一、概念
什么是搜索?
从数据库查询。
我们在百度搜索一个关键字,或者在京东淘宝搜索一个商品,这些系统的后台怎么处理?
这些系统会将我们的搜索内容进行拆分,然后将拆分出来的一些词作为关键字,从“数据库”查询对应的信息,并且展示。
**
什么是索引?
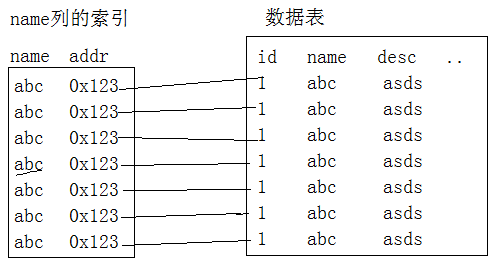
MySQL的索引实现方式是:B+Tree。
索引库
Elasticsearch就是一个搜索引擎,主要就是管理索引。检索速度非常快。
常见的搜索引擎:solr和Elasticsearch。
如果项目中需要大数据量的检索,不要犹豫直接使用搜索引擎,会大幅度提高响应时间。
Elasticsearch简介
Lucene
倒排索引 **
**
例子
要检索关键字:“洋河”。。。。。。
数据库的做法(传统做法):从第一条数据开始查询,判断关键字是否在text1这列中存在,如果存在就返回这行数据。
倒排索引:建立一个索引记录

Kibana

和Elasticsearch的交互
官方给出的标题:RESTFul API with JSON over HTTP 翻译就是:基于HTTP的带有JSON的restfulapi
其他语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信,你可以用 web 客户端访问 Elasticsearch 。事实上,正如你所看到的,你甚至可以使用 curl 命令来和 Elasticsearch 交互。
tip:
①所有的访问都是基于HTTP协议。
②API接口都是RESTful风格。
③所有的数据格式都是json。(请求参数,响应的数据)
关于RESTfull的说明
| method | url | 说明 |
|---|---|---|
| POST | http://192.168.96.138:9200/indexnam/typeName/docId | 给指定的索引添加一个文档(一行记录),并且指定文档的id |
| POST | http://192.168.96.138:9200/indexnam/typeName | 给指定的索引添加一个文档(一行记录),并且生成随机的id |
| PUT | http://192.168.96.138:9200/indexnam/typeName/docId | 更新指定ID的文档信息 |
| PUT | http://192.168.96.138:9200/indexnam/typeName/docId/_created | 使用PUT请求新增一个文档信息 |
| POST | http://192.168.96.138:9200/indexnam/typeName/docId/_update | 使用POST更新指定ID的文档信息 |
| DELETE | http://192.168.96.138:9200/indexnam/typeName/docId | 删除指定ID的文档信息 |
| GET | http://192.168.96.138:9200/indexnam/typeName/docId | 查询指定ID的文档信息 |
理论:
POST请求:表示增加数据(索引,文档)
GET请求:查询数据
PUT请求:更新(修改)
DELETE请求:删除数据
案例:
新增一个索引: 相当于以前数据库的一个insert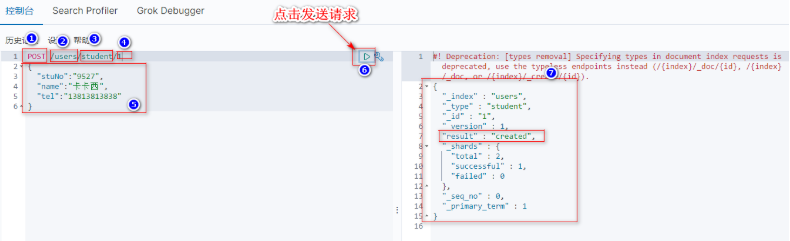
①请求的方式是POST,表示新增
②users新增的索引的名字。
③student是新增的类型的名字。
④ 指定的文档(一行记录)的id。(如果不指定,就会生成一个随机的id)
⑤我们要新增的索引的数据(JSON格式)。
⑥点击发送请求的按钮。
⑦服务器响应的结果(JSON格式)。
ES中的一些概念
什么是索引?
你可以将索引理解为一个数据库。
创建一个索引就相当于创建了一个库。
类型
你可以将类型理解为一张数据表。
相当于一张数据表,或者一个实体类。
一个索引只能有一个类型。
文档
可以理解为数据表中的一条记录
添加一个文档: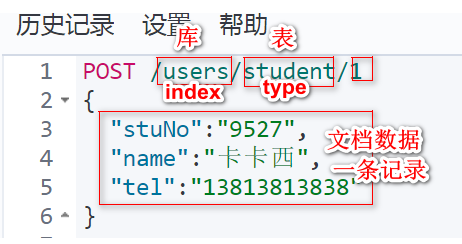
再给studet添加一条记录(ID随机)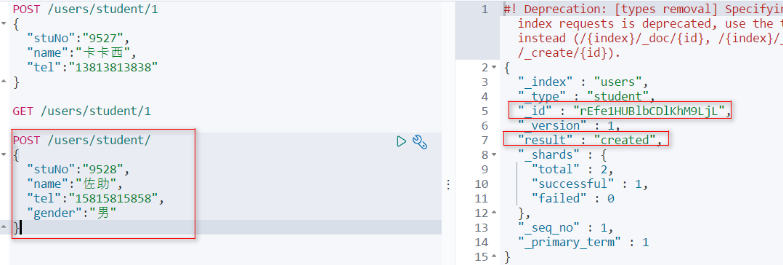
tips:一个索引只能有一个类型。
分词器
搜索引擎的主要功能:
1:分词 : 搜索引擎会自动将索引内容进行分词,并且对要检索的内容进行分词。
2 :检索。
默认情况下ES是按照英文分词的。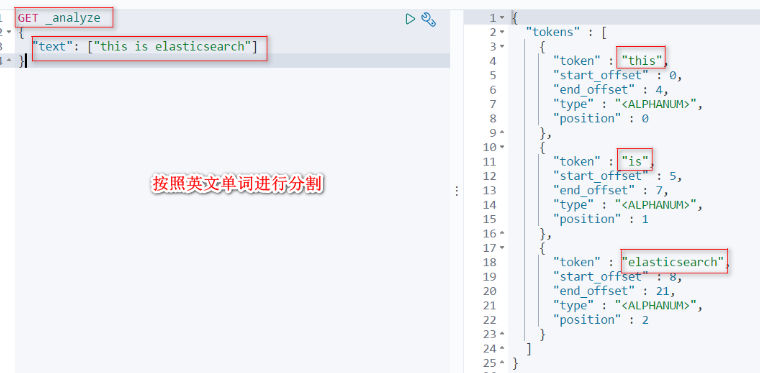
如果是中文那就是按照一个字一个字的分割
ES本身不支持中文分词,需要自己配置专门的中文分词器。下载对应的中文分词器,下载的时候,要注意版本的对应。
安装中文分词器
linux中解压zip,需要安装 unzip命令.
