简介
Go中主要有四种复合类型
- 数组
slicemap- 结构体
数组是由同构的元素组成——每个数组元素都是完全相同的类型
结构体则是由异构的元素组成的。数组和结构体都是有固定内存大小的数据结构。**slice**和**map**则是动态的数据结构,它们将根据需要动态增长
数组
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。因为数组的长度是固定的,因此在Go语言中很少直接使用数组。和数组对应的类型是Slice(切片),它是可以增长和收缩动态序列
数组的每个元素可以通过索引下标来访问,索引下标的范围是从0开始到数组长度减1的位置。内置的len函数将返回数组中元素的个数
var arr [4]intfmt.Println(arr[1]) // 0
数组的每个元素都被初始化为元素类型对应的零值,对于数字类型来说就是0。我们也可以使用数组字面值语法用一组值来初始化数基本格式为**vararray_name[length]type**,数组的长度必须是常量表达式,如果在数组的长度位置出现的是...省略号,则表示数组的长度是根据初始化值的个数来计算,下面是几种数组的构建方式
var arr1 [4]int
var arr2 [4]int = [4]int{1, 2, 3} // 给定元素数量不够会用元素类型对应的零值填充
var arr3 [4]string
var arr4 [4]string = [4]string{"a", "b", "c"}
var arr5 [4]bool
func main() {
arr6 := [...]int{1, 2, 3, 4}
fmt.Println(arr1[2]) // 0
fmt.Println(arr2[2]) // 3
fmt.Println(arr3[2]) // (空字符串)
fmt.Println(arr4[2]) // c
fmt.Println(arr5[2]) // false
fmt.Println(arr6[2]) // 3
}
数组、slice、map和结构体字面值的写法都很相似。上面的形式是直接提供顺序初始化值序列,但是也可以指定一个索引和对应值列表的方式初始化,在这种形式的数组字面值形式中,初始化索引的顺序是无关紧要的,而且没用到的索引可以省略,未指定初始值的元素将用零值初始化如,arr:=[...]int{99:-1},只有第99个元素被初始化为-1,其余皆0
type Currency int
const (
USD Currency = iota
EUR
GBP
RMB
)
func main() {
// 下面的语句相当于 symbol := [...]string{0:"$", 1:"€", 2: "£", 3: "¥"}
symbol := [...]string{USD:"$", EUR:"€", GBP: "£", RMB: "¥"}
fmt.Println(RMB, symbol[RMB])
fmt.Println(symbol)
}
// out
// 3 ¥
// [$ € £ ¥]
如果一个数组的元素类型是可以相互比较的,那么数组类型也是可以相互比较的,这时候我们可以直接通过==比较运算符来比较两个数组,只有当两个数组的所有元素都是相等的时候数组才是相等的。不相等比较运算符!=遵循同样的规则
应用举例crypto/sha256包的Sum256函数对一个任意的字节slice类型的数据生成一个对应的消息摘要。消息摘要有256bit大小,因此对应[32]byte数组类型。如果两个消息摘要是相同的,那么可以认为两个消息本身也是相同%x它用于指定以十六进制的格式打印数组或slice全部的元素,%t副词参数是用于打印布尔型数据,%T副词参数是用于显示一个值对应的数据类型
package main
import (
"fmt"
"crypto/sha256"
)
func main() {
c1 := sha256.Sum256([]byte("X"))
c2 := sha256.Sum256([]byte("x"))
fmt.Printf("%x\n%x\n%t\n%T\n", c1, c2, c1 == c2, c1)
}
// out
// 4b68ab3847feda7d6c62c1fbcbeebfa35eab7351ed5e78f4ddadea5df64b8015
// 2d711642b726b04401627ca9fbac32f5c8530fb1903cc4db02258717921a4881
