单节点集群
{"settings": {// 为该索引设置3个主分片"number_of_shards": 3,// 每个主分片设置1个副本分片"number_of_replicas: 1}
}’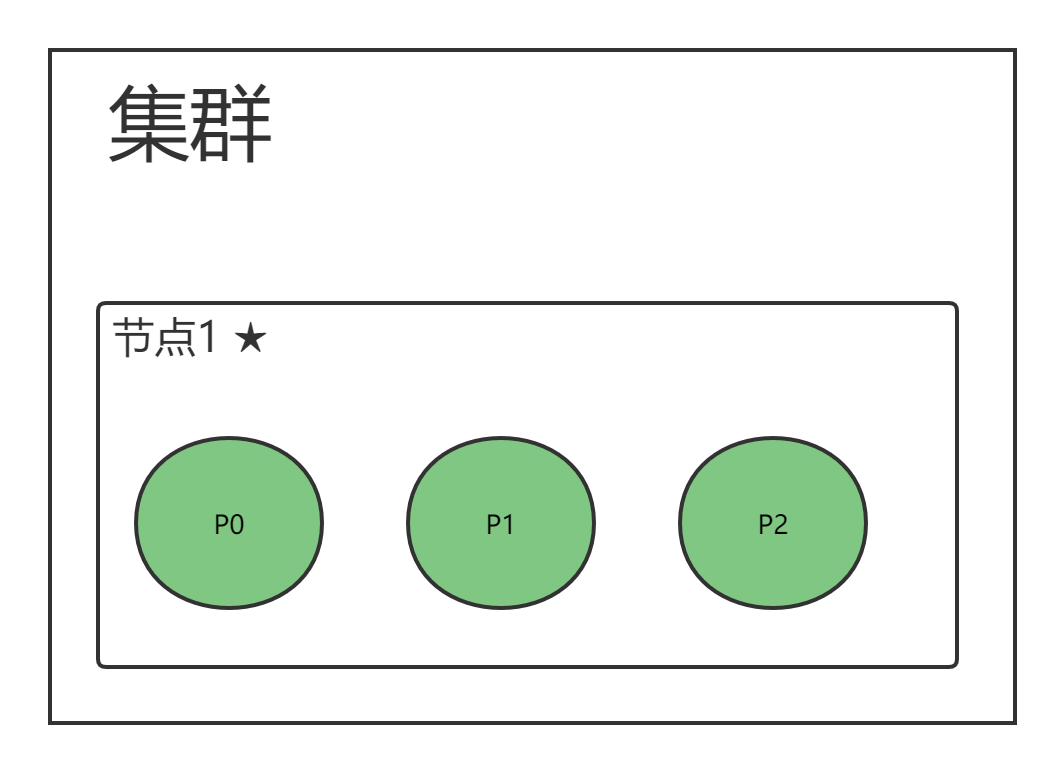
- 副本无法分片,集群状态黄色
为集群新增一个节点后
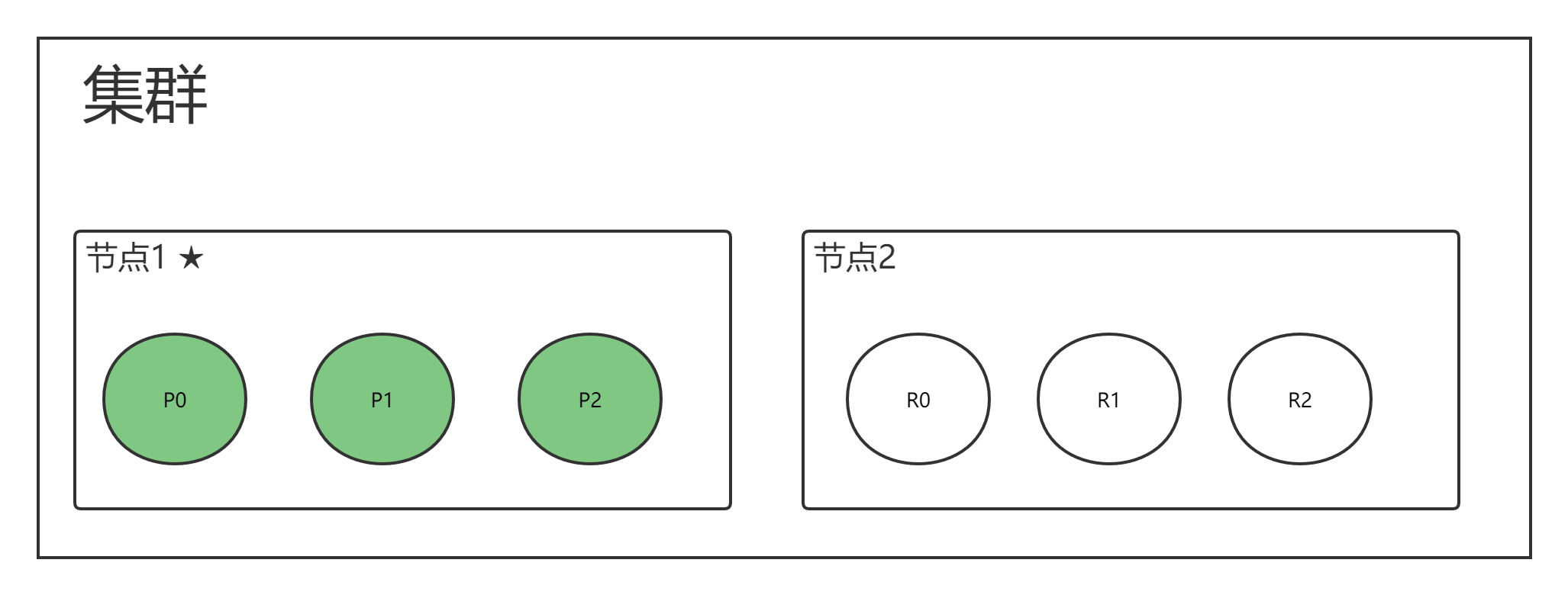
- 集群状态变成绿色
- 集群具备故障转移能力
再加入一个节点
