函数声明
函数声明包括函数名、 形式参数列表、 返回值列表( 可省略) 以及函数体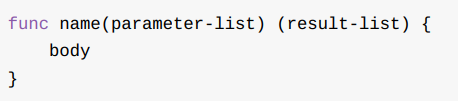
形式参数列表描述了函数的参数名以及参数类型。 这些参数作为局部变量, 其值由参数调用者提供。 返回值列表描述了函数返回值的变量名以及类型。 如果函数返回一个无名变量或者没有返回值, 返回值列表的括号是可以省略的。 如果一个函数声明不包括返回值列表, 那么函数体执行完毕后, 不会返回任何值
func main(a int, b int) int {// func body //}
如果一组形参或返回值有相同的类型, 我们不必为每个形参都写出参数类型
func f(i, j, k int, s, t string) { /* ... */ }
func f(i int, j int, k int, s string, t string) { /* ... */ }
函数的类型被称为函数的标识符。 如果两个函数形式参数列表和返回值列表中的变量类型一一对应, 那么这两个函数被认为有相同的类型和标识符。 形参和返回值的变量名不影响函数标识符也不影响它们是否可以以省略参数类型的形式表示
每一次函数调用都必须按照声明顺序为所有参数提供实参( 参数值) 。 在函数调用时, Go语言没有默认参数值, 也没有任何方法可以通过参数名指定形参, 因此形参和返回值的变量名对于函数调用者而言没有意义
没有函数体的函数声明, 这表示该函数不是以Go实现的
package math
func Sin(x float64) float
多返回值
调用多返回值函数时, 返回给调用者的是一组值, 调用者必须显式的将这些值分配给变量
links, err := findLinks(url)
//
links, _ = findLinks(url)
一个函数内部可以将另一个有多返回值的函数作为返回值, 下面的例子展示了与findLinks有相同功能的函数, 两者的区别在于下面的例子先输出参数(类似实现了一个装饰器)
func findLinksLog(url string) ([]string, error) {
log.Printf("findLinks %s", url)
return findLinks(url)
}
准确的变量名可以传达函数返回值的含义。 尤其在返回值的类型都相同时, 就像下面这样
func Size(rect image.Rectangle) (width, height int)
func Split(path string) (dir, file string)
func HourMinSec(t time.Time) (hour, minute, second int)
如果一个函数将所有的返回值都显示的变量名, 那么该函数的return语句可以省略操作数。 这称之为bare return, 但是不宜过度使用bare return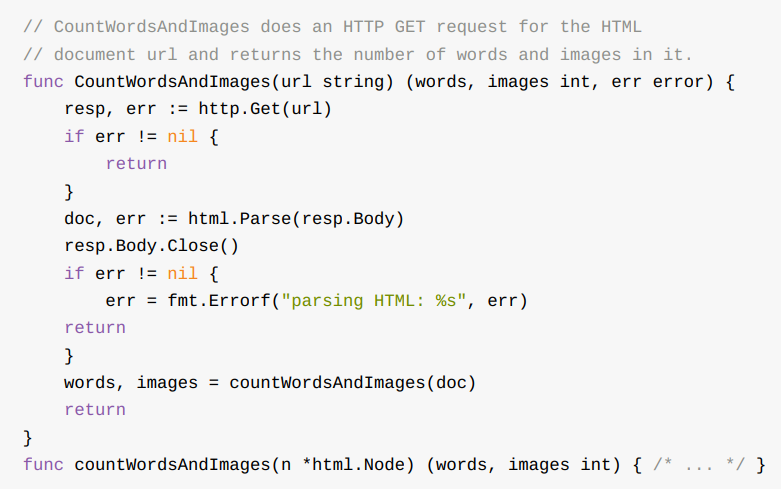
错误
一部分函数只要输入的参数满足一定条件, 也能保证运行成功。 比如time.Date函数, 该函数将年月日等参数构造成time.Time对象, 除非最后一个参数( 时区) 是nil。 这种情况下会引发panic异常。 panic是来自被调函数的信号, 表示发生了某个已知的bug。 一个良好的程序永远不应该发生panic异常
通常, 导致失败的原因不止一种, 尤其是对I/O操作而言, 用户需要了解更多的错误信息。 因此, 额外的返回值不再是简单的布尔类型, 而是error类型,内置的error是接口类型error类型可能是nil或者non-nil。 nil意味着函数运行成功, non-nil表示失败。 对于non-nil的error类型,我们可以通过调用error的Error函数或者输出函数获得字符串类型的错误信息
在Go中, 函数运行失败时会返回错误信息, 这些错误信息被认为是一种预期的值而非异常( exception) , 这使得Go有别于那些将函数运行失败看作是异常的语言。
错误处理
Go使用控制流机制( 如if和return) 处理异常
- 最常用的方式是传播错误。 这意味着函数中某个子程序的失败, 会变成该函数的失败

例如,
