索引结构
二叉树:
- 缺点:如果是自增索引,则二叉树会退化成链表。
红黑树:
- 缺点:树的高度不可控,百万级数据的表,如果是红黑树的高度会很高,查询效率会很慢。
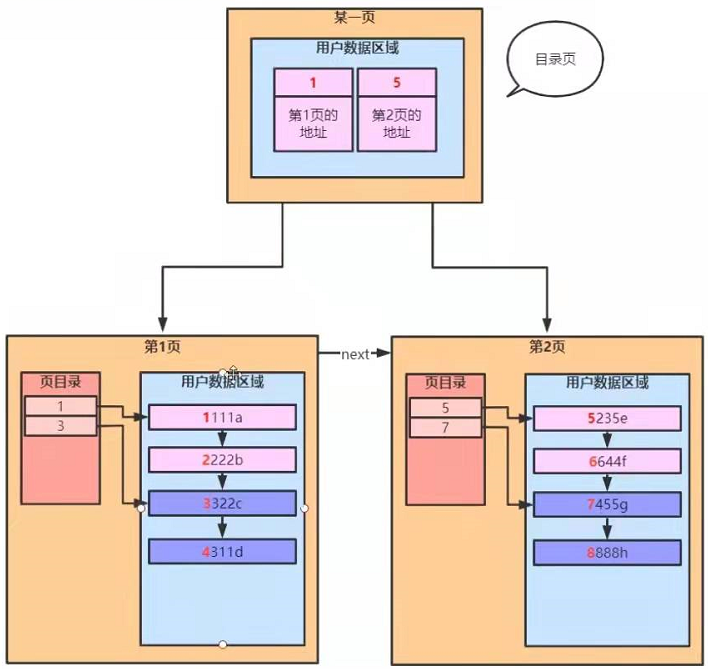
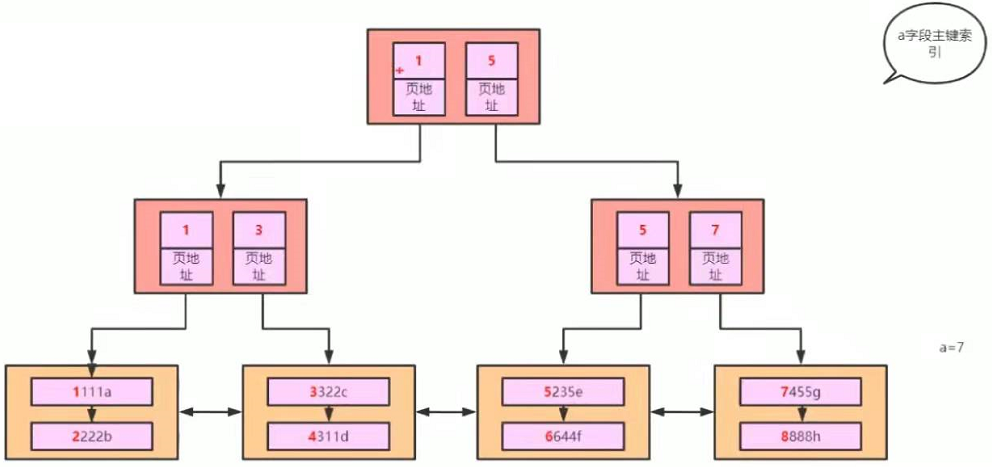
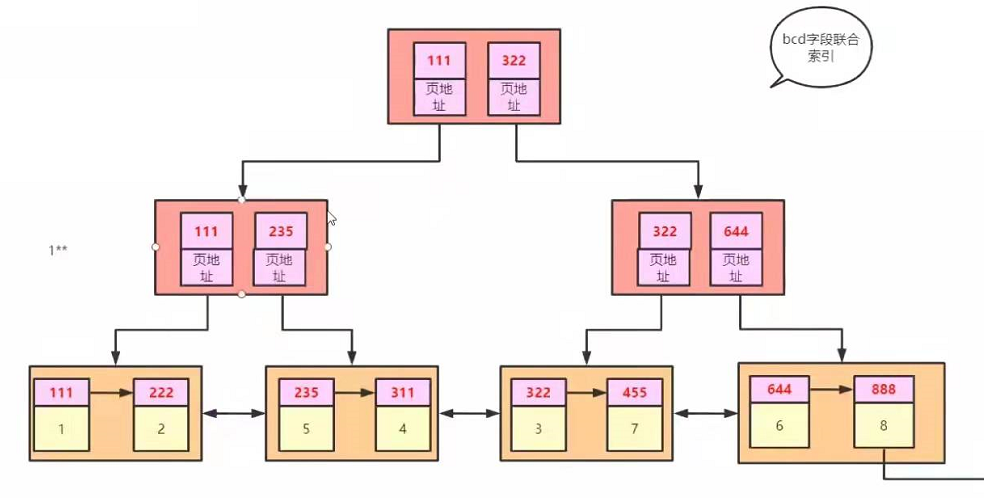
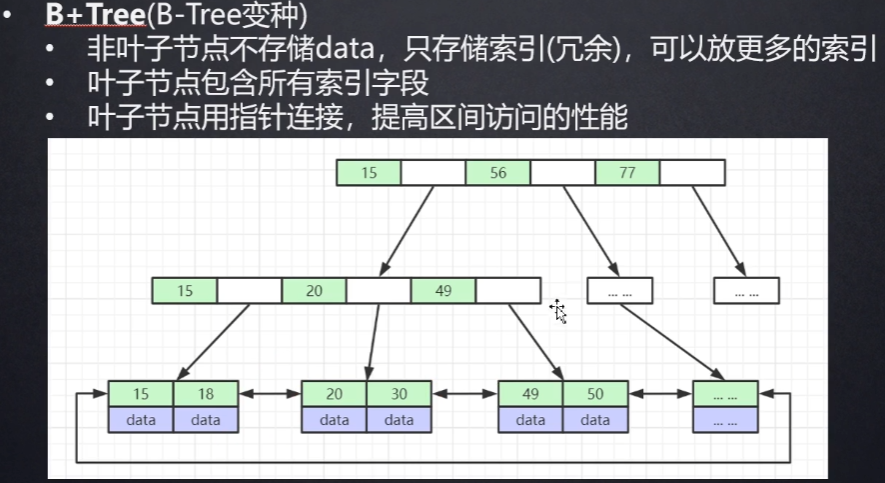
索引结构:B+树
B+树的特点:
- 排好序
- 每个节点都可以存储多个元素
- 叶子节点之间有指针
- 非叶子节点在叶子节点上都冗余一份
Innodb页
页的本质就是一块16KB大小的存储空间,InnoDB为了不同的目的而把页分为不同的类型,其中用于存放记录的页也称为数据页,我们先看看这个用于存放记录的页长什么样。数据页代表的这块16KB大小的存储空间可以被划分为多个部分,不同部分有不同的功能,各个部分如图所示: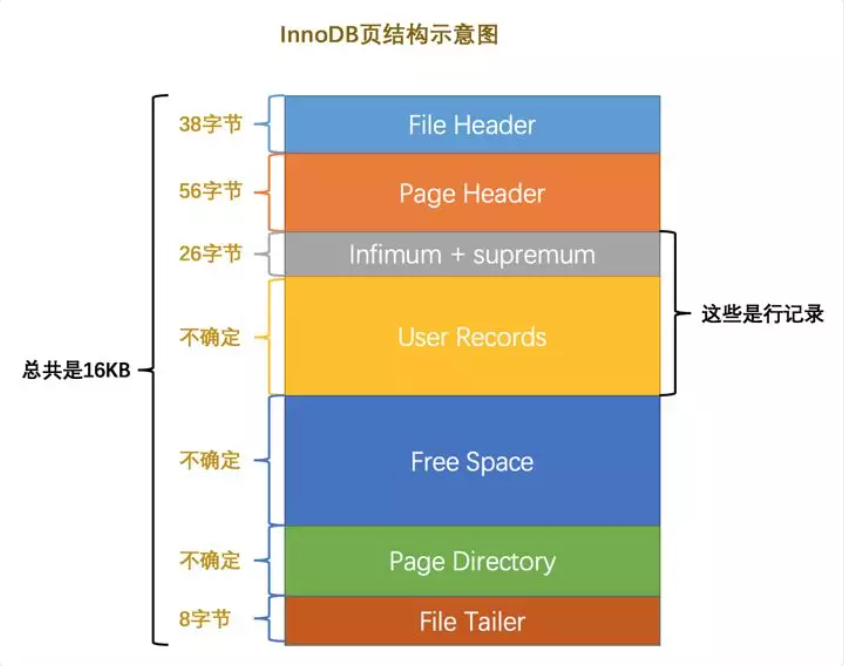
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| FileHeader | 文件头 | 38字节 | 描述页的信息,上一页下一页地址等 |