// false
// [32]uint8
slice
Slice(切片)代表变长的序列,序列中每个元素都有相同的类型。一个slice类型一般写作[]T,其中T代表slice中元素的类型;slice的语法和数组很像,只是没有固定长度而已,即[]type{}
一个slice由三个部分构成:
指针、长度和容量。指针指向第一个slice元素对应的底层数组元素的地址,要注意的是slice的第一个元素并不一定就是数组的第一个元素。指针指向的索引的指向的底层数组的第一个元素,如数组a=[1,3,4,5],a[1:]slice对应的第一个元素为3
- 长度(
**len**)对应slice中元素的数目;长度不能超过容量 - 容量(
**cap**)一般是从**slice**的开始位置到底层数据的结尾位置。 - 内置的
len和cap函数分别返回slice的长度和容量
例如,
package main
import "fmt"
func main(){
test := []string{"a","b","c","d","e","f"}
test2 := test[:4]
test3 := test[4:]
test4 := test[1:3]
fmt.Printf("test: len: %d, cap: %d, 底层数组左侧指针位置(index): 0\n", len(test), cap(test))
fmt.Printf("test1: len: %d, cap: %d, 底层数组左侧指针位置(index): 0\n", len(test2), cap(test2))
fmt.Printf("test1: len: %d, cap: %d, 底层数组左侧指针位置(index): 4\n", len(test3), cap(test3))
fmt.Printf("test1: len: %d, cap: %d, 底层数组左侧指针位置(index): 1\n", len(test4), cap(test4))
}
// output:
// test: len: 6, cap: 6, 底层数组左侧指针位置(index): 0
// test1: len: 4, cap: 6, 底层数组左侧指针位置(index): 0
// test1: len: 2, cap: 2, 底层数组左侧指针位置(index): 3
// test1: len: 2, cap: 5, 底层数组左侧指针位置(index): 1
len和cap的关系以下图也可清楚表示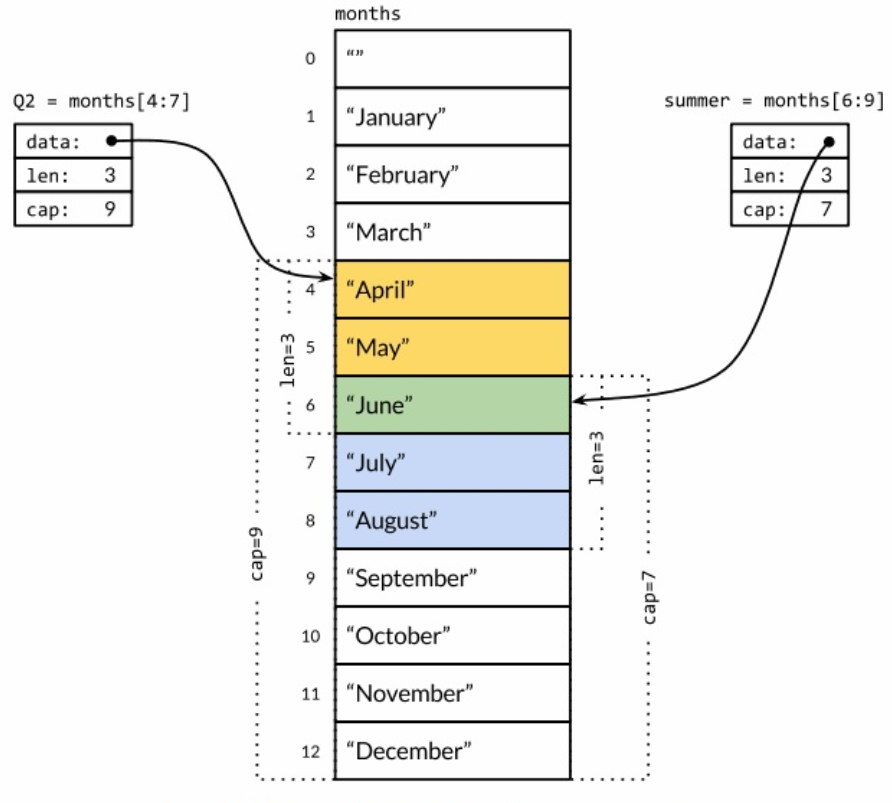
字符串的切片操作和[]byte字节类型切片的切片操作是类似的。它们都写作x[m:n],并且都是返回一个原始字节系列的子序列,底层都是共享之前的底层数组,因此切片操作对应常量时间复杂度。x[m:n]切片操作对于字符串则生成一个新字符串,如果x是[]byte的话则生成一个新的[]byteslice值包含指向第一个slice元素的指针,因此向函数传递slice将允许在函数内部修改底层数组的元素。换句话说,复制一个slice只是对底层的数组创建了一个新的**slice**别名,下面的reverse函数在原内存空间将**[]string**类型的**slice**反转
package main
import "fmt"
func reverse(s []string) []string{
for i, j := 0, len(s) -1; i<j; i, j = i + 1, j - 1{
s[i], s[j] = s[j], s[i]
}
return s
}
func main(){
ss := []string{"a", "b", "c", "d"}
ssr := reverse(ss[2:])
fmt.Println(ss)
fmt.Println(ssr)
}
// output
// [a b d c] 原数组的最后两个元素也修改了
// [d c]
创建
slice和数组的字面值语法很类似,它们都是用花括弧包含一系列的初始化元素,但是对于slice并没有指明序列的长度。这会隐式地创建一个合适大小的数组,然后**slice**的指针指向底层的数组。**slice**之间不能比较,因此我们不能使用**==**操作符来判断两个**slice**是否含有全部相等元素。不过标准库提供了高度优化的bytes.Equal函数来判断两个字节型slice是否相等([]byte),但是对于其他类型的**slice**,必须自己展开每个元素进行比较,安全的做法是直接禁止**slice**之间的比较操作,slice唯一合法的比较操作是和nil比较