- 如果错误的发生是偶然性的, 或由不可预知的问题导致的。 一个明智的选择是重新尝试失败的操作。 在重试时, 我们需要限制重试的时间间隔或重试的次数, 防止无限制的重试
- 如果错误发生后, 程序无法继续运行, 我们就可以采用第三种策略: 输出错误信息并结束程序。 需要注意的是, 这种策略只应在
main中执行。 对库函数而言, 应仅向上传播错误, 除非该错误意味着程序内部包含不一致性, 即遇到了**bug**, 才能在库函数中结束程序 - 调用log.Fatalf可以更简洁的代码达到与上文相同的效果。 log中的所有函数, 都默认会在错误信息之前输出 时间信息, 例如
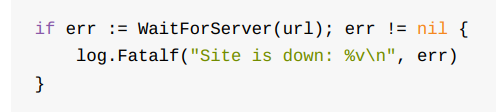
2006/01/02 15:04:05 Site is down: no such domain:
bad.gopl.io
我们只需要输出错误信息就足够了, 不需要中断程序的运行。 我们可以通过log包提供函数log.Printf或log.Fprintf,log包中的所有函数会为没有换行符的字符串增加换行符
- 直接忽略掉错误
在Go中, 错误处理有一套独特的编码风格。 检查某个子函数是否失败后, 我们通常将处理失败的逻辑代码放在处理成功的代码之前。 如果某个错误会导致函数返回, 那么成功时的逻辑代码不应放在**else**语句块中, 而应直接放在函数体中。 **Go**中大部分函数的代码结构几乎相同, 首先是一系列的初始检查, 防止错误发生, 之后是函数的实际逻辑
函数值
在Go中, 函数被看作第一类值(first-class values) : 函数像其他值一样, 拥有类型, 可以被赋值给其他变量, 传递给函数, 从函数返回。 对函数值( function value) 的调用类似函数调用
函数类型的零值是nil。 调用值为nil的函数值会引起panic错误
匿名函数
函数字面量的语法和函数声明相似, 区别在于func关键字后没有函数名。 函数值字面量是一种表达式, 它的值被称为匿名函数(anonymous function),如
// 和python的map差不多 匿名函数 lambda
strings.Map(func(r rune) rune { return r + 1 }, "HAL-9000")
例如以下闭包
func test() func() int{
var x int
return func() int {
x++
return x * x
}
}
func main() {
f := test()
fmt.Println(f())
fmt.Println(f())
fmt.Println(f())
}
// out 1 4 9
可变参数
参数数量可变的函数称为为可变参数函数。 典型的例子就是fmt.Printf和类似函数。 Printf首先接收一个的必备参数, 之后接收任意个数的后续参数
在声明可变参数函数时, 需要在参数列表的最后一个参数类型之前加上省略符号..., 这表示该函数会接收任意数量的该类型参数
func test(vars...int) int x{//...//}
在函数体中,vals被看作是类型为[] int的切片。 如下面的,sum可以接收任意数量的int型参数
func sum(vars...int) int{
sum_value := 0
for _, v := range vars {
sum_value = sum_value + v
}
return sum_value
}
func main() {
fmt.Println(sum(1))
fmt.Println(sum(1,3,4,5))
fmt.Println(sum(1,2,3,-5))
}
// out 1 13 1
调用者隐式的创建一个数组, 并将原始参数复制到数组中, 再把数组的一个切片作为参数传给被调函数。 如果原始参数已经是切片类型, 只需在最后一个参数后加上省略符...。 下面的代码功能与上个例子中最后一条语句相同
func sum(vars...int) int{
// ... ... //
}
func main() {
values := []int{1,2,3,-5}
fmt.Println(sum(values...))
