浏览器工作原理
JavaScript 是一门高级编程语言
JavaScript 是一门高级语言,高级语言都要转换成 CPU 能识别的机器指令,所以高级语言都会有个“翻译官”,先将高级语言翻译成汇编语言,汇编语言再翻译成机器指令。
不同的 CPU 也只能执行符合自己指令集的机器指令。
JavaScript 在浏览器中是怎么被下载的?
先下载 html 文件,解析遇到了 css 标签或 script 标签才去下载对应文件。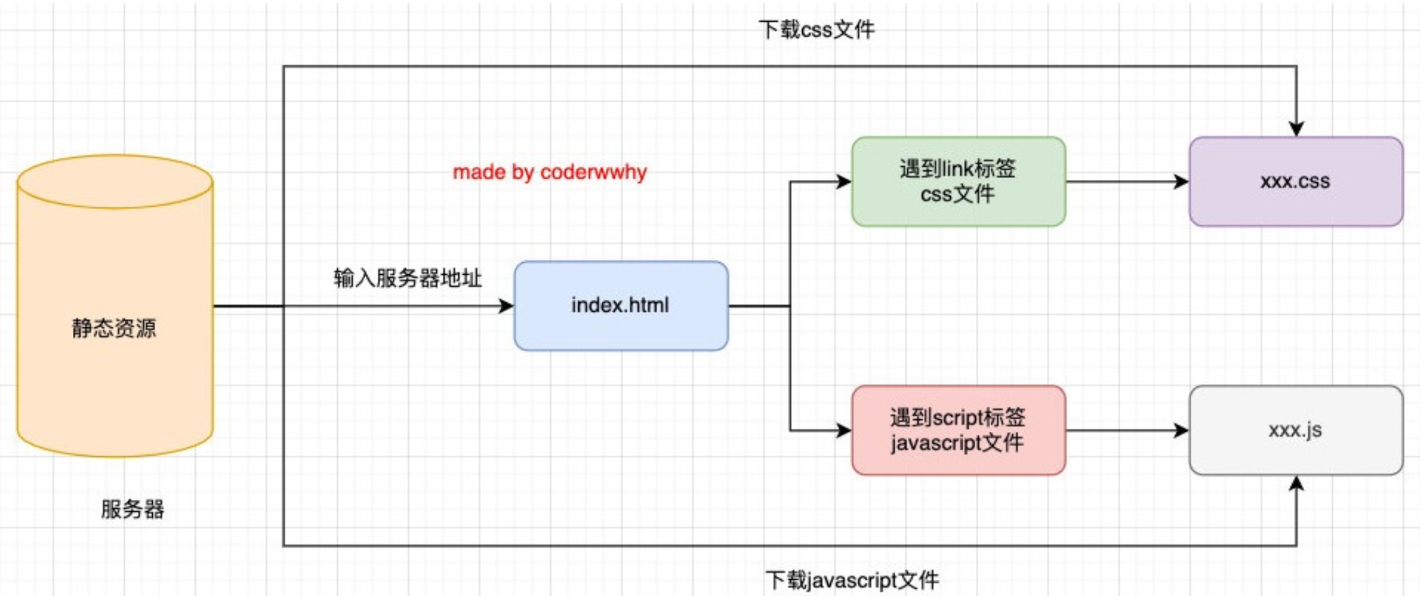
浏览器内核
浏览器内核有很多别名,都是指同一个东西:排版引擎(layout engine),也称为浏览器引擎(browser engine)、页面渲染引擎(rendering engine)或样版引擎。
- Gecko:早期被Netscape和Mozilla Firefox浏览器浏览器使用;
- Trident:微软开发,被IE4~IE11浏览器使用,但是Edge浏览器已经转向Blink;
- Webkit:苹果基于KHTML开发、开源的,用于Safari,Google Chrome之前也在使用;
- Blink:是Webkit的一个分支,Google开发,目前应用于Google Chrome、Edge、Opera等;
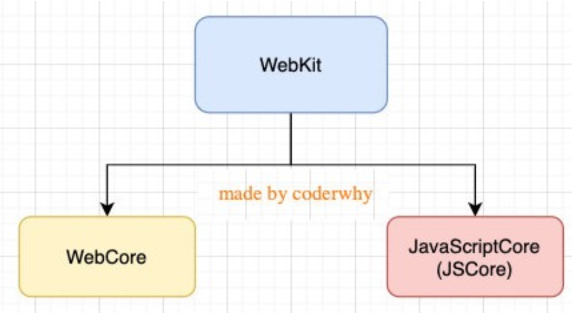
浏览器内核的组成
这里我们先以 WebKit 为例,WebKit 事实上由两部分组成的:
- WebCore:负责HTML解析、布局、渲染等等相关的工作;
- JavaScriptCore:解析、执行JavaScript代码;
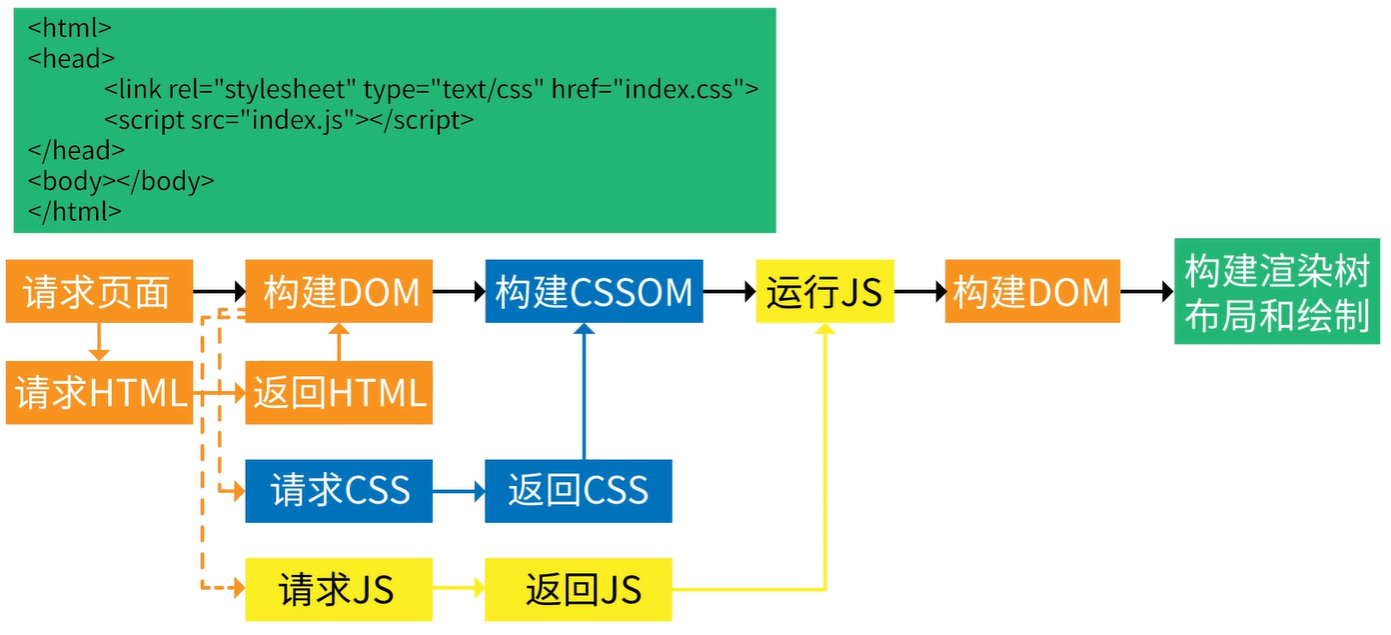
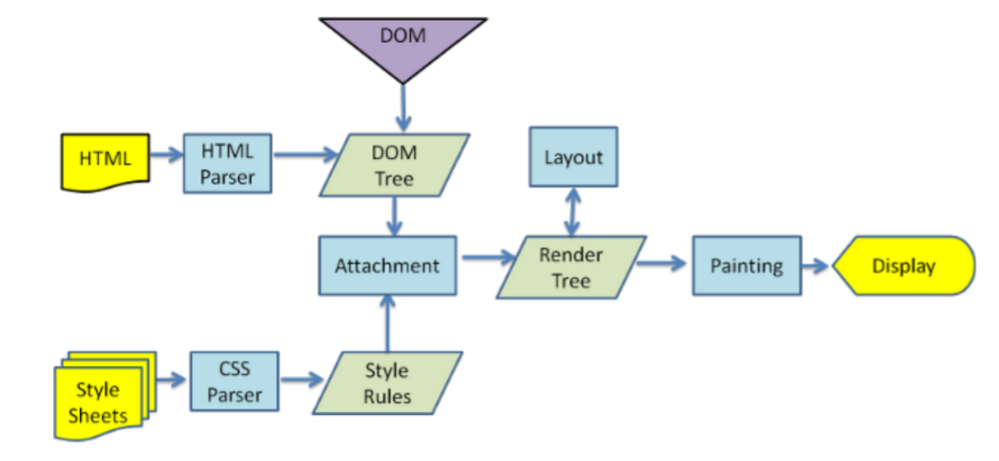
⭐浏览器渲染网页的过程
