安装
单机
- 下载安装包并解压 ```bash wget -P /usr/local https://download.redis.io/releases/redis-6.2.5.tar.gz
进入到下载目录下
cd /usr/local tar -zxvf redis-6.2.5.tar.gz
- 安装[gcc](http://ftp.gnu.org/gnu/gcc/)运行环境```bash# 查看gcc版本,如果没有请安装gcc -vyum install centos-release-scl -yyum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils# 设置环境设置,二选一# 临时有效scl enable devtoolset-9 bash# 长期有效echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
安装redis
# 进入redis解压目录下cd /usr/local/redis-6.2.5/make install PREFIX=/usr/local/bin/redis-6.2.5
启动redis ```bash
复制redis解压目录下的配置文件到redis安装目录中(即存放redis命令的目录)
cp /usr/local/redis-6.2.5/redis.conf /usr/local/bin/redis-6.2.5/bin/
进入存放redis命令的目录下
cd /usr/local/bin/redis-6.2.5/bin/
修改redis配置文件
vi ./redis.conf +———————————————————————————— | bind 0.0.0.0 # 允许任意ip访问 | protected-mode no # 允许远程访问 | daemonize yes # 后台运行 +————————————————————————————
启动redis
./redis-server ./redis.conf
查看redis进程
ps -ef | grep redis
关闭redis
./redis-cli shutdown
- 开启远程访问权限```bash# 开放防火墙端口,重启,查看开放端口sudo firewall-cmd --zone=public --add-port=6379/tcp --permanentsudo firewall-cmd --reloadsudo firewall-cmd --list-ports
主从
复制原理
全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中;
增量复制:master继续将新的所有收集到的修改命令一次传给slave ,完成同步;
slave启动成功连接到master后会发送一个sync命令,master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集指令,在后台进程执行完毕之后,master将传送整个数据文件到slave进行一次全量复制。之后msater还有新数据将进行增量复制。
ps:只要重新连接master ,就会自动进行全量复制。
搭建过程
一主两从:
主机:192.168.73.132
主节点:6379
从节点:6380、6381
命令方式
复制3份配置文件
cp redis.conf redis6379.confcp redis.conf redis6380.confcp redis.conf redis6381.conf
修改两个从节点配置文件中的信息,以6380为例 ``` bind 0.0.0.0 protected-mode no daemonize yes
port 6380 pidfile /var/run/redis_6380.pid logfile “/usr/local/bin/redis-6.2.5/bin/log6380.log” dbfilename dump6380.rdb
- 启动三个服务实例```bash./redis-server ./redis6379.conf./redis-server ./redis6380.conf./redis-server ./redis6381.conf
- 将6380、6381配置为从节点,以6380为例
./redis-cli -p 6380 # 连接到6380的客户端slaveof 192.168.73.132 6379 # 隶属于6379info replication # 查看主从状态信息exit # 退出客户端
ps:不难想到的是这种方式当从节点重启后配置会失效,需要重新用命令行配置才行。
配置方式
复制3份配置文件
cp redis.conf redis6379.confcp redis.conf redis6380.confcp redis.conf redis6381.conf
修改两个从节点配置文件中的信息,以6380为例 ``` bind 0.0.0.0 protected-mode no daemonize yes
port 6380 pidfile /var/run/redis_6380.pid logfile “/usr/local/bin/redis-6.2.5/bin/log6380.log” dbfilename dump6380.rdb replicaof 192.168.73.132 6379