一个零值的slice等于nil。一个nil值的slice并没有底层数组。一个nil值的slice的长度和容量都是0,但是也有非nil值的slice的长度和容量也是0的,例如[]int{}或make([]int,3)[3:]
如果需要测试一个**slice**是否是空的,使用**len(s)==0**来判断,而不应该用**s==nil**来判断
内置的make函数创建一个指定元素类型、长度和容量的slice。容量部分可以省略,在这种情况下,容量将等于长度
make([]Type, len)
make([]Type, len, cap) // same as make([]T, cap)[:len]
make创建了一个匿名的数组变量,然后返回一个**slice**;只有通过返回的**slice**才能引用底层匿名的数组变量。
- 第一种语句,
slice是整个数组的view。 - 第二种语句,
slice只引用了底层数组的前len个元素,但是容量将包含整个的数组。额外的元素是留给未来的增长用的append
append函数用于向slice追加元素 ```go package main
import “fmt”
var runes []rune
func main() { ss := “Hello 你” // runes := []rune{} for _, s := range ss { runes = append(runes, s) } fmt.Println(runes) fmt.Println([]rune(ss)) } // output // [72 101 108 108 111 32 20320] // [72 101 108 108 111 32 20320]
在循环中使用`append`函数构建一个由九个`rune`字符构成的`slice`,同样可以通过`Go`语言内置的`[]rune("Hello 你")`转换操作完成
<a name="qeca2"></a>
#### appendint(非内置函数)
写一个函数`appendInt`函数, 专门用于处理`[]int`类型的`slice`
```go
package main
import "fmt"
func appendint(x []int, y int) []int {
var z []int
// 新数组的输出长度
zlen := len(x) + 1
// 输入的x数组的容量是否够可以容纳一个新元素, 若可以则直接扩展数组后利用索引添加元素
if zlen <= cap(x) {
z = x[:zlen]
} else {
// x数组的容量是否无法容纳一个新元素
zcap := zlen
if zcap < 2*len(x) {
// 创建一个容量是元素数两倍的数组(动态数组原理)
zcap = 2 * len(x)
}
z = make([]int, zlen, zcap)
copy(z, x)
}
z[len(x)] = y
return z
}
func main() {
ss := []int{13,4,55}
ss2 := appendint(ss[:1], 999)
fmt.Println(ss)
fmt.Println(ss2)
}
// out
// [13 999 55]
// [13 999]
每次调用appendInt函数, 必须先检测slice底层数组是否有足够的容量来保存新添加的元素。如果有足够空间的话, 直接扩展slice( 依然在原有的底层数组之上) , 将新添加的y元素复制到新扩展的空间, 并返回slice。 因此, 输入的x和输出的z共享相同的底层数组。
如果没有足够的增长空间的话, appendInt函数则会先分配一个足够大的slice用于保存新的结果, 先将输入的x复制到新的空间, 然后添加y元素。 结果z和输入的x引用的将是不同的底层数组
内置的
copy函数可以方便地将一个slice复制另一个相同类型的slice。copy函数的第一个参数是要复制的目标slice, 第二个参数是源slice, 目标和源的位置顺序和dst = src赋值语句是一致的。 两个slice可以共享同一个底层数组, 甚至有重叠也没有问题。copy函数将返回成功复制的元素的个数( 我们这里没有用到) , 等于两个slice中较小的长度