- 下载 html 文件后开始 html 解析(parser)生成 dom 树
- 碰到 css ,下载 css 文件后进行 css 解析,此时 dom 继续往下解析
- 碰到 script 标签下载 js 文件,js 引擎解析 js 对 dom 树操作,例如:创建元素
- 默认情况下 js 的解析和执行会中断 dom 的解析,除非设置了 async 或者 defer
- 注意:此时 css 的解析正在进行中,js 的解析也正在进行中,那有没有顺序呢?
- 答:解析没有顺序,但是 js 解析完后的执行,必须等到 css 构建 cssom 后才能执行。
- dom 树和样式规则融合,生成渲染树。渲染树里去掉了不用渲染的 dom,比如 meta 标签和 display: none;
- 浏览器根据自身当前情况进行 layout(布局),例如:此时浏览器窗口缩小了,页面就得重新布局。(回流)
- 最后将渲染树绘制出来展示(重绘)
V8 引擎
V8 是用 C ++ 编写的 Google 开源高性能 JavaScript 和 WebAssembly 引擎,它用于 Chrome 和 Node.js 等。
它能解析 ECMAScript 和 WebAssembly ,并在 Windows 7 或更高版本上,mac OS 10.12+ 上使用以及 x64,IA-32,ARM 或 MIPS 处理器的 Linux 系统上运行。
V8 可以独立运行,也可以嵌入到任何 C ++ 应用程序中。Node.js 中就是嵌入了一个 V8 引擎。
JIT 和 AOT
代码有两种编译运行的方式:
jit(just in time compilation)运行时编译。将代码的运行和生成机器代码的过程结合在一起。在运行阶段根据收集的类型信息生成机器码,然后直接运行生成好的机器码。js 就采用了这种方式。
aot(ahead of time)在运行前就编译生成好机器码,比如 c++