}
// out 1
Deffered
只需要在调用普通函数或方法前加上关键字defer, 就完成了defer所需要的语法。 当**defer**语句被执行时, 跟在**defer**后面的函数会被延迟执行。 直到包含该**defer**语句的函数执行完毕时,**defer**后的函数才会被执行, 不论包含defer语句的函数是通过return正常结束, 还是由于panic导致的异常结束。 你可以在一个函数中执行多条defer语句, 它们的执行顺序与声明顺序相反defer语句经常被用于处理成对的操作, 如打开、 关闭、 连接、 断开连接、 加锁、 释放锁。 通过defer机制, 不论函数逻辑多复杂, 都能保证在任何执行路径下, 资源被释放。 释放资源的defer应该直接跟在请求资源的语句后, 类似于with
defer语句中的函数会在**return**语句更新返回值变量后再执行, 又因为在函数中定义的匿名函数可以访问该函数包括返回值变量在内的所有变量, 所以, 对匿名函数采用defer机制, 可以使其观察函数的返回值
func double(x int) (result int) {
defer func() { fmt.Printf("double(%d) = %d\n", x,result) }() // ()要加 否则不执行
return x + x
}
被延迟执行的匿名函数甚至可以修改函数返回给调用者的返回值
func triple(x int) (result int) {
defer func() { result += x }()
return double(x)
}
在循环体中的defer语句需要特别注意, 因为只有在函数执行完毕后, 这些被延迟的函数才会执行。 下面的代码会导致系统的文件描述符耗尽, 因为在所有文件都被处理之前, 没有文件会被关闭
for _, filename := range filenames {
f, err := os.Open(filename)
if err != nil {
return err
}
defer f.Close() // NOTE: risky; could run out of file
descriptors
// ...process f…
}
Panic异常
Go的类型系统会在编译时捕获很多错误, 但有些错误只能在运行时检查, 如数组访问越界、空指针引用等。 这些运行时错误会引起painc异常
当
panic异常发生时, 程序会中断运行, 并立即执行在该**goroutine**( 可以先理解成线程, 在第8章会详细介绍) 中被延迟的函数(**defer **机制) 。 随后, 程序崩溃并输出日志信息。 日志信息包括panic value和函数调用的堆栈跟踪信息。panic value通常是某种错误信息。 对于每个goroutine, 日志信息中都会有与之相对的, 发生panic时的函数调用堆栈跟踪信息。 通常, 我们不需要再次运行程序去定位问题, 日志信息已经提供了足够的诊断依据。 因此, 在我们填写问题报告时, 一般会将panic异常和日志信息一并记录
panic: runtime error: index out of range [6] with length 4
goroutine 1 [running]:
main.main()
/root/Golang/src/f.go:15 +0x1d
panic函数接受任何值作为参数。 当某些不应该发生的场景发生时, 我们就应该调用panic。 比如, 当程序到达了某条逻辑上不可能到达的路径
switch s := suit(drawCard()); s {
case "Spades": // ...
case "Hearts": // ...
case "Diamonds": // ...
case "Clubs": // ...
default:
panic(fmt.Sprintf("invalid suit %q", s)) // Joker?
}
断言函数必须满足的前置条件是明智的做法, 但这很容易被滥用。 除非你能提供更多的错误信息, 或者能更快速的发现错误, 否则不需要使用断言, 编译器在运行时会帮你检查代码 panic一般用于严重错误, 如程序内部的逻辑不一致
if err != nil {
panic(err)
}
return re
}
Recover异常捕获
如果在deferred函数中调用了内置函数recover, 并且定义该defer语句的函数发生了panic异常, recover会使程序从panic中恢复, 并返回panic value。 导致panic异常的函数不会继续运行, 但能正常返回。 在未发生panic时调用recover, recover会返回nil
func main() {
defer func() {
p := recover() // 捕获异常
if p != nil {
fmt.Println(1)
}else {
fmt.Println(0)
}
}() // 异常捕获
panic("test") // 触发一个panic 类似于py里的raise
}
// out 1
不加区分的恢复所有的
panic异常, 不是可取的做法; 因为在panic之后, 无法保证包级变量的状态仍然和我们预期一致。 比如, 对数据结构的一次重要更新没有被完整完成、 文件或者网络连接没有被关闭、 获得的锁没有被释放。 此外, 如果写日志时产生的panic被不加区分的恢复, 可能会导致漏洞被忽略

若有收获,就点个赞吧
0 人点赞
