1.简单讲解
对于这个简短的程序,逻辑还是非常简单的。
- 首先创建一个流处理环境env,
- 然后往这个环境添加数据源,比如env.socketTextStream,和env.addSource(kafkaSource);
- 自定义算子,算子的作用是对传输过来的每一条数据进行处理,是数据处理的核心部分。在下面的程序里,我们重写了flatMap()方法,flatMap+keyBy+sum就完成了一条消息的word count。
env.execute()执行任务。实际上前面的部分是我们定义了这个任务的执行规则,到这一行才开始执行任务,按上述规则对每个事件(指收到消息)进行处理。
2.maven依赖
<dependencies><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.7</version><scope>runtime</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>runtime</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.11</artifactId><version>2.3.1</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.3.1</version></dependency><!-- Apache Flink dependencies --><!-- These dependencies are provided, because they should not be packaged into the JAR file. --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.10.2</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>1.10.2</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka-base_2.11</artifactId><version>1.10.2</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>1.10.2</version></dependency>
需要注意的是我们有两处
provided ,所以要在IDEA->Run->edit configurations里选上 Include provided scope那一行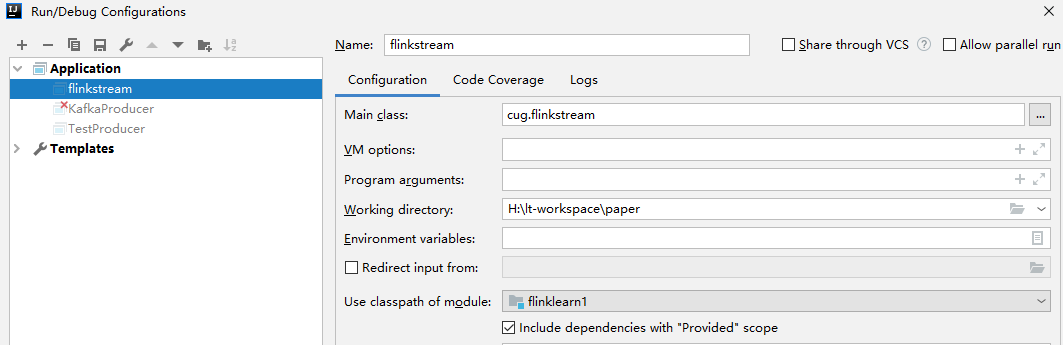
3.Java代码
flinkstream类,接收Kafka生产者发送的消息,对每条消息进行word count
import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import org.apache.flink.util.Collector;import java.util.Properties;public class flinkstream {public static void main(String[] args) throws Exception {//创建流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//接收一个socket文本流,参数:主机名,端口号// DataStream<String> text = env.socketTextStream("127.0.0.1", 9000);System.out.println("设置kafka连接参数!!!");Properties props = new Properties();props.setProperty("bootstrap.servers", "172.27.210.57:9092");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("group.id", "cug/kafka/test");//如果没有记录偏移量,第一次从最开始消费//props.setProperty("auto.offset.reset", "earliest");//kafka的消费者不自动提交偏移量// props.setProperty("enable.auto.commit","false");System.out.println("给flink添加上kafka数据源!!!");//kafkaSource,flink消费指定topic的数据FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("lt", new SimpleStringSchema(), props);DataStream<String> lines = env.addSource(kafkaSource);//进行转换处理DataStream<Tuple2<String, Integer>> dataStream = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {String[] tokens = s.toLowerCase().split("\\W+");for (String token : tokens) {if (token.length() > 0) {collector.collect(new Tuple2<String, Integer>(token, 1));}}}}).keyBy(0).timeWindow(Time.seconds(5)).sum(1);//keyby是分组 ,sum叠加//打印结果dataStream.print();//启动任务执行,execute可以不给参数,参数是作业名字env.execute("Java WordCount from SocketTextStream Example");}}
TestProducer,一个简单的Kafka生产者,发送消息出去
import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;import java.util.Scanner;public class TestProducer {public static void main(String[] args) {Properties props = new Properties();props.setProperty("bootstrap.servers", "172.27.210.57:9092");props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(props);String topic = "lt";while(true){System.out.println("请输入一个字符串");Scanner sc = new Scanner(System.in);String str = sc.nextLine();producer.send(new ProducerRecord<>(topic, str));}}}
4.运行结果
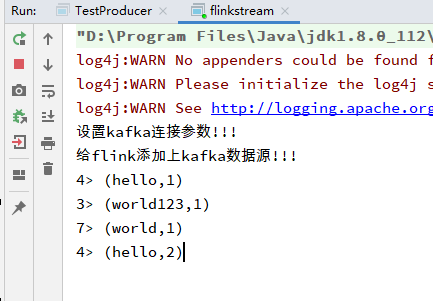
Kafka发送两条消息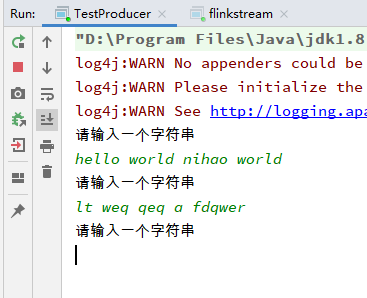
flink对每条消息的处理结果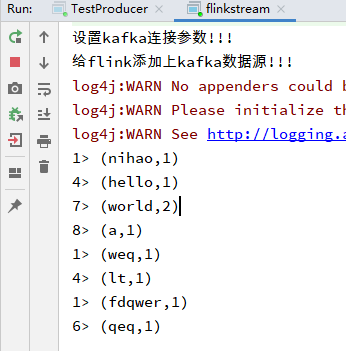
如果不懂Kafka,可以换成netcat发送数据,
18行取消注释
DataStream
36行lines改成text
DataStream
注释调20-33行Kafka那一段
运行netcat,结果如图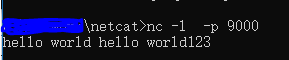
5.关于重写方法
个人觉得上面那种写法有点不易读,主要是实现了flatMap()里面的接口FlatMapFunction,补全的它的方法flatMap(),可以写一个类来实现它,改动如下:
DataStream<Tuple2<String, Integer>> dataStream = text.flatMap(new Splitter()).keyBy(0).sum(1);
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {String[] tokens = s.toLowerCase().split("\\W+");for (String token : tokens) {if (token.length() > 0) {collector.collect(new Tuple2<String, Integer>(token, 1));}}}}
以flatMap对应的FlatMapFunction为例,它在源码中的定义为:
public interface FlatMapFunction<T, O> extends Function, Serializable {void flatMap(T value, Collector<O> out) throws Exception;}
这是一个接口类,它继承了Flink的Function函数式接口。函数式接口只有一个抽象函数方法(Single Abstract Method),其目的是为了方便Java 8 Lambda表达式的使用。此外,它还继承了Serializable,以便进行序列化,这是因为这些函数在运行过程中要发送到各个TaskManager上,发送前后要进行序列化和反序列化。需要注意的是,使用这些函数时,一定要保证函数内的所有内容都可以被序列化。如果有一些不能被序列化的内容,或者使用接下来介绍的Rich函数类,或者重写Java的序列化和反序列化方法。
进一步观察FlatMapFunction发现,这个这个函数有两个泛型T和O,T是输入,O是输出,在使用时,要设置好对应的输入和输出数据类型。自定义函数最终归结为重写函数flatMap,函数的两个参数也与输入输出的泛型类型对应,即参数value的是flatMap的输入,数据类型是T,参数out是flatMap的输出,我们需要将类型为O的数据写入out。
在我们的程序里,泛型O用了Tuple2,Tuple2又是一个泛型类,是flink里定义的,在里面设置参数类型为

若有收获,就点个赞吧
0 人点赞
