Puppeteer 简介
Puppeteer(中文翻译“木偶”),是一个 Node 库,它提供了一个高级 API 来通过 DevTools) 协议控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行,但是可以通过修改配置文件运行“有头”模式。
高级 API
开发者工具能让我们轻松调试目标页面,这其实都是 Chrome DevTools Protocol(基于 WebSocket 协议) 的能力,同样我们可以直接操作协议来控制页面,但是代码难度很高。而 Puppeteer 则进行了更上层的封装,通过暴露的 API 同样可以控制 Chromium 或 Chrome,但代码难度大大降低。
DevTools 协议
开发工具协议,Chrome DevTools 协议允许使用工具来检测,检查,调试和分析 Chromium,Chrome 和其他基于 Blink 的浏览器。当前,许多现有项目都使用该协议。 Chrome DevTools 使用此协议,并且团队维护其 API。
仪器划分为多个域(DOM,调试器,网络等)。每个域定义了它支持的许多命令以及它生成的事件。命令和事件都是固定结构的序列化 JSON 对象。
Chromium & Chrome
Chromium 是由 Google 发起的一个开源项目(同样它也是一个浏览器),Chromium 的诞生主要是为了发展 Google Chrome 浏览器,新功能都会率先在 Chromium 上试验,验证后才会应用到 Chrome 中。由于 Chrome 是闭源的,所以国内的很多浏览器都是基于 Chromium 开源代码。
headless 模式
“无头”模式,你可以简单的理解为没有界面的模式,就是在终端跑脚本。当然你也可以通过修改文件配置运行“有头”模式。
puppeteer-core
puppeteer 是浏览器自动化的产品。在安装的同时,还是下载 Chromium,并且使用 puppeteer 驱动工作。
而 puppeteer-core 则是一个库,用来帮助驱动任何支持 DevTools 协议的程序或者应用。puppeteer-core 在安装是不会下载 Chromium 。
总结:一般情况下直接安装 puppeteer 使用,但当你正在构建 DevTools 协议顶部的另一个产品或库,那通过使用 puppeteer-core 避免下载 Chromium 来节省磁盘空间则是正确的方案。
Puppeteer 综述
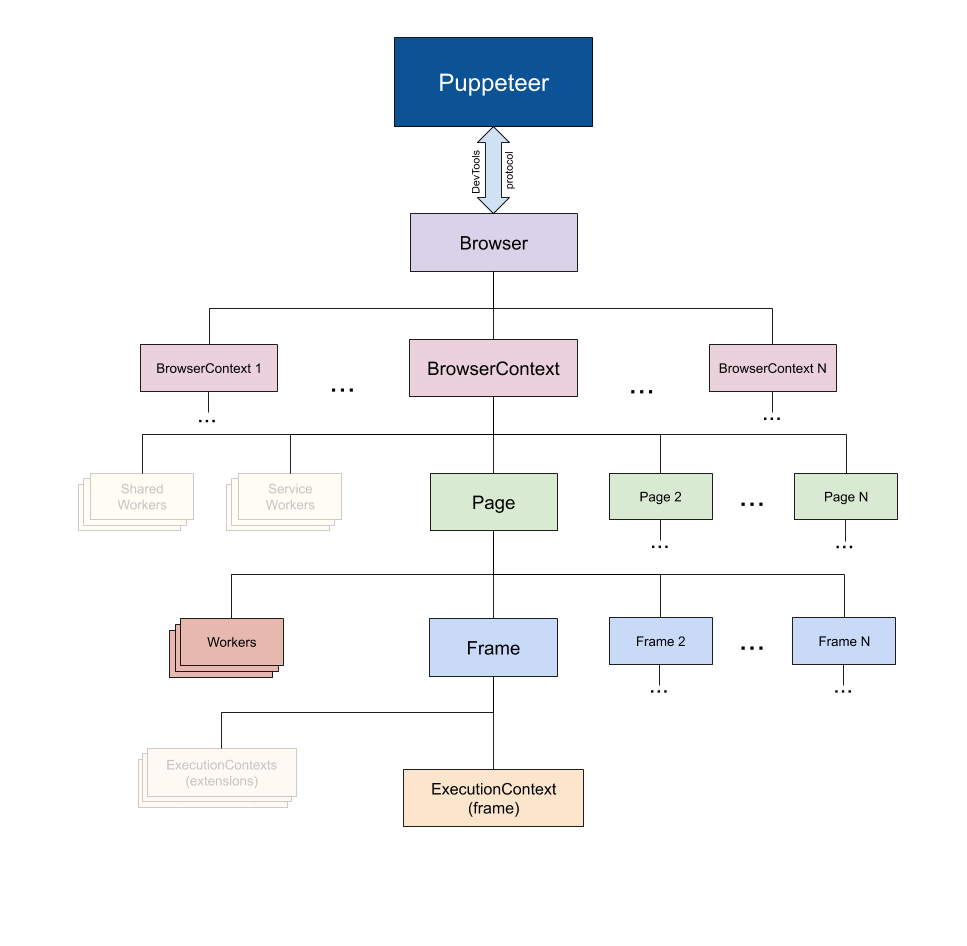
- Puppeteer 使用 DevTools 协议与浏览器进行通信。
- Browser 实例拥有浏览器上下文。
- BrowserContext 实例定义了一个浏览会话并且可拥有多个页面。
- Page 至少有一个主框架,可能还有其它框架由 iframe 或者框架标签创建。
- Frame 至少有一个执行上下文。一个框架可能有额外的与扩展关联的执行上下文。
- Worker 具有单一执行上下文,便于与WebWorks进行交互。
注意:在下面的图表中,浅色框体内容目前不在 Puppeteer 中体现。
Puppeteer 能做什么?
- 生成页面 PDF。
- 抓取 SPA(单页应用)并生成预渲染内容(即“SSR”(服务器端渲染))。
- 自动提交表单,进行 UI 测试,键盘输入等。
- 创建一个时时更新的自动化测试环境。 使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中执行测试。
- 捕获网站的 timeline trace,用来帮助分析性能问题。
- 测试浏览器扩展。
Puppeteer 安装与环境搭建
由于墙的原因,通过官方提供的安装指南可能无法顺利的完成安装,这边提供一个兜底的解决方案。
使用官方提供的环境变量来安装,忽略 Chromium 的下载。
env PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true npm i puppeteer -D
手动下载 Chromium 文件,导引地址 https://npm.taobao.org/mirrors/chromium-browser-snapshots/,根据自己的系统以及指定的 Chromium 版本进行下载,并且解压。