V8 引擎处理 JavaScript 的过程
引擎编译 js 的过程大致可分为 3 个阶段:
- 解析器解析成抽象语法树
- 解释器解释为字节码
- 编译器编译为机器码

上面只是一个大致的流程,各种引擎的实际表现可能不一样,比如 V8 引擎在 5.9 版本以前,就没有字节码的过程,AST 直接编译成机器码。
5.9 版本以前的 V8 引擎
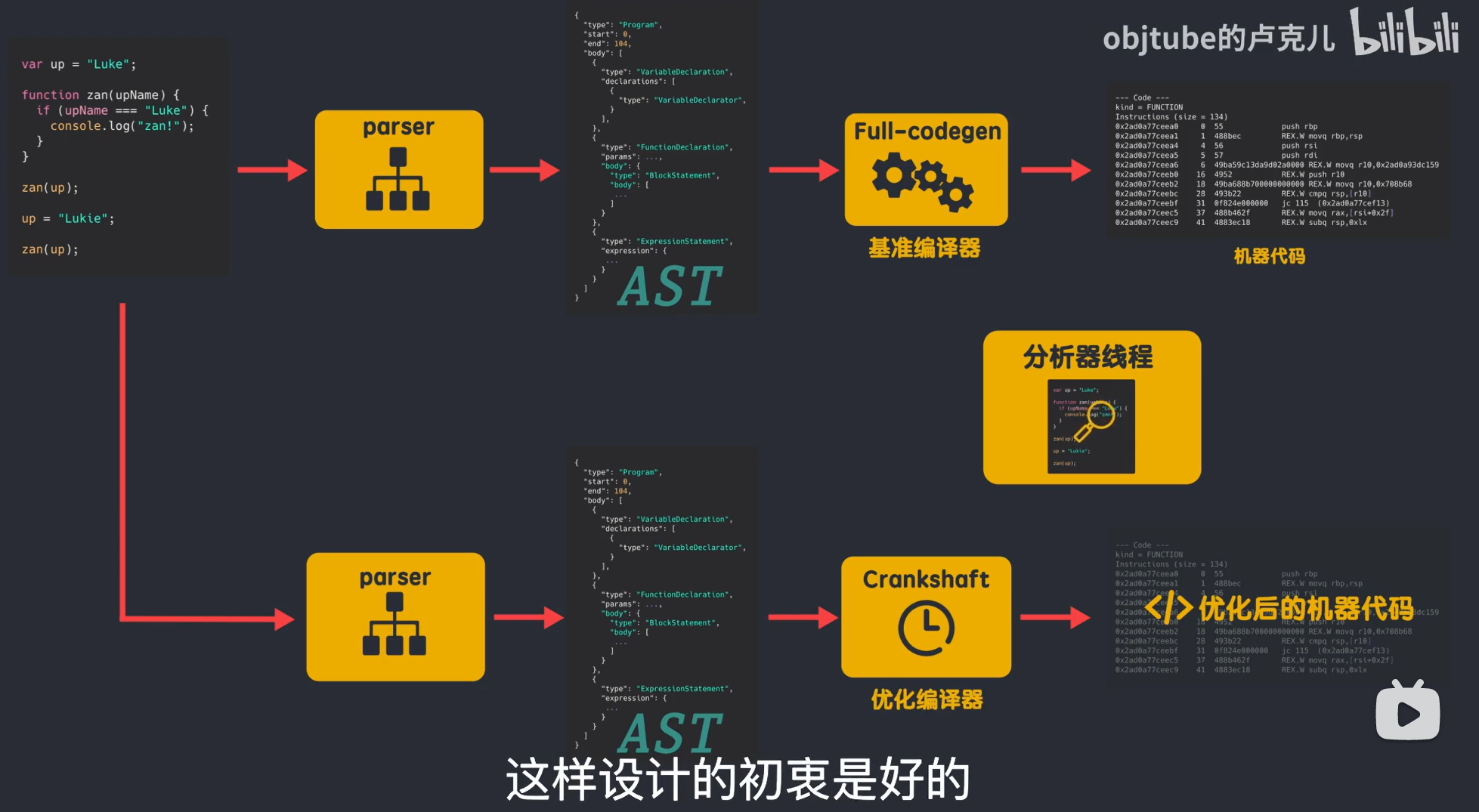
通常 js 引擎有三大组件:解析器,解释器,编译器。但是早期的 V8 没有解释器,但是却有两个编译器。(基准编译器和优化编译器)
处理过程:
- 解析器解析成 AST,AST 直接被基准编译器编译为机器码,Full-codegen 编译生成的是一个基准的未被优化的机器码,这样的好处是,第一次执行的时候没有字节码过程,速度很快。
- 当执行一段时间后,V8 引擎中的分析线程收集了足够多的信息,就会帮助另一个编译器,优化编译器 Crankshaft 来优化代码。
- 需要被优化的代码重新被解析为 AST,然后优化编译器编译成优化后的机器码
减少字节码的过程提高了效率但是带来新的问题:
- 字节码占用了太对内存空间,有些代码只执行一次,但还是生成了机器码
- 缺少中间层,无法执行一些优化策略
- 没办法优化和支持未来的 js 新语法特性
⭐采用新架构的 V8 引擎
新的架构中增加了 Ignition 解释器,将 AST 解析成字节码。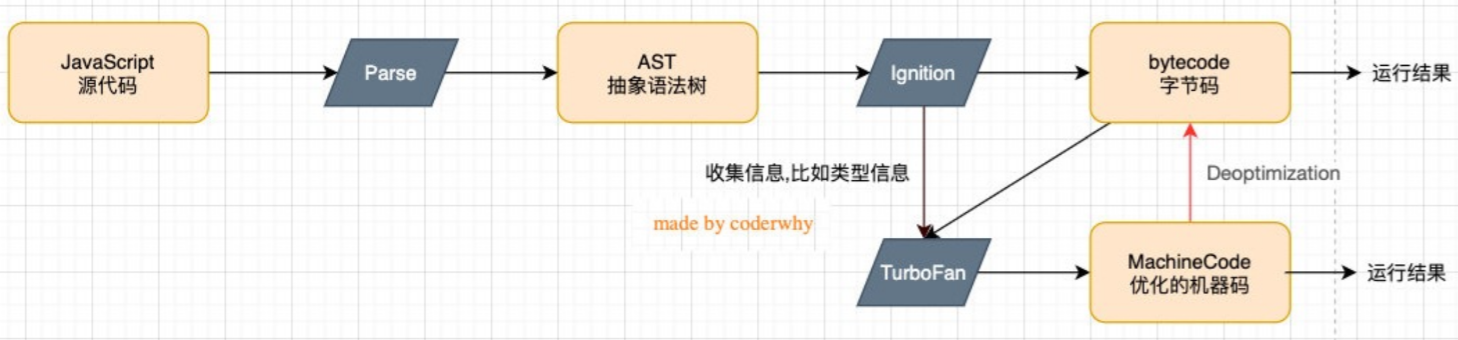
- Parse 模块 对源代码进行词法分析和语法分析,生成 AST 抽象语法树(查看抽象语法树)
- 词法分析会对代码进行切割,生成一个 tokens 数组,里面有很多对象,每个对象都包含了一个词的分析
- 语法分析对这些对象组合分析,形成抽象语法树