新分配的数组一般略大于保存x和y所需要的最低大小。 通过在每次扩展数组时直接将长度翻倍从而避免了多次内存分配
map
哈希表是一种巧妙并且实用的数据结构。 它是一个无序的key/value对的集合, 其中所有的key都是不同的, 然后通过给定的key可以在常数时间复杂度内检索、 更新或删除对应的value
在Go语言中, 一个map就是一个哈希表的引用, map类型可以写为map[K]V, 其中K和V分别对应key和value。 **map**中所有的**key**都有相同的类型, 所有的**value**也有着相同的类型, 但是**key**和**value**之间可以是不同的数据类型与**python**的**dict**类似。 其中K对应的key必须是支持==比较运算符的数据类型, 所以map可以通过测试key是否相等来判断是否已经存在。 不要用浮点数做key
创建
makeages := make(map[string]int) args["Tom"] = 12 args["Jerry"] = 13map字面值的语法创建map, 同时还可以指定一些最初的key/valueages := map[string]int{ "Tom": 12, "Jerry": 13 }操作
使用
[]访问元素ages["Tom"] // 12内置的delete函数可以删除元素
delete(ages, "Tom")++赋值ages["Tom"]++ // ages["Tom"] = ages["Tom"] + 1 ages["Tom"]+=1 // ages["Tom"] = ages["Tom"] + 1但是
map中的元素并不是一个变量, 因此不能对map的元素进行取址操作遍历map
可以使用
range风格对map遍历,但是每次遍历的顺序是不一致的,因此需要对map的key进行显示排序 ```go package main
import “fmt”
func main(){
ages := map[string]int{
“Tom”: 12,
“Terry”: 13,
“Sphinx”: 14,
}
for name, age := range ages {
fmt.Printf(“%s\t%d\n”, name, age)
}
}
// 运行两次
// Tom 12
// Terry 13
// Sphinx 14
// 第二次
// Terry 13
// Sphinx 14
// Tom 12
使用`sort`包中的`Strings`函数排序,或自行指定相应序列后进行有序遍历
```go
package main
import (
"fmt"
"sort"
)
var names []string
func main(){
ages := map[string]int{
"Tom": 12,
"Terry": 13,
"Sphinx": 14,
}
// 创建已知大小的数组较好节约内存
// names = make([]string, 0, len(ages))
for name, _ := range ages {
names = append(names, name)
}
sort.Strings(names)
for _, name := range names {
fmt.Printf("%s\t%d\n", name, ages[name])
}
}
// out
// Sphinx 14
// Terry 13
// Tom 12
通过key作为索引下标来访问map将产生一个value。 如果key在map中是存在的, 那么将得到与key对应的value; 如果key不存在, 那么将得到value对应类型的零值,与python的defaultdict类似map之间不能进行相等比较; 唯一的例外是和nil进行比较。 要判断两个map是否包含相同的key和value, 必须通过一个循环实现
结构体
结构体是一种聚合的数据类型, 是由零个或多个任意类型的值聚合成的实体。 每个值称为结构体的成员,
用结构体的经典案例处理公司的员工信息, 所有的这些信息都需要绑定到一个实体中, 可以作为一个整体单元被复制, 作为函数的参数或返回值, 或者是被存储到数组中
type Employee struct {
ID int
Name string
Address string
DoB time.Time
Position string
Salary int
ManagerID int
// ...
