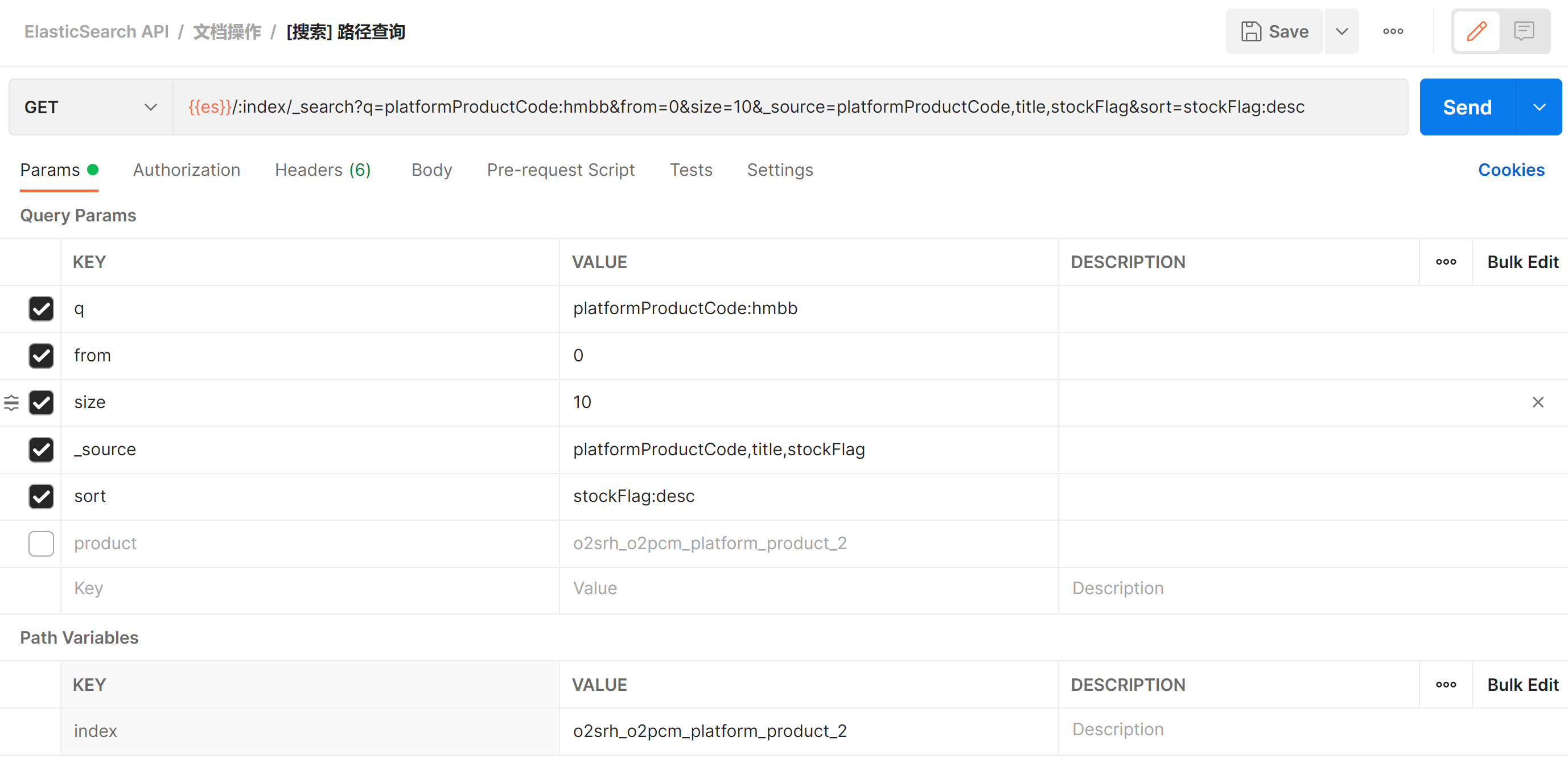
搜索请求的基本模块
- query: 具体的搜索内容
- size:返回文档的数量,默认10
- from:偏移量:如果要看第二页的10个结果,ES需要计算出前20个结果->获取靠后的分页代价越来越大,默认0
- _source:指定返回的字段,默认全部字段返回
- sort:排序,默认的排序是按照文档的得分降序排
- profile:分析
- explain:计算得分过程
Search API
- URI Search
- 在 URL 上使用查询参数
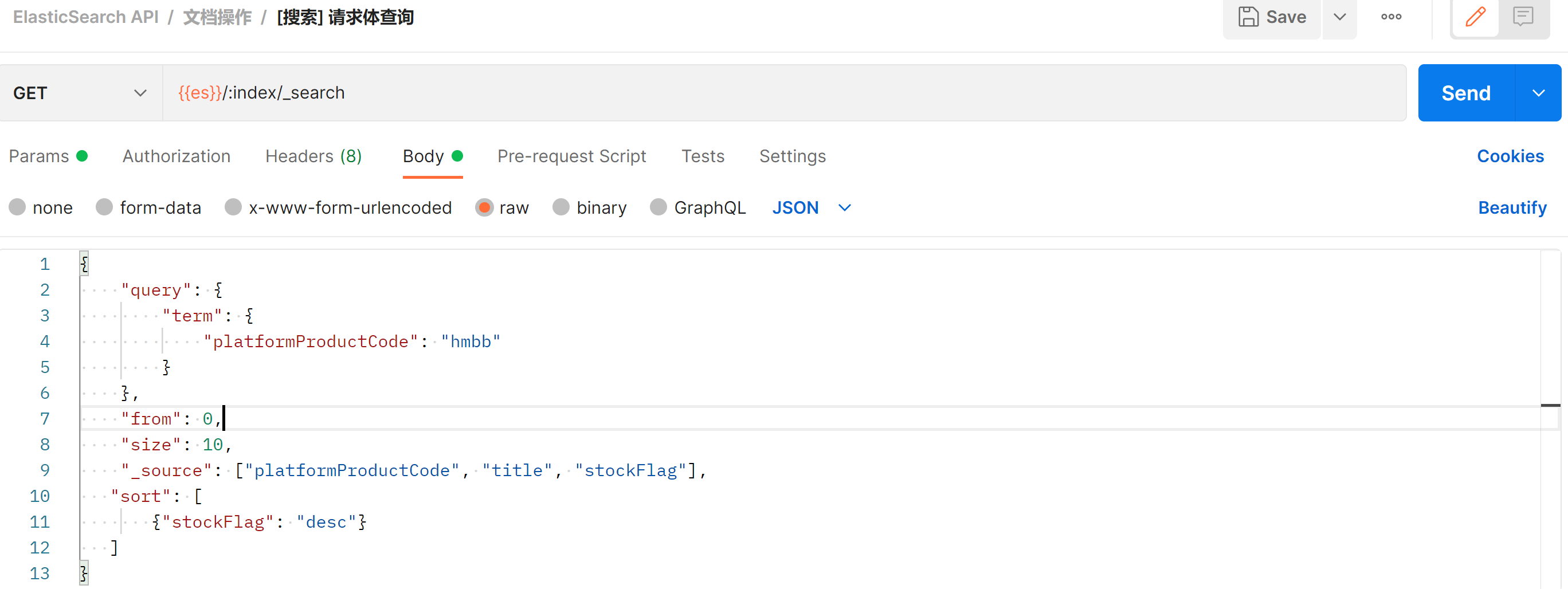
- Request Body Search
- 使用 ElasticSearch 提供的,基于 JSON 格式的更加完备的 Query Domain Specific Language (DSL)
响应体解析
{// 花费时间,毫秒"took": 4,// 是否超时"timed_out": false,// 涉及分片信息"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},// 命中文档的信息组"hits": {// 命中数"total": {"value": 1,"relation": "eq"},// 命中文档中最大的匹配分数"max_score": 5.247024,// 命中文档详细信息"hits": [{// 文档索引"_index": "o2srh_o2pcm_platform_product_10_2",// 文档索引类型"_type": "_doc",// 文档id"_id": "hmbb_OW-1",// 此词搜索文档的匹配分数"_score": 5.247024,// 文档源字段"_source": {"platformProductCode": "hmbb","title": "海绵宝宝","stockFlag": 1}}]}}
基于词项和基于全文的搜索
创建索引的Mapping结构
PUT book{"mappings": {"dynamic": "false","properties": {"nameText": {"type": "text","analyzer": "standard"},"nameKeyWord": {"type": "keyword"},"country": {"type": "keyword"},"price": {"type": "float"}}}}