- 启动三个服务实例```bash./redis-server ./redis6379.conf./redis-server ./redis6380.conf./redis-server ./redis6381.conf
链式
上述方式均为从节点连接主节点,还有链式连接:master→slave1→slave2→…
这种模式当主节点挂掉后,可以手动选一个新的主节点出来,不过并不靠谱。
slaveof no one
ps:只有这种模式才可以怎么做,因为slave直接有直接的联系
哨兵
概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行,其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个 Redis 实例。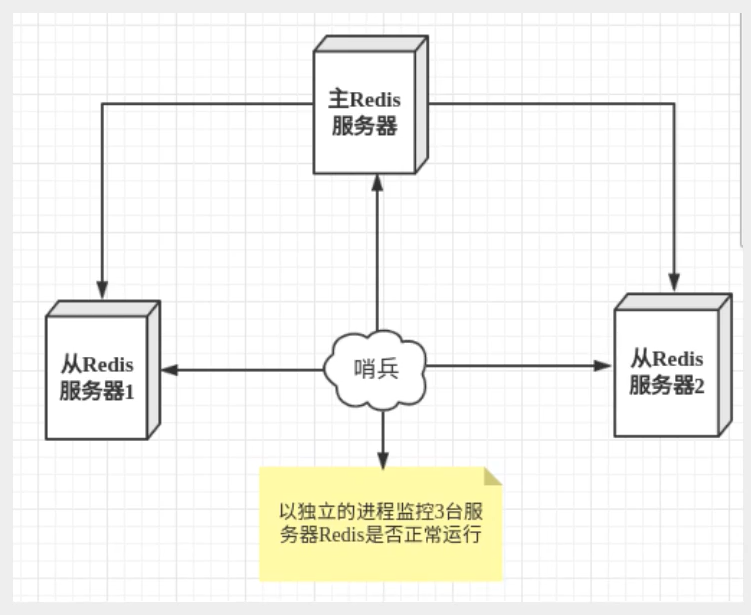
哨兵有两个作用:
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成 master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而,一个哨兵进程对Redis服务器进行监控,也可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。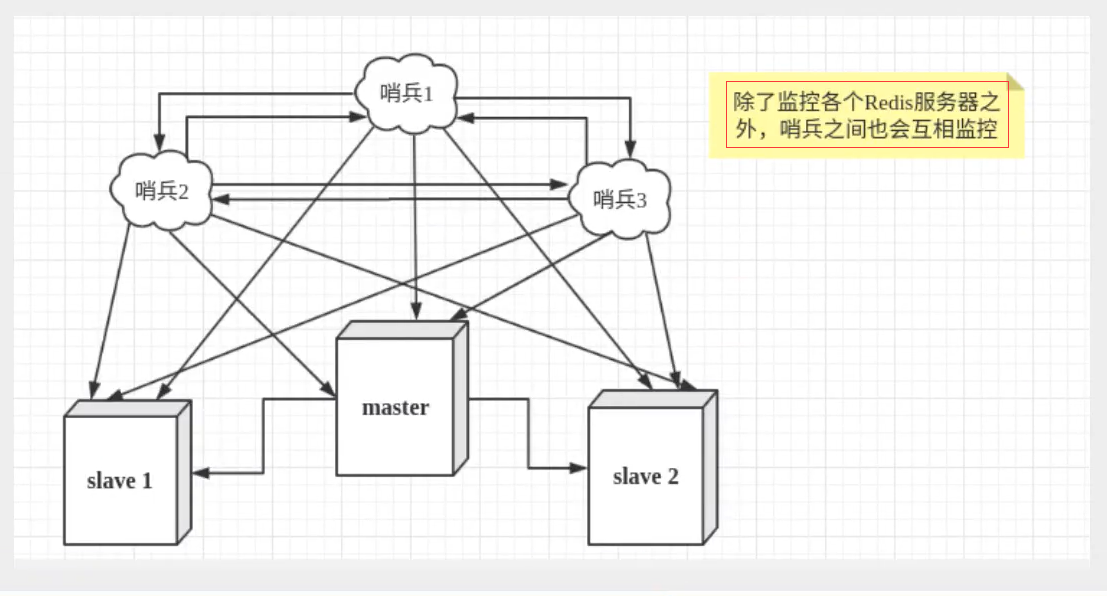
假设主服务宕机,哨兵1先检测到这个结果,系统并不会马上进行failover(故障转移)过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。
搭建过程
一主两从三哨兵:
主机:192.168.73.132
主节点:6379
从节点:6380、6381
哨兵:哨兵为奇数个,防止平票现象发生
复制3份配置文件
cp redis.conf redis6379.confcp redis.conf redis6380.confcp redis.conf redis6381.conf
修改两个从节点配置文件中的信息,以6380为例 ``` bind 0.0.0.0 protected-mode no daemonize yes
port 6380 pidfile /var/run/redis_6380.pid dbfilename dump6380.rdb replicaof 192.168.73.132 6379
- 启动三个服务实例```bash./redis-server ./redis6379.conf./redis-server ./redis6380.conf./redis-server ./redis6381.conf
- 创建3个如下形式的哨兵配置文件,以其中一个为例
```bash
vi sentinel1.conf
+———————————————————————————-
| # 当前Sentinel服务运行的端口,端口号一般是redis主服务器的端口号加上2000
| port 26379
| # 后台启动 | daemonize yes | # 哨兵监听的主服务器,且主实例判断为失效至少需要2个Sentinel的同意 | sentinel monitor redis6379 192.168.73.132 6379 2 | | # 3s内redis6379无响应,则认为redis6379宕机了 | #sentinel down-after-milliseconds redis6379 3000 | # 如果10秒后,redis6379仍没启动过来,则启动failover
| #sentinel failover-timeout redis6379 10000
| # 执行故障转移时,最多有1个从服务器同时对新的主服务器进行同步 | #sentinel parallel-syncs redis6379 1 +———————————————————————————-
sentinel2.conf、sentinel3.conf
- 启动哨兵,哨兵会自动监视节点与其它哨兵```bash./redis-sentinel ./sentinel1.conf./redis-sentinel ./sentinel2.conf./redis-sentinel ./sentinel3.conf# 查询主节点信息./redis-cli -h 192.168.73.132 -p 6379info replication
集群🔥
相关概念
分片原理
Redis集群没有选用一致性哈希,而是采用了哈希槽的这种概念。主要的原因就是因为一致性哈希算法对于数据分布、节点位置的控制并不是很友好。
首先哈希槽其实是两个概念,第一个是哈希算法。Redis Cluster的hash算法不是简单的hash(),而是crc16算法,一种校验算法。 另外一个就是槽位的概念,空间分配的规则。其实哈希槽的本质和一致性哈希算法非常相似,不同点就是对于哈希空间的定义。一致性哈希的空间是一个圆环,节点分布是基于圆环的,无法很好的控制数据布。而Redis Cluster的槽位空间是自定义分配的,类似于Windows盘分区的概念。这种分区是可以自定 义大小,自定义位置的。
Redis Cluster包含了16384个哈希槽0~16383,每个Key通过计算后都会落在具体一个槽位上,而这个槽位是属于哪个存储节点的,则由用户自己定义分配。例如机器硬盘小的,可以分配少一点槽位,硬盘大的可以分配多点。如果节点硬盘都差不多则可以平均分配。所以哈希槽这种概念很好地解决了一致性哈希的弊端。