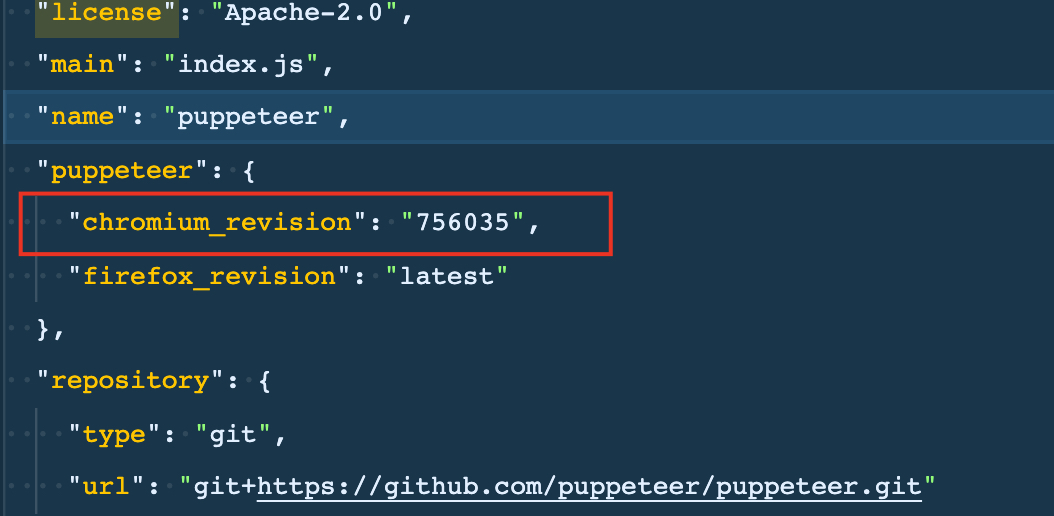
Chromium 需要选择的版本,可以到项目目录中的 node_moudules/puppeteer/package.json 文件里查看。
- 将解压好的 chrome—mac 文件放到自己的项目目录中,通过给 launch API 设置 executablePath 参数进行使用即可。 ```javascript const puppeteer = require(‘puppeteer’) const path = require(‘path’) const executablePath = path.join(__dirname, ‘../chrome-mac/Chromium.app/Contents/MacOS/Chromium’)
;(async () => { const browser = await puppeteer.launch({ executablePath, }) })()
<a name="zDvFA"></a>## 基础 Demo```javascriptconst puppeteer = require('puppeteer');(async () => {const browser = await puppeteer.launch()const page = await browser.newPage()await page.goto('https://www.baidu.com')await browser.close()})()
解读上面代码块的含义:
- 通过
puppeteer.launch创建一个浏览器实例 browser。 - 通过 browser 对象的
newPage方法创建一个页面对象 page。 - 调用 page 对象的
goto方法跳转到指定页面。 - 最后调用 browser 对象的
close方法关闭浏览器。
基础 API
- puppeteer.launch(options):用于创建一个 brower 实例
| 配置项 | 描述 | 默认值 |
|---|---|---|
| headless | 是否以 无头模式 运行浏览器 | true |
| executablePath | 可运行 Chromium 或 Chrome 可执行文件的路径,而不是绑定的 Chromium | ‘’ |
| slowMo | 将 Puppeteer 操作减少指定的毫秒数。这样你就可以看清发生了什么。 | ‘’ |
| timeout | 等待浏览器实例启动的最长时间(以毫秒为单位) | 默认是 30000 (30 秒)。通过 0 来禁用超时。 |
| devtools | 是否为每个选项卡自动打开DevTools面板 | 默认是 false。如果这个选项是 true,headless 选项将会设置成 false |
- browser.newPage():返回一个新的 Page 对象
- browser.close():关闭 Chromium 及其所有页面
- page.goto(url[, options]):页面导航到指定的地址
- page.pdf([options]):将页面保存成 pdf(目前仅支持无头模式的 Chrome)
- page.screenshot([options]):获取页面截图
- page.$(selector):获取页面指定元素。此方法在页面内执行
document.querySelector。如果没有元素匹配指定选择器,返回值是null。 - page.close([options]):关闭当前页面
进阶 Demo
ES6 入门教程内容爬取保存成 PDF
利用了 Puppeteer 的获取浏览器网页 DOM 内容以及
page.pdf能力。
