自我介绍
面试官您好,我叫庄杰,目前已经有2年多的开发经验,之前在闻康集团有限公司和广州紫域网络科技有限公司担任java开发,大大小小的项目也接触不少,之前接触单体的项目用springboot搭建的项目比较多,最近在上家公司的微服务项目寻医问药,在这个项目中,我主要负责预约挂号这个服务,这个服务也算是这个项目中比较核心的业务.主要就是用户在页面可提供服务的专家列表,挂号填写自身一个个人资料,然后预约选择医院,科室,医生
看到贵公司的招聘信息,觉得自身的情况还是比较符合,所以今天非常荣幸能来到贵公司面试.
具体执行流程
用户在点击提交的时候,
客户端会将一个用户的uuid,以及医生id,医生的一个预约时间段提交到服务端
服务端中zuul网关先过滤掉一些不合理的请求之后,会去到预约挂号的一个服务,然后
我们会去判断一些情况,像用户是否登录,手机号码是否正确,是否是黑名单,是否重复预约,预约名额是否重足
因为我们对医生的预约名额做了一个本地标识的处理,然后我们会去通过这个本地标识判断医生是否预约名额是否已经满了,如果满了的话,那么我们会返回预约失败的结果给用户,
然后我们还在redis中做了一个预库存的处理,就是将每个医生各时间段的预约名额数量放到redis中,避免每次访问都去访问数据库,造成数据库的压力过大,
我们会判断这个redis中的预库存预约名额是否已经小于0的一个操作,如果小于0那么也是给用户返回一个预约失败的信息
然后就发送给MQ,MQ会马上返回一个正在预约的那么一个信息,并且MQ会将消息发送给websocket,
这时候客户端也会和websocket进行一个长连接,等待预约是否 成功的消息.
数据库执行完之后也会发送消息,如果失败就返回给到websocket,websocket消费该消息通过uuid去找到预约失败的客户端返回该失败,如果失败的话, 我们就会将预库存做一个回补还有本地标识修改的一个操作
这边预约成功了,我们也发条消息,告诉用户预约成功了,但是这里是有分情况,如果用户预约成功的话, 我们会调用阿里云的接口给用户发送已预约成功请及时支付的那么一条短信,
如果预约成功后,超时了未支付,那么我们会对redis中的预库存做一个回补,数据库回补,和修改本地标识,
如果预约成功,且在限定时间内支付了的话,那么我们会给医院端该医生发送用户下单信息,并调用阿里云的接口给用户发送预约成功,请在预约时间段就诊的那么一条信息.
简历上知识点准备
Restful
URL定位资源,用HTTP(GET,POST,DELETE)描述操作
为什么要 使用Restful?
1. 可以规范化接口访问方式1. 资源标识唯一
Redis
持久化
RDB
原理:redis单独创建(fork)一个与当前进程一模一样的子进程来进行持久化操作,这个子进程和原进程一模一样,它会将数据写到一个临时文件中,待持久化结束后,再用这个临时文件替换上次持久化好得到文件,整个过程原进程不进行任何io操作
1.为什么要fork一个子进程呢?
因为redis是单线程的,在进行的其他操作的时候,他不能去做持久化操作,如果做持久化操作,他就不能做其他的操作了,所以他需要fork一个子进程
2.如果用主进程去做持久化有什么样的一个情况
那么就会进入阻塞状态,主进程就去做持久化,大量的操作就无法进行
3.什么操作会触发持久化操作?
shoutdown的时,如果没有开启aof就会触发,
默认配置里面也会触发
4.RDB持久化机制可以关掉吗?
可以关掉,但是redis有一个主从集群的机制,如果在这个机制就关不掉,因为主机要将RDB文件发送给从机,从机进行复制
AOF
原理:保存的是命令,保存在一个aof文件
触发机制:根据配置文件配置的, 配置文件中要去开启
1.AOF对比RDB有什么优势?
