参考文章
重点看下面第一篇文章,这三个写的都很类似
三篇文章差不多,讲了各种io的流程模型,以及最后对应到java中的nio
【1】从Linux内核理解JAVA的NIO
RocketMQ文件存储的基础:MappedFile和MappedFileQueue
当应用程序读文件的时候,数据需要从先从磁盘读取到内核空间(第一次读写,没有 page cache 缓存数据),在从内核空间 copy 到用户空间,这样应用程序才能使用读到的数据。当一个文件的全部数据都在内核的 Page Cache 上时,就不用再从磁盘读了,直接从内核空间 copy 到用户空间去了
内存映射
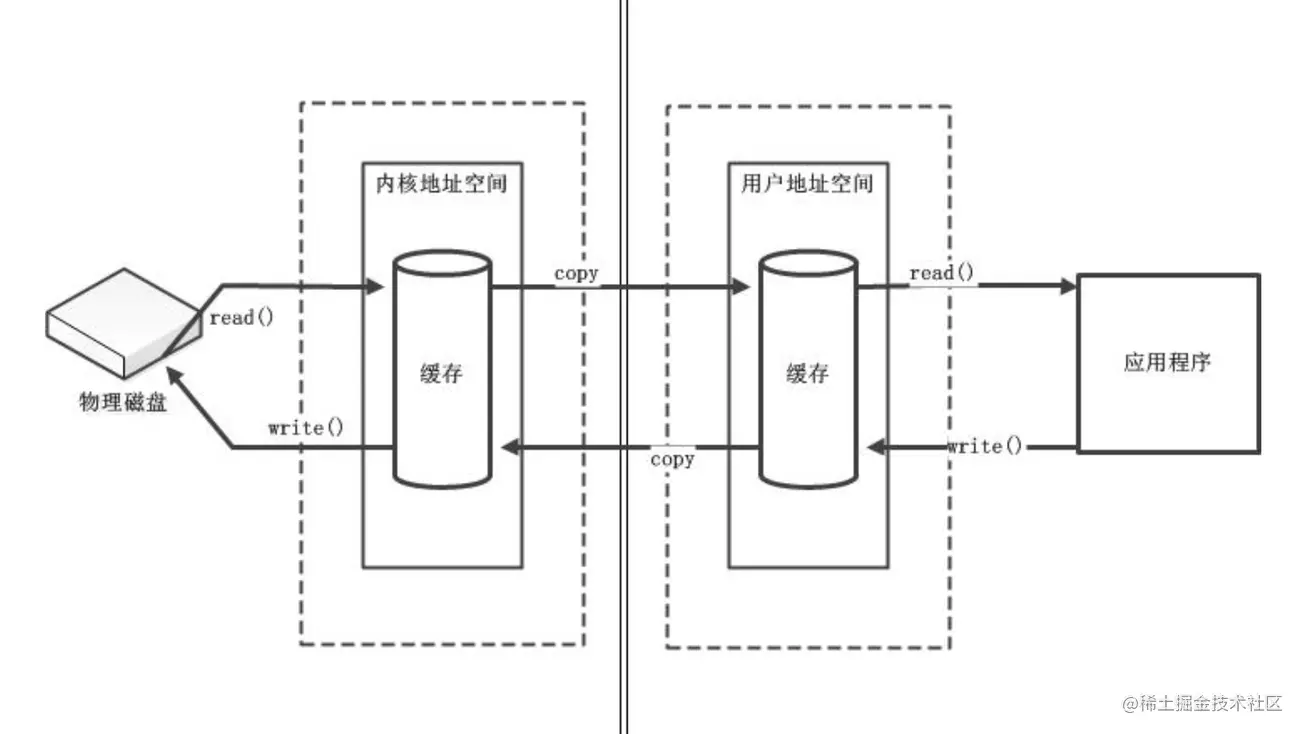
当应用程序读文件的时候,数据需要从先从磁盘读取到内核空间(第一次读写,没有 page cache 缓存数据),在从内核空间 copy 到用户空间,这样应用程序才能使用读到的数据。当一个文件的全部数据都在内核的 Page Cache 上时,就不用再从磁盘读了,直接从内核空间 copy 到用户空间去了。
应用程序对一个文件写数据时,先将要写的数据 copy 到内核 的 page cache,然后调用 fsync 将数据从内核落盘到文件上(只要调用返回成功,数据就不会丢失)。或者不调用 fsync 落盘,应用程序的数据只要写入到 内核的 pagecache 上,写入操作就算完成了,数据的落盘交由 内核 的 Io 调度程序在适当的时机来落盘(突然断电会丢数据,MySQL 这样的程序都是自己维护数据的落盘的)。
我们可以看到数据的读写总会经过从用户空间与内核空间的 copy ,如果能把这个 copy 去掉,效率就会高很多,这就是 mmap (内存映射)。将用户空间和内核空间的内存指向同一块物理内存。内存映射 英文为 Memory Mapping ,缩写 mmap。对应系统调用 mmap
这样在用户空间读写数据,实际操作的也是内核空间的,减少了数据的 copy 。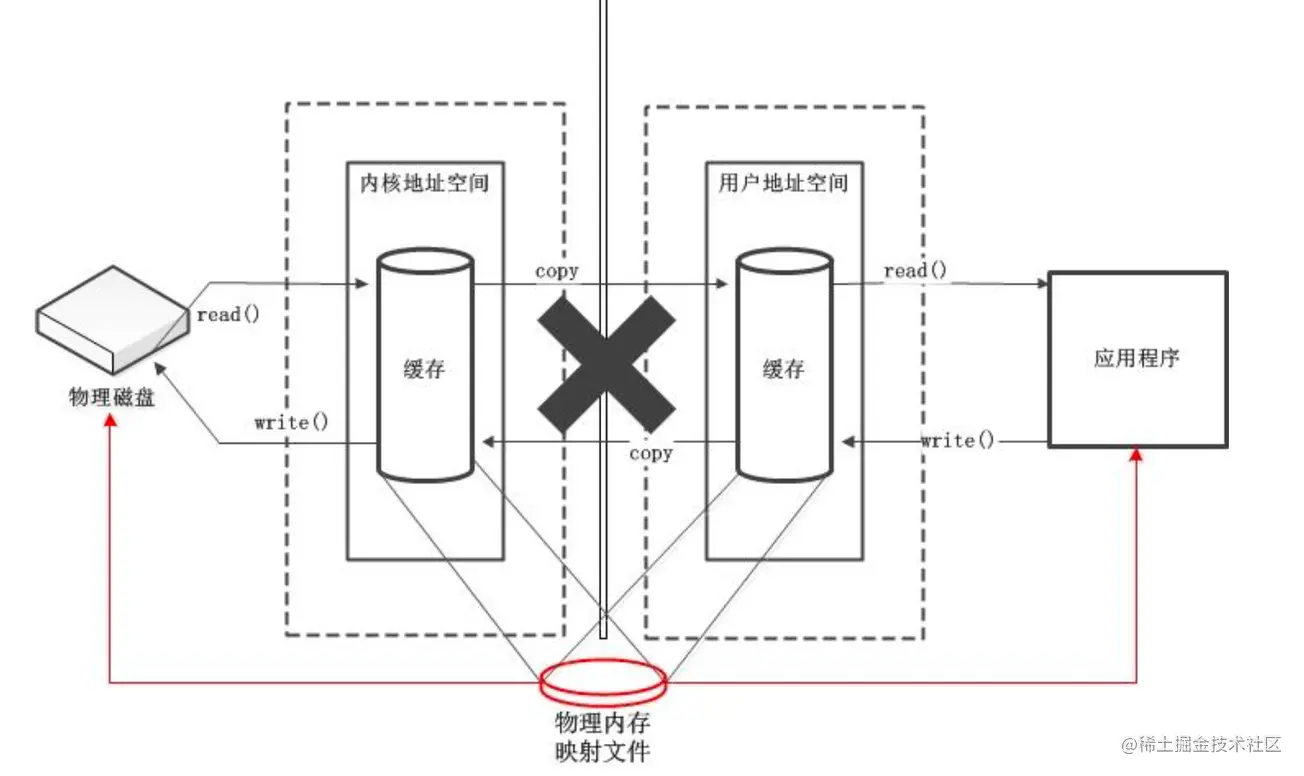