插入的数据
[{"nameText":"ES in action ES","nameKeyWord":"ES in action ES","country":"China","price":100},{"nameText":"ES in one action","nameKeyWord":"ES in one action","country":"Japan","price":200},{"nameText":"ES in one two action","nameKeyWord":"ES in one two action","country":"America","price":300},{"nameText":"What is ES","nameKeyWord":"What is ES","country":"China","price":400},{"nameText":"one thing is good","nameKeyWord":"one thing is good","country":"America","price":500}]
nameText 字段被设置成 text 类型,会走分析流程,并且使用 设置的 standard分析器进行分析写入:
| Term | _id: 1 | _id: 2 | _id: 3 | _id: 4 | _id: 5 |
|---|---|---|---|---|---|
| es | 2 | 1 | 1 | 1 | |
| in | 1 | 1 | 1 | ||
| action | 1 | 1 | 1 | ||
| one | 1 | 1 | 1 | ||
| two | 1 | ||||
| what | 1 | ||||
| is | 1 | 1 | |||
| thing | 1 | ||||
| good | 1 |
基于全文的查询
特点:
- 索引和搜索时都会进行分词,查询字符串先传递到一个合适的分词器,然后生成一个供查询的词项列表
- 查询的时候,先会对输入的查询进行分词,然后每个词项逐个进行底层的查询,最终将结果进行合并。并为每个文档生成一个得分。
典型代表:
- Match Query
- Match Phrase Query