AOF比RDB丢失的数据要少,RDB保存的是内存数据,而AOF是通过保存我们操作的命令,RDB是如果丢失,他丢失的是一段时间的数据,而AOF丢失的数据可能性是不会超过2秒,每一秒都会进行一个备份
2.AOF文件中除了保存操作命令,也会保存协议,就是这些命令一组的长度
aof的重写机制:
1.aof的重写机制是什么?
他就是给aof文件瘦身,比如说你incr xxx 如果这样的数据有100条,那么他就会直接set xxx 100,同时如果你是set xxx 1,然后又decr xxx 那么就会抵消掉,他就不会记录
2.什么时候会触发aof的重写机制呢?
默认到64m就会触发aof重写机制,在真实的生产是绝对回去配置这个默认64m,因为重写机也是会浪费性能的.
还有一个是增长比例,这个增长比例就是当aof文件,超过这个默认的大小,比如说默认大小是64,其增长比例设置为40%那么在超过64*0.4的时候就会去触发
redis4.0后会有一个混合持久化机制
各种集群
1.单机版
2.主从复制
读写分离: 主机写数据,从机读数据
容灾备份: 主机坏了,从机还可以去读
好处:解决了qps瓶颈,
缺点:主机挂了之后,从机没有办法自动完成主从切换
3.哨兵(自动模式的主从复制):
哨兵节点去监控我们的主节点(看他是否挂掉)
自动转移机制:如果主机关掉了,哨兵节点就会自动从从机里面选一个从机切换为主机(选取从节点的时候整个redis是不可用的)
好处:解决了我们的单机故障
缺点:在自动转移的时候,会有一个不可用的时间
4.cluster
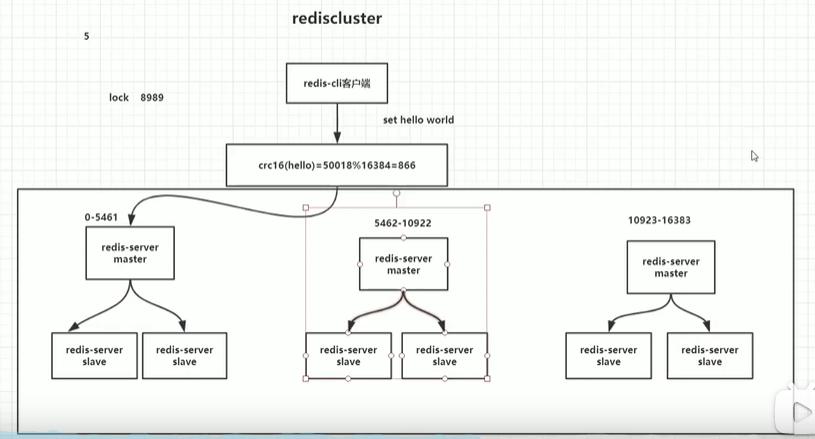
由多个哨兵模式组成,但是没哨兵节点
怎么工作的?
他会对这个命令进行crc算法进行计算,他们会16384取余,这个余就是槽位,他会对16384默认是平均分,我们也可以对其进行配置,可以根据性能进行分配
好处:一个集群挂了,还有大部分集群可以用,
缓存四大问题
1.缓存穿透
1. 什么是缓存穿透?1. 数据库当中没有的数据,缓存里面也没有的数据,就是查询的时候缓存中没有这个数据,然后去数据库里面查询,也没有,这样子就没有起到保护数据库的作用
解决方案:
1. 将空值缓存起来1. 使用布隆过滤器
2.缓存击穿
1. 什么是缓存击穿?1. 缓存中没有,数据库中有(一般缓存时间到了),这个时候由于用户特别多,同时读缓存没读到数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
1. 加锁,加互斥锁1. 多部署的话可以使用分布式锁不是的话就可以使用jvm锁
4. 缓存雪崩
1. 什么是缓存雪崩?1. 缓存雪崩就是大量缓存集中失效
解决方案:
1. 对不同的数据就使用不同的失效时间
4. 缓存与数据库数据一致性
1. 什么是缓存和数据库数据一致性1. 如果是单线程,先去更新数据库,如果缓存挂掉了怎么办,如果先更新缓存,再更新数据库,数据库挂掉了怎么办?1. 如果是多线程,a线程和b线程都要去更新name这个字段,a线程更新成李四,b线程更新成王五,a线程先更新,那么name变成李四,b线程再更新name,那么b线程覆盖成name,name变成王五,然后b线程去更新缓存时设置为王五后,a线程才去更新缓存,那么缓存中name又变为李四这样子怎么办?