另外在容错性和扩展性上,表象与一致性哈希一样,都是对受影响的数据进行转移。而哈希槽本质上是对槽位的转移,把故障节点负责的槽位转移到其他正常的节点上。扩展节点也是一样,把其他节点上的槽位转移到新的节点上。 但一定要注意的是,对于槽位的转移和分派,Redis集群是不会自动进行的,而是需要人工配置的。所以Redi集群的高可用是依赖于节点的主从复制与主从间的自动故障转移。
通信机制
在Redis集群中,数据节点提供两个TCP端口,在配置防火墙时需要同时开启下面两类端口:
- 普通端口:即客户端访问端口,如默认的6379;
- 集群端口:普通端口号加10000,如6379的集群端口为16379,用于集群节点之间的通讯;
集群间发送的Gossip消息有下面五种消息类型:
- MEET:在节点握手阶段,对新加入的节点发送meet消息,请求新节点加入当前集群,新节点收到消息会回复PONG消息;
- PING:节点之间互相发送ping消息,收到消息的会回复pong消息。ping消息内容包含本节点和其他节点的状态信息,以此达到状态同步;
- PONG:pong消息包含自身的状态数据,在接收到ping或meet消息时会回复pong消息,也会主动向集群广播pong消息;
- FAIL:当一个主节点判断另一个主节点进入fail状态时,会向集群广播这个消息,接收到的节点会保存该消息并对该fail节点做状态判断;
- PUBLISH:当节点收到publish命令时,会先执行命令,然后向集群广播publish消息,接收到消息的节点也会执行publish命令;
集群的节点之间通讯采用Gossip协议,节点根据固定频率(每秒10次)定时任务进行判断,当集群状态发 生变化,如增删节点、槽状态变更时,会通过节点间通讯同步集群状态,使集群收敛。
选举机制
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
- slave发现自己的master变为FAIL;
- 将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST信息;
- 其他节点收到该信息,只有master响应,判断请求者的合法性, 并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack;
- 尝试failover的slave收集FAILOVER_AUTH_ACK;
- 超过半数后变成新Master
- 广播Pong通知其他集群节点。
从节点并不是在主节点一进入FAIL状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状 态,可能会拒绝投票。
延迟计算式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000msSLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。
理论上这种方式下,持有最新数据的slave将会首先发起选举。
请求重定向
当客户端向一个”错误”的节点发出了指令,该节点会发现指令的key所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去 连这个节点去获取数据。客户端收到指令后除了跳转到正确的节点上去操作,还会同步更新纠正 本地的槽位映射表缓存,后续所有key将使用新的槽位映射表。
集群方式没有为客户端提供代理,所以说客户端连接集群可能需要一次重定向。
搭建过程
三主三从:
主机:192.168.73.132
各节点:6379、6380、6381、6382、6383、6384
集群搭建
创建redis-cluster文件夹,然后在其下创建6个文件夹用于存放个节点的配置
mkdir -p /usr/local/bin/redis-6.2.5/bin/redis-clustercd /usr/local/bin/redis-6.2.5/bin/redis-clustermkdir 6379 6380 6381 6382 6383 6384
将
redis.conf配置文件复制到redis-cluster文件加下的6个文件夹中echo 6379 6380 6381 6382 6383 6384 | xargs -n1 cp -v /usr/local/bin/redis-6.2.5/bin/redis.conf
修改文件夹中redis.conf配置文件的信息,以6379为例
vi ./6379/redis.conf+--------------------------------------------------| bind 0.0.0.0| protected-mode no| daemonize yes| appendonly yes|| port 6379| pidfile /var/run/redis_6379.pid| appendfilename "appendonly6379.aof"| # 数据文件存放位置| dir /usr/local/bin/redis-6.2.5/bin/redis-cluster/6379/|| cluster-enabled yes| cluster-config-file nodes-6379.conf| cluster-node-timeout 5000+--------------------------------------------------