}
声明一个Employee变量
var dilbert Employee
dilbert结构体变量的成员可以通过.操作符访问, 比如dilbert.Name和dilbert.DoB。 因为dilbert是一个变量, 它所有的成员也同样是变量, 可以直接对每个成员赋值
dilbert.Salary = 5000
或者是对成员取地址, 然后通过指针访问
position := &dilbert.Position
*position = "Senior " + *position
点操作符也可以和指向结构体的指针一起工作
var employeeOfTheMonth *Employee = &dilbert
employeeOfTheMonth.Position += " (proactive team player)"
通常一行对应一个结构体成员, 成员的名字在前类型在后, 不过如果相邻的成员类型如果相同的话可以被合并到一行, 就像下面的Name和Address成员那样
type test struct {
Name, Address string
}
如果结构体成员名字是以大写字母开头的, 那么该成员就是导出的; 这是Go语言导出规则决定的。 一个结构体可能同时包含导出和未导出的成员
结构体面值
结构体值也可以用结构体面值表示, 结构体面值可以指定每个成员的值, 通常应用在较小的结构体中(它要求写代码和读代码的人要记住结构体的每个成员的类型和顺序, 不过结构体成员有细微的调整就可能导致上述代码不能编译)
type Point struct{ X, Y int }
p := Point{1, 2}
更常用的是以成员名字和相应的值来初始化, 可以包含部分或全部的成员,如果成员被忽略的话将默认用零值
anim := gif.GIF{LoopCount: nframes}
结构体可以作为函数的参数和返回值, 如果考虑效率的话, 较大的结构体通常会用指针的方式传入和返回
func Bonus(e *Employee, percent int) int {
return e.Salary * percent / 100
}
如果要在函数内部修改结构体成员的话, 用指针传入是必须的; 因为在**Go**语言中, 所有的函数参数都是值拷贝传入的, 函数参数将不再是函数调用时的原始变量,
因为结构体通常通过指针处理, 可以用下面的写法来创建并初始化一个结构体变量, 并返回结构体的地址
pp := &Point{1, 2}
// 与上面的等价
pp := new(Point)
*pp = Point{1, 2}
如果结构体的全部成员都是可以比较的, 那么结构体也是可以比较的, 那样的话两个结构体将可以使用==或!=运算符进行比较
可比较的结构体类型和其他可比较的类型一样, 可以用于map的key类型
结构体嵌入和匿名成员
如下列程序, Circle和Wheel两个结构体有共同部分,因此可以重构成以下代码
重构后,
type Point struct {
X, Y int
}
type Circle struct {
Center Point
Radius int
}
type Wheel struct {
Circle Circle
Spokes int
}
访问每个成员的方法变得更复杂,
var w Wheel
w.Circle.Center.X = 8
w.Circle.Center.Y = 8
w.Circle.Radius = 5
w.Spokes = 20
匿名成员
Go语言有一个特性让我们只声明一个成员对应的数据类型而不指名成员的名字; 这类成员就叫匿名成员, 匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针,上面的Circle和Wheel各自都有一个匿名成员(Center和Circle),也可以说Point类型被嵌入到了Circle结构体, 同时Circle类型被嵌入到了Wheel结构体
可以不通过匿名成员,直接访问叶子成员, 其中匿名成员Circle和Point都有自己的名字——就是命名的类型名字——但是这些名字在点操作符中是可选的。 我们在访问子成员的时候可以忽略任何匿名成员部分。结构体字面值并没有简短表示匿名成员的语法, 因为匿名成员也有一个隐式的名字, 因此不能同时包含两个类型相同的匿名成员, 这会导致名字冲突。
var w Wheel
w.X = 8 // equivalent to w.Circle.Point.X = 8
w.Y = 8 // equivalent to w.Circle.Point.Y = 8
w.Radius = 5 // equivalent to w.Circle.Radius = 5
w.Spokes = 20
以下语句无法编译通过
w = Wheel{8, 8, 5, 20} // compile error: unknown fields
w = Wheel{X: 8, Y: 8, Radius: 5, Spokes: 20} // compile error: unknown fields
必须遵循形状类型声明时的结构, 所以我们只能用下面的两种语法, 它们彼此是等价的

若有收获,就点个赞吧
0 人点赞
