整理自 https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes https://github.com/fengdu78/deeplearning_ai_books
什么是机器学习 (What is Machine Learning)
第一个机器学习的定义来自于Arthur Samuel。他定义机器学习为,在进行特定编程的情况下,给予计算机学习能力的领域。
另一个年代近一点的定义,由Tom Mitchell提出,来自卡内基梅隆大学,Tom定义的机器学习是,一个好的学习问题定义如下,他说,一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。
监督学习 (Supervised Learning)
监督学习指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成。
回归问题 (Regression)
回归 这个词的意思是,我们在试着推测出这一系列 连续 值属性。
分类问题 (Classification)
无监督学习 (Unsupervised Learning)
无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。
无监督学习算法可能会把这些数据分成两个不同的簇,叫做 聚类 算法。
线性回归 (Linear Regression)
模型表示 (Model Representation)

因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
代价函数 (Cost Function)

我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得代价函数最小。
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。
我们真正需要的是一种有效的算法,能够自动地找出这些使代价函数取最小值的参数 和
和 来。
来。
梯度下降 (Gradient Descent)

梯度下降是一个用来求函数最小值的算法
梯度下降背后的思想是:开始时我们随机选择一个参数的组合,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。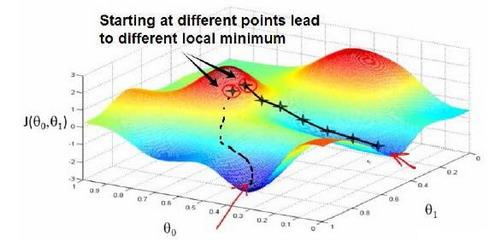
学习率 (learning rate)
它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。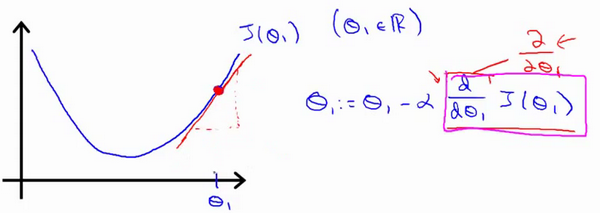
如果太小的话,可能会很慢,因为它会一点点挪动,它会需要很多步才能到达全局最低点。
如果太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,下一次迭代又移动了一大步,越过一次,又越过一次,一次次越过最低点,直到你发现实际上离最低点越来越远,所以,如果太大,它会导致无法收敛,甚至发散。
逻辑回归 (Logistic Regression)
Sigmoid function
逻辑回归模型的假设是: 
其中: 代表逻辑函数( logistic function )是一个常用的逻辑函数为 S 形函数( Sigmoid function ),公式为:
代表逻辑函数( logistic function )是一个常用的逻辑函数为 S 形函数( Sigmoid function ),公式为:  。
。
该函数的图像为: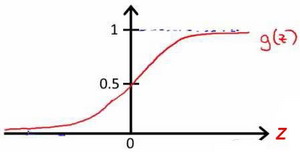
正则化 (Regularization)
Overfitting
过拟合问题
若给出一个新的值使之预测,它将表现的很差,是过拟合。虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好。
支持向量机 Support Vector Machine
一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。
聚类 Clustering
在非监督学习中,我们需要将一系列无标签的训练数据,输入到一个算法中,然后我们告诉这个算法,快去为我们找找这个数据的内在结构给定数据。我们可能需要某种算法帮助我们寻找一种结构。
K-Means Algorithm
K-均值是一个迭代算法,假设我们想要将数据聚类成n个组,其方法为:
首先选择k个随机的点,称为聚类中心(cluster centroids)。
对于数据集中的每一个数据,按照距离个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类。
计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置。
重复步骤2-4直至中心点不再变化。
异常检测 (Anomaly Detection)
高斯分布/正态分布 (Gaussian Distribution)
多元高斯分布 (Multivariate Gaussian Distribution)
假使我们有两个相关的特征,而且这两个特征的值域范围比较宽,这种情况下,一般的高斯分布模型可能不能很好地识别异常数据。其原因在于,一般的高斯分布模型尝试的是去同时抓住两个特征的偏差,因此创造出一个比较大的判定边界。
推荐系统 (Recommender Systems)
基于内容的推荐系统 (Content Based Recommendations)
在一个基于内容的推荐系统算法中,我们假设对于我们希望推荐的东西有一些数据,这些数据是有关这些东西的特征。
协同过滤 (Collaborative Filtering)
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数。相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征。

若有收获,就点个赞吧
0 人点赞