如果不想一个一个改,可以批量替换文件中的内容,以6380为例 ```bash
sed -i “s/查找字段/替换字段/g”
grep 查找字段 -rl 路径sed -i “s/6379/6380/g”
grep 6379 -rl /usr/local/bin/redis-6.2.5/bin/redis-cluster/6380/redis.conf
ps:记得也要检查一下,防止不小心出错哦
- 启动6个redis实例```bashcd .././redis-server ./redis-cluster/6379/redis.conf./redis-server ./redis-cluster/6380/redis.conf./redis-server ./redis-cluster/6381/redis.conf./redis-server ./redis-cluster/6382/redis.conf./redis-server ./redis-cluster/6383/redis.conf./redis-server ./redis-cluster/6384/redis.conf# 查看redis进程ps -ef | grep redis
- 创建redis集群
```bash
1代表每个主服务器配置1个从服务器
./redis-cli —cluster create —cluster-replicas 1 192.168.73.132:6379 192.168.73.132:6380 192.168.73.132:6381 192.168.73.132:6382 192.168.73.132:6383 192.168.73.132:6384
yes
- 连接任意节点,查看相关信息```bash./redis-cli -c -h 192.168.73.132 -p 6379cluster nodes # 查看节点列表cluster info # 查看集群信息
扩容
新添一主一从:
主:6385
从:6386
- 按之前的方法修改6385、6386中redis.conf参数,修改完成后启动redis实例
新增6385、6386节点,6384为已知节点(任意节点即可)
./redis-cli --cluster add-node 192.168.73.132:6385 192.168.73.132:6384./redis-cli --cluster add-node 192.168.73.132:6386 192.168.73.132:6384
为6385新增主节点分配哈希槽,找到集群中的任意一个主节点,对其进行重新分片
# 进行此操作前,应先查询集群节点中6385的节点id,因为分配时需要用到这个节点id./redis-cli --cluster reshard 192.168.73.132:6379
新增6386为6385的从节点,客户端连接6386指定6385的节点id即可 ```bash ./redis-cli -h 192.168.73.132 -p 6386
master-nodeid为6386的主节点id
cluster replicate master-nodeid
<a name="Ik3ww"></a>#### 缩容- 删除6386从节点,因为集群中从节点不提供读写功能,只提供备份功能保持高可用,所以可以直接删除```bash# nodeid为6386的节点id./redis-cli --cluster del-node 192.168.73.132:6386 nodeid
- 删除6385主节点,需要迁移数据后才能删除
```bash
先把slot数据迁移到一个master节点上面
./redis-cli —cluster reshard 192.168.73.132:6379 => 选择一个接受的master节点di => 输入6385的节点id done
nodeid为6385的节点id
./redis-cli —cluster del-node 192.168.73.132:6385 nodeid
<a name="ow3at"></a># Spring Boot集成<a name="sQHG4"></a>## 前提- 引入maven依赖- spring-boot-starter-data-redis- commons-pool2- `application.yml`配置```yamlspring:redis:host: 192.168.73.132port: 6379database: 0password: qw1028# 连接超时时间timeout: 2000lettuce:pool:# 最大连接数max-active: 20# 最大阻塞等待时间,负数为无限制max-wait: -1# 连接池最大空闲连接max-idle: 5# 连接池最小空闲连接min-idle: 5
Redis
- 可以直接使用,这里还装配了常用的类型