| Page Header | 页头 | 56字节 | 页的状态信息 |
| Infimum + Supremum | 最小记录和最大记录 | 26字节 | 两个虚拟的行记录 |
| User Records | 用户记录 | 不确定 | 实际存储的行记录内容 |
| Free Space | 空闲空间 | 不确定 | 页中尚未使用的空间 |
| Page Directory | 页目录 | 不确定 | 页中的记录相对位置 |
| File Trailer | 文件结尾 | 8字节 | 结尾信息,检查数据完整性的校验和等数据 |

Buffer Pool
buffer pool是什么
- 是一块内存区域,当数据库操作数据的时候,把硬盘上的数据加载到buffer pool,不直接和硬盘打交道,操作的是buffer pool里面的数据
- 数据库的增删改查都是在buffer pool上进行,和undo log/redo log/redo log buffer/binlog一起使用,后续会把数据刷到硬盘上
-
缓冲池的作用
缓存表数据与索引数据,把磁盘上的数据加载到缓冲池,避免每次访问都进行磁盘IO,起到加速访问的作用。(磁盘读写是按页读取,一次至少读一页数据,一般是4K)
数据页
磁盘文件被分成很多数据页,一个数据页里面有很多行数据
- 一个数据页默认大小 16K
更新一行数据,实际上是把行数据所在的数据页整个加载到buffer pool中
缓存页
buffer pool中存放的数据页我们叫缓存页,和磁盘上的数据页是一一对应的,都是16KB
-
缓存页描述信息(描述信息块)
存的是数据页所属的表空间号,数据页编号,数据页地址等信息
- 放在缓存页的前面
- 每个描述信息块大小是缓存页的5%左右,大约是 1610240.05=800个字节
buffer pool初始化
- 数据库只要一启动,就会按照你设置的Buffer Pool大小,稍微再加大一点,去找操作系统申请一块内存区域,作为Buffer Pool的内存区域
- 然后当内存区域申请完毕之后,数据库就会按照默认的缓存页的16KB的大小以及对应的800个字节左右的描述数据的大小,在Buffer Pool中划分出来一个一个的缓存页和一个一个的他们对应的描述数据
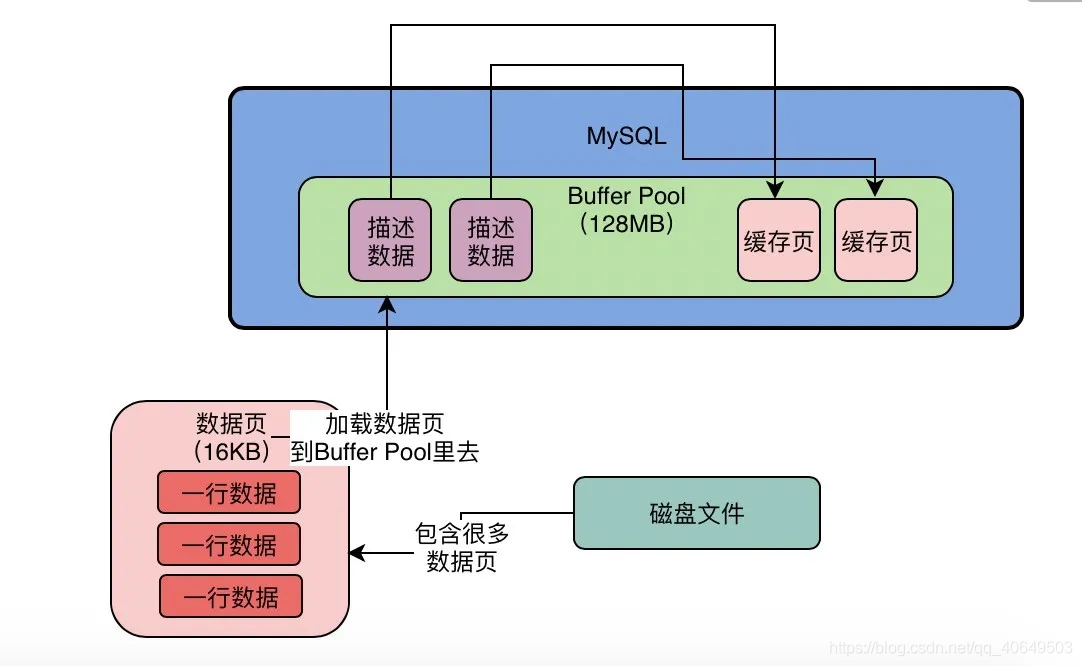
free链表
- 作用:帮助我们找到空闲的缓存页
- 是一个双向链表,链表节点是空闲的缓存页对应的描述信息块(空的缓存页)
- 链表上除了描述信息块,还有一个基础节点,存储了free链有多少个描述信息块,也就是有多少个空闲的缓存页