yum install -y unzip zip
进入目录:
cd /opt/elasticsearch-7.6.2/plugins
创建一个目录ik (当然也可以不叫ik)并将文件解压到对应的ik目录
[root@localhost plugins]# mkdir ik [root@localhost plugins]# cd ../../ [root@localhost opt]# unzip -d /opt/elasticsearch-7.6.2/plugins/ik/ elasticsearch-analysis-ik-7.6.2.zip
重启ES和kibana
重启过程中就会发现加载分词器:
再测试,测试时指定分词器:
IK分词器有两个分词策略
[1]ik_smart: 最小分词。 (将一句话里面的词语分到最小单位)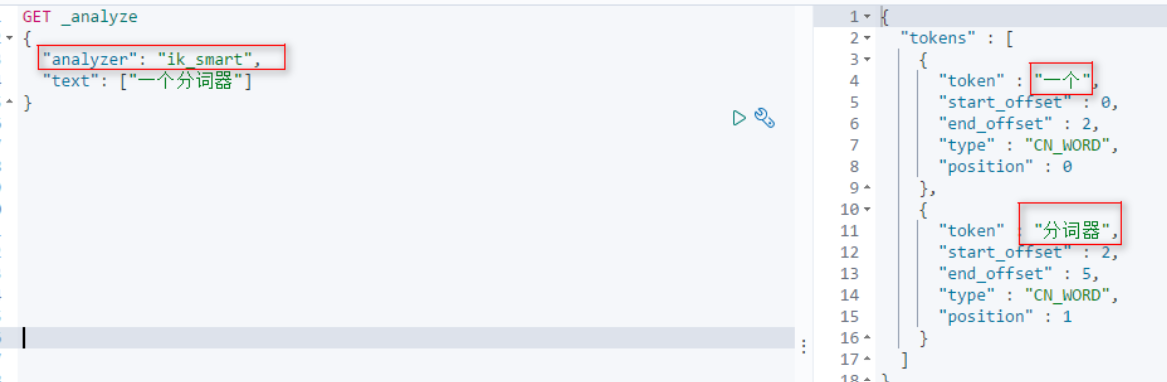
[2]ik_max_word:最多分词。 (按照各种不通的方式组织词语进行分词)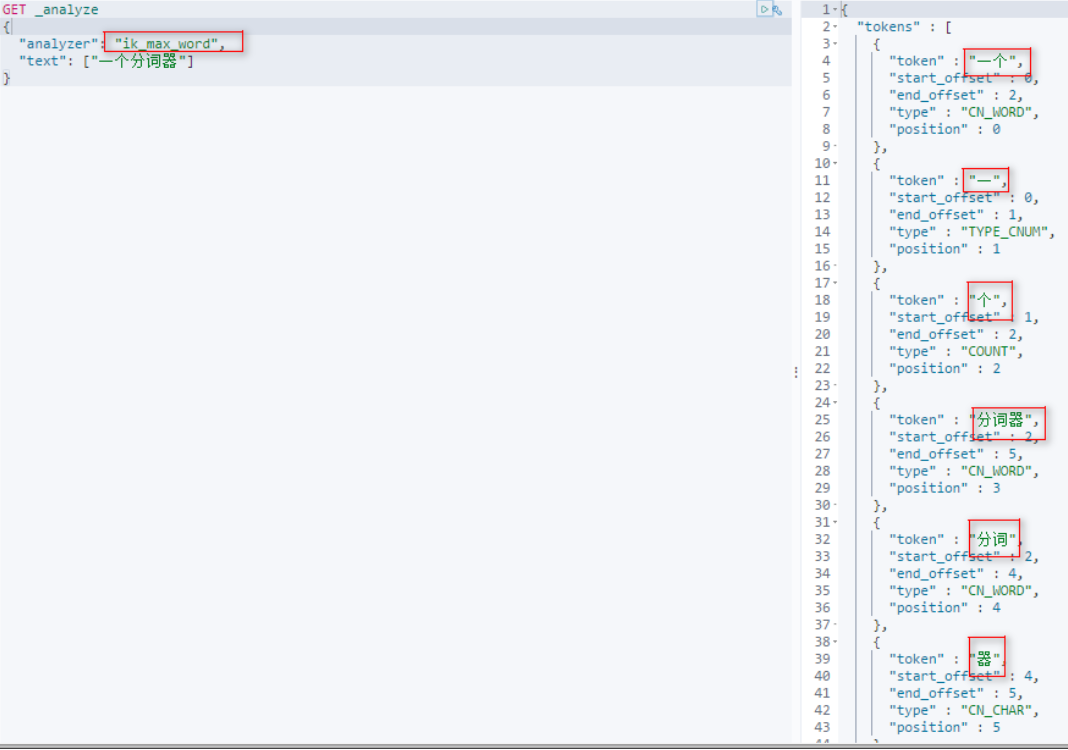
这个分词器中有些词是不认识的。
查看分词器的配置文件:(在windows下解压查看)