怎么实现的呢,简单来说就是 linux 中进程的地址是虚拟地址,cpu 会将虚拟地址映射到物理内存的物理地址上。mmap 实际是将用户进程的某块虚拟地址与内核空间的某块虚拟地址映射到同一块物理内存上,已达到减少数据的 copy 。
用户程序调用系统调用 mmap 之后的数据的读写都不需要调用系统调用 read 和 write 了。
虚拟内存与物理内存的映射
计算机的主存可以看做是由 M 个连续字节组成的数组,每个字节都有一个唯一物理地址 (Physical Address)。
Cpu 使用的 虚拟寻址 (VA,Virtual Address) 来查找物理地址。
CPU 会将进程使用的 虚拟地址 通过 CPU 上的硬件 内存管理单元 (Memory Management UnitMMU) 的进行地址翻译找到物理主存中的物理地址,从而获取数据。
当进程加载之后,系统会为进程分配一个虚拟地址空间,当虚拟地址空间中的某个 虚拟地址 被使用的时候,就会将其先映射到主存上的 物理地址。
当多个进程需要共享数据的时候,只需要将其虚拟地址空间中的某些虚拟地址映射相同的物理地址即可。
通常我们操作数据的时候,不会一个字节一个字节的操作,这样效率太低,通常都是连续访问某些字节。所以在内存管理的时候,将内存空间分割为页来管理,物理内存中有物理页(Physical Page),虚拟内存中有 Virtual Page 来管理。通常页的大小为 4KB。
系统通过 MMU 和 页表(Page Table) 来管理 虚拟页 和 物理也 的对应关系,页表就是页表条目(Page Table Entry,PTE)的数组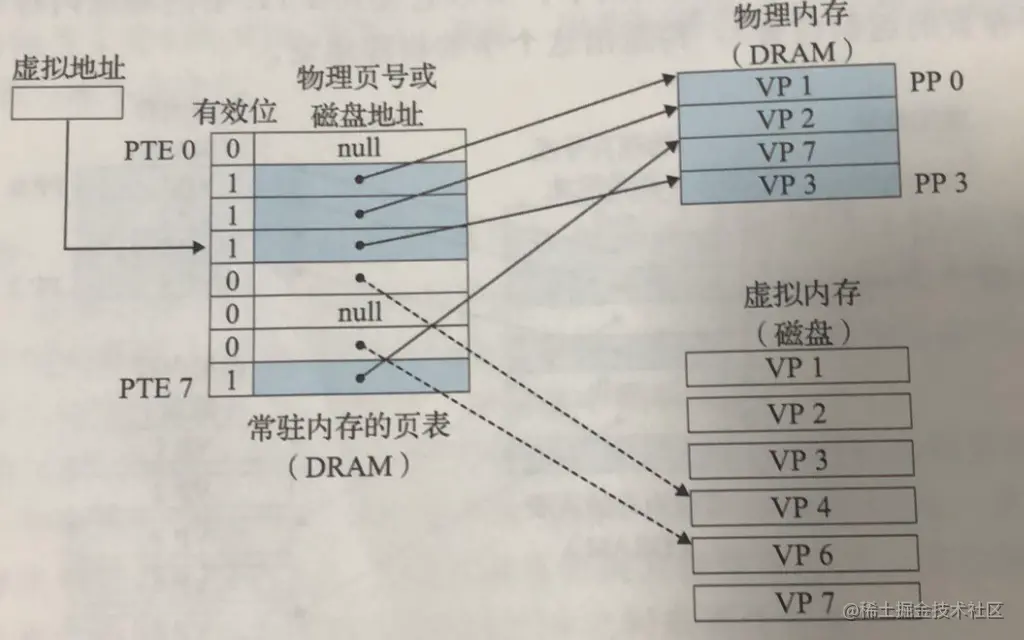
PTE 的有效为1时,标识数据在内存中,标识为 0 时,标识在磁盘上。
当访问的虚拟地址对应的数据不再物理内存上时,会有两种情况处理:
1、在内存够用的时候,会直接将虚拟页对应在磁盘上的数据加载到物理内存上,
2、当内存不够用的时候,就会触发 swap,会根据 LRU 将最近使用频率比较低的虚拟页对应物理也淘汰掉,写入到磁盘中去,淘汰掉一部分物理内存中的数据,然后对对应的虚拟页设置为 0,然后将磁盘上的数据再加载到内存中去。