- 当我们加载数据的时候,会从free链中找到空闲的缓存页,把数据页的表空间号和数据页号写入描述信息块;加载数据到缓存页后,会把缓存页对应的描述信息块从free链表中移除
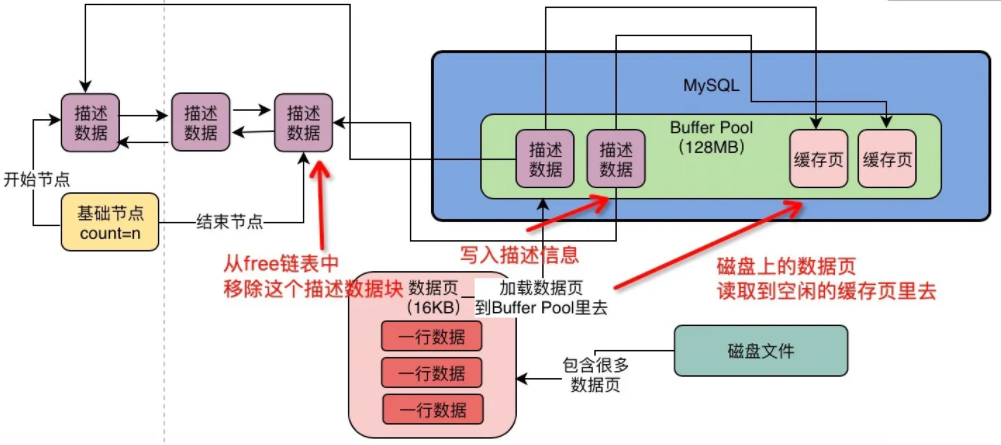
怎么知道数据页是否被缓存?
- 数据库中有一个 数据页缓存哈希表,用表空间号+数据页号,作为一个key,然后缓存页的地址作为value
-
什么是脏缓存页?
被更新过的缓存页,数据和磁盘上的数据不一致,所以是脏缓存页
-
flush链表
是一个双向链表,链表结点是被修改过的缓存页的描述信息块(更新过的缓存页)
- 作用:帮我们找到脏缓存页,也就是需要刷盘的缓存页
- 和free链表一样,也有一个基础结点,链接首尾结点,并存储了有多少个描述信息块
- 最后要把flush链表上结点对应的缓存页刷盘,后台线程会在MySQL不怎么繁忙的时候,找个时间把flush链表中的缓存页都刷入磁盘中,这样被你修改过的数据,迟早都会刷入磁盘的;缓存页从flush链表中移除,加入到free链表当中
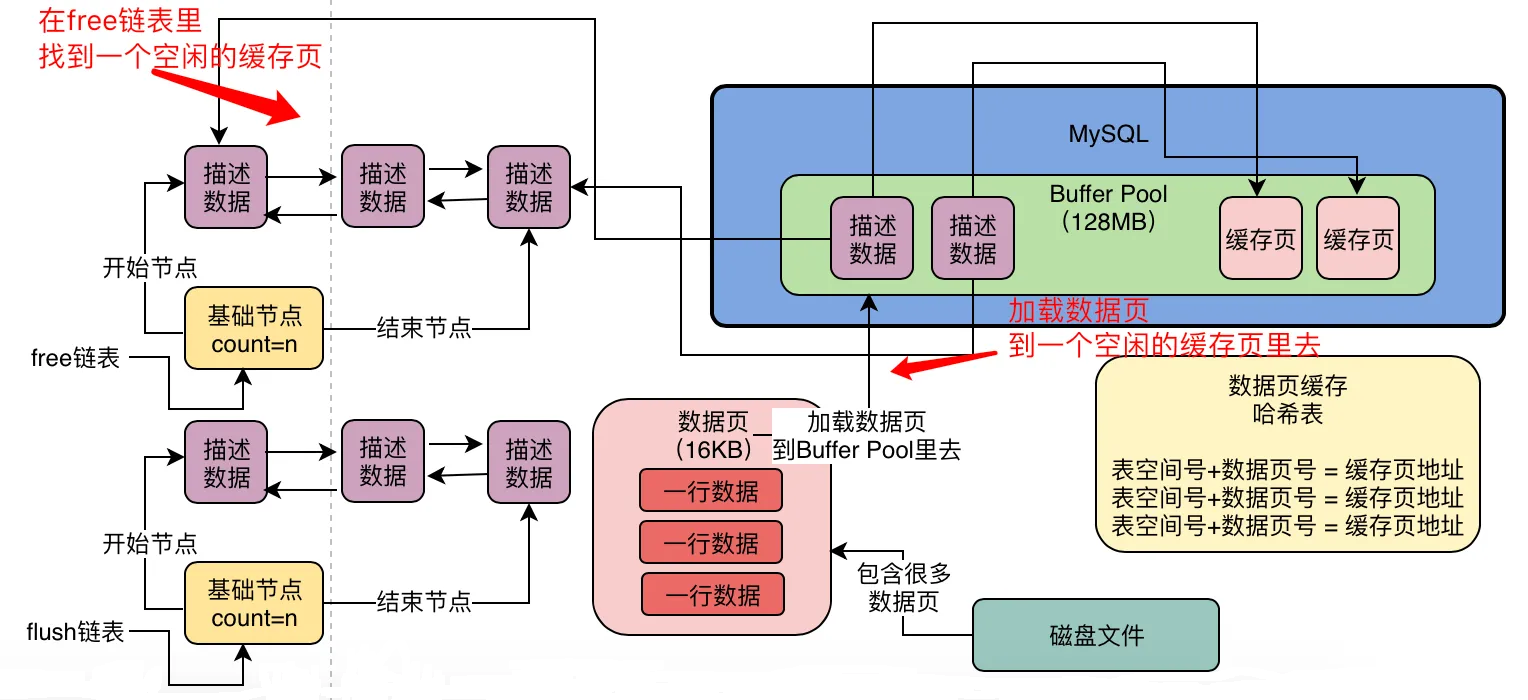
lru链表
- 是一个双向链表,链表结点是 非空的缓存页对应的描述信息块(有数据的缓存页,包含更新过和未更新过的缓存页,范围比flush链表大,flush链表是它的子集)