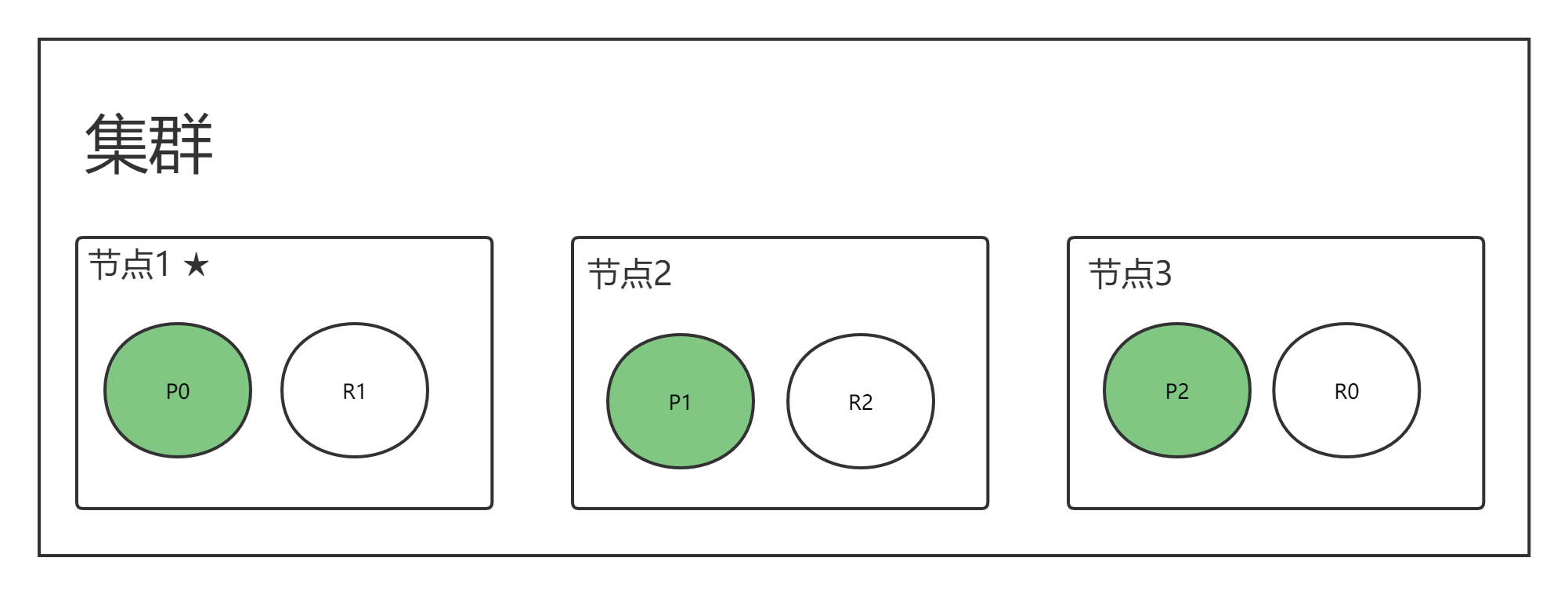
- 集群具备故障转移能力
- Master 节点会决定分片分到哪个节点
- 通过增加节点,提高集群的计算能力
故障转移
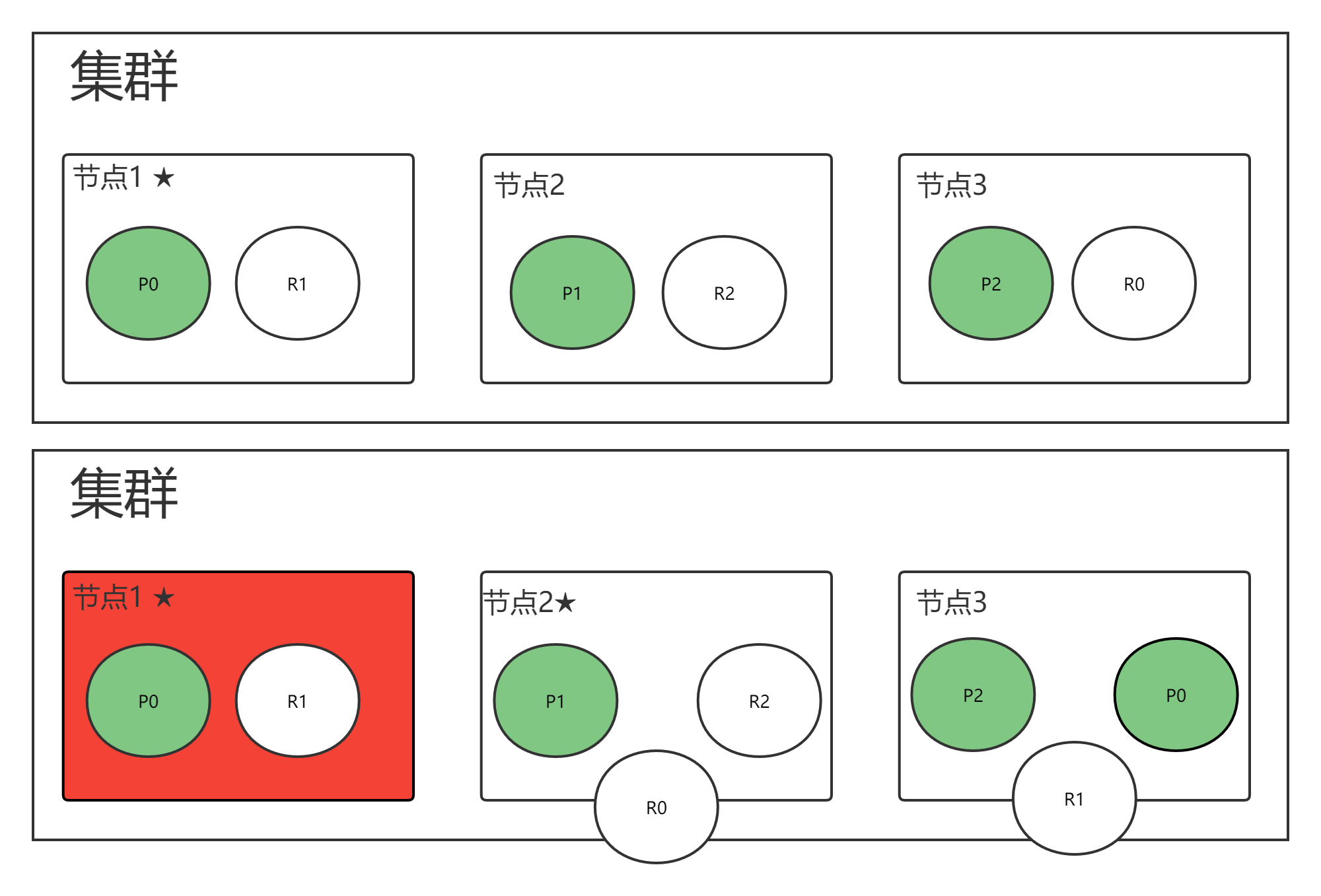
假设 主节点:节点1 挂了
转移流程:
- 节点2 与 节点3 重新选举主节点,假设 节点2 成为新的主节点
- 主分片 P0 挂了,位于 节点3 的副本分片 R0 提升成主分片 P0,集群状态为黄色