- 如果函数只是声明,没有被调用,那么是不会被转换成 AST 的。
- 抽象语法树结构非常固定,很易于转换,Ignition 模块是一个解释器,将 AST 转换成 bytecode 字节码文件,之后 AST 将会被释放,节省内存。
- 生成的字节码文件作为基准执行模型,字节码文件也很简洁,相当于等效的基准机器码 25-50%
- 字节码文件转成汇编指令,再转成机器码最后执行
- 在代码的不断运行过程中,解释器 Ignition 会收集到很多优化信息,比如变量类型信息和执行频率较高的函数。这些信息将会被发送给 TurboFan。
- 显然只调用一次的函数就没有进行优化的必要了,字节码将被直接解释执行。ignition 也没办法收到它的信息传给 TurboFan。
- TurboFan 模块是一个优化编译器,它根据优化信息将对应的字节码转换成机器码保存下来
- 因为这段函数代码若被多次调用,该函数将会被标记为热点函数,所以可以以空间换时间,将机器码保存下来,省去字节码转汇编再转机器码的过程,提高执行效率。
- 保存的机器码可能需要逆优化(Deoptimization)成字节码文件
- 因为 js 中函数参数类型不固定,例如:某个函数调用的参数一直是数字,突然传入字符串做参数,就会导致以数字为参数类型保存的机器码失效。这就需要重新转成字节码,再去执行了。
总结一下 V8 引擎解析编译过程的 3 个优化策略:
- 只声明的函数不会转成 AST
- 只执行一次的函数将转成字节码直接执行,不会被优化转成机器码
- 多次执行的函数将标记为热点函数优化执行
新架构的 V8 解决三个老问题外,还有三个优点:
- AST 转成字节码的时间比转成机器码的时间快很多,所以浏览器首屏渲染很快
- 优化不用从头开始,可以从字节码优化成机器码
- 字节码具有跨平台能力,不用考虑机器码的 CPU 兼容问题
