一、概念
跳表(SkipList)是一种增加多级索引结构的链表。相比一般的链表,有更高的查找效率,跳表的查找、插入、删除时间复杂度都是O(logn),在某些场景下使用跳表相较于红黑树更合适。
许多知名的开源软件(库)中的数据结构都采用了跳表这种数据结构。例如:
- Redis中的有序集合zset
- LevelDB、RocksDB、HBase中Memtable
- ApacheLucene中的TermDictionary、Posting List
二、底层原理
单链表在做查询操作时,只能从头到尾遍历链表,查询的时间复杂度为O(n):
对链表建立一级索引,每两个节点提取一个节点到上一级。图中的down指针指向下一级节点:
如果现在要查找某个结点,比如 16。可以先在索引层遍历,当遍历到索引层中值为 13 的结点时,我们发现下一个结点是 17,那要查找的结点 16 肯定就在这两个结点之间。然后通过索引层结点的 down 指针,下降到原始链表这一层,继续遍历。这个时候,只需要再遍历 2 个结点,就可以找到值等于 16 的这个结点了。这样,原来如果要查找 16,需要遍历 10 个结点,现在只需要遍历 7 个结点。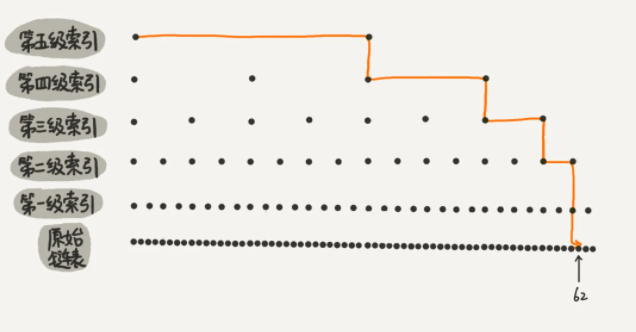
通过增加多级索引层,可以看出,原来没有索引的时候,查找 62 需要遍历 62 个结点,现在只需要遍历 11 个结点。所以当链表的长度 n 比较大时,比如 1000、10000 的时候,在构建索引之后,查找效率的提升就会非常明显。
跳表结构其实就是利用空间置换时间。比起单纯的链表,跳表需要存储多级索引,空间复杂度是O(n)。
但实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
三、代码实现
package com.study.skiplist;import java.util.Random;/*** 1,跳表的一种实现方法,用于练习。跳表中存储的是正整数,并且存储的是不重复的。* 2,本类是参考作者zheng ,自己学习,优化了添加方法* 3,看完这个,我觉得再看ConcurrentSkipListMap 源码,会有很大收获* Author:ldb*/public class SkipList2 {private static final int MAX_LEVEL = 16;private int levelCount = 1;/*** 带头链表*/private Node head = new Node(MAX_LEVEL);private Random r = new Random();public Node find(int value) {Node p = head;// 从最大层开始查找,找到前一节点,通过--i,移动到下层再开始查找for (int i = levelCount - 1; i >= 0; --i) {while (p.forwards[i] != null && p.forwards[i].data < value) {// 找到前一节点p = p.forwards[i];}}if (p.forwards[0] != null && p.forwards[0].data == value) {return p.forwards[0];} else {return null;}}/*** 优化了作者zheng的插入方法** @param value 值*/public void insert(int value) {int level = head.forwards[0] == null ? 1 : randomLevel();// 每次只增加一层,如果条件满足if (level > levelCount) {level = ++levelCount;}Node newNode = new Node(level);newNode.data = value;Node update[] = new Node[level];for (int i = 0; i < level; ++i) {update[i] = head;}Node p = head;// 从最大层开始查找,找到前一节点,通过--i,移动到下层再开始查找for (int i = levelCount - 1; i >= 0; --i) {while (p.forwards[i] != null && p.forwards[i].data < value) {// 找到前一节点p = p.forwards[i];}// levelCount 会 > level,所以加上判断if (level > i) {update[i] = p;}}for (int i = 0; i < level; ++i) {newNode.forwards[i] = update[i].forwards[i];update[i].forwards[i] = newNode;}}/*** 优化了作者zheng的插入方法2** @param value 值*/public void insert2(int value) {int level = head.forwards[0] == null ? 1 : randomLevel();// 每次只增加一层,如果条件满足if (level > levelCount) {level = ++levelCount;}Node newNode = new Node(level);newNode.data = value;Node p = head;// 从最大层开始查找,找到前一节点,通过--i,移动到下层再开始查找for (int i = levelCount - 1; i >= 0; --i) {while (p.forwards[i] != null && p.forwards[i].data < value) {// 找到前一节点p = p.forwards[i];}// levelCount 会 > level,所以加上判断if (level > i) {if (p.forwards[i] == null) {p.forwards[i] = newNode;} else {Node next = p.forwards[i];p.forwards[i] = newNode;newNode.forwards[i] = next;}}}}/*** 作者zheng的插入方法,未优化前,优化后参见上面insert()** @param value* @param level 0 表示随机层数,不为0,表示指定层数,指定层数* 可以让每次打印结果不变动,这里是为了便于学习理解*/public void insert(int value, int level) {// 随机一个层数if (level == 0) {level = randomLevel();}// 创建新节点Node newNode = new Node(level);newNode.data = value;// 表示从最大层到低层,都要有节点数据newNode.maxLevel = level;// 记录要更新的层数,表示新节点要更新到哪几层Node update[] = new Node[level];for (int i = 0; i < level; ++i) {update[i] = head;}/**** 1,说明:层是从下到上的,这里最下层编号是0,最上层编号是15* 2,这里没有从已有数据最大层(编号最大)开始找,(而是随机层的最大层)导致有些问题。