- Match Phrase Prefix
基于 Term 的查询
Term 是分词语义的最小单位。
在 ES 中, Term 查询,对输入不做分词。会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分。
可以利用 Constant Score 将查询转换成一个 Filtering,避免算分,并且利用缓存,提高性能。
典型代表组成:
- Term Query
- Range Query
- Prifix Qery
ES 的两种搜索上下文
- query context:
- 关注点是的是匹配度有多高,并计算出匹配分数,关注点是match
- 查询:计算文档得分
- 结果不会缓存
- 走的是倒排索引
- 应用场景:全文检索以及任何需要相关性的场景
- filter context:
- 关注点是匹配与否,并不需要计算分数,关注点是 included or not
- 只筛选出符合的文档,不算得分
- 缓存文档 ——>大范围筛选数据
- 走的是 Bitsets
- 应用场景:完全精确匹配,范围检索
性能比较
- query context除了检索外,还需要计算相关度
- filter 有缓存
filter context 怎么缓存
- ES 会创建一个文档匹配过滤器的位集 bitset,文档匹配就是1,否则为0,随后用相同的过滤器查询就会重用这部分缓存。
- 当创建/更新文档时,bitset也会更新
Lucene金科玉律:尽量用 filter context,除非必须使用 query context(当且仅当需要计算分的时候)
bool 复合查询
是一个或者多个查询子句的组合。组合查询。
bool:
- query context:
- must:必须匹配。贡献算分
- should:选择性匹配。贡献算分。
- filter context:
- must not:查询字句,必须不能匹配
- filter:必须匹配,但不贡献算分
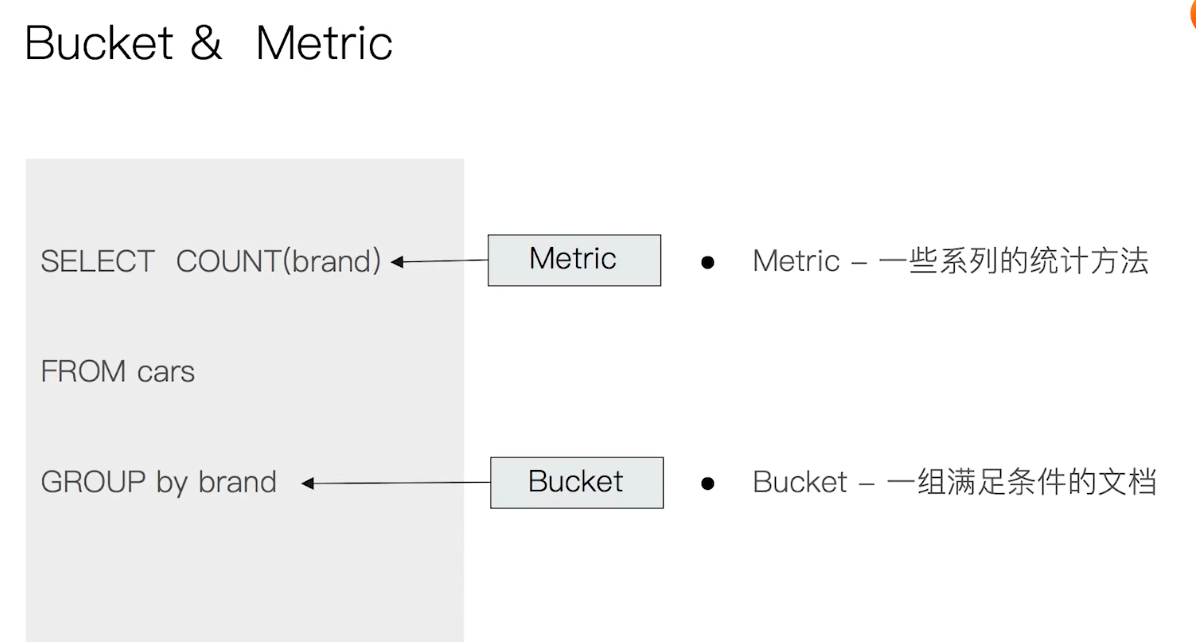
聚合(Aggregation)
ES 对数据进行统计分析的功能,
经典组成:
- Bucket Aggregation
- 分组,一组满足条件的文档
- Metric Aggregation
- 一系列的统计方法(最大值、最小值、平均值)

若有收获,就点个赞吧
0 人点赞
