1 OOM事件介绍
OOM(Out Of Memory)内存不足,通常是由于某些不稳定的进程占用过多的内存造成,在Docker中称为OOM事件,当容器使用的内存过多时就会发生OOM事件,这个事件是由Linux内核的内存管理机制发起,并将是使用占用内存过多的容器Kill掉,保证系统的可持续运行。Linux内核为了保证系统的稳定性而将内存划分为两大部分用户空间与内核空间
用户空间是提供给用户进程所使用的内存空间。内核空间是仅提供给内核运行的空间。用户的进程是无法访问内核空间,而内核是可以访问用户空间与内核空间。在Linux内存管理机制中还存在一个定时任务,检查计算机的内存是否足够使用,分别收集以下几个指标
- Total page cache as page cache is easily reclaimed
- Total free pages because they are already available
- Total free swap pages as userspace pages may be paged out
- Total pages managed by swapper_space although this double-counts the free swap – pages. This is balanced by the fact that slots are sometimes reserved but not used
- Total pages used by the dentry cache as they are easily reclaimed
- Total pages used by the inode cache as they are easily reclaimed
如果内核发现内存不足够使用时开始发起OOM的状态检查,接着调用out-of-memory函数查找使用内存最多的进程并kill掉 oom
在Docker的容器中默认是没有限制资源使用的,也就是说容器获得到CPU/内存与宿主机是一样的,为了避免OOM事件,可以给Docker的容器作一些调整
- 通过性能测试后才放到生产环境的容器中
- 确保主机上有足够的资源分配
- 使用SWAP(交换空间)
- 将容器转换到有足够内存的Docker Swarm的服务中
注意:Docker不建议手动调整–oom-score-adj与–oom-disable-kill选项来避免OOM。
2 OOM排查
