了解ES:
是非常强大的开源搜索引擎,可以帮助我们从海量
数据中快速找到需要的内容。
海量数据找到我们需要的数据:
就比如说你上淘宝搜索手机,就会出现很多手机品牌
以及很多手机厂商
基础概念:
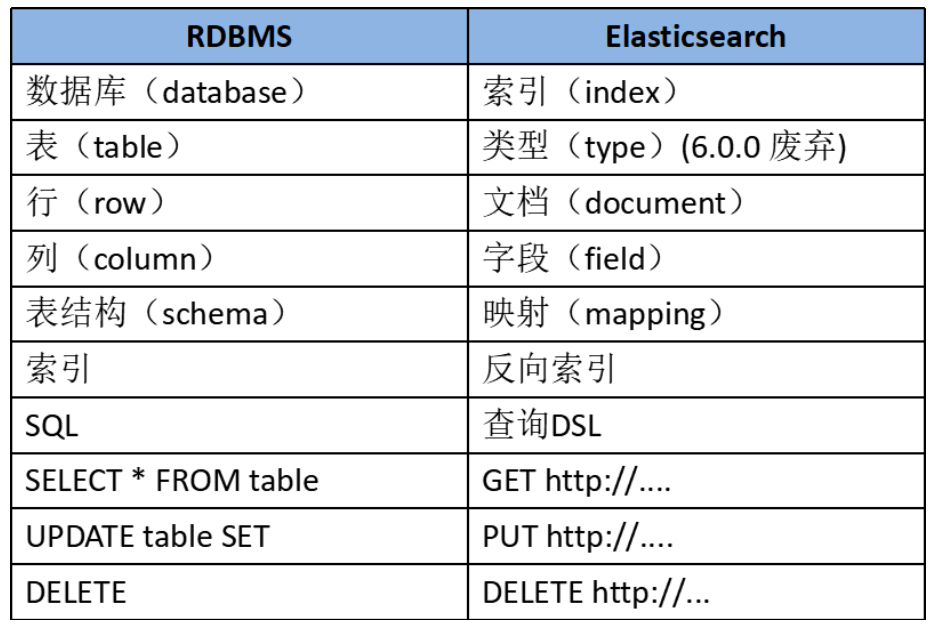
我们还需对比结构化数据库,看看ES的基础概念,为我们后面学习作铺垫。
- Near Realtime(NRT) 近实时。数据提交索引后,立马就可以搜索到。
- Cluster 集群,一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具有相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。
- Node 节点:存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。
- Index 索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。
- Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。
- Document 文档:被索引的一条数据,索引的基本信息单元,以JSON格式来表示。
- Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。
- Replication 备份: 一个分片可以有多个备份(副本
ES结合了Kibana,Logstash,Beats,也就是elastic stack(ELK)
被广泛应用在日志数据分析实时监控等领域
日志库分析:
就在我们项目运行的时候会有海量的日志信息
日志信息就是可以方便定位BUG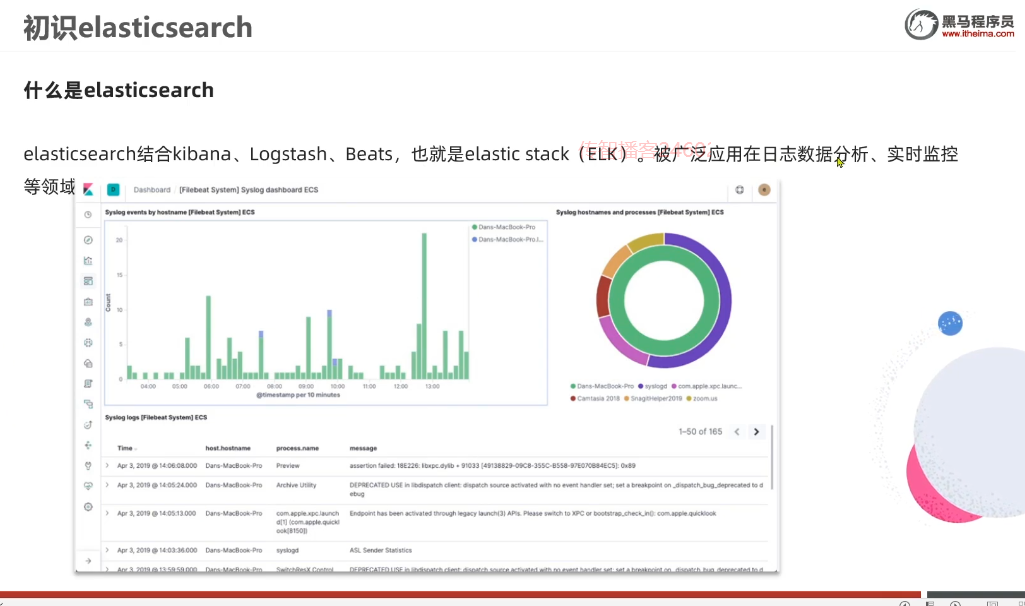
实时监控:
就是说我们项目在运行的时候他会有状态
cpu,内存,这些等等的情况