官网的 V8 引擎解析图:更细化了解析(parser)过程
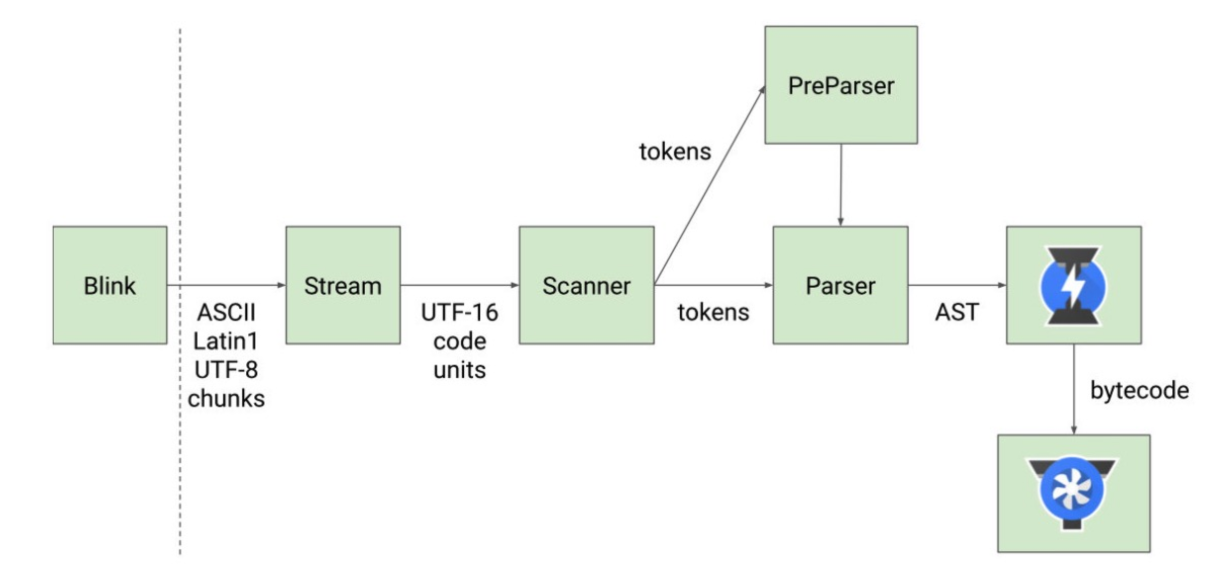
- Blink 将源码交给 V8 引擎,Stream 获取到源码并且进行编码转换;
- Scanner 会进行词法分析(lexical analysis),词法分析会将代码转换成 tokens;
- 接下来 tokens 会被转换成 AST 树,经过 Parser 和 PreParser:
- Parser 就是直接将 tokens 转成 AST 树架构;
- PreParser 称之为预解析,为什么需要预解析呢?
- 这是因为并不是所有的JavaScript代码,在一开始时就会被执行。那么对所有的JavaScript代码进行解析,必然会影响网页的运行效率;
- 所以V8引擎就实现了 Lazy Parsing(延迟解析)的方案,它的作用是将不必要的函数进行预解析,也就是只解析暂时需要的内容,而对函数的全量解析是在函数被调用时才会进行;
- 比如我们在一个函数 outer 内部定义了另外一个函数 inner,那么 inner 函数就会进行预解析;
- 生成 AST 树后,会被 Ignition 转成字节码(bytecode),之后的过程就是代码的执行过程。
代码是如何被(parse)解析的
var name = 'liu';var age = 18;function foo() { console.log(age) };foo();
parser 解析的时候 V8 引擎会在堆内存中创建一个全局对象:Global Object(GO)
- 所有的作用域(scope)都可以访问到该对象;
- 里面会包含当前运行环境的全局对象,如:Date、Array、String、Number、setTimeout、setInterval 等等;