Mysql优化
索引优化
二叉树
默认的右边的子节点,会要比父节点的数值要高,所以查询次数就会变少。但是这效率仍然还是不够高。
红黑树
本质还是二叉树,但是他有一个自动平衡, 全名叫平衡
优化Join关键字
在选择Join算法时,会有优先级,理论上会优先判断能否使用INLJ,BLNJ:
优先级:INLJ>BNLJ-SNLJ
Simple Nested-Loop Join (SNLJ)
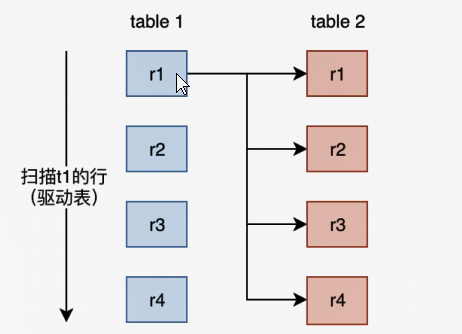
这种算法就是t1表和t2进行关联,join不是有一个on的条件吗,如果t1的r1和t2的r1条件匹配,那么就输出结果,如果不匹配那么t1那么就继续和r2去匹配,这个算法就是从t1表一直扫下去,如果t1表有1w条数据,t2有1w条数据,那么这样就有 1w*1w=1亿此 的查询判断
效率超级低
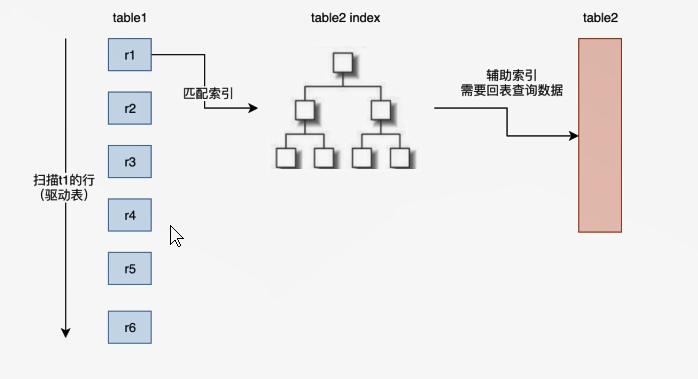
Index Nested-Loop Join (INLJ)
Block Nested-Loop Join (BLNJ)
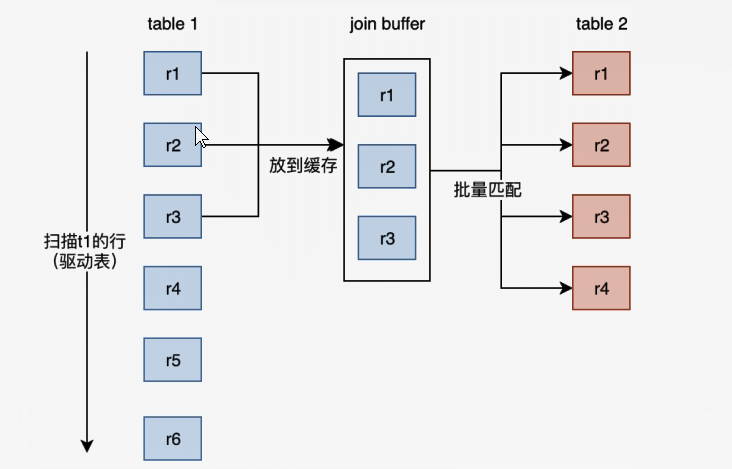
BNLJ这种就是中间有个join bulffer这样的一个缓存,然后在这个缓存里面的,就可以批量去t2表中去查询.