底层实现是Lucene的技术
那么什么叫类库呢?
就是jar包
我可以基于它做一些扩展
高性能(基于排序索引)
Lucene的缺点:
只限于java语言开发
学习曲线陡峭
不支持水平扩展

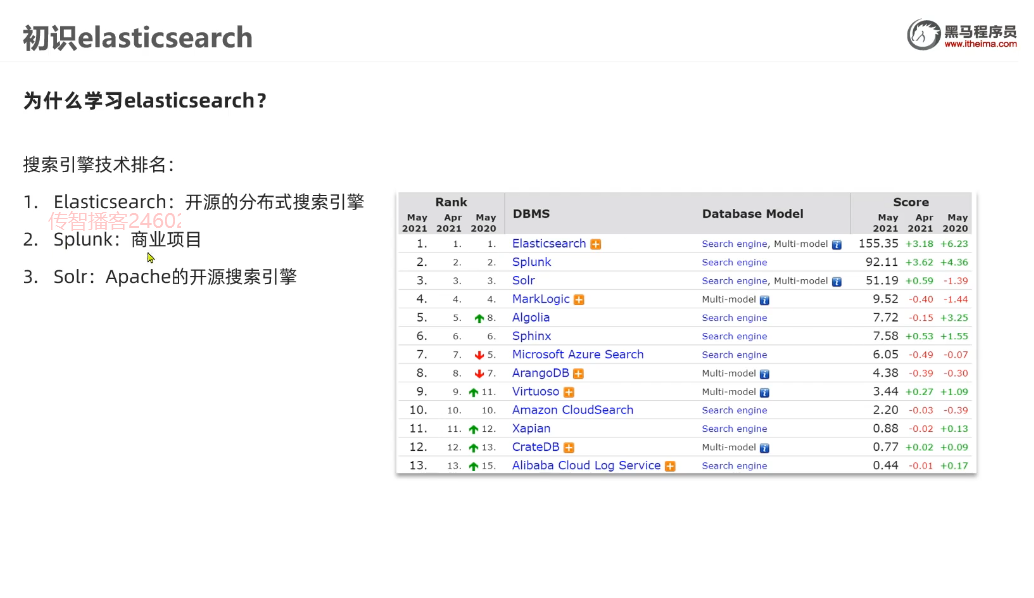
总结:
什么是elasticsearch?
一个开源的分布式搜索引擎,可以作为扩展形成集群
可以用来实现搜索,日志统计,分析监控等功能
什么是elastic stack(ELK)?
是以elasticsearch 为核心的技术栈,
包括 beats Logstash
kibana elasticsearch
什么是Lucene?
是Apache的开源搜索引擎类库 提供了搜索引擎的核心API
(就是一个jar包)

若有收获,就点个赞吧
0 人点赞