背景:<br /> 微服务架构,几百个服务,运行在不同的容器上,总是莫名的同时出现十几个服务不可用,伴随着各个容器的状态异常,无法ping通,无法ssh上去,大量告警。。。总是莫名的有物理机宕机,每次查的时候总是无疾而终。。。<br /> <br /> 验尸报告:<br /> Emmm,故障现场不够新鲜,检查的力度不够。。。<br /> 故障之间总是有关联的,查出根本的问题之后,就发现,莫名的物理机宕机和这次发生的问题是一样的,只是原来从来没有想过,内存泄漏导致物理机重启,未曾进行关联,当查出每次都是OOM之后,那么问题就可以联系在一起,其实两者的问题的本质是一样的。<br /> 收到告警,大量服务出现单点,查看相关的告警信息,大量的容器无法ping通,伴随着load值告警,而且这些所有的容器都分布在一台物理机上,有部门的服务在慢慢的恢复。。。经常看到这种情况的发生,也麻木了,等一会儿,慢慢就会自动恢复的。。。<br /> 等了两个多小时,还没有恢复,依据以往的经验,这个时候应该已经恢复了。。。Emmm,经验往往是不可靠的,所谓的黑天鹅事件了解一下。。。<br /> 大量的容器无法ping通,登录上主机,查看资源抢占情况*(示例图):<br /> 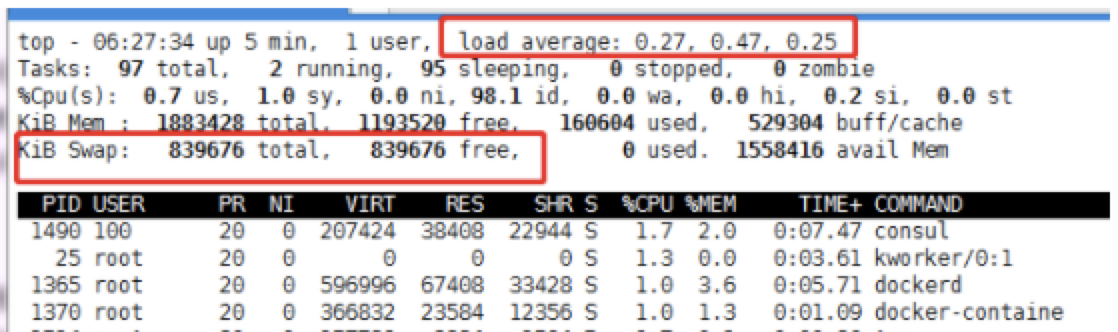<br /> 在以上的图中,主要看四个指标,一个是load,Emmm,假设CPU是56个,实际的load值达到了3K,那么这个时候,系统已经不堪重负了;一个是Tasks,主要看任务的运行数量,在图中,才2个在运行,实际也就几百个,但是sleeping状态的有几万个,而zombie状态的有300多个;一个就是内存的使用量,在实际情况中,内存基本使用完毕;最后一个就是使用交换空间,图中的未使用,实际上已经全部使用完毕。<br /> 系统资源不足,要不扩容试试。。。向上?还是水平扩展。。。Emm,当然是不可能的。。。<br /> CPU的load太高,那么说起来其实也就两个队列,一个是运行的队列,一个block的队列,从而需要收集相关的进程信息,从而可以使用ps来查看进程的状态信息:<br /><br /> 以上主要是为了统计:一个是进程的数量,一个是线程的数量。。。(需要多次执行,从而进行对比,可以知道哪些进程造成了相关的阻塞,数量庞大的必有蹊跷。。),统计的结果是大量状态为D的进程。。。在线程多的结果中,可以看到相关的PID,从而可以知道是哪个进程产生了大量的阻塞。。。<br /> 统计容器的数量,从容器的内存限制来查看是否容器的内存都达到了限制。