| 特性 | 场景 | |
|---|---|---|
| List | 有序、可重复 | |
| Set | 无序、不可重复 | |
| Queue | 有序、可重复,先进先出 | 排队 |
| Map | 无序、不可重复 |
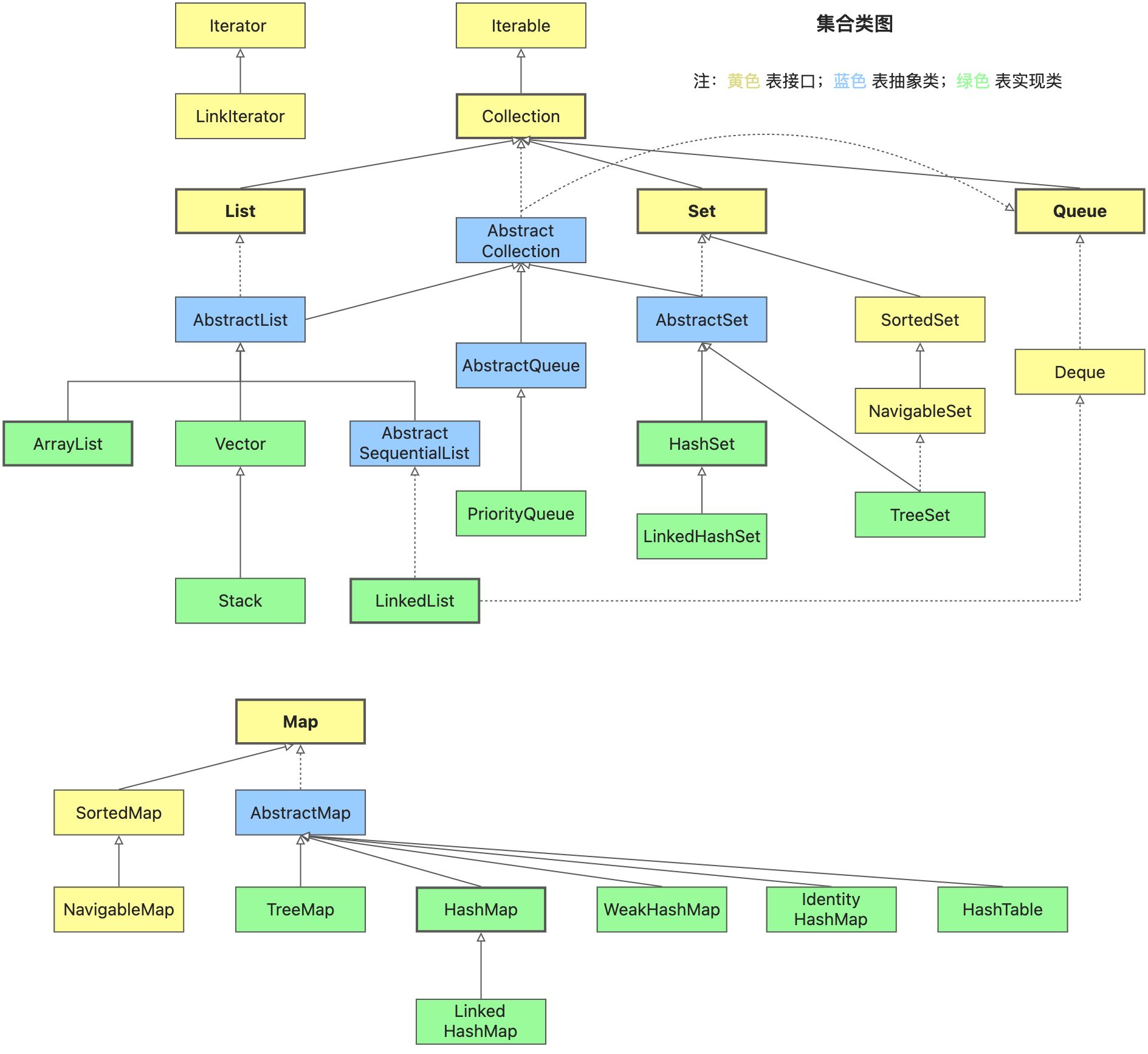
List
快速创建List
方式一:Arrays.asList(T … a)
List<Integer> list = Arrays.asList(1, 2, 3);
注意:Arrays.asList() 方法是 Arrays 的静态方法。这种方式构造的 List 是固定长度的,如果调用 add 方法增加新的元素时会报异常 java.lang.UnsupportedOperationException。这种方式仅适用于构造静态不变的 List。
如果想要改变可以通过 ArrayLis t进行包装成动态:List<Integer> list = Arrays.asList(1, 2, 3);list = new ArrayList<>(list);list.add(4);
方式二:Stream式创建
List<Integer> list = Stream.of(1, 2, 3).collect(Collectors.toList());
Set
| HashSet | 是 Set 接口的主要实现类 ,HashSet 的底层是 HashMap,线程不安全的,可 以存储 null 值; | | —- | —- | | LikedHashSet | 是 HashSet 的子类,能够按照添加的顺序遍历; | | TreeSet | 底层使用红黑树,元素是有序的,排序的方式有自然排序和定制排序。 |
HashSet 如何检查重复?