IKAnalyzer.cfg.xml文件:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>
我们自己编写一个扩展词典,放入我们自己的词语
我们准备一个扩展词典和终止符词典:
将这两个文件上传到ik分词器的config中: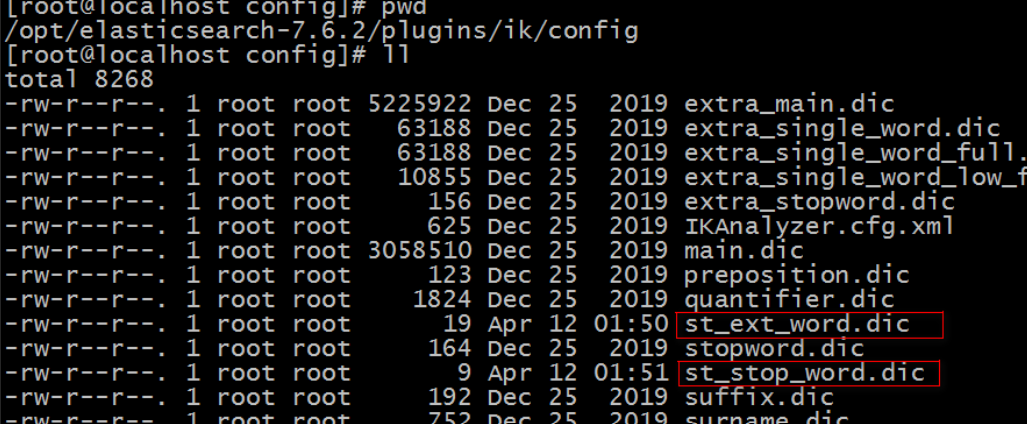
在IKAnalyzer.cfg.xml配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">st_ext_word.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">st_stop_word.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
将st_ext_word.dic和IKAnalyzer.cfg.xml上传到linux中,覆盖linux中原有的文件
重启ES和Kibana
基本的命令
_cat命令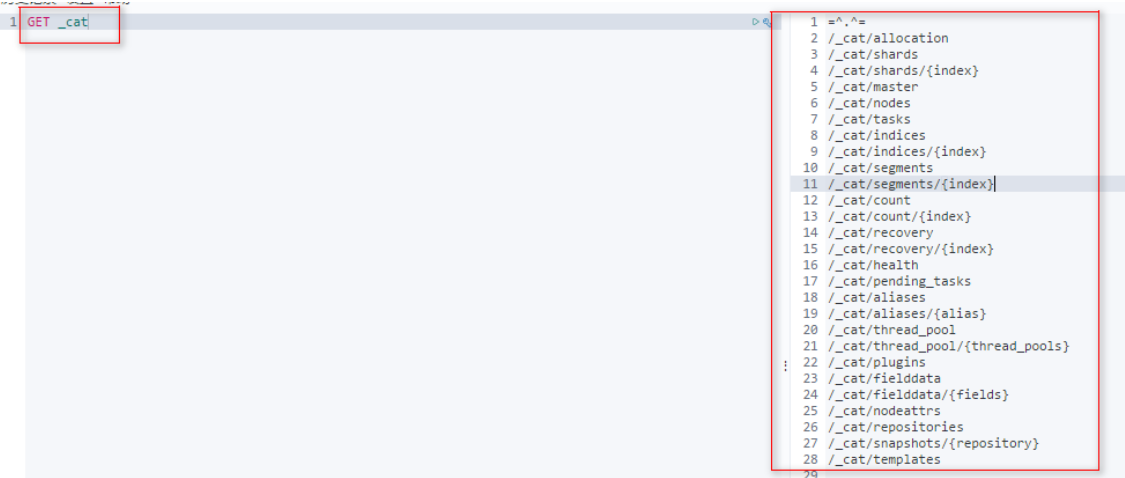
查看集群的健康状态