- 剩余的副本分片 R0 与 R1 重新分配,集群状态为绿色。
文档写入(新增/更新/删除)过程
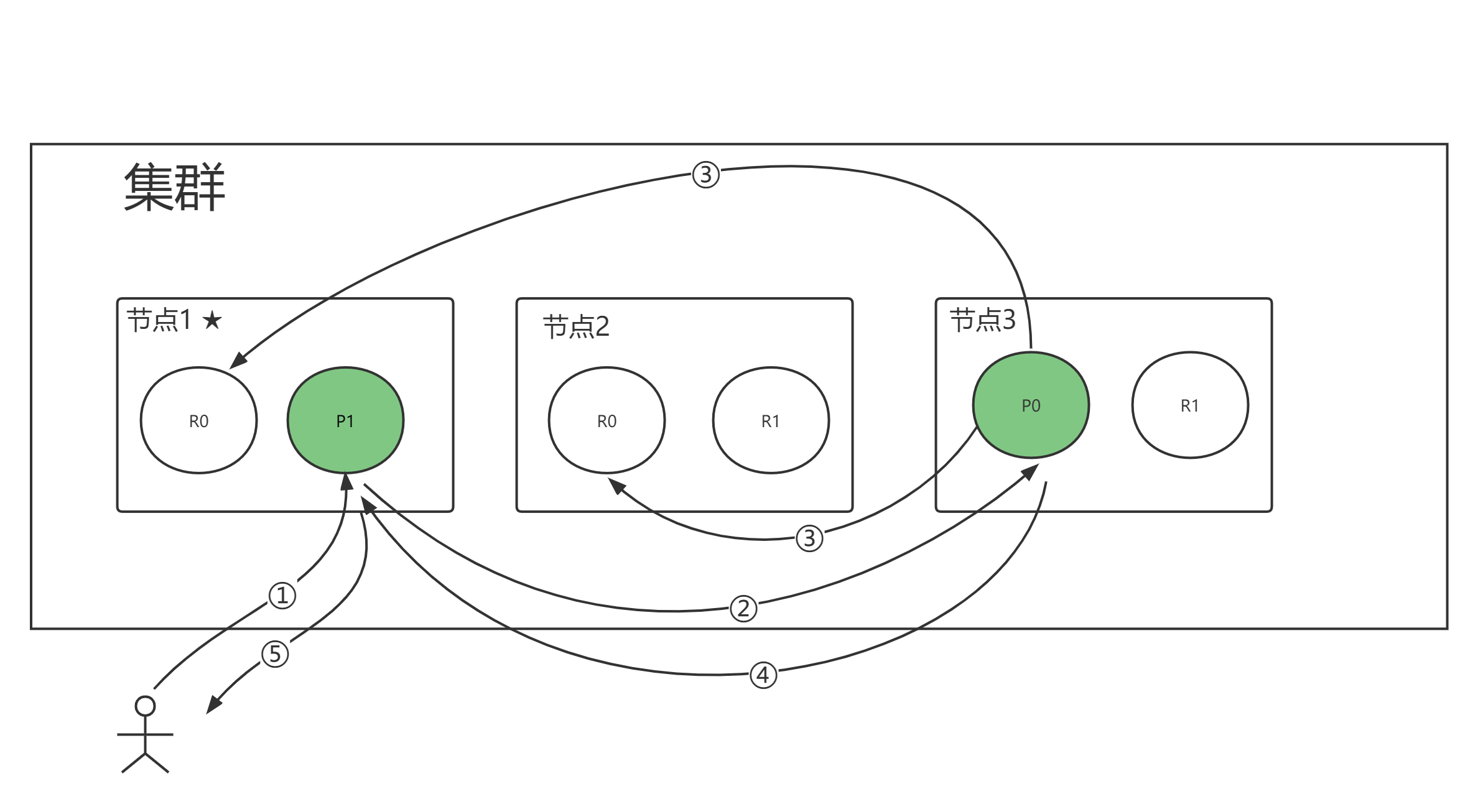
以下是在主副分片和任何副本分片上面 成功新建,索引和删除文档所需要的步骤顺序:
- 客户端向 节点1 发送新建、索引或者删除请求。
- 节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 节点3,因为分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。
