一、排序方法与复杂度归类
(1)几种最经典、最常用的排序方法:
冒泡排序、插入排序、选择排序、快速排序、归并排序、计数排序、基数排序、桶排序。
(2)复杂度归类
冒泡排序、插入排序、选择排序 O(n^2)
快速排序、归并排序 O(nlogn)
计数排序、基数排序、桶排序 O(n)
二、如何分析一个“排序算法”?
<1>算法的执行效率
- 最好、最坏、平均情况时间复杂度。
2. 时间复杂度的系数、常数和低阶。
3. 比较次数,交换(或移动)次数。<2>排序算法的稳定性
- 稳定性概念:如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
2. 稳定性重要性:可针对对象的多种属性进行有优先级的排序。
3. 举例:给电商交易系统中的“订单”排序,按照金额大小对订单数据排序,对于相同金额的订单以下单时间早晚排序。用稳定排序算法可简洁地解决。先按照下单时间给订单排序,排序完成后用稳定排序算法按照订单金额重新排序。<3>排序算法的内存损耗
原地排序算法:特指空间复杂度是O(1)的排序算法。
三、冒泡排序
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求,如果不满足就让它俩互换。
稳定性:冒泡排序是稳定的排序算法。
空间复杂度:冒泡排序是原地排序算法。
时间复杂度:
1. 最好情况(满有序度):O(n)。
2. 最坏情况(满逆序度):O(n^2)。
3. 平均情况:
“有序度”和“逆序度”:对于一个不完全有序的数组,如4,5,6,3,2,1,有序元素对为3个(4,5),(4,6),(5,6),有序度为3,逆序度为12;对于一个完全有序的数组,如1,2,3,4,5,6,有序度就是n(n-1)/2,也就是15,称作满有序度;逆序度=满有序度-有序度;冒泡排序、插入排序交换(或移动)次数=逆序度。
最好情况下初始有序度为n(n-1)/2,最坏情况下初始有序度为0,则平均初始有序度为n(n-1)/4,即交换次数为n(n-1)/4,因交换次数<比较次数<最坏情况时间复杂度,所以平均时间复杂度为O(n^2)。
// 冒泡排序,a表示数组,n表示数组大小public void bubbleSort(int[] a, int n) {if (n <= 1) return;for (int i = 0; i < n; ++i) {// 提前退出冒泡循环的标志位boolean flag = false;for (int j = 0; j < n - i - 1; ++j) {if (a[j] > a[j+1]) { // 交换int tmp = a[j];a[j] = a[j+1];a[j+1] = tmp;flag = true; // 表示有数据交换}}if (!flag) break; // 没有数据交换,提前退出}}
四、插入排序
插入排序将数组数据分成已排序区间和未排序区间。初始已排序区间只有一个元素,即数组第一个元素。在未排序区间取出一个元素插入到已排序区间的合适位置,直到未排序区间为空。
空间复杂度:插入排序是原地排序算法。
时间复杂度:
1. 最好情况:O(n)。
2. 最坏情况:O(n^2)。
3. 平均情况:O(n^2)(往数组中插入一个数的平均时间复杂度是O(n),一共重复n次)。
稳定性:插入排序是稳定的排序算法。
// 插入排序,a表示数组,n表示数组大小public void insertionSort(int[] a, int n) {if (n <= 1) return;for (int i = 1; i < n; ++i) {int value = a[i];int j = i - 1;// 查找插入的位置for (; j >= 0; --j) {if (a[j] > value) {a[j+1] = a[j]; // 数据移动} else {break;}}a[j+1] = value; // 插入数据}}
五、选择排序
选择排序将数组分成已排序区间和未排序区间。初始已排序区间为空。每次从未排序区间中选出最小的元素插入已排序区间的末尾,直到未排序区间为空。
空间复杂度:选择排序是原地排序算法。
时间复杂度:(都是O(n^2))
1. 最好情况:O(n^2)。
2. 最坏情况:O(n^2)。
3. 平均情况:O(n^2)。
稳定性:选择排序不是稳定的排序算法。
问题:选择排序和插入排序的时间复杂度相同,都是O(n^2),在实际的软件开发中,为什么我们更倾向于使用插入排序而不是冒泡排序算法呢?