三个颜色:
green:有主备份。数据完整,而且高可用。
yellow:有主,但是没有备份,数据完成。
red:数据都不完整。
查看节点信息:
创建文档
添加一条记录。如果索引库存在就直接给对应的索引库中添加文档,如果不存在就创建所以库并且添加索引。
使用POST请求完成索引的添加: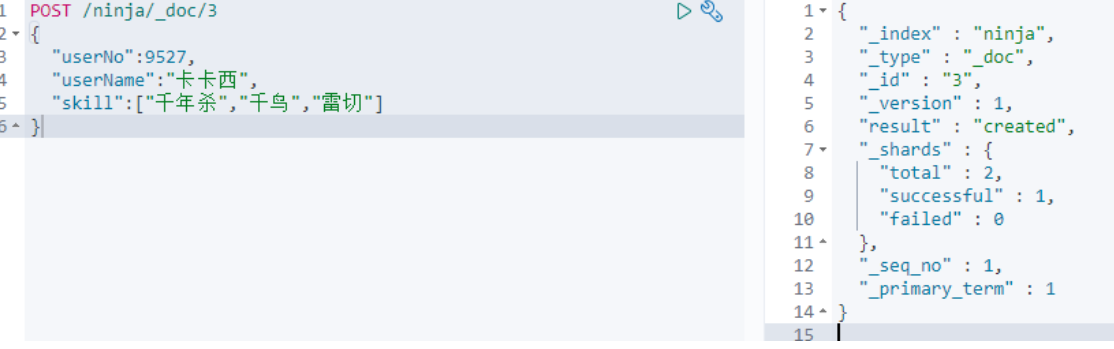
post 请求方式 /ninja 索引的名字是:ninja /_doc 索引的数据类型,这里使用默认的 /3 指定id为3 如通过不指定id会生成一个随机的id {….} 文档数据(json格式)
PUT方法本来是用来修改的,但是我们在使用的时候,如果数据不存在则就是添加,但是put方法必须指定id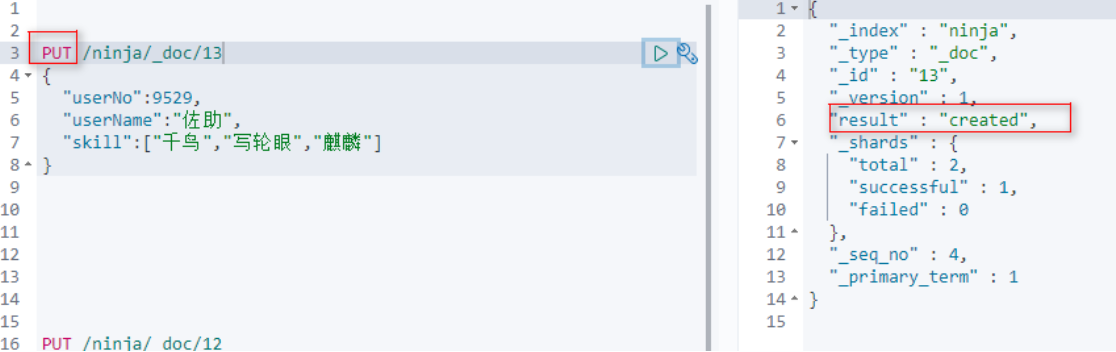
删除文档
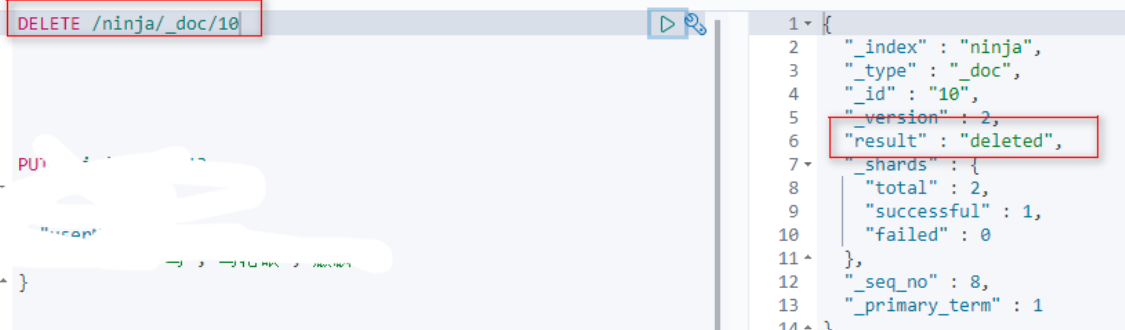
更新文档
使用PUT命令进行更新
跟新基本信息: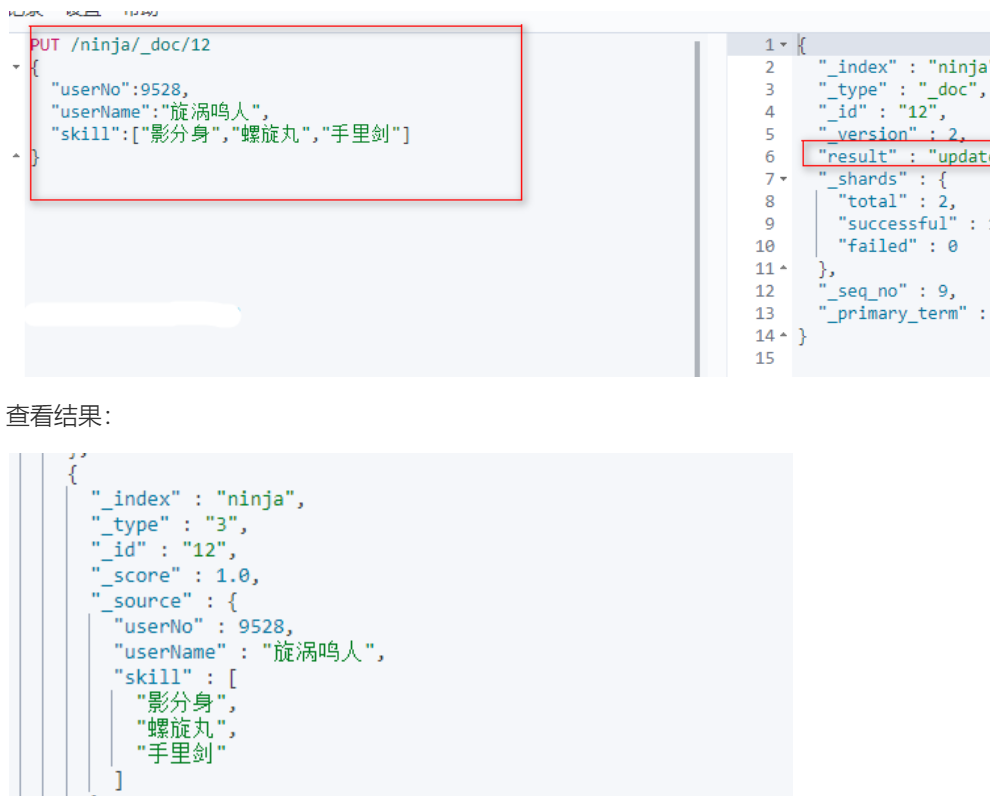
tips:版本自动升级,其他的属性就全部被更新掉了。