<br /> <br /> 在查看结果的时候,发现很多容器使用的内存值和限制值差不多一致,而且falcnt也就是分页中断有几万次。。。当然缺页异常几万次,可能或许maybe属于正常情况。。<br /> 保存进程列表(主要是保存进程的树形结构,可以用来追查父进程):<br />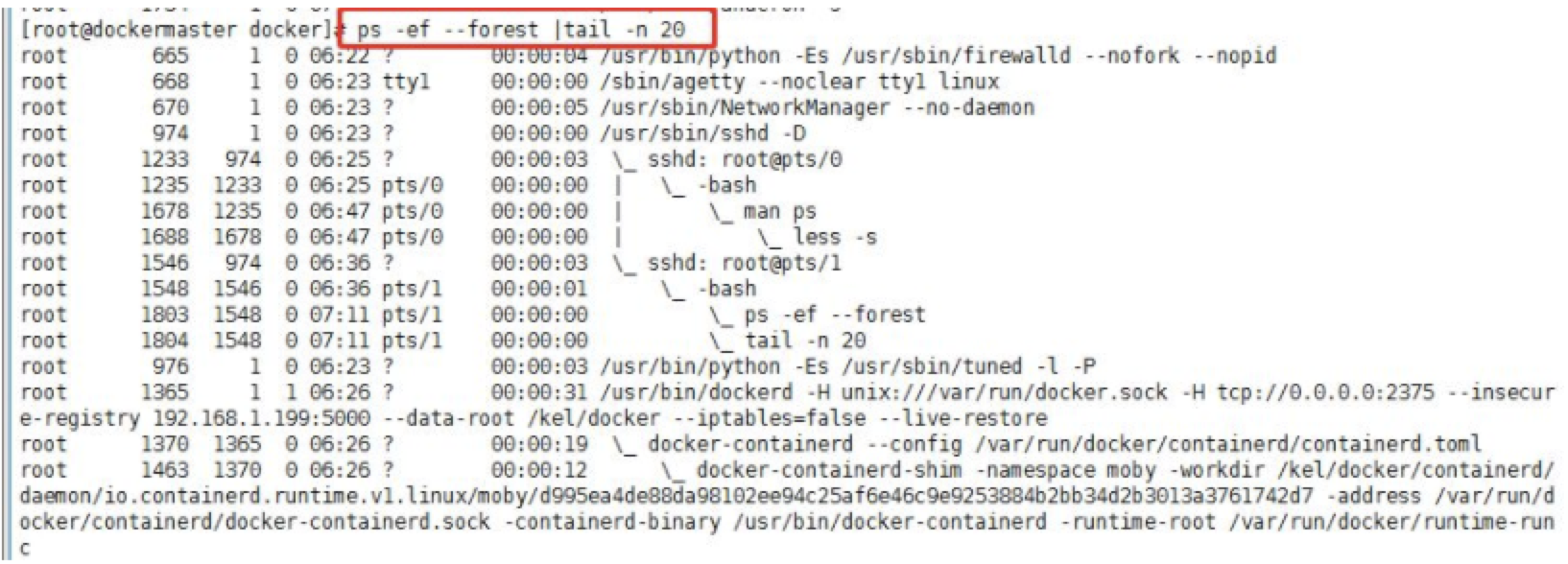<br /> 突然出现。。。fork,Can't allocate memory!。。至此已经无法查看相关信息,只能。。。重启服务器了。。。所有的内存已经耗尽。。。。<br /> 重启之后查看相关的日志:对。。。重启是万能的。。。<br /> 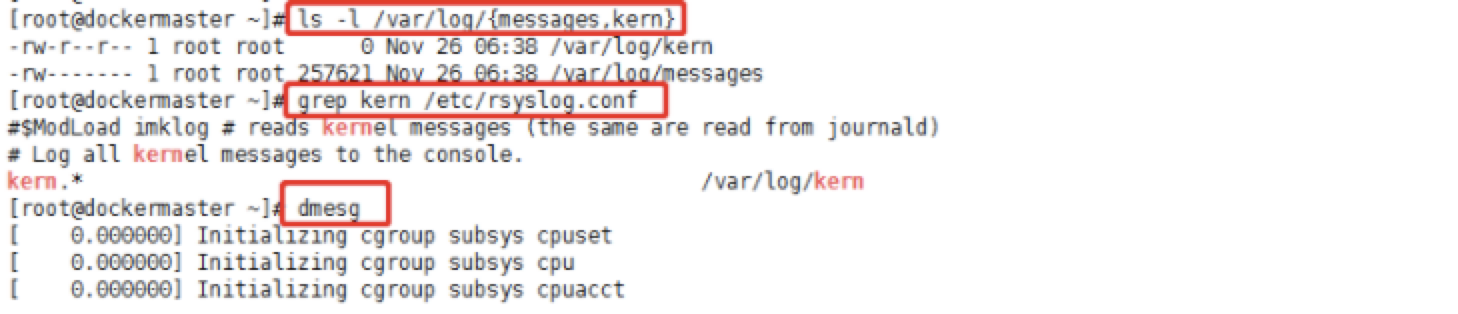<br /> 在日志里面查看到大量的OOM信息,也就可以看到相关的进程被杀死,从而可以找到是哪些进程导致了内存泄漏,从而进行整改。。。在kern日志中可以看到被杀死的进程名,在dmesg中可以看到OOM,在message中,能追查到相关的容器id。。。<br /> 排查思路:根据load值偏高,查询进程的数量和线程的数量,从而从增加的数量查看到是什么样的进程阻塞了CPU的调度,查看系统日志,主要查看oom,从而对比两者的结果进程是否一致,从而看哪个进程OOM需要整改。。。可能你会说,查看单独进程的内存占用量,Emmm,这也是一个排查思路。。。<br />风言风语<br /> 在以上的问题追踪中,可以产生两个疑点:第一既然oom都杀死了进程,为什么内存还会溢出,杀死了进程应该已经将相关的内存进行回收了;第二:是什么导致了那么高的load值。。。<br /> 回答第一个问题就是:在oom killer进行杀死进程的时候,使用的是kill -9 ,从而能强行杀死进程,但是在进行oom的时候,oom的分值是给占用内存大的进程,而这个进程在等待IO,也就是等待分配内存,Emm。。。读取内存也是一种IO,所谓的缺页中断。。。在杀死这个进程的时候,这个进程的状态为D,也就是表示这个进程是不可中断睡眠,在等待分配内存。。。从而杀死这个进程可能根本就无法杀死。。。<br /> 还有一种情况是,进程已经变成了僵尸进程,从而在oom killer在进行杀死进程的时候,根据当前的进程号id杀,而僵尸进程要想杀死,必须杀掉其父进程,而当僵尸进程的父进程为1的时候,这个时候就相当于服务器重启了。<br /> 回答第二个问题就是:将一个进程杀死,变成了僵尸进程,自动拉起进程并不能识别变成了僵尸进程,从而会自动拉起服务,然后又内存溢出,再次杀,再次变成僵尸进程,死循环,最终导致内存耗尽。。。