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入 的位置,同时也会与其他加入的对象的 hashcode 值作比较,如果没有相符的 hashcode, HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会 让加入操作成功。
在 openjdk8 中,HashSet 的 add()方法只是简单的调用了 HashMap 的 put()方法, 并且判断了一下返回值以确保是否有重复元素。 也就是说,在 openjdk8 中,实际上无论 HashSet 中是否已经存在了某元素,HashSet 都会直接插入,只是会在 add()方法的返回 值处告诉我们插入前是否存在相同元素。
Queue
在jdk中的队列都实现了java.util.Queue接口,在队列中又分为两类:
- 线程不安全队列:ArrayDeque,LinkedList等,因为线程不安全,所以并不常用;
- 线程安全队列:位于java.util.concurrent包下,常用的如下表: | 队列名字 | 数据结构 | 关键技术 | 有界么 | 有锁么 | | —- | —- | —- | —- | —- | | ArrayBlockingQueue | 数组 | ReentrantLock | Y | | | LinkedBlockingQueue | 链表 | ReentrantLock | | | LinkedTransferQueue | 链表 | CAS | N | | | ConcurrentLinkedQueue | 链表 | CAS | |
无界的队列,有可能会致使咱们内存直接溢出,一般场景下不建议使用。在队列中,通常获取这个队列元素以后紧接着会获取下一个元素,或者一次获取多个队列元素都有可能,而数组在内存中地址是连续的,在操做系统中会有缓存的优化,因此一般场景下,数组应该作为首选的结构。那么通过以上分析,符合条件的也就只剩ArrayBlockingQueue了。
当然ArrayBlockingQueue本身也有数组的弊端,就是增删性能比较低。同时它是有锁的,自然性能比无锁的队列要差。还是那句话,无银弹,只有最合适的,没有最好的。
- 常见方法 | add(e) | 队列未满时,返回true;队列满则抛出IllegalStateException(“Queue full”)异常 | | —- | —- | | put(e) | 队列未满时,直接插入没有返回值;队列满时会阻塞等待,一直等到队列未满时再插入 | | offer(e) | 队列未满时,返回true;队列满时返回false。非阻塞立即返回。 | | offer(e, time, unit) | 设定等待的时间,如果在指定时间内还不能往队列中插入数据则返回false,插入成功返回true。 | | poll() | 获取并移除队首元素,在指定的时间内去轮询队列看有没有首元素有则返回,否者超时后返回null | | take() | 与带超时时间的poll类似不同在于take时候如果当前队列空了它会一直等待其他线程调用notEmpty.signal()才会被唤醒 |
Map
HashMap
底层数据结构为哈希表
- 两个重要属性
- 加载因子(LoadFactor):用于控制哈希表的阈值。默认加载因子为0.75。
如果加载因子越小,会导致哈希表数据越稀疏,虽然保证了散列,查询效率高,但是空间利用率低;如果加载因子越大,会越容易产生hash冲突,虽然保证了空间利用率高,但是查询效率低。
- 阈值(Threshold):用于控制哈希表的扩容,当哈希表使用率大于阈值时,就扩容。是通过初始容量和 LoadFactor 计算所得,默认值是12。
HashMap 中 Node 的数量超过边界值,HashMap 就会调用 resize() 方法重新分配 table 数组。这将会导致 HashMap 的数组复制,迁移到另一块内存中去,从而影响 HashMap 的效率。
- HashMap 的长度为什么是 2n ?
使其元素充分散列,减少哈希冲突。如果初始化大小设置的不是2的幂次方,HashMap也会调整到比初始化值大且最近的一个2n作为capacity。
- 首先,为了保证hash值与数组能一一映射,我们可以直接使用取模运算的方式来计算位置:hash % len。len表示数组的长度。
- 而计算机中做数学运算远不如位运算的效率高,所以,可以将 hash % len ➡️ hash & len,但前提是必须要保证 hash % len == hash & len。那么如何做到呢?如果 len的二进制全是1的话该等式便成立。我们知道 2n -1 的二进制是n个1,那么 我们可以将 hash & len ➡️ hash & (len -1),只要保证len为 2n即可。
- 如何保证充分散列呢?
其实第二点就已经保证了充分散列。2n-1的二进制全是1,那么与hash值做 & 运算的结果的散列性最好。如果有一个位置为0(以第2位为例),那么无论hash值是多少 & 操作后那一位总是0,也就是数组下标的2进制的第2位为1的就都用不了了。

若有收获,就点个赞吧
0 人点赞