如何优化
1. **小结果集驱动大结果集**1. 假设两张表,小结果集没有索引,大结果集有索引.这时候我们可以用straight_join指定有索引的为驱动表,没索引为被驱动表,虽然这样会提升我们内层表的查询次数,但是所获的提升效率,可以忽略不计2. **为匹配的条件增加索引**2. **增大join buffer size的大小**2. **减少不必要的条件查询**
RocketMQ
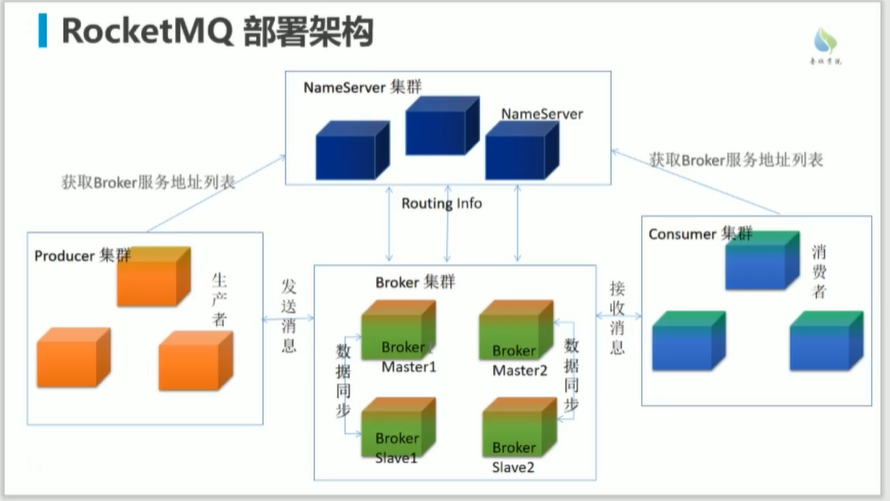
Broker集群
消息的注册,消息的存储
nameserver
相当于rocketMQ的注册中心,路由发现
producer(生产者)
生产消息
consumer(消费者)
消费消息
NameServer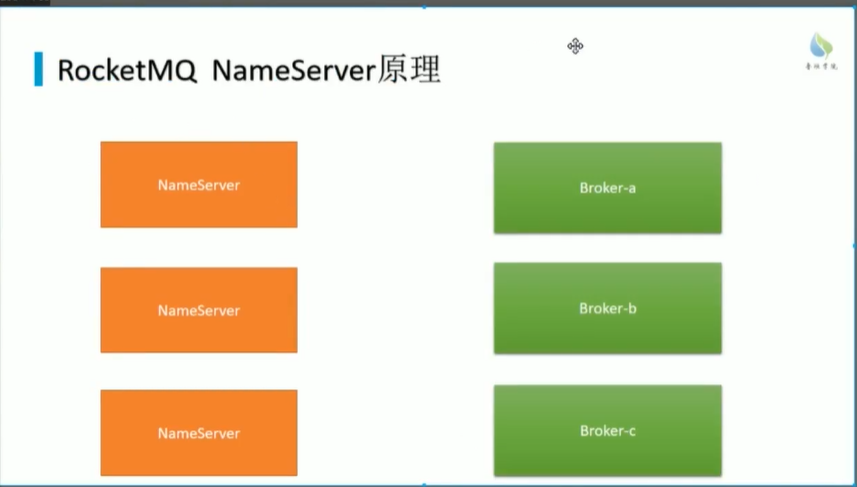
NameServer实现broker的注册中心,路由实现的呢?
NameServer需要注册什么信息?
broker的基本信息, IP和端口
主题地址信息,集群信息,存活broker信息,过滤器,
这些保存到NameServer的一个缓存当中
NameServer怎么注册到NameServer?
每十秒钟会去扫描broker
Broker多久注册一次路由信息?
每30秒中去注册路由信息
broker30s注册一次,如果出现宕机?怎么办?