使用POST新增时,如果ID是存在,就完成更新操作。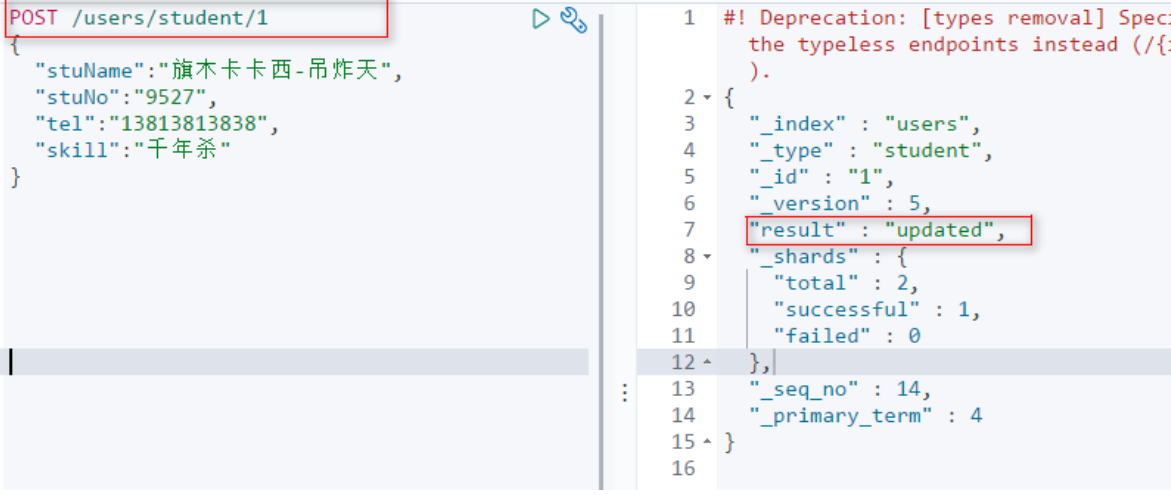
tips:文档的更新,永远都会保持最新的版本。
**
查询
根据ID查询具体的文档
使用GET请求完成查询: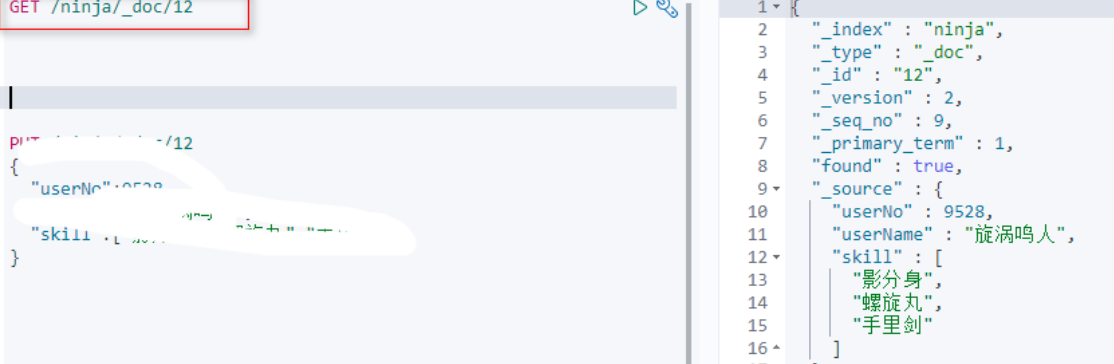
返回的json格式的数据中的,_sorces中存储的就是我们要的结果。
查询所有的文档
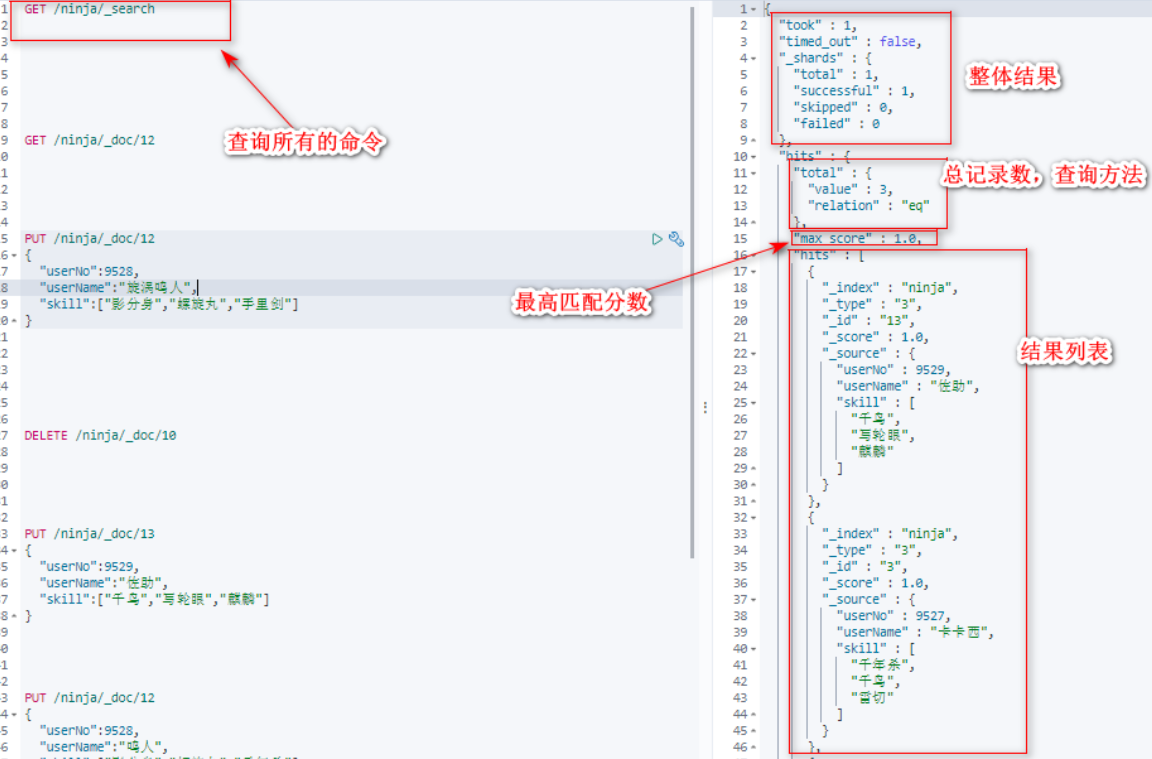
按照条件查询
按照匹配分数排序。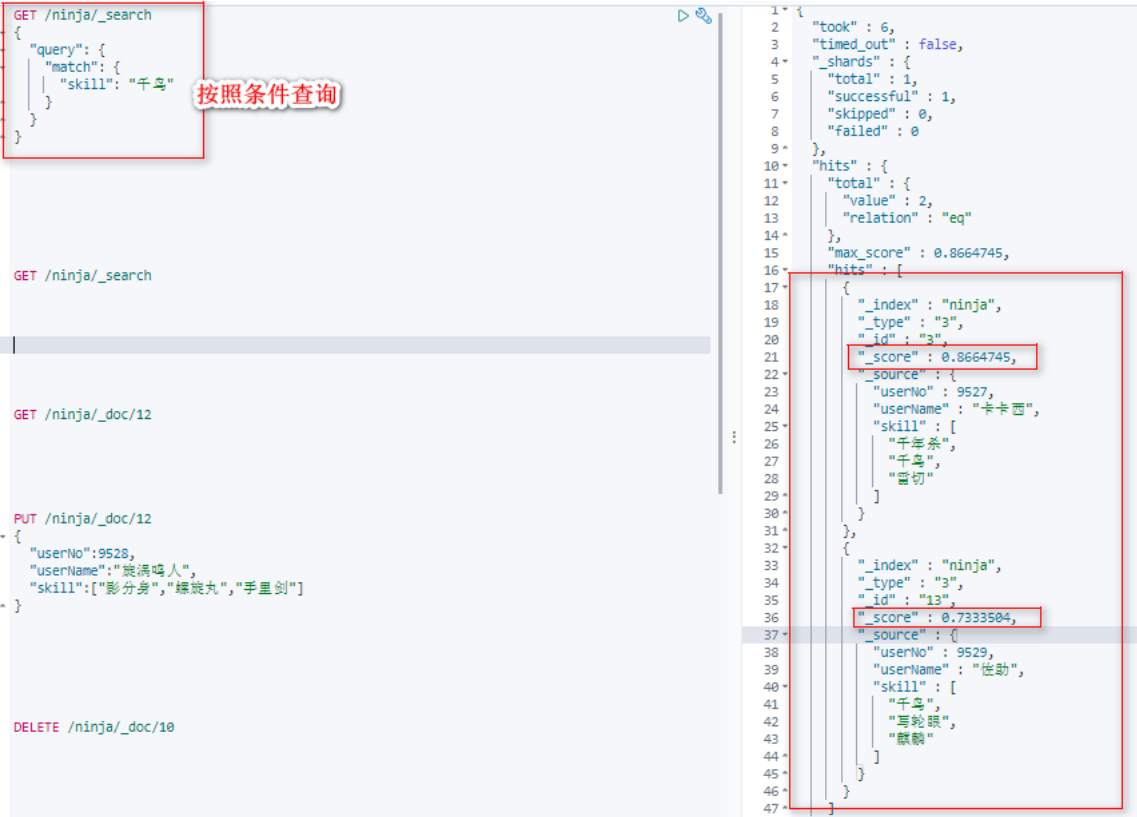
高级查询
[1]基本查询
语法:GET /indexName/[type/]_search
上面的语法默认是查询全部。 其中的type是非必须的。
[2]按照字段匹配查询(metch)
语法:
GET /indexName/_search
{
query:{
match:
{"fieldName":"value"}
}
}
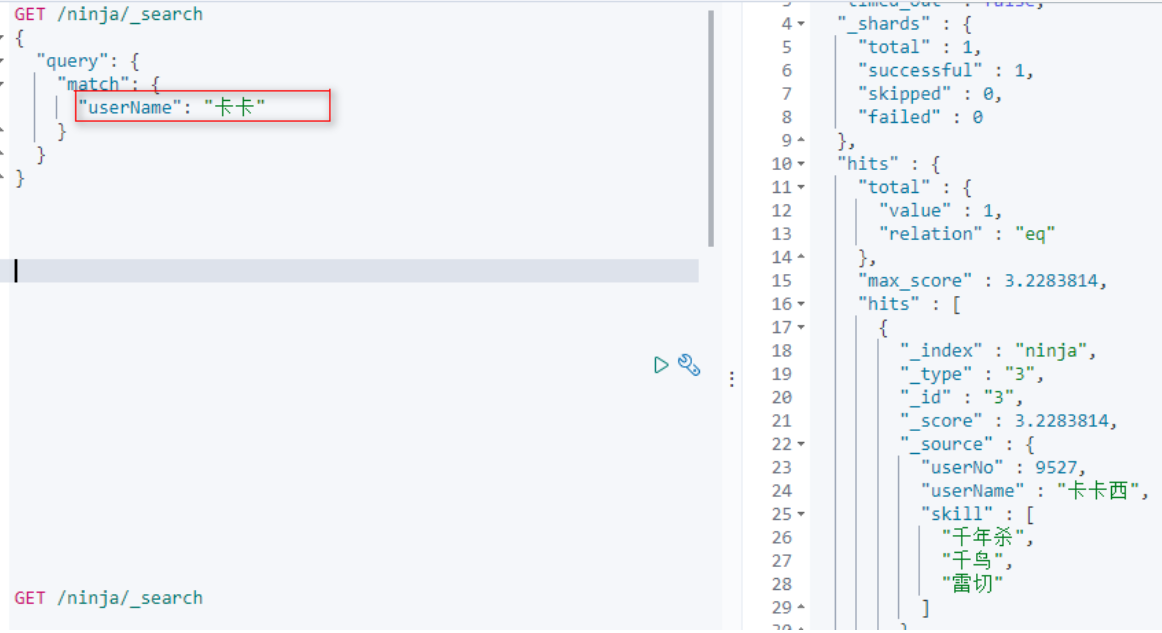
[3]多条件查询-多个查询关键字