优化点:
- 可选等待副本同步成功的数量
- consistency,一致性
- 默认是规定数量:quorum:int((primary + numbers_of_replicas) / 2) + 1
- 可选值:one、all
- 超时时间
写入的总时间 = 主分片延时 + 并行写入副本分片的最大延时
副本越多,写入的时间可能就越长,但数据可靠性和搜索吞吐性增加
文档搜索的过程
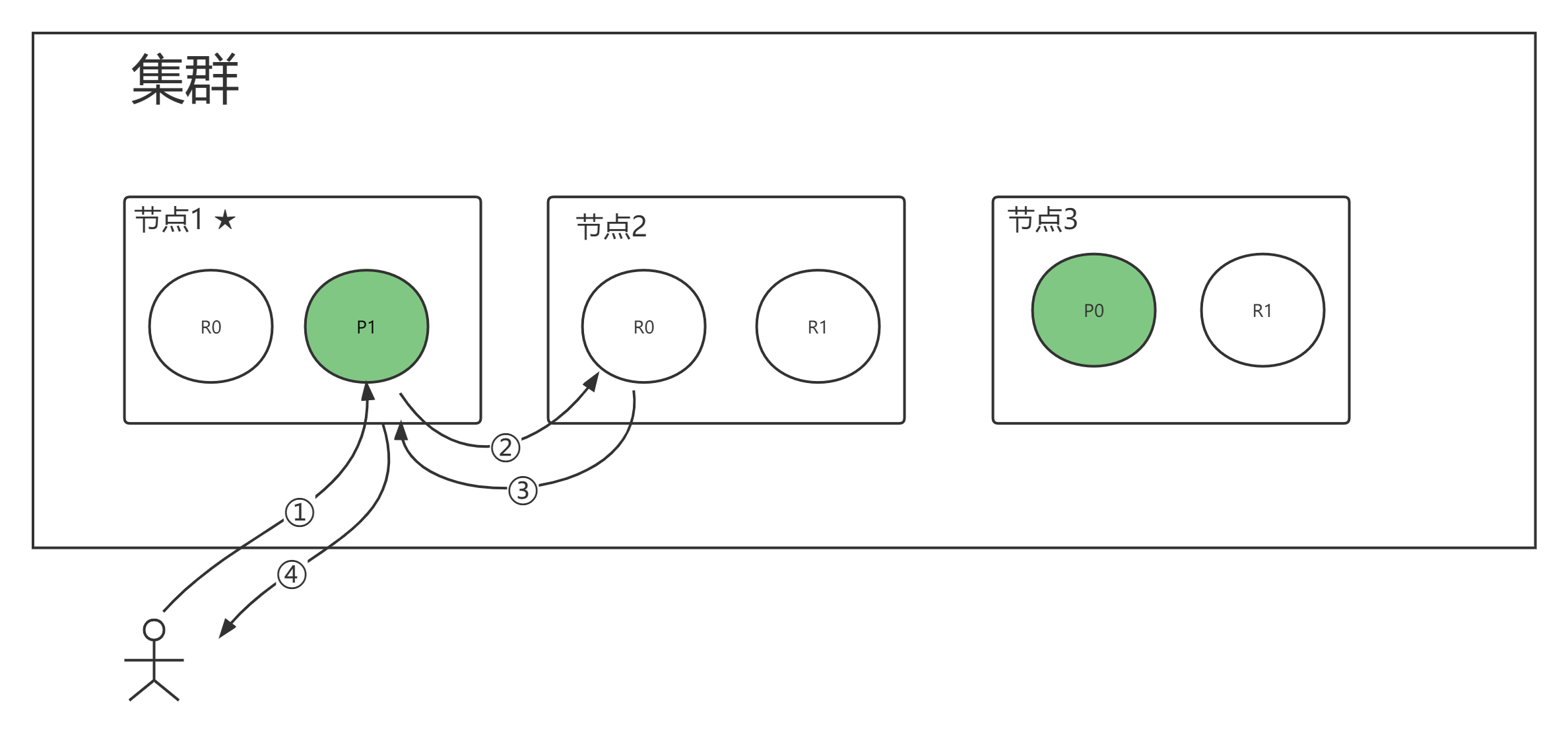