- 其中还有一个 window 属性指向自己; ```javascript var globalObject = { String: ‘类’, Date: ‘类’, setTimeout: ‘函数’, … window: globalObject, }
GO 中除了上面这些默认的属性外,示例代码也会被解析,然后放入 GO 中,这个过程也称之为**变量的作用域提升(hoisting)。**但是放入的时候代码还没被执行,**只有在代码执行的时候才会赋值**,所以变量的值都是 undefined。```javascriptvar globalObject = {String: '类',Date: '类',setTimeout: '函数',...window: globalObject,name: undefined,age: undefined,foo: OX1000}
⭐代码是怎么被执行的
系统将代码从磁盘加载到内存中,V8 引擎会在内存中组织起两个结构,代码调用栈和堆结构
调用栈
js 引擎内部有一个执行上下文栈(Execution Context Stack,简称ECS),它是用于执行代码的调用栈。调用栈能执行全局代码和函数。
首先引擎为了执行全局代码会构建一个全局执行上下文 Global Execution Context(GEC)放入到 ECS 中 执行;
GEC 被放入到 ECS 中里面执行的时候有两部分内容:变量对象 VariableObject(VO)和全局代码。
- VO 保存的是 GO 的地址,指向了GO。
- 执行全局代码从上往下依次执行。代码执行过程,就是一个查找过程。
- 比如一条代码为修改变量的值,则引擎会通过 VO 在 GO 中查找该变量,然后修改值。
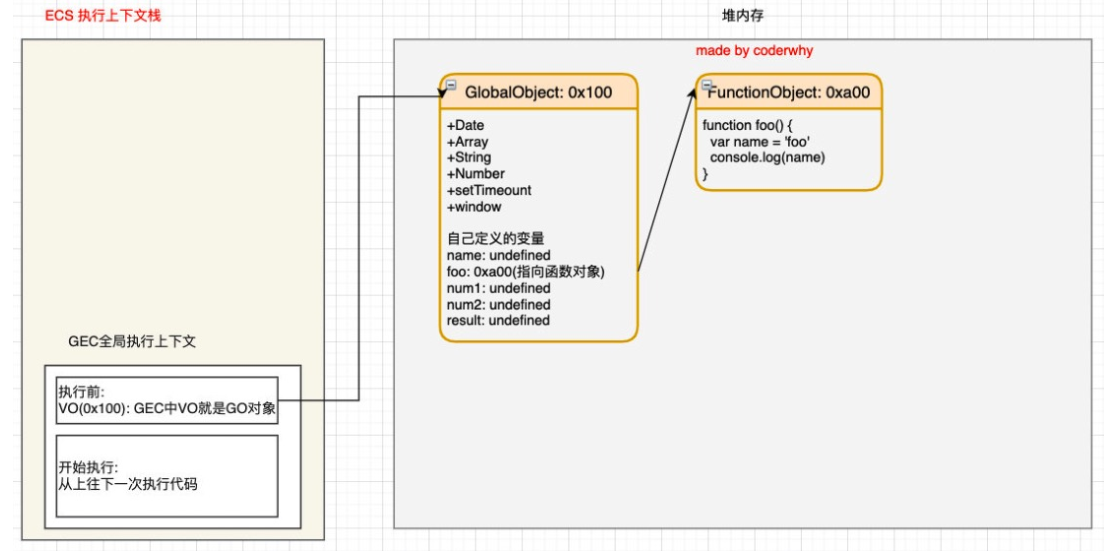
