location的语法
location [ = | ~ | ~ | ^~ ] uri {
…
}
上述语法中的URI部分是关键,这个URI可以是普通的字符串地址路径,或者是正则表达式,匹配成功则执行后面大括号里的相关命令。正则表达式的前面还可以有“~”或“~”等特殊字符。
“~”用于区分大小写(大小写敏感)的匹配;
“~”用于不区分大小写的匹配。还可以用逻辑操作符“!”对上面的匹配取反,即“!~”和“!~”;
“^~”的作用是先进行字符串的前缀匹配(必须以后边的字符串开头),如果能匹配到,就不再进行其他location的正则匹配了
“=”用于必须和匹配的内容相一致才行
curl -s -o /dev/null -w “%{http_code}\n” www.92test.com
curl -s -o /dev/null -w “%{http_code}\n” www.92test.com/
curl -s -o /dev/null -w “%{http_code}\n” www.92test.com/xxxx
curl -s -o /dev/null -w “%{http_code}\n” www.92test.com/documents
curl -s -o /dev/null -w “%{http_code}\n” www.92test.com/documents/
curl -s -o /dev/null -w “%{http_code}\n” www.92test.com/images/
curl -s -o /dev/null -w “%{http_code}\n” www.92test.com/images/x.jpg
curl -s -o /dev/null -w “%{http_code}\n” www.92test.com/x.jpg
curl -s -o /dev/null -w “%{http_code}\n” www.92test.com/documents/image/x.jpg
cat nginx.conf
worker_processes 1;
error_log logs/error.log;
pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
tcp_nopush on;
keepalive_timeout 65;
gzip on;
server {
listen 80;
server_name www.92test.com;
access_log logs/host.access.log main;
location / {
return 401;
}
location =/ {
return 402;
}
location = /images/ {
return 501;
}
location /documents/ {
return 403;
}
location ^~ /images/ {
return 404;
}
location ~* .(gif|jpg|jpeg)$ {
return 500;
}
}
}
[root@nginx-web02 conf]#
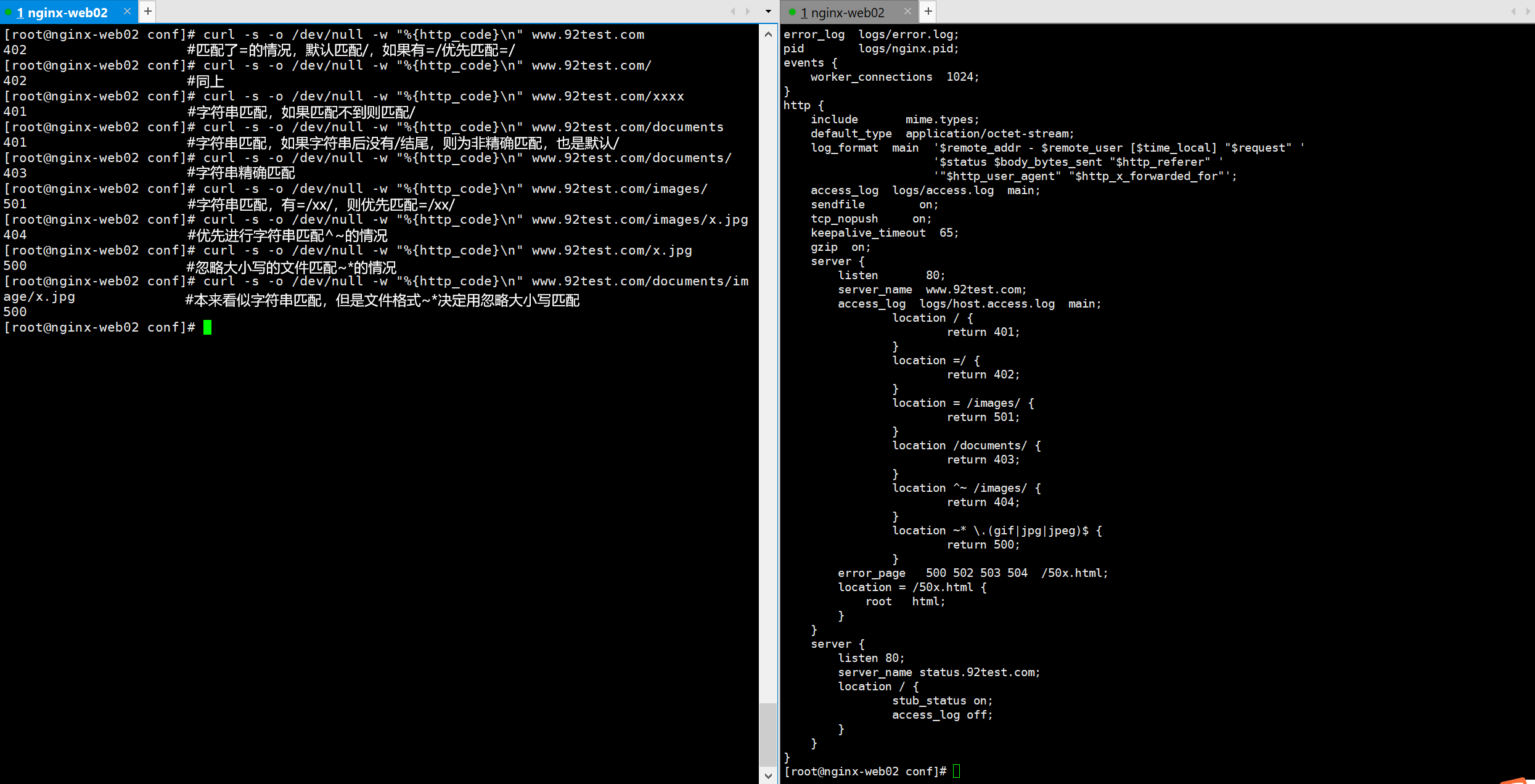
从多个location的配置匹配可以看出匹配的优先顺序
| 顺序 | 匹配标识的location | 匹配说明 |
|---|---|---|
| 1 | “ location =/ { “ | 精确匹配 |
| 2 | “ location ^~ /images/ { “ | 先进行字符串的前缀匹配,如果匹配到就不做正则匹配检查 |
| 3 | “ loction ~* \.(gif | jpg | jpeg)$ { “ | 正则匹配,*为不区分大小写 |
| 4 | “ location /documents/ { “ | 匹配常规字符串,模糊匹配,如果有正则检查,正则优先 |
| 5 | “ location / { “ | 所有location都不能匹配后的默认匹配原则 |
Nginx 的 location 实现了对请求的细分处理,有些 URI 返回静态内容,有些分发到后端服务器等,今天来彻底弄懂它的匹配规则
一个最简单的 location 的例子如下
server {
server_name website.com;
location /admin/ {