@Configurationpublic class RedisConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);RedisSerializer<String> stringRedisSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer<Object> serializer = new Jackson2JsonRedisSerializer<>(Object.class);redisTemplate.setKeySerializer(stringRedisSerializer);redisTemplate.setValueSerializer(serializer);redisTemplate.setHashKeySerializer(stringRedisSerializer);redisTemplate.setHashValueSerializer(serializer);redisTemplate.setDefaultSerializer(stringRedisSerializer);return redisTemplate;}}
Redis缓存
装配redis缓存配置
@EnableCaching@Configurationpublic class RedisCacheConfig extends CachingConfigurerSupport {@Beanpublic CacheManager cacheManager(RedisConnectionFactory factory) {RedisSerializer<String> stringRedisSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);// 解决查询缓存转换异常的问题ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);om.activateDefaultTyping(om.getPolymorphicTypeValidator(), ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(om);// 配置序列化,解决乱码的问题RedisCacheConfiguration config =RedisCacheConfiguration.defaultCacheConfig()// 缓存过期时间.entryTtl(Duration.ofMinutes(10)).serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(stringRedisSerializer)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer)).disableCachingNullValues();return RedisCacheManager.builder(factory).cacheDefaults(config).build();}}
使用 ```java // 如果设置 sync=true // 1、如果缓存中没有数据,多个线程同时访问这个方法,则只有一个方法会执行到方法,其它方法需要等待 // 2、如果缓存中已经有数据,则多个线程可以同时从缓存中获取数据 @Cacheable(value = “student”, key = “#student.id”, sync = true) public Student method1(Student student) { return student; }
// 条件缓存,只有满足condition的请求才可以进行缓存 @Cacheable(value = “student”, condition = “T(java.lang.Integer).parseInt(#student.id) < 3 “) public Student method2(Student student) { return student; }
// 对不满足unless的记录,才进行缓存 @Cacheable(value = “student”, unless = “T(java.lang.Integer).parseInt(#student.id) < 3 “) public Student method3(Student student) { return student; }
// 如果需要自定义定制key可以使用这个,但是key和keyGenerator是互斥,如果同时指定会出异常 @Cacheable(value = “student”, keyGenerator = “myKeyGenerator”) public Student method4(Student student) { return student; }
// 无论缓存里是否有值,每次执行都会执行方法替换缓存中的值 @CachePut(cacheNames = “student”, key = “#student.id”) public Student method5(Student student) { return student; }
// allEntries为true,则清空student中的所有缓存 @CacheEvict(cacheNames = “student”, allEntries = true) public void clear() {}
// 对符合key条件的记录从缓存中student移除 @CacheEvict(cacheNames = “student”, key = “#id”) public void remove(Integer id) {} ```

若有收获,就点个赞吧
0 人点赞