<br /> 还有一种情况就是,在容器中运行了很多进程,而oom分值高的进程是其中的一个子进程,而不是容器的根进程,也就是pid为1的进程,如果恰好是1的进程,那么很完美,相当于将容器进行重启,那么这种情况下会慢慢的恢复,不会增加load值;而当是一个普通进程之后,杀掉,有很大的概率变成僵尸进程。。。<br /> 容器也是一个进程,在其中又有很多进程,资源隔离还不是那么好。。。原因之一也在于使用不当。<br /> 最后解答开篇的问题:要不要设置cpu和容器的最高使用值。。。要<br /> 如果在容器的层面进行限制了内存的使用,那么就只有容器出现OOM,而不会影响这台机器上其他的容器,不会出现资源竞争的情况。。。在查看容器oom的时候,也可以通过docker inspect id来查看容器的OOM。。。<br />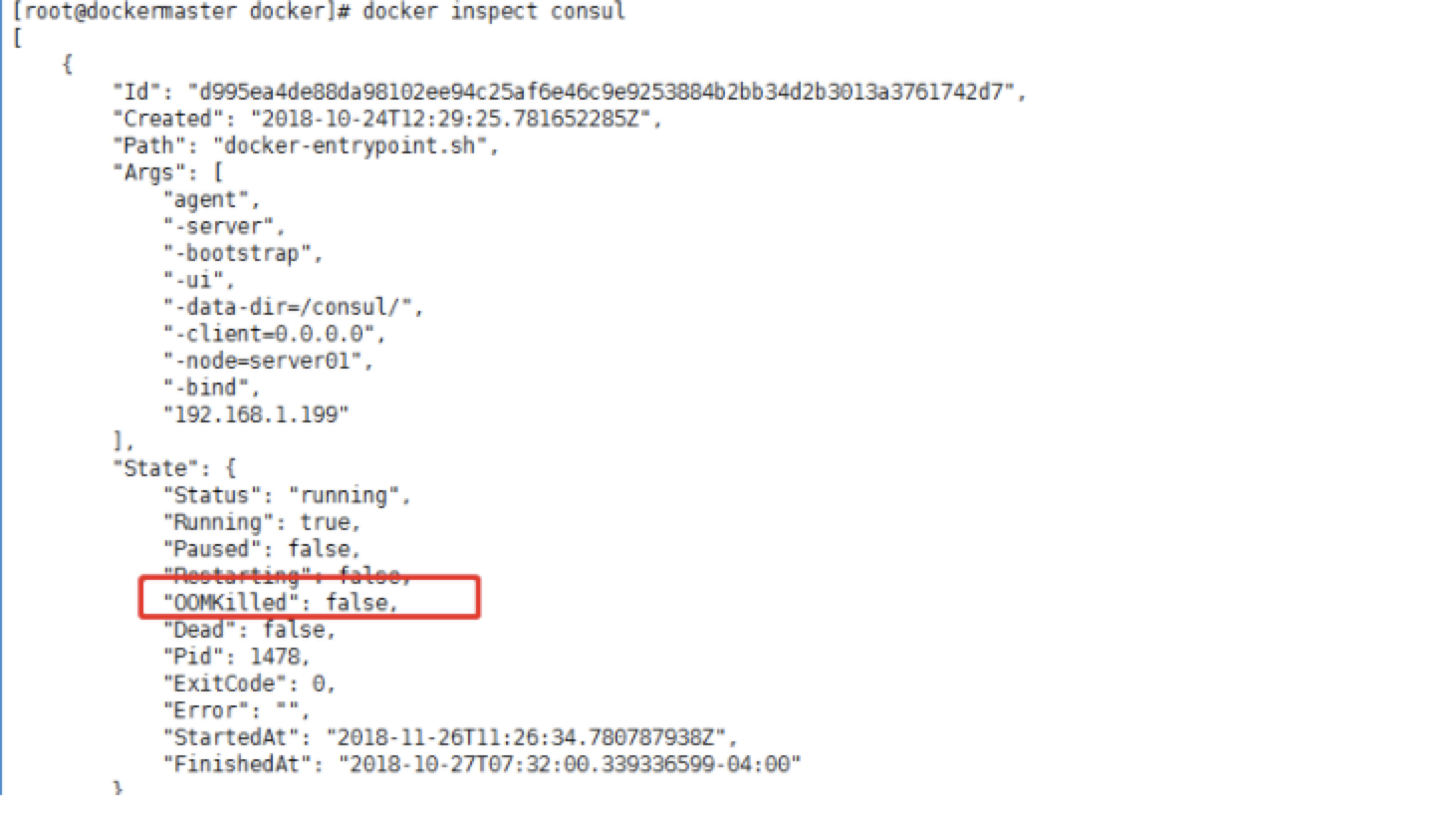
3 记录一次docker容器频繁oom的问题排查
业务系统在docker内内存持续增大,导致频繁被系统kill
使用 cat /var/log/message 查看kernal日志得到是因为oom被系统kill
使用docker stats 查看容器运行状况
docker run 命令如下(使用了lxcfs,事实证明最后的解决方案并不需要用到lxcfs)
| 1 | docker run -m 2800M —memory-swap 3500M —memory-swappiness 60 -p 9011:9011 -dit —cap-add=SYS_PTRACE —security-opt seccomp=unconfined —restart=always -e CATALINA_OPTS=’-Xmx200m’ —name=${project} —network=host -v /etc/localtime:/etc/localtime:ro —hostname=alioracle -v logs${project}:/tools/tomcat8/logs -v /tools/application2.properties:/tools/tomcat8/bin/application.properties $extrarunops scm.nicezhuanye.com:6555/$p:$version` |
|---|---|
设置-Xmx200m