通讯协议是什么?
心跳协议,通过netty来实现通讯
NameServer集群中各个节点是否会保持通信?
不会保持
那么问题来了 不保持通信,那么数据有没有可能不一致?
会不一致.
生产者是怎么发消息的?
他启动的时候会拉一个路由信息表,生产者他会去看路由信息表,这个主题在不在路由表信息里面,如果没有的话,他会去nameserver拉取一个最新的路由信息表,这样就得知发给哪个broker
发送消息的方式
同步:等待结果返回
异步:不等待结果返回,去做别的事情,后台处理再回调将结果发给我
单向:过去消息之后,就不管结果
发送过程:
1. 校验, 主题命名方式呀一些1. 拉取路由信息1. 重试机制3次1. 寻找队列1. 默认队列四个,四个读四个写 自己可以设置1. 默认是轮询去找队列
消息队列
各种消息队列产品的比较
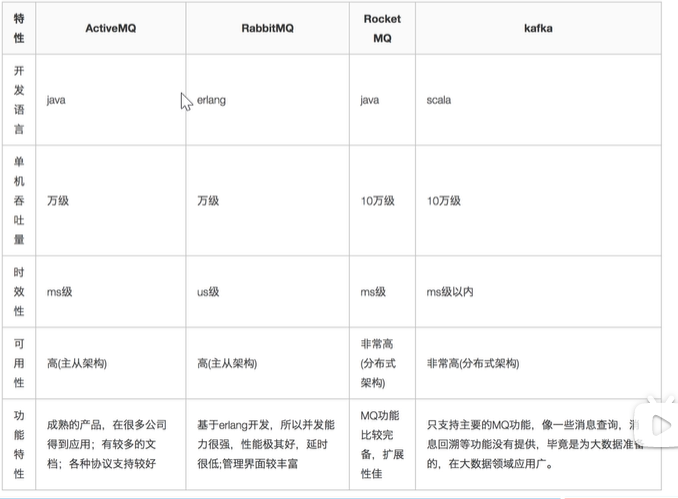
如何选用?

消息队列的优点和缺点?
优点:解耦,异步,削峰
缺点:
系统可用性降低
系统映入的外部依赖月越多,系统稳定性越差,一旦MQ宕机,就会对业务造成,影响如何解决?
做集群
系统复杂度提高
MQ的加入增加了系统的复杂度,以前系统间都是同步的远程调用,现在是通过MQ进行异步调用
1. **_消息丢失怎么办?如何保证 消息不丢失?_**1. 1. 首先我们先知道消息丢失的几种情况,1. 生产者在发送消息的时候,丢失1. 发送到MQ中消息丢失1. 发送给消费者的时候丢失2. 解决:1. 我们MQ在接受生产者消息的时候,给生产者进行一个confirm的进行一个确认1. 如果在MQ中丢失消息的话,我们可以做一个持久化消息的一个操作1. 在发送一个消费者中丢失的话 我们可以让消费者消费完做ack确认,如果没收到这个确认的时候,我们MQ就保留这消息.2. **_重复消息怎么处理?(如何保证消息不被重复消费,如何保证消息消费的幂等性?)_**1. 