当一个字段,有多个关键字的时候,可以使用空格隔开,匹配度最高排前面
语法: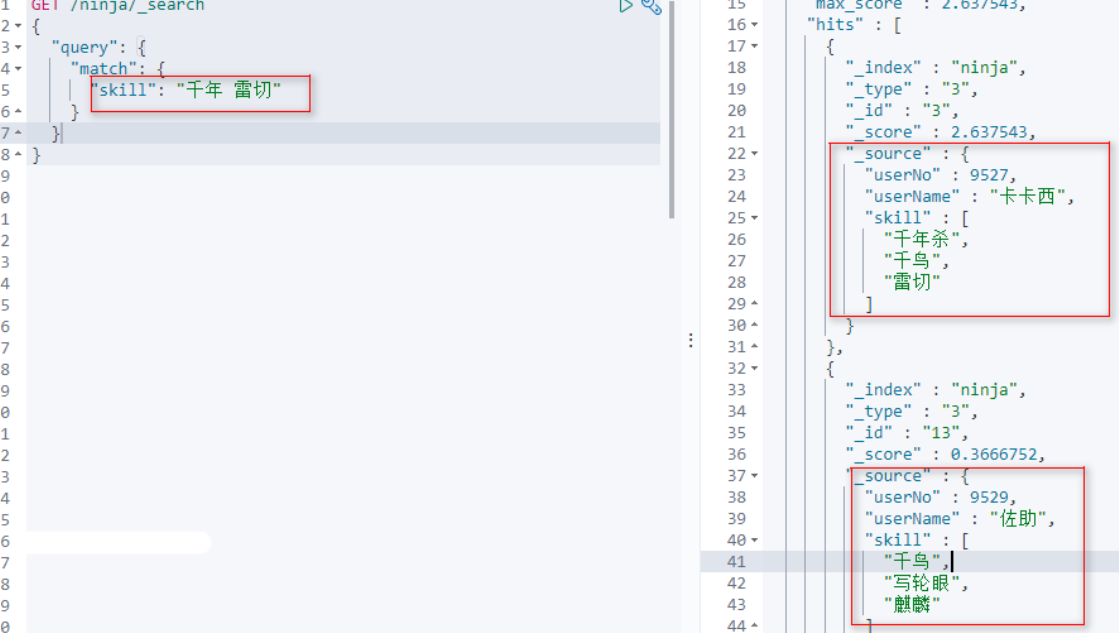
[4]组合查询(and)
同时满足:userName和skill两个查询条件。
语法: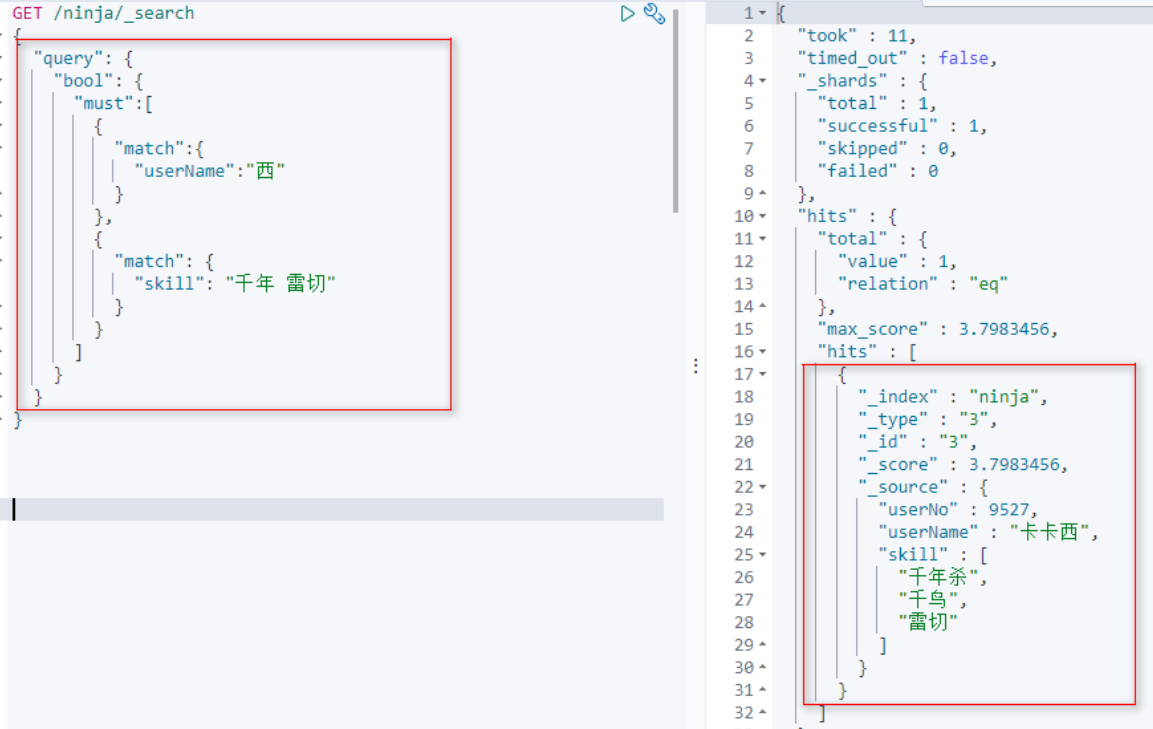
[5]组合查询[or]
满足其中一个即可 使用关键字should。
语法: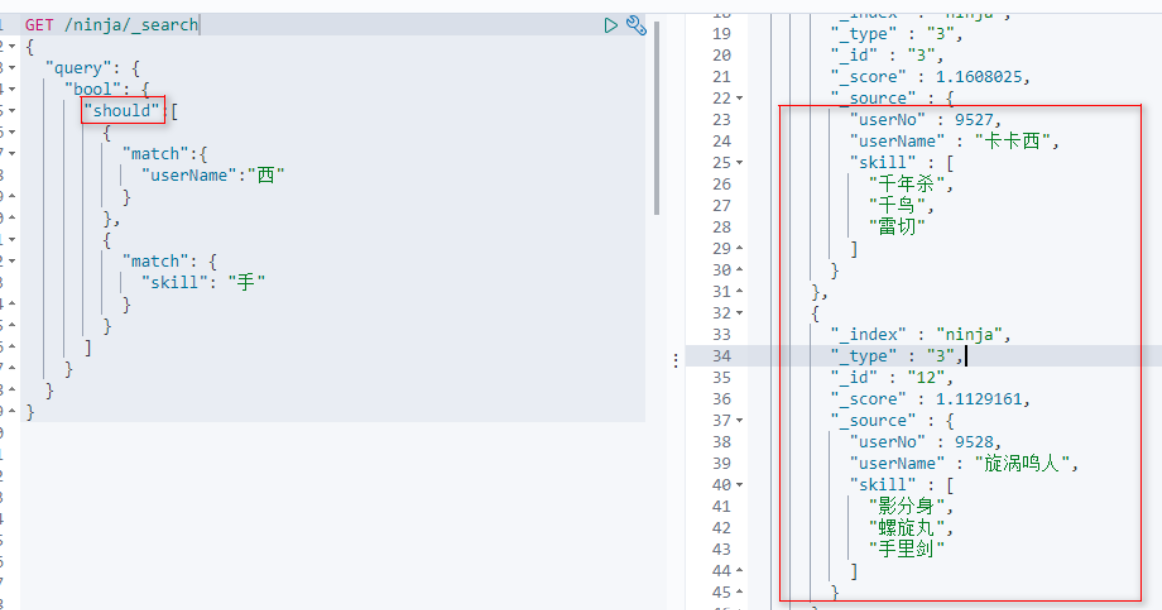
上面的案例都是逻辑运算,我们可以按照java中的逻辑运算符理解: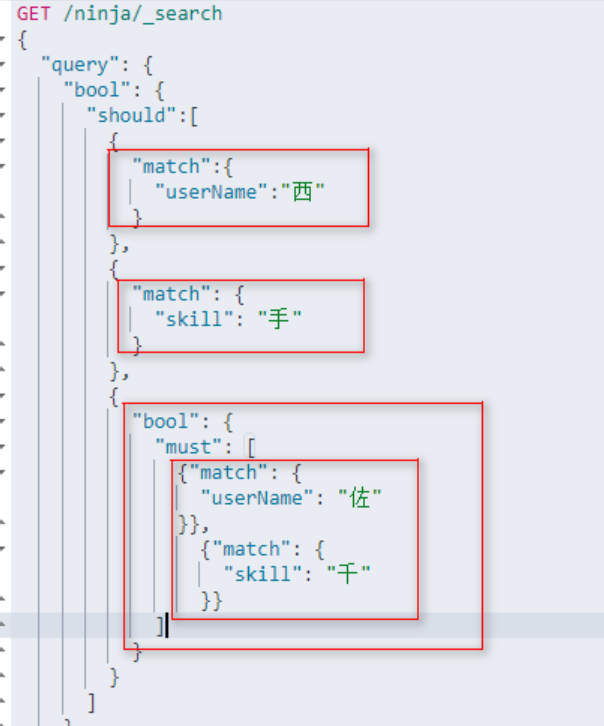
通过伪代码理解:
if(username.eq(“西”) || skill.eq(“手”) || (username.eq(“佐”) && skill.eq(“千”)))
理解之后,就不难发现,这个其实可以一直嵌套下去。
[6]逻辑非(!)必须不能有
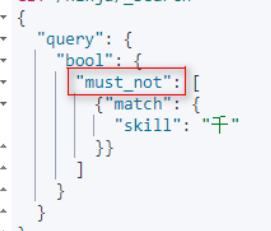
[7]条件过滤
(数字范围查询) 这里使用filter关键字
语法:
range 查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下: gt : > 大于(greater than) lt : < 小于(less than) gte : >= 大于或等于(greater than or equal to) lte : <= 小于或等于(less than or equal to)
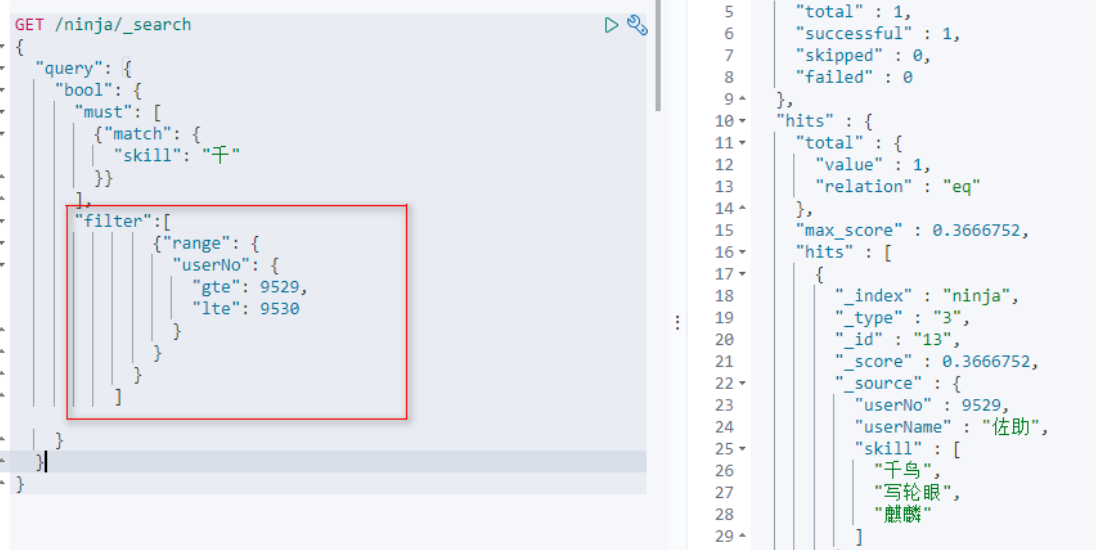
日期范围的查询:
“range” : { “timestamp” : { “gt” : “2014-01-01 00:00:00”, “lt” : “2014-01-07 00:00:00” } }
[8]指定要显示的数据属性
相当于MySQL中的:select 指定列名. …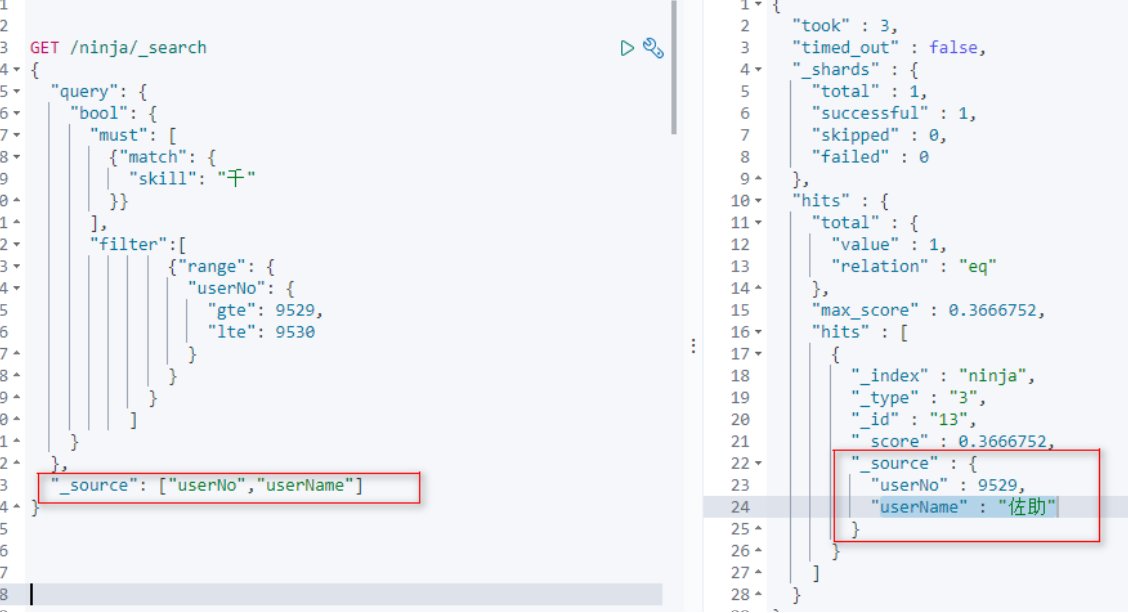
[9]高亮查询
百度的查询结果中,关键字红色的实现是在关键在的两边添加em标签。
从索引库查询出来的数据就可以直接他添加对应的标签。
通过highlight设置高亮显示的列,查询结果就会有高亮显示的效果。
ES不修改原有的查询结果,只是新增了高亮显示的查询结果。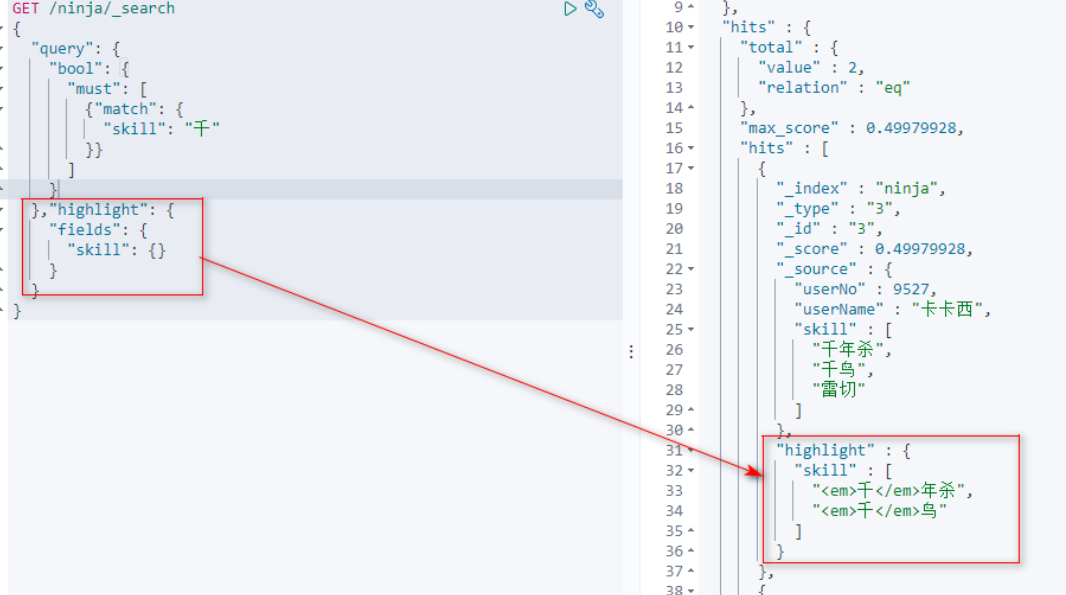