- 作用:用来淘汰不常被访问的缓存页
- LRU链表分为热数据区和冷数据区,冷数据区占了总链表的37%
- 冷数据区是不常访问的缓存页
- 热数据区是经常访问的缓存页
- 加载数据的时候,缓存页会放在冷数据区的头部
- 数据页加载到缓存页后,在1s之后,访问该缓存页,该缓存页会被移动到热数据区头部
- 数据页刚加载到缓存页后,在1s之内,访问该缓存页,该缓存页是不会被移动到热数据区头部的
- 什么时候会lru中的缓存页刷盘并清空?
- 当缓存页用完的时候,把冷数据区尾部的缓存页刷盘清空,缓存页对应的信息描述块从lru链表中移除,加入到free链表当中
有一个后台线程,他会运行一个定时任务,这个定时任务每隔一段时间就会把LRU链表的冷数据区域的尾部的一些缓存页,刷入磁盘里去,清空这几个缓存页,把他们加入回free链表去;如果该缓存页也在flush链表中(该缓存页更新过),也需要把该缓存页从flush链表中移除。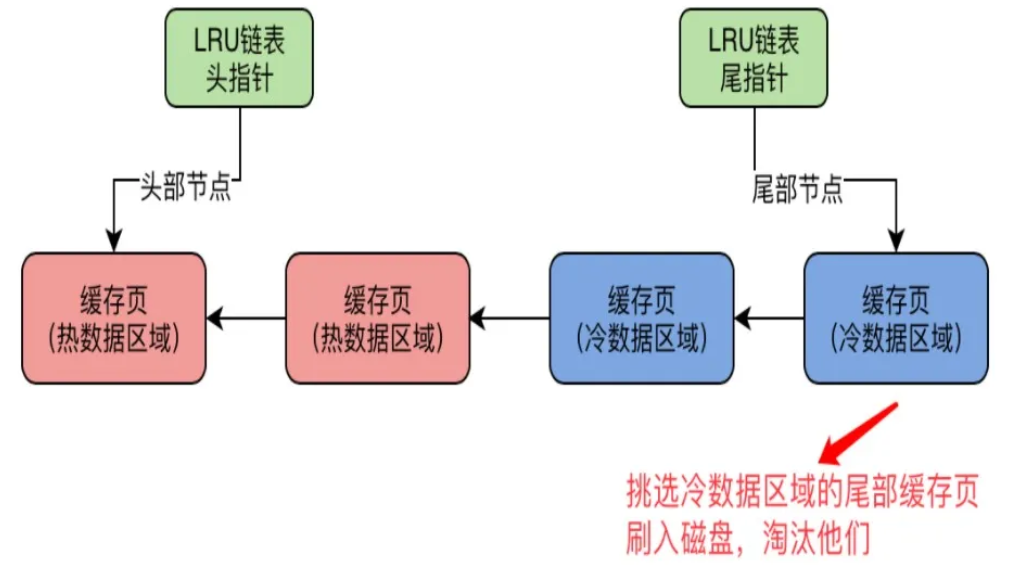
预读机制
- 所谓预读机制,说的就是当你从磁盘上加载一个数据页的时候,他可能会连带着把这个数据页相邻的其他数据页,也加载到缓存里去
- 什么时候会触发预读机制?