重复消息出现的根本原因就是网络波动1. 生产者在发送消息的时候因为网络波动,生产者没有收到confirm的确认,再次发送消息1. 因为网络波动,MQ没有接收到ack的一个确认,再次给消费者发送消息.2. 解决:1. 因为网络波动的问题,我们是无法避免的,所以我们可以让详细携带一个全局的id,在消费消息的时候,我们在redis中或者数据库中,去查询该消息是否给消费了,如果消费了就丢弃,如果没查询到,就消费,并将消费记录持久化到redis或者数据库中3. _**如何保证消息传递的顺序性?**_1. _1. 上图的这种架构,由于MQ发送消息给消费者,由于网络波动的原因,即使MQ是先进先出的存储机制,那么也不能保证消息的顺序性2. <br />
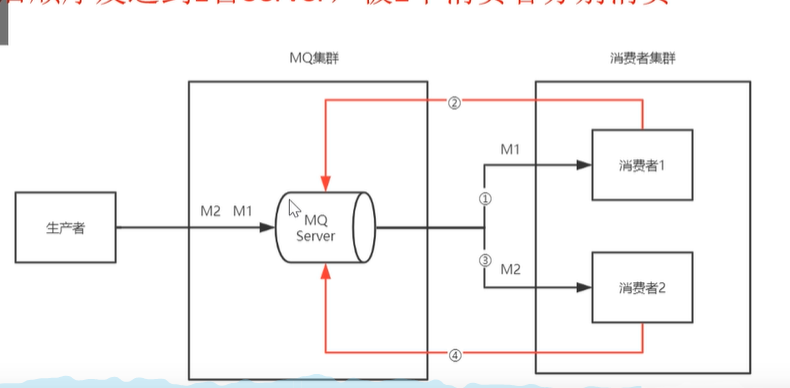
1. 上图这种架构,就是MQ给消费者1发送消息,等消费者1消费完数据,在和MQ确认,然后在给消费者2发送消息,然后再给MQ确认.但是这样的吞吐量下降,容错性降低
c.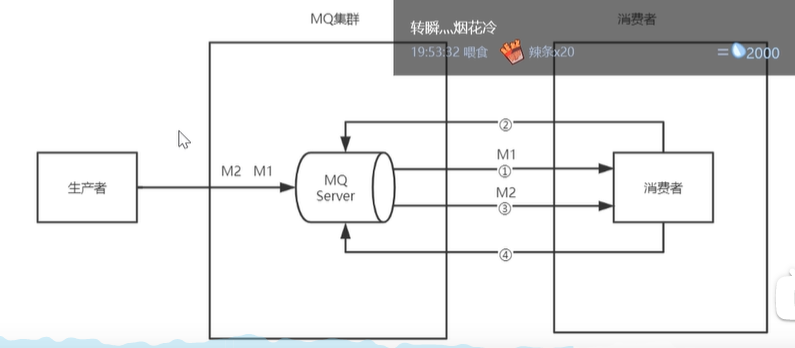
1. 如果想完全实现顺序消费的话,那就使用生产者:MQ:消费者 1:1:1但是这样子我们吞吐量下降,容错性降低d.<br />1. 最后我们可以采取上图这样一个架构,局部的保证消息消费的顺序性,1. 我们可以根据消息id,将消息放到不同的消息队列中去,由于MQ的先进先出.所以MQ给到消费者的顺序性就得到了保证,1. 为了保证我们MQ的吞吐量,队列发出的消息是可以给所有消费者消费,但是在消费者消费的时候,MQ提供了一个分段锁,将队列锁住,等待消费者消费完消息以后再继续发送下一条的消息,如果这个时候生产者再给MQ发送消息的话,其他的消息又没给锁住,其他的消费者也依然可以消费,这样子吞吐量也保证了,容错性也保证了,还不影响性能.1. 
4.大量的消息堆积处理怎么处理?