[10]精确查询
使用term就是将查询的关键字作为一个整体进行查询。
所以往往用来查询:数字,布尔,日期 文本(无法拆分)
我们现在使用term是查询不到任何信息的,是因为我们存储的数据没有使用ik分词器,所以即使我们使用的关键字是一个整体,但是索引库中拆分的关键字是一个个的单独的文字。
自定义类型
我们正常的添加一个文档到索引库:
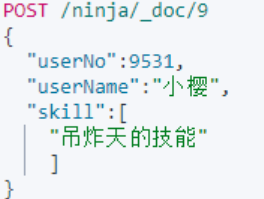
索引库或自动判断数据类型,并且进行索引的建立。
其实我们可以指定类型,就好像创建一个数据表一样
ES中的操作: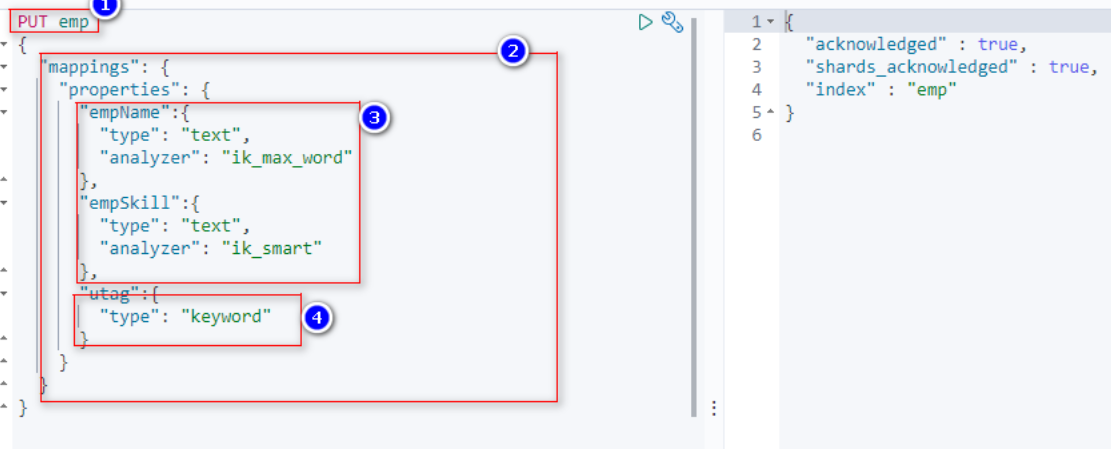
上面的操作就是在索引库中创建一个索引 emp
① 索引的名字 ② 设置这个索引的属性(列) ③ 设置empName和empSkill都是text类型,并且使用ik分词器。 ④ utag 设置关键字。 设置为关键字的列,不会被拆分。完全作为一个整体。
添加几条数据: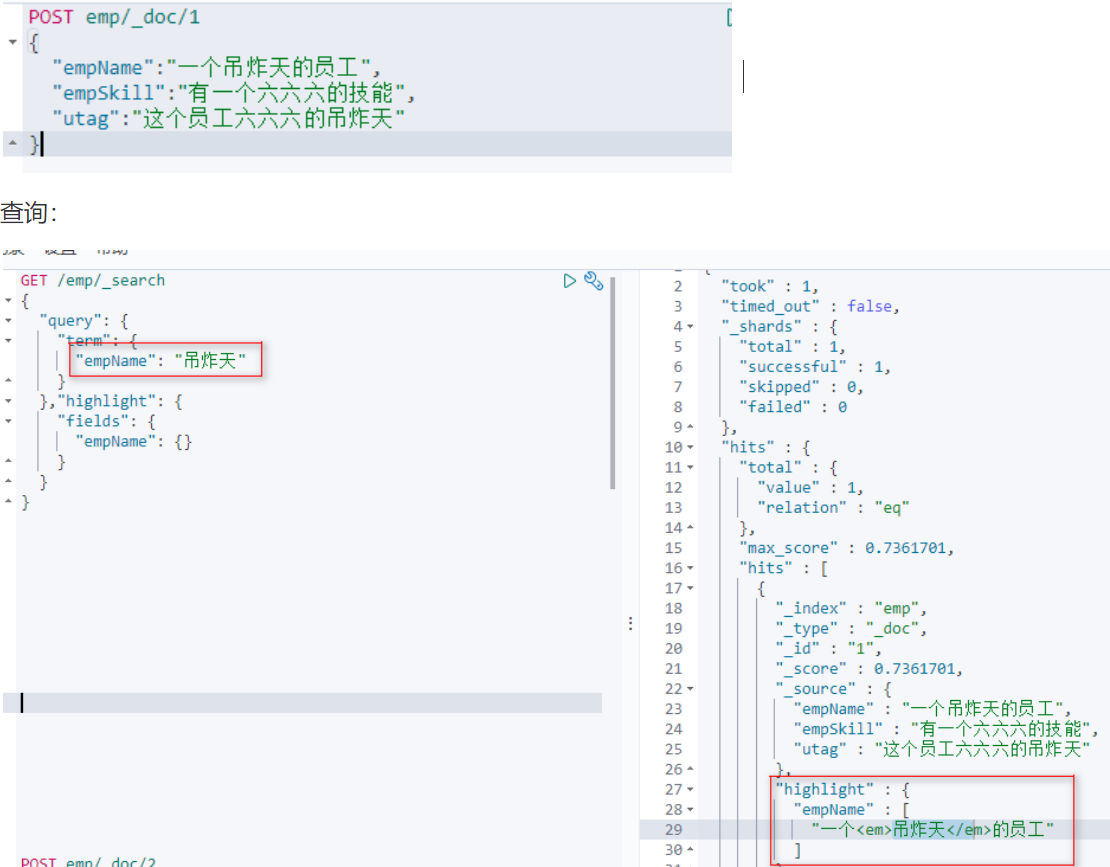

若有收获,就点个赞吧
0 人点赞
