeAttributeNameState:碰到h,进入AttributeNameState状态
AttributeNameState:碰到=,进入BeforeAttributeValueState状态(HTMLToken属性列表中加入一个属性,属性名为href)
BeforeAttributeValueState: 碰到“,进入AttributeValueDoubleQuotedState状态
AttributeValueDoubleQuotedState:碰到b,保持状态,提取属性值
AttributeValueDoubleQuotedState:碰到“,进入AfterAttributeValueQuotedState(HTMLToken当前属性的值为http://www.0x002.com).
AfterAttributeValueQuotedState: 碰到>,进入DataState,完成解析。
在完成startTag的解析的时候,会在解析器中存储与之匹配的end标签(m_appropriateEndTagName),等到解析end标签的时候,会同它进行匹配(语法解析的时候)。
html,body起始标签类似a起始标签,但没有属性解析
2)a元素内容
DataState:0x002,碰到0,维持原状态,提取元素内容(HTMLToken的type为character)。
DataState:0x002,碰到<,完成解析,不consume’<’。(HTMLToken的m_data为w3c)。
3)a结束标签
DataState:0x002,碰到<,进入TagOpenState。
TagOpenState:0x002,碰到/,进入到EndTagOpenState。(HTMLToken的type为endTag)。
EndTagOpenState:0x002,碰到a,进入到TagNameState。
TagNameState:0x002,碰到>,进入到DataState,完成解析。
这部分设计到状态机的知识,与解析原理有关。
为什么要讲这部分呢?因为他与接下来要讲的XSS载荷字符实体编码有关。
HTML解析器,部分标签在完成解析时,会按照节点类型、节点属性等生成不同的解析器去完成接下来的工作。
如a标签的href属性,HTML解析器会生成一个Url解析器去解析里边的内容。
对于

若有收获,就点个赞吧
0 人点赞