1. 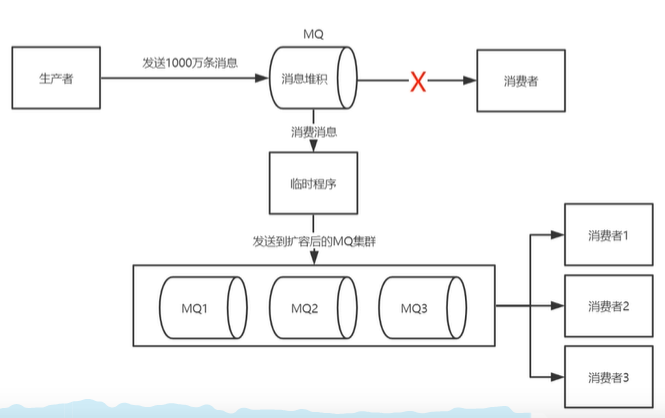1. 首先我们要先了解为什么会出现大量的消息堆积1. 网络波动导致消费者没有消费1. 消费者没有进行ack的一个确认2. 解决方案:1. 在我们解决了消费者的问题时,我们可以写一个临时程序,将消息分发给其他的MQ,然后MQ再去找多个消费者进行消费处理3. _**如何避免大量的消息堆积?**_1. 我们可以给消息设置一个过期时间,如果超时了还没有被消费的话, 我们就会将该消息转到一个死信队列,不建议直接删除.因为你没有进行一个消费
5.消息过期如何处理?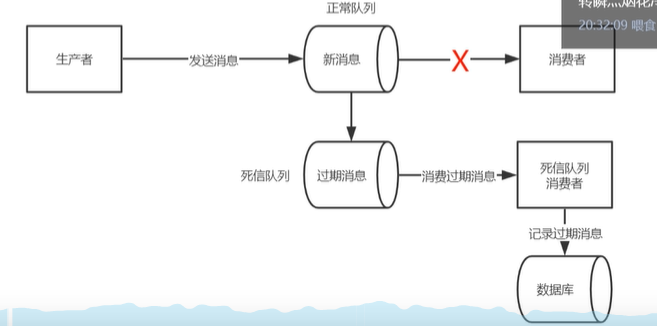
过期时间进入死信序列之后,存储到数据库中,重新查询出来再次发送给MQ在进行一次消费
1. 过期消息进入到死信队列1. 启动专门的消费者消费死信队列消息并写入到数据库记录日志1. 查询数据库消息日志,重新发送MQ
一致性问题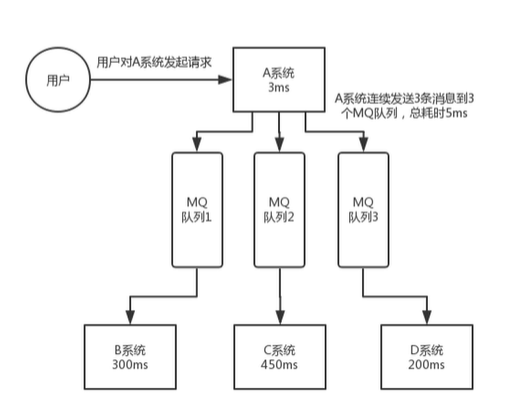
A系统处理完业务,通过MQ给BCD系统发送消息数据,如果B系统失败,C,D系统成功那么怎么保证系统的一致性?
如何保证消息队列的高可用?
RabbitMQ
普通集群
**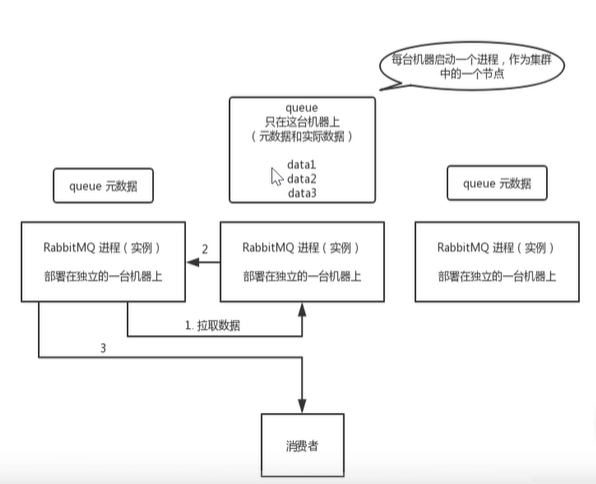
我们可以做一个集群的操作,如上图
元数据:就是相当索引
实际数据:就是真正消息
左右两个的RabbitMQ就会去中间的RabbitMQ根据元数据去找实际数据
总结:
1. 在多台及其上分别启动RabbitMQ实例1. 多个实例之间可以相互通信1. 创捷的Queue只会放在一个RabbitMQ上,其他实例都同步元数据1. 消费的时候,如果连接的没有Queue,那么当前实例会从queue所在的实例拉取数据
普通集群的特点:就是没有做到真正的高可用(万一中间那台挂掉了呢),还有就是拉取数据的时候也会有开销