传统 IO、mmap 和 sendfile
场景:从本地文件读取在写到网卡的过程中
无论是传统 I/O 拷贝方式还是引入零拷贝的方式,2 次 DMA Copy 是都少不了的,因为两次 DMA 都是依赖硬件完成的。下面从 CPU 拷贝次数、DMA 拷贝次数以及系统调用几个方面总结一下上述几种 I/O 拷贝方式的差别。
| 拷贝方式 | CPU拷贝 | DMA拷贝 | 系统调用 | 上下文切换 |
|---|---|---|---|---|
| 传统方式(read + write) | 2 | 2 | read / write | 4 |
| 内存映射(mmap + write) | 1 | 2 | mmap / write | 4 |
| sendfile | 1 | 2 | sendfile | 2 |
| sendfile + DMA gather copy | 0 | 2 | sendfile | 2 |
| splice | 0 | 2 | splice | 2 |
总结一下(以从磁盘读取文件再通过网路发送出去的情况为例):
- 传统 IO:执行时需要 4 次上下文切换(用户态 -> 内核态 -> 用户态 -> 内核态 -> 用户态)和 4 次拷贝(磁盘文件 DMA 拷贝到内核缓冲区,内核缓冲区 CPU 拷贝到用户缓冲区,用户缓冲区 CPU 拷贝到 Socket 缓冲区,Socket 缓冲区 DMA 拷贝到协议引擎)。
- mmap:执行时将磁盘文件映射到内存,支持读和写,对内存的操作会反映在磁盘文件上,适合小数据量读写,需要 4 次上下文切换(用户态 -> 内核态 -> 用户态 -> 内核态 -> 用户态)和 3 次拷贝(磁盘文件DMA拷贝到内核缓冲区,内核缓冲区 CPU 拷贝到 Socket 缓冲区,Socket 缓冲区 DMA 拷贝到协议引擎)。
- sendfile:执行时将读到内核空间的数据,转到 socket buffer,进行网络发送,适合大文件传输,只需要 2 次上下文切换(用户态 -> 内核态 -> 用户态)和 2 次拷贝(磁盘文件 DMA 拷贝到内核缓冲区,内核缓冲区 DMA 拷贝到协议引擎)

若有收获,就点个赞吧
0 人点赞