我们现在可以解释在变量声明前使用变量,为什么变量是 undefined 了? 引擎在编译阶段会创建全局对象 GO ,在这个阶段识别了变量并将它加入 GO 中,变量值都为 undefined。运行时调用变量的时候就会来 GO 中寻找这个变量,此时就会获取到 undefined。
函数是怎么被执行的
函数在声明的代码前,能正常调用,而不是像变量一样是 undefined。函数是怎么执行的?
全局函数和局部函数(比如嵌套函数)
和变量一样,在编译时,碰到函数,函数也会作为属性添加到 GO 中,属性名就是函数名,可 value 不再是 undefined,引擎会在堆内存中创建一个函数对象。value 就是函数对象的地址—— GO 中有对函数对象的引用。
函数对象主要包含两部分:父级作用域和要执行的函数代码块。全局函数的父级作用域就是全局,也是GO。父级作用域只和函数定义的位置有关,和调用位置无关。
在执行时,执行全局代码的时候碰到函数调用,也就是括号运算符,这时候就会根据函数名在GO中找到函数对象的引用。然后在调用栈中生成一个函数执行上下文 Function Execution Context(FEC),也就是入栈。
函数在调用栈中一条一条往下执行。当函数执行完,函数执行上下文就会出栈,被销毁。(GEC 没出栈,所以函数对象暂时不会被销毁)这就是函数的执行过程。再次调用函数的话,就会再来一遍入栈出栈。
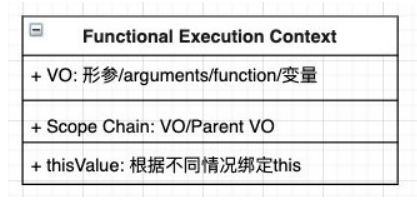
FEC 中主要有三部分:
- 里面也有 VO,这里的 VO 指向的对象不再是 GO,而是活跃对象 Activation Object(AO)。
- AO 中包含形参、定义的变量、函数定义和指向函数对象
- 作用域链:由当前VO(即AO) + 父级作用域构成
- 函数执行时变量查找的过程就是按作用域链来层层往上查找。
- this 绑定的值
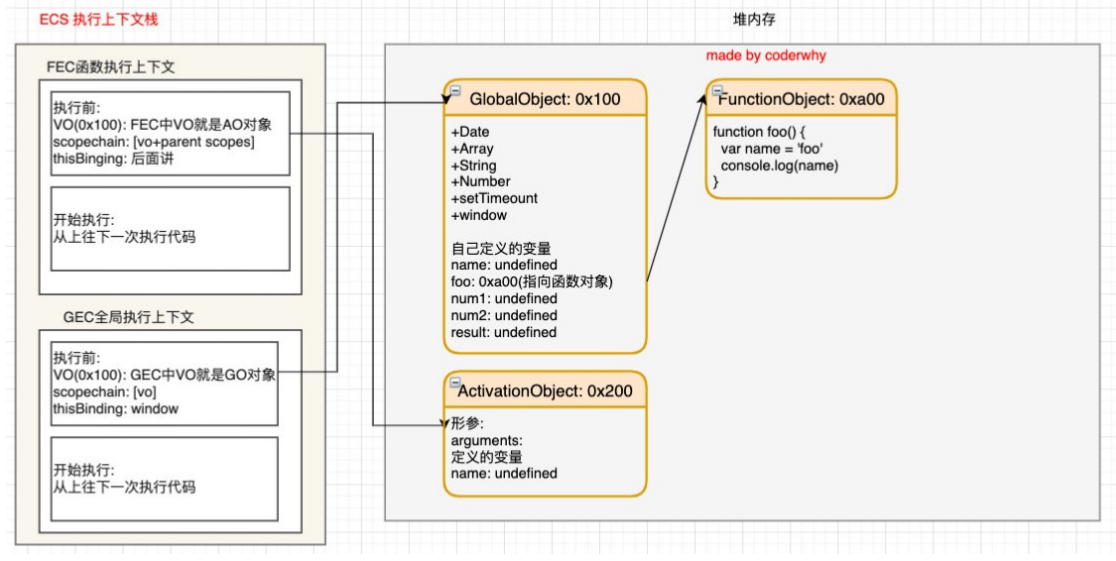
总结一下函数执行的过程:
- 在编译时,碰到函数体,生成函数对象,GO中建立对函数对象的引用。
- 在执行时,生成 AO,将参数,变量等注入 AO,变量值为 undefined
- 生成函数执行上下文进入调用栈,执行根据作用域链层层查找变量
- 最后出栈,上下文销毁。
了解函数执行的过程,也就是可以解释很多问题了。
函数里面的变量在未声明时调用,也是 undefined。因为AO中就是 undefined。
为什么可以在函数声明前可以调用函数?
因为编译的时候就生成了函数对象在堆内存中,调用的时候就是函数执行上下文的入栈去查找 AO,最后出栈。
根据作用域链的查找顺序,如果往上一直找会找到全局,也就是GO,找不到就会报错。如果变量名为 name 会特殊一点,浏览器自带了这个属性,所以没有在代码中定义 name,一直往上查找也不会报错。
ES5 之后的代码执行过程
前面的代码执行过程都是 ES5 以前的执行过程,现在的版本执行过程有点不一样。
js 糟粕——变量非正常定义
function foo() {m = 100; // m 未定义就使用}foo();console.log(m) // 100
正常的代码,未定义的变量直接使用,甚至都无法通过编译。而 js 对这种形式做了特殊处理,没有定义直接使用的变量相当于就是定义在 GO 中。所以上面可以打印出 100。
var m = 100;function foo() {}foo();console.log(m) // 10
js 糟粕——连续定义变量
function foo() {var a = b = 10; // 连等定义变量// 转换的代码实际为:// var a = 10;// b = 10; 两个糟粕呼应了属于是。}foo();console.log(a); // 报错,找不到 aconsole.log(b); // 10

若有收获,就点个赞吧
0 人点赞