const puppeteer = require('puppeteer')const { timeout, delDir } = require('../utils/tools')const path = require('path')const executablePath = require('../utils/getExecutablePath');(async () => {delDir('../pdf/es6-pdf')console.time('time')// headless: false does not support PDFs// https://github.com/puppeteer/puppeteer/issues/830const browser = await puppeteer.launch({executablePath,})let page = await browser.newPage()// Configure the navigation timeoutawait page.setDefaultNavigationTimeout(100000)await page.goto('https://es6.ruanyifeng.com/#README')// 获取「目录」 => 返回「标题 + 链接」let catalogTags = await page.evaluate(() => {let allCatalog = [...document.querySelectorAll('#sidebar ol li a')]return allCatalog.map((catalog) => {return {href: catalog.href.trim(),name: catalog.text,}})})for (let i = 0; i < catalogTags.length; i++) {page = await browser.newPage()console.log('name: ', catalogTags[i])await page.goto(catalogTags[i].href, { waitUntil: 'networkidle2' })await page.pdf({path: path.join(__dirname, `../data/pdf/es6-pdf/${catalogTags[i].name}.pdf`),format: 'A4',})await page.close()}console.timeEnd('time')browser.close()})()
自动登录
在做一些自动化测试的时候,我们需要时常需要先登录应用,Puppeteer 为我们提供了相应的 API。
// https://www.yuque.com/allenzhoujiawei/uia384const puppeteer = require('puppeteer')const executablePath = require('../utils/getExecutablePath');(async () => {console.time('time')const browser = await puppeteer.launch({executablePath,})const page = await browser.newPage()await page.goto('https://www.yuque.com/allenzhoujiawei/uia384')await page.type('input[type="tel"]', '****** your account ******')await page.type('input[type="password"]', '****** your secret ******')await page.click('.btn-login')console.timeEnd('time')})()
获取 QQ 音乐前 50 位摇滚歌手
const puppeteer = require('puppeteer-cn')const { delDir } = require('../utils/tools')const fs = require('fs')const path = require('path');(async () => {console.time('time')delDir('../data/qq-rock-music/top50-player-profile')const browser = await puppeteer.launch({headless: true})const page = await browser.newPage()await page.goto('https://y.qq.com/portal/singer_list.html#page=1&genre=2&')await page.waitFor(2000)let rockPlayers = await