* 如果数据量为1亿,随机level=1 ,那么插入时间复杂度为O(n)*/Node p = head;for (int i = level - 1; i >= 0; --i) {while (p.forwards[i] != null && p.forwards[i].data < value) {p = p.forwards[i];}// 这里update[i]表示当前层节点的前一节点,因为要找到前一节点,才好插入数据update[i] = p;}// 将每一层节点和后面节点关联for (int i = 0; i < level; ++i) {// 记录当前层节点后面节点指针newNode.forwards[i] = update[i].forwards[i];// 前一个节点的指针,指向当前节点update[i].forwards[i] = newNode;}// 更新层高if (levelCount < level) levelCount = level;}public void delete(int value) {Node[] update = new Node[levelCount];Node p = head;for (int i = levelCount - 1; i >= 0; --i) {while (p.forwards[i] != null && p.forwards[i].data < value) {p = p.forwards[i];}update[i] = p;}if (p.forwards[0] != null && p.forwards[0].data == value) {for (int i = levelCount - 1; i >= 0; --i) {if (update[i].forwards[i] != null && update[i].forwards[i].data == value) {update[i].forwards[i] = update[i].forwards[i].forwards[i];}}}}/*** 随机 level 次,如果是奇数层数 +1,防止伪随机** @return*/private int randomLevel() {int level = 1;for (int i = 1; i < MAX_LEVEL; ++i) {if (r.nextInt() % 2 == 1) {level++;}}return level;}/*** 打印每个节点数据和最大层数*/public void printAll() {Node p = head;while (p.forwards[0] != null) {System.out.print(p.forwards[0] + " ");p = p.forwards[0];}System.out.println();}/*** 打印所有数据*/public void printAll_beautiful() {Node p = head;Node[] c = p.forwards;Node[] d = c;int maxLevel = c.length;for (int i = maxLevel - 1; i >= 0; i--) {do {System.out.print((d[i] != null ? d[i].data : null) + ":" + i + "-------");} while (d[i] != null && (d = d[i].forwards)[i] != null);System.out.println();d = c;}}/*** 跳表的节点,每个节点记录了当前节点数据和所在层数数据*/public class Node {private int data = -1;/*** 表示当前节点位置的下一个节点所有层的数据,从上层切换到下层,就是数组下标-1,* forwards[3]表示当前节点在第三层的下一个节点。*/private Node forwards[];/*** 这个值其实可以不用,看优化insert()*/private int maxLevel = 0;public Node(int level) {forwards = new Node[level];}@Overridepublic String toString() {StringBuilder builder = new StringBuilder();builder.append("{ data: ");builder.append(data);builder.append("; levels: ");builder.append(maxLevel);builder.append(" }");return builder.toString();}}public static void main(String[] args) {SkipList2 list = new SkipList2();list.insert(1, 3);list.insert(2, 3);list.insert(3, 2);list.insert(4, 4);list.insert(5, 10);list.insert(6, 4);list.insert(8, 5);list.insert(7, 4);list.printAll_beautiful();list.printAll();/*** 结果如下:* null:15-------* null:14-------* null:13-------* null:12-------* null:11-------* null:10-------* 5:9-------* 5:8-------* 5:7-------* 5:6-------* 5:5-------* 5:4------- 8:4-------* 4:3-------5:3-------6:3-------7:3-------8:3-------* 1:2-------2:2------- 4:2-------5:2-------6:2-------7:2-------8:2-------* 1:1-------2:1-------3:1-------4:1-------5:1-------6:1-------7:1-------8:1-------* 1:0-------2:0-------3:0-------4:0-------5:0-------6:0-------7:0-------8:0-------* { data: 1; levels: 3 } { data: 2; levels: 3 } { data: 3; levels: 2 } { data: 4; levels: 4 }* { data: 5; levels: 10 } { data: 6; levels: 4 } { data: 7; levels: 4 } { data: 8; levels: 5 }*/// 优化后insert()SkipList2 list2 = new SkipList2();list2.insert2(1);list2.insert2(2);list2.insert2(6);list2.insert2(7);list2.insert2(8);list2.insert2(3);list2.insert2(4);list2.insert2(5);System.out.println();list2.printAll_beautiful();}}
随机函数
private int randomLevel1() {int level = 1;for (int i = 1; i < MAX_LEVEL; ++i) {if (r.nextInt() % 2 == 1) {level++;}}return level;}private int randomLevel2() {int level = 1;while (Math.random() < SKIPLIST_P && level < MAX_LEVEL)level += 1;return level;}
理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
- 50%的概率返回 1
- 25%的概率返回 2
-
四、使用场景
Redis 中的有序集合是通过跳表来实现的,严格点讲,其实还用到了散列表。如果查看 Redis 的开发手册,就会发现,Redis 中的有序集合支持的核心操作主要有下面这几个:
插入一个数据;
- 删除一个数据;
- 查找一个数据;
- 按照区间查找数据(比如查找值在[100, 356]之间的数据);
- 迭代输出有序序列。
其中,插入、删除、查找以及迭代输出有序序列这几个操作,红黑树也可以完成,时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
对于按照区间查找数据这个操作,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,这样做非常高效。
参考资料:《数据结构与算法之美》- 17 | 跳表:为什么Redis一定要用跳表来实现有序集合?

若有收获,就点个赞吧
0 人点赞
