DSL(查询文档):
DSL是基于JSON风格的查询语句
查询所有:
查询出所有的数据,不加条件限制,但是会加分页的限制
列入:
match_all
全文检索查询:
查询利用分词器对用户输入内容分词,然后倒排索引库中匹配
例如:
match_query
multi_match_query
精确查询:
根据精确词条值查询数据,一般查找keyword 数值 日期
boolean等类型字段例如:
共同: 不用进行分词
但是回去建立倒排索引,内容整体存入词条
例如:
ids :根据ID匹配
range :根据数值范围查询
trem :按照数据的值进行查询
地理(geo)查询根据经纬度查询例如:
geo_distance
geo_bounding_box
复合查询:
它本身没有查询条件的,将上诉的各种查询组合起来,合并查询条件
列入:
bool
function_score:算分的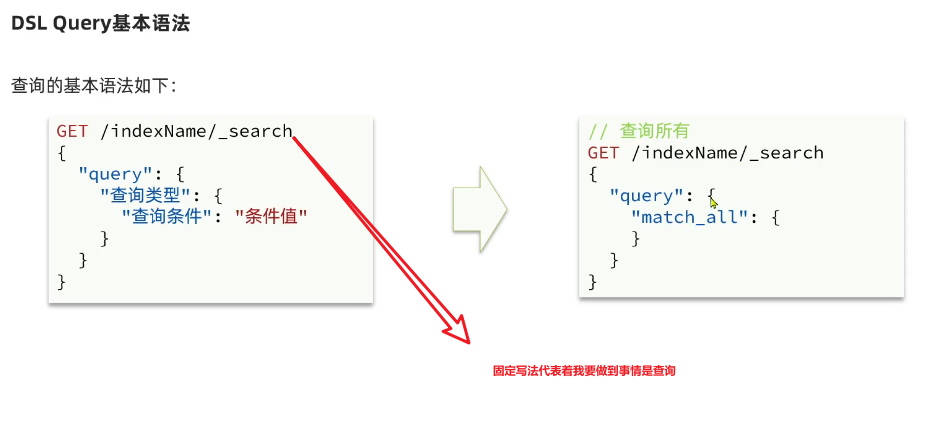
#查询所有GET /hotel/_search{"query": {"match_all": {}}}
基本语法:
全文检索查询:
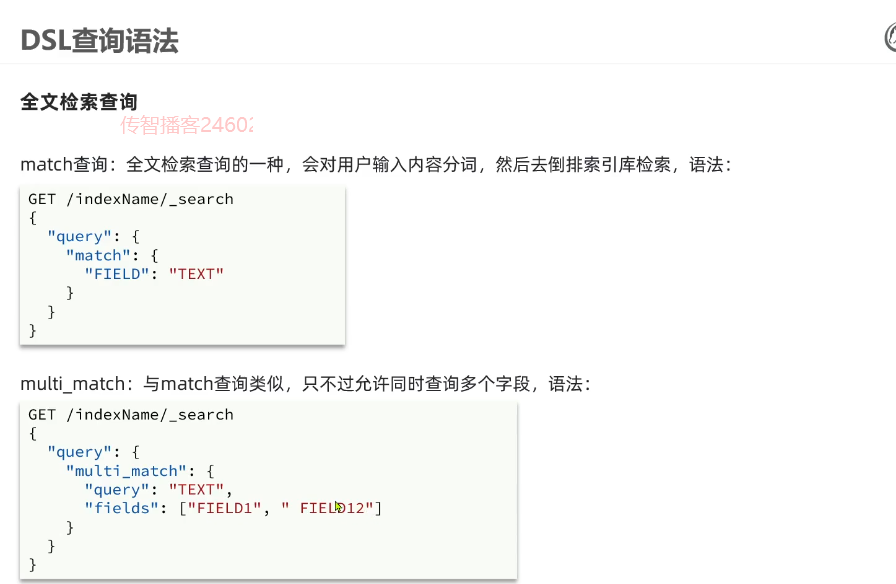
全文检索查询,会对用户输入内容分词,常用于搜索框搜索。
match查询:
#matchGET /hotel/_search{"query": {"match": {"all": "如家"}}}
#multi_matchGET /hotel/_search{"query": {"multi_match": {"query": "外滩如家","fields": ["brand","name","business"]}}}
总结:
mutch 和multi_match的区别是什么?
mutch是查询单个字段
multi_match可以数组形式查询多个字段
参与查询字段越多查询性能越差
精确查询:
精确查询一般查找keyword,数值 日期 booolean 等类型字段
所以不会多搜索条件分词 常见的有:
精确查询:
term:根据词条精确值查询
range:根据值的范围查询
#term查询GET /hotel/_search{"query": {"term": {"FIELD": {"value": "上海"}}}}
#range查询GET /hotel/_search{"query": {"range": {"price": {"gte": 100,"lte": 300}}}}
地理查询:
根据经纬度查询。常见的场景: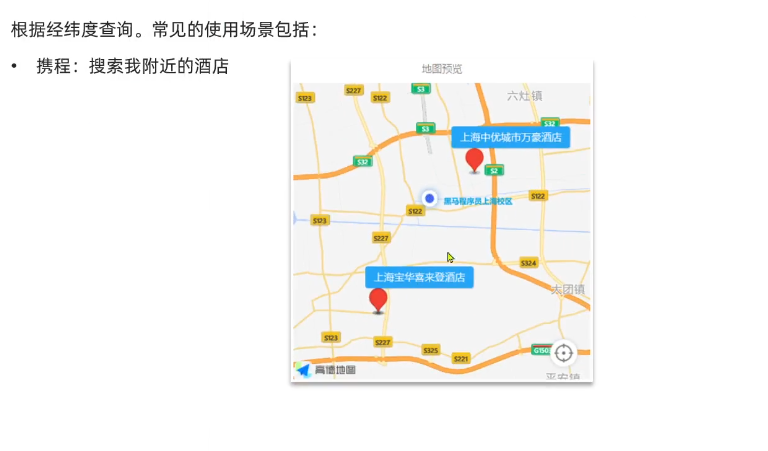
geo_bounding_box:查询geo_point值落在其中矩形范围的
所有文档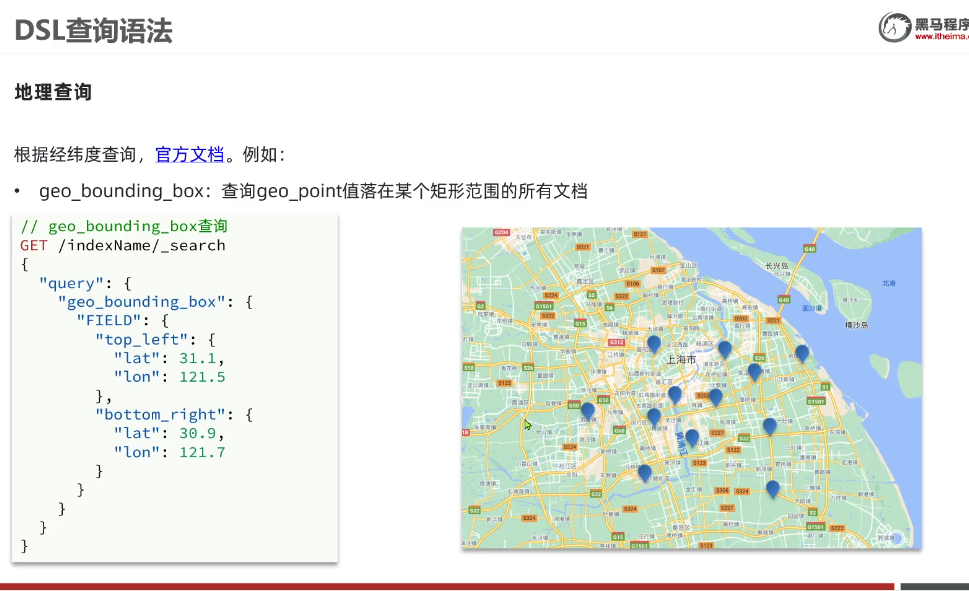
geo_distance :(相当于范围查询)查询到指定中心点小其中距离值的所有文档