page.evaluate(() => {let allRockPlayerslet part_with_avatar = [...document.querySelectorAll('.js_avtar_list .singer_list__item .singer_list__title a')]let part_only_txt = [...document.querySelectorAll('.singer_list_txt .singer_list_txt__item a')]allRockPlayers = part_with_avatar.concat(part_only_txt).splice(0, 50)return allRockPlayers.map(rockPlayer => {return {title: rockPlayer.title.trim().replace(/\//g, ''),href: rockPlayer.href}})})// console.log(rockPlayers)for (let i = 0; i < rockPlayers.length; i++) {console.log(rockPlayers[i].title)await page.goto(rockPlayers[i].href)let playerDescTxt = await page.evaluate(() => {return document.querySelector('.data__cont .data__desc_txt').textContent})// console.log(playerDescTxt)// 文件流形式写入文件let writeStreamtry {writeStream = fs.createWriteStream(path.join(__dirname,`../data/qq-rock-music/top50-player-profile/${rockPlayers[i].title}-个人简介.txt`))writeStream.write(playerDescTxt, 'UTF8')writeStream.end()} catch (e) {console.log(e)}}await page.close()await browser.close()console.timeEnd('time')})()
获取指定网页的性能分析
const puppeteer = require('puppeteer-cn')/*** 网页性能分析* API:page.tracing.start* API:page.tracing.stop*/;(async () => {console.time('time')const browser = await puppeteer.launch({headless: false})const page = await browser.newPage()await page.tracing.start({path: '../data/trace/trace.json'})await page.goto('https://zjiawei.cn/')await page.tracing.stop()await page.close()await browser.close()console.timeEnd('time')})()
Puppeteer 畅想
京喜前端自动化测试之路
使用 Puppeteer 搭建统一海报渲染服务
服务端预渲染在可视化搭建业务的实践
文档与参考
Demo 案例仓库:https://github.com/AllenChinese/Puppeteer-tools
Github:https://github.com/puppeteer/puppeteer#faq
英文文档:https://pptr.dev/
中文文档:https://zhaoqize.github.io/puppeteer-api-zh_CN/
Google Chrome:https://developers.google.com/
DevTools Protocol:https://www.wangshaoxing.com/blog/2017-08-24-chrome-devtools-protocol.html

若有收获,就点个赞吧
0 人点赞