镜像集群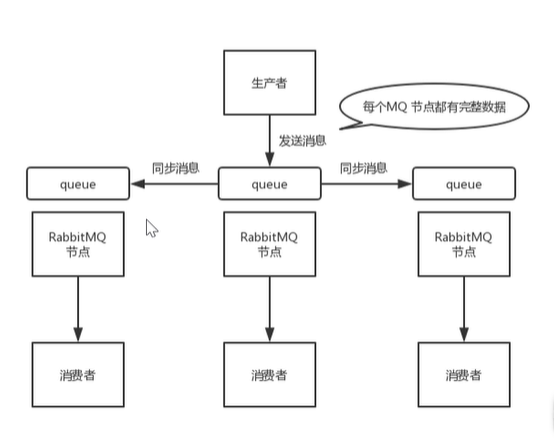
普通集群不能实现真正的高可用,是因为实际数据MQ挂了之后,其他只有元数据的MQ也相当于挂掉了
所以我们可以让全部MQ中都有实际数据来保证其中任何一个MQ挂掉,都会有数据,这样的集群模式叫镜像集群
其实就是生产者在向RabbitMQ集群发送消息的时候,如果其中RabbitMQ发送成功后,成功的就会给其他的同步消息给其他,所以生产者发送成功了一个,那么其他的他就不会管了
总结
1. 在多台机器上分别启动rabbitMQ实例1. 多个实例之间可以相互通信1. 每次生产者写消息到queue的时候,都会自动把消息同步到多个实例的queue上,每个rabbitMQ节点上都有实际数据和元数据1. 某一个节点宕机,其他节点依然保存完整数据,不影响客户端消费
RocketMQ
双主双从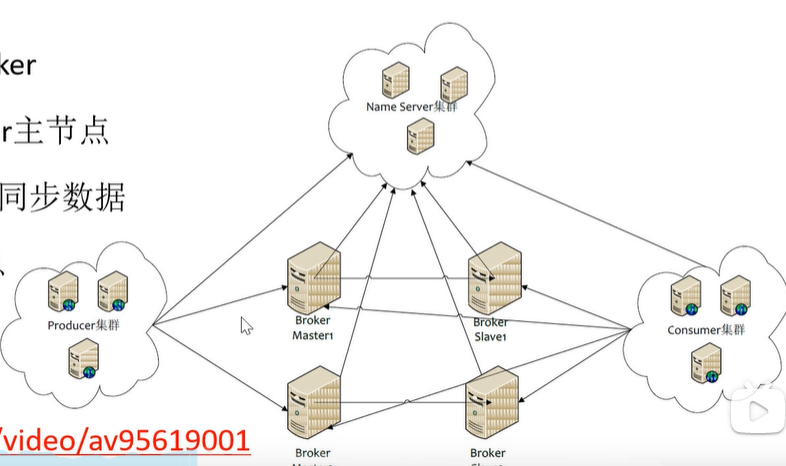
RocketMQ做集群,因为他本身就是一个分布式的一个部署,所以我们做集群就在RocketMQ上面NameServer和Broker做集群,因为本身RocketMQ里面的Broker有一个主节点一个从节点,如果主节点挂了,那么无法读数据的
所以我们要创建一个主节点一个从节点,NameServer也要做集群
总结:
1. 生产者通过NameServer发现Broker1. 生产者发送队列消息到2个Broker主节点1. Broker主节点分别和各自从节点同步数据1. 消费者从主或者从节点订阅信息
SpringCloud
Feign
Feign其实就是帮我们解决了,在此之前我们用ribbon+restTemplate的问题,硬编码
他的底层是通过JDK动态代理去实现的.
如何实现?
就是在你需要调用的远程服务的接口上贴上个@FeignClient 并指定服务名称.
然后在方法上贴上映射路径,
然后在需要的地方注入进去,然后进行调用

若有收获,就点个赞吧
0 人点赞