- 有一个参数是innodb_read_ahead_threshold,他的默认值是56,意思就是如果顺序的访问了一个区里的多个数据页,访问的数据页的数量超过了这个阈值,此时就会触发预读机制,把下一个相邻区中的所有数据页都加载到缓存里去
- 如果Buffer Pool里缓存了一个区里的13个连续的数据页,而且这些数据页都是比较频繁会被访问的,此时就会直接触发预读机制,把这个区里的其他的数据页都加载到缓存里去
- 全表扫描的时候,select * from tableName 会把该表所有的数据页都缓存到buffer pool当中
mysql启动流程
- 数据库启动时,会申请内存创建buffer pool,buffer pool分成一个个缓存页及其缓存页描述信息块,描述信息块加入到free链表中
- 数据加载到一个缓存页,free链表里会移除这个缓存页,然后lru链表的冷数据区域的头部会放入这个缓存页
- 如果查询了一个缓存页,那么此时就会把这个缓存页在lru链表中移动到热数据区域去,或者在热数据区域中也有可能会移动到头部去
- 如果更新了缓存页,会把该缓存页加入到flush链表中
- 如果缓存页不够用了,会把lru冷数据区尾部的缓存页刷盘,清空;该缓存页从lru链表和flush链表中移除,加入到free链表中
- mysql后台线程也会定时把lru冷数据区尾部的缓存页刷盘,清空;定时把flush链表中的缓存页刷盘,清空,加入到free链表中
redo log(重做日志,是InnoDB存储引擎层的日志)
bin log(归档日志,是MySQL Server层记录的日志)记录的是sql,主从会用到
binlog 用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。
binlog 是 mysql的逻辑日志,并且由 Server 层进行记录,使用任何存储引擎的 mysql 数据库都会记录 binlog 日志。
- 逻辑日志:可以简单理解为记录的就是sql语句 。
- 物理日志:mysql 数据最终是保存在数据页中的,物理日志记录的就是数据页变更 。
binlog 是通过追加的方式进行写入的,可以通过max_binlog_size 参数设置每个 binlog文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。
binlog使用场景:在实际应用中, binlog 的主要使用场景有两个,分别是 主从复制 和 数据恢复 。