#distanceGET /hotel/_search{"query": {"geo_distance":{"distance":"2km","location":"32.21,121.5"}}}
相关性算法:
复合型查询:可以将其他的简单查询组合起来实现更为复杂的查询
词条频率:




FunctionScoreQuery:控制打分
人为控制排名: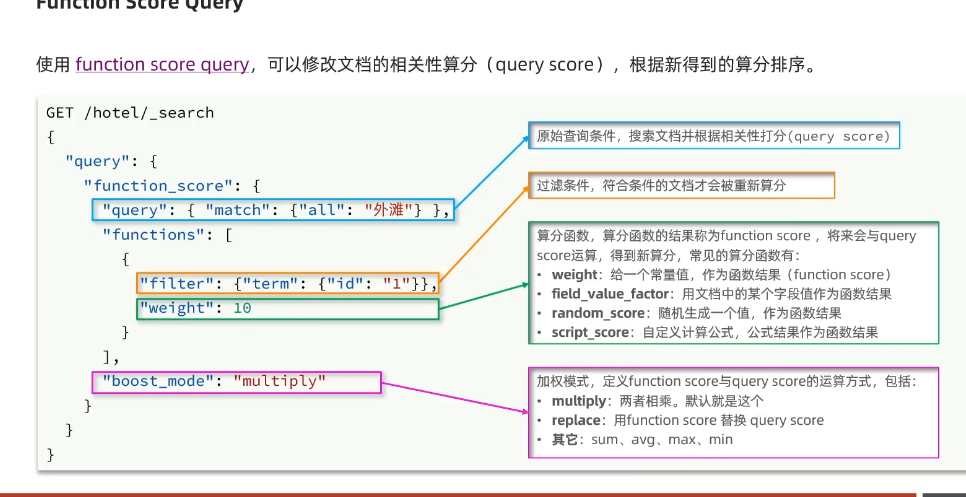
案列:
给如家这个品牌的酒店排名靠前一些:
把这个问题翻译一下 function score 需要三要素
那些文档需要算法加权?
品牌为如家酒店
算分函数是什么?
weight
加权模式是什么?
求和
#function _scoreGET /hotel/_search{"query": {"function_score": {"query": {},"functions": [{"filter": {"term": {"brand": "万怡"}},"weight": 10}],"boost_mode": "sum"}}}
过滤条件 :那些文档要加分
算分函数:如何计算 function score
加权方式;
fuction score 与 query score 如何运算
BOOLQuery(第二种符合查询)
布尔查询是一个或多个查询子句组合 子查询组合方式有:
- must:必须匹配每个子查询 类似“与”
- should:选择性匹配子查询类似“或”
- must_not: 必须不匹配 不参与算分 类似“非”
- filter:不参与算分

需求:
搜索名字包含“如家”价格不高于400
坐标在31.21,121.5周围10km范围内的酒店
#bool查询GET /hotel/_search{"query": {"bool": {"must": [{"match": {"FIELD": "TEXT"}}],"must_not": [{"range": {"price": {"gte": 400}}}],"filter": [{"geo_distance": {"distance": "10km","location": {"lat": 31.21,"lon": 121.5}}}]}}}参与算分的越多那么性能就越差


若有收获,就点个赞吧
0 人点赞