(使用-swapiness可以决定程序使用交换内存的意愿,0-100,0表示绝对不会使用交换内存,越大使用的概率越大,设置交换内存后,程序把交换内存跑满,一样会被kill)
初步怀疑java heap泄露
使用 docker exec -it schedulercore2 bash -c "wget [https://alibaba.github.io/arthas/arthas-boot.jar](https://alibaba.github.io/arthas/arthas-boot.jar) && java -jar arthas-boot.jar" 进入容器内
使用 arthas的dashborad命令查看java heap并没有超过限制
所以有可能是堆外内存超了
使用pmap <pid> -X来查看java进程的内存情况
发现很多两个一组,加起来等于65536kb也就是64mb,仔细观察大多都是132kb的堆是rw权限,650000多的是无权限的内存块
使用gbd attach <pid> 到java进程上
使用命令 dump memory <path> <start address> <end address>将内存块dump到磁盘上,(例如 dump memory /tools/core.dump 0x7fce18000000 0x7fce18000000+65536,开始地址为pmap中的内存地址直接加0x前缀,结束地址为开始地址加内存块地址长度)
使用strings命令查看dump的内容,发现无可查看内容(有可能是无用内存)
查看网上资料,网上也有很多大老遇到了类似的问题
http://ju.outofmemory.cn/entry/105474
https://blog.csdn.net/ityouknow/article/details/84038718
初步得到可能是glibc内存分配的原因
可以添加系统变量MALLOC_ARENA_MAX=4 来限制堆的使用
尝试后发现64mb的堆的确少了,但是还是会出现内存爆炸的现象
之后尝试文章中将glibc替换为谷歌研发的tcmalloc后,成功稳定住了堆外内存
使用yum install gperftools-libs.x86_64
在/usr/lib64中可以找到libtcmalloc.so.4
将该文件添加到docker镜像中
DOCKERFILE中添加 LD_PRELOAD="/usr/lib64/libtcmalloc.so.4.1.0" 环境变量
这样就将glibc替换为了tcmalloc

若有收获,就点个赞吧
0 人点赞