- 主从复制 :在 Master 端开启 binlog ,然后将 binlog发送到各个 Slave 端, Slave 端重放 binlog 从而达到主从数据一致。
- 数据恢复 :通过使用 mysqlbinlog 工具来恢复数据。
binlog刷盘时机
mysql 通过 sync_binlog 参数控制 biglog 的刷盘时机,取值范围是 0-N:
- 0:不去强制要求,由系统自行判断何时写入磁盘;
- 1:每次 commit 的时候都要将 binlog 写入磁盘;
- N:每N个事务,才会将 binlog 写入磁盘。
binlog 日志有三种格式,分别为 STATMENT 、 ROW 和 MIXED。
undo log(回滚日志)
- update buffer pool里面的页数据—-脏页
- udpate语—->生成一个redo log —-> Log Buffer
redo log 持久化(事务提交的时候)
- 可以去配置innodb_flush_log_at_trx_commit | 配置值 | 描述 | | —- | —- | | 0 | 表示事务提交时,不立即对redo log进行持久化,这个任务交给后台线程去做 | | 1 | 表示事务提交时,立即把redo log进行持久化 | | 2 | 表示事务提交时,立即将redo log写到操作系统的缓冲区,并不会直接将redo log进行持久化,这种情况下,如果数据库挂了,但是操作系统没挂,那么事务的持久性还是可以保证的。 |
bin log 持久化
- undo log 反向操作
- 修改成功
存储引擎(针对表)
mylsam
保持在磁盘上的文件为:
.frm 存储表结构
.MYD 存储表数据
.MYI 存储表索引
叶子节点保存的是磁盘数据的地址
非聚集索引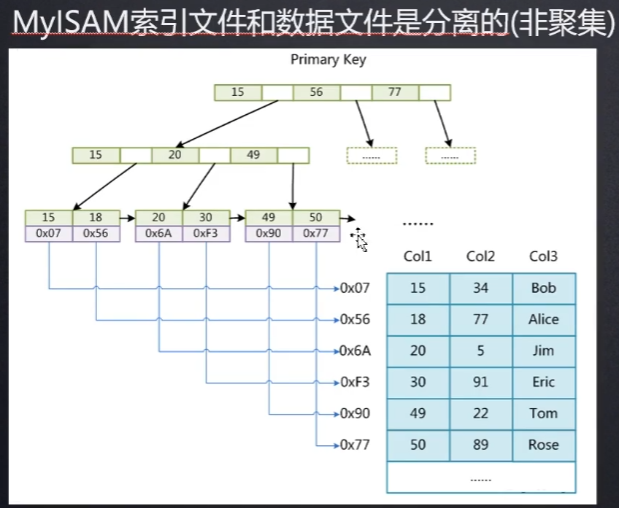
innodb
保持在磁盘上的文件为:
.frm 存储表结构
.ibd 存储表数据和索引
叶子节点保存的是所有的列数据
聚集索引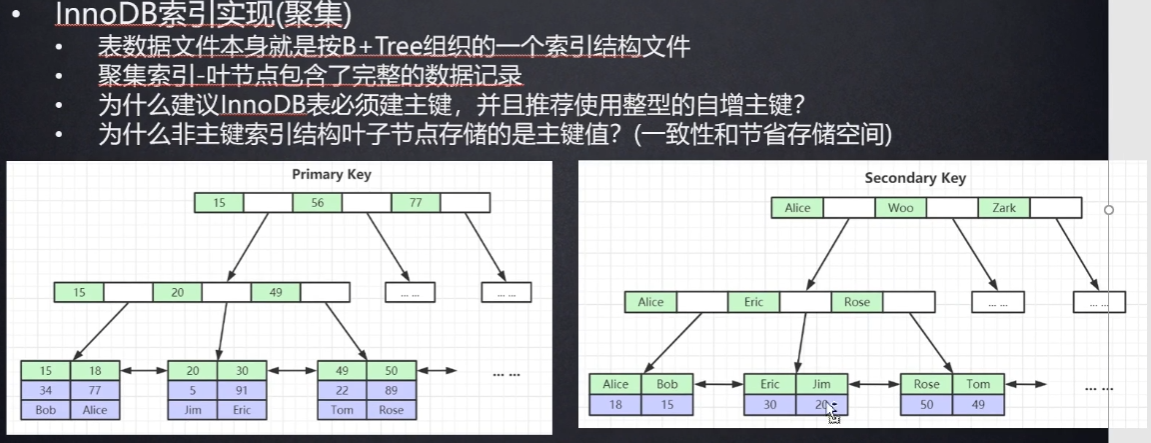
为什么建议innodb表建立主键?
因为主键自带索引,会去构建b+树,如果不建索引会去所有列中寻找不重复的列,添加唯一索引,构建b+树,组织整张表的所有数据。如果没有找到会去维护一个隐藏列去构建b+数,组织整张表的所有数据。
为什么推荐使用整型的自增主键?
因为索引是要排序的数据结构,使用自增的主键,索引构建时按顺序在每一页上构建就ok了。
hash索引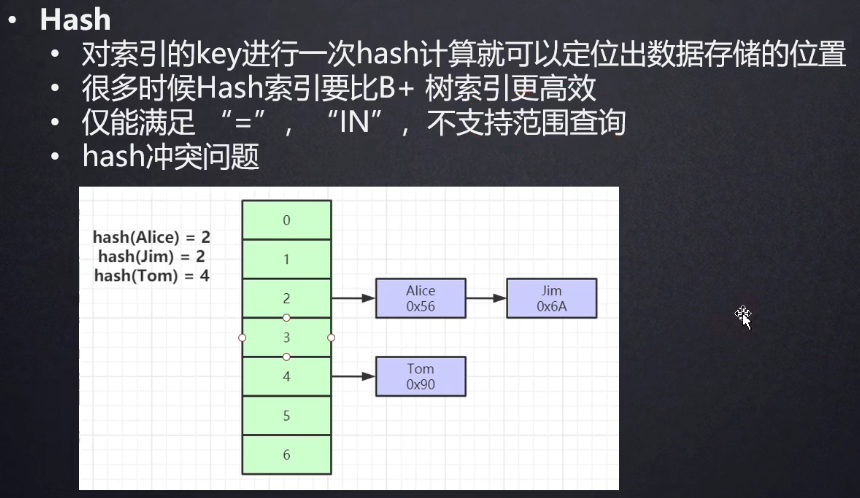
慢查询如何优化?