读主副分片都行,协调节点控制,分片控制策略是轮询,不是访问你,你就要处理结果
- 客户端发送查询请求到协调节点
- 协调节点计算数据所在的分片以及全部的副本位置
- 为了能够负载均衡,可以轮询所有节点
- 将请求转发给具体的节点
-
文档部分更新的过程
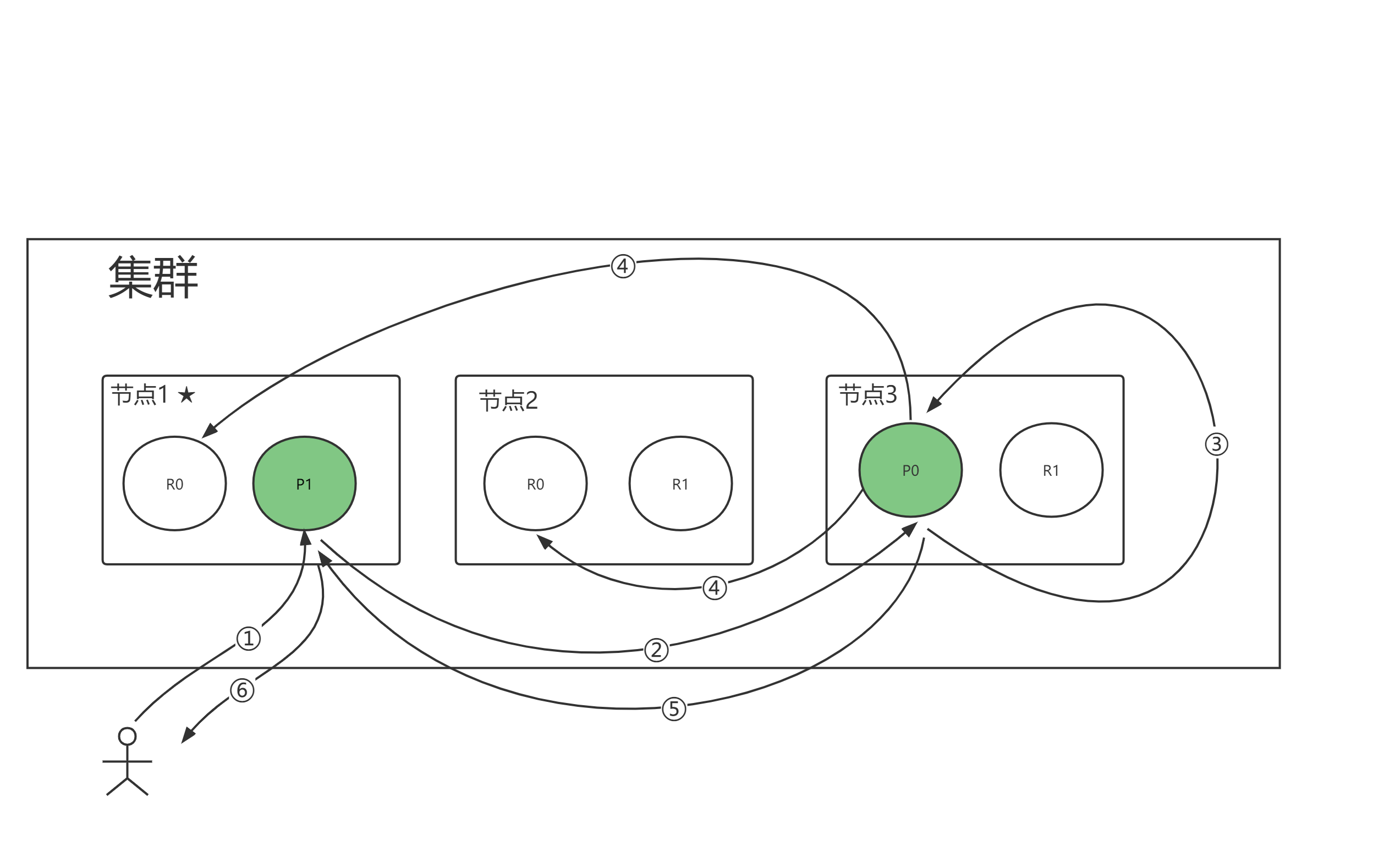
客户端向 Node 1 发送更新请求
- 它将请求转发到主分片所在的 Node 3
- Node 3 从主分片检索文档,修改 _source 字段中的 JSON,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤3,超过 retry_on_conflict 次数后放弃。
- 如果 Node 3 成功地更新文档,它将新版本的文档并行转发到 Node 1 和 Node 2上的副本分片,重新建立索引。一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
当主分片把更改转发到副本分片时,它不会转发更新请求。相反,它转发完整文档的新版本。这些更改将会异步转发到副本分片上,并且不能保证它们以发送它们相同的顺序到达。如果ES仅仅转发更改请求,则可能以错误的顺序应用更改,从而导致文档损坏。
批量操作
mget 和 bulk API 的模式类似于单文档模式。区别在于协调节点知道每个文档存在于哪个分片中。它将整个多文档请求分解成 每个分片 的多文档请求,并且将这些请求并行转发到每个参与节点。
协调节点一旦收到来自每个节点的答应,就将每个节点的响应收集整理成单个响应,返回给客户端。

若有收获,就点个赞吧
0 人点赞