答:从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要3个赋值操作,而插入排序只需要1个,所以在对相同数组进行排序时,冒泡排序的运行时间理论上要长于插入排序。
六、归并排序(Merge Sort)
如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
递推公式:merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))终止条件:p >= r 不用再继续分解
稳定性:归并排序是稳定的排序算法。
空间复杂度:归并排序不是原地排序算法,空间复杂度为O(n)
时间复杂度:归并排序的执行效率与要排序的原始数组的有序程度无关,所以其时间复杂度是非常稳定的,不管是最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。
七、快速排序(Quicksort)
如果要排序数组中下标从 p 到 r 之间的一组数据,选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
根据分治、递归的处理思想,可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
递推公式:quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1… r)终止条件:p >= r
分区排序过程: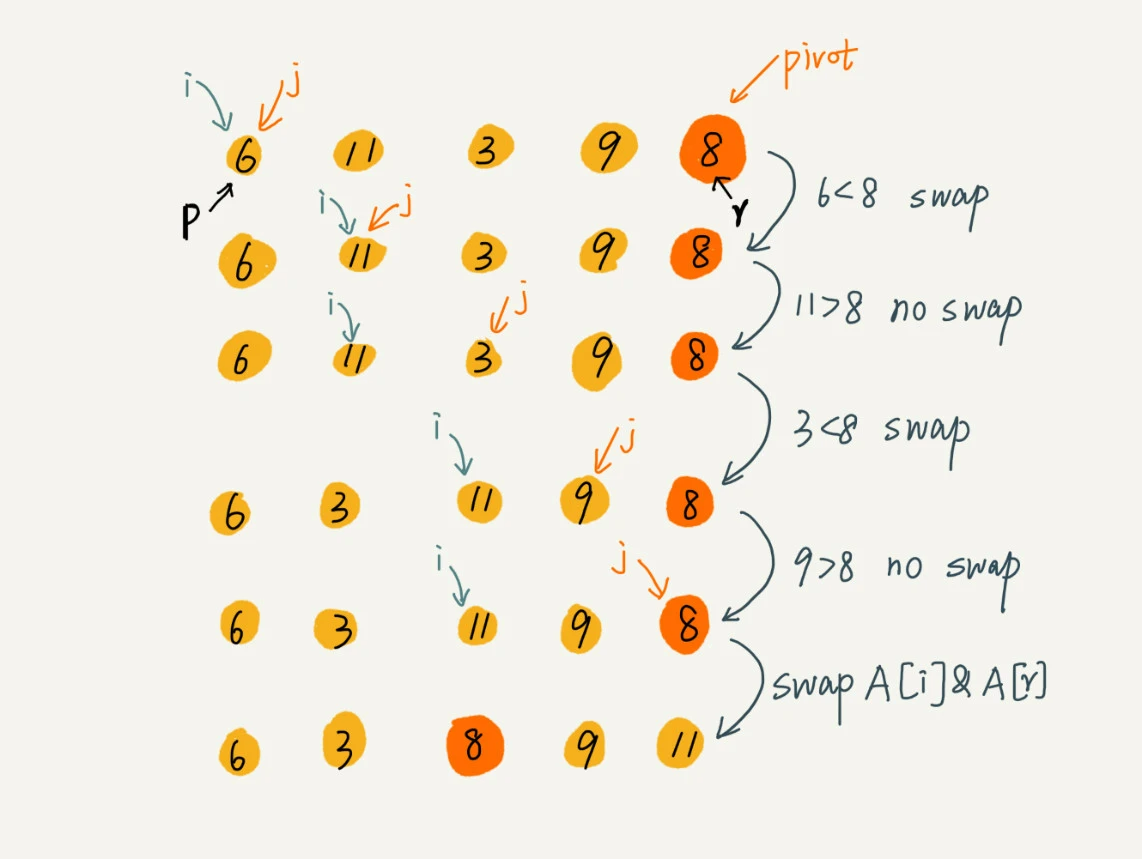
稳定性:快速排序是不稳定的排序算法。
空间复杂度:快速排序是原地排序算法。
时间复杂度:O(nlogn) ,极端情况下会退化为O(n2)。
代码实现:
/*** 快速排序* @param array*/public static void quickSort(int[] array) {int len;if(array == null|| (len = array.length) == 0|| len == 1) {return;}sort(array, 0, len - 1);}/*** 快排核心算法,递归实现* @param array* @param left* @param right*/public static void sort(int[] array, int left, int right) {if(left > right) {return;}// base中存放基准数int base = array[left];int i = left, j = right;while(i != j) {// 顺序很重要,先从右边开始往左找,直到找到比base值小的数while(array[j] >= base && i < j) {j--;}// 再从左往右边找,直到找到比base值大的数while(array[i] <= base && i < j) {i++;}// 上面的循环结束表示找到了位置或者(i>=j)了,交换两个数在数组中的位置if(i < j) {int tmp = array[i];array[i] = array[j];array[j] = tmp;}}// 将基准数放到中间的位置(基准数归位)array[left] = array[i];array[i] = base;// 递归,继续向基准的左右两边执行和上面同样的操作// i的索引处为上面已确定好的基准值的位置,无需再处理sort(array, left, i - 1);sort(array, i + 1, right);}
归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是 O(n)。正因为此,它也没有快排应用广泛。
快速排序算法虽然最坏情况下的时间复杂度是 O(n2),但是平均情况下时间复杂度都是 O(nlogn)。不仅如此,快速排序算法时间复杂度退化到 O(n2) 的概率非常小,我们可以通过合理地选择 pivot 来避免这种情况。

若有收获,就点个赞吧
0 人点赞