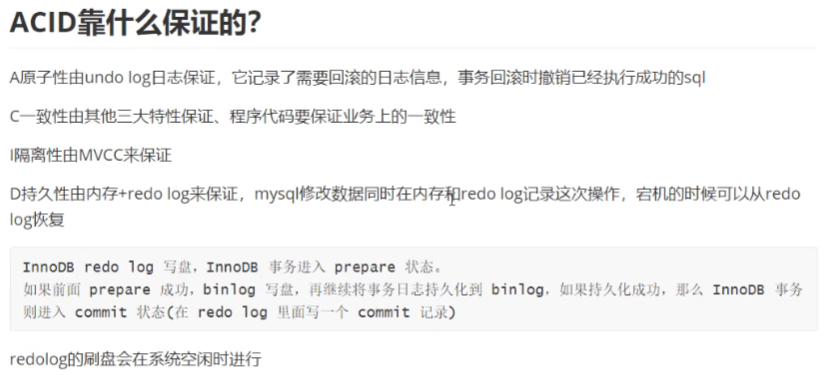
ACID靠什么保证的?
MVCC




mysql主从同步


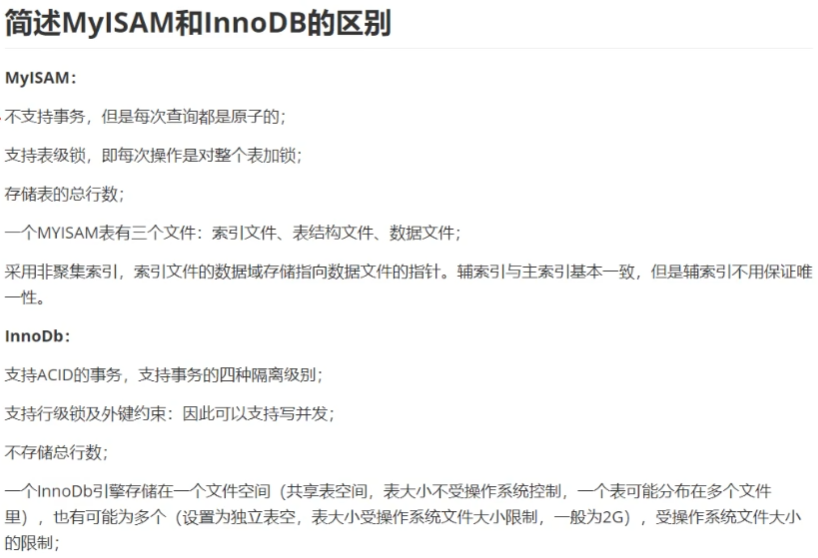
简述MyISAM和InnoDB的区别

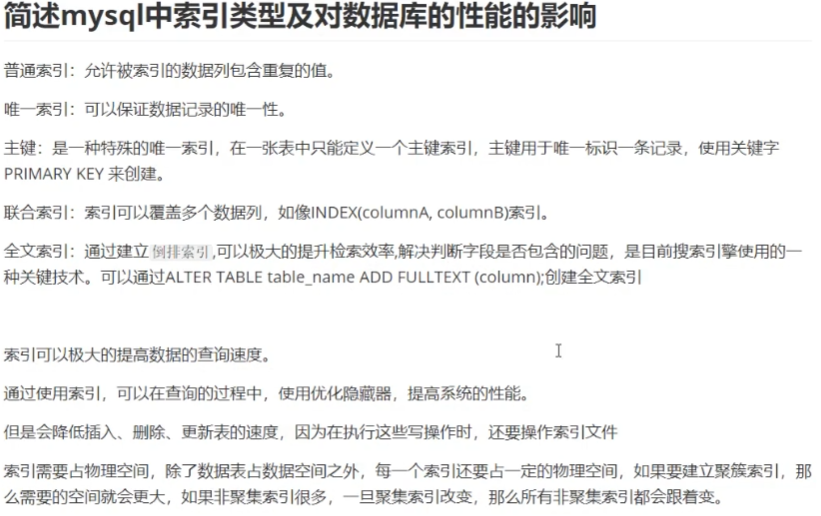
简述mysql中索引类型及对数据库性能的影响

若有收获,就点个赞吧
0 人点赞