# The configuration you place here only applies to
# http://website.com/admin/
}
}
location 支持的语法
location [=|~|~*|^~|@] pattern { … },乍一看还挺复杂的,来逐个看一下。
location修饰符类型
「=」 修饰符:要求路径完全匹配
server {
server_name website.com;
location = /abcd {
[…]
}
}
url地址为http://website.com/abcd匹配 http://website.com/ABCD可能会匹配,也可以不匹配,取决于操作系统的文件系统是否大小写敏感(case-sensitive)。
ps: Mac 默认是大小写不敏感的,git 使用会有大坑。
http://website.com/abcd?param1¶m2 匹配,忽略 querystring
http://website.com/abcd/ 不匹配,带有结尾的/
http://website.com/abcde 不匹配 ,字符串不同
「~」修饰符:区分大小写的正则匹配
server {
server_name website.com;
location ~ ^/abcd$ { […]
}
}
^/abcd$这个正则表达式表示字符串必须以/开始,以$结束,中间必须是abcd
http://website.com/abcd匹配(完全匹配)
http://website.com/ABCD不匹配,大小写敏感
http://website.com/abcd?param1¶m2 匹配,忽略querystring
http://website.com/abcd/ 不匹配,不能匹配正则表达式
http://website.com/abcde 不匹配,不能匹配正则表达式
「~」不区分大小写的正则匹配
server {
server_name website.com;
location ~ ^/abcd$ { […]
}
}
http://website.com/abcd 匹配(完全匹配)
http://website.com/ABCD 匹配(大小写不敏感)
http://website.com/abcd?param1¶m2 匹配,忽略querystring
http://website.com/abcd/ 不匹配,不能匹配正则表达式
http://website.com/abcde 不匹配,不能匹配正则表达式
「^~」修饰符:前缀匹配
如果该 location 是最佳的匹配,那么对于匹配这个 location 的字符串, 该修饰符不再进行正则表达式检测。
注意,这不是一个正则表达式匹配,它的目的是优先于正则表达式的匹配 查找的顺序及优先级
当有多条 location 规则时,nginx 有一套比较复杂的规则,优先级如下:
精确匹配=
前缀匹配^~(立刻停止后续的正则搜索)
按文件中顺序的正则匹配~或~*
匹配不带任何修饰的前缀匹配。
这个规则大体的思路是 先精确匹配,没有则查找带有^~的前缀匹配,没有则进行正则匹配,最后才返回前缀匹配的结果(如果有的话)
如果上述规则不好理解,可以看下面的伪代码(非常重要)
function match(uri):
rv = NULL
if uri in exact_match:
return exact_match[uri]
if uri in prefix_match:
if prefix_match[uri] is’^~’:
return prefix_match[uri]else:
rv = prefix_match[uri]
// 注意这里没有return,且这里是最长匹配
if uri in regex_match:
return regex_match[uri]
// 按文件中顺序,找到即返回returnrv复制代码
一个简化过的Node.js写的代码如下
function ngx_http_core_find_location(uri, static_locations, regex_locations, named_locations, track){letrc =null;
letl = ngx_http_find_static_location(uri, static_locations, track);
if(l) {
if(l.exact_match) {
returnl;
}
if(l.noregex) {returnl;
}
rc = l;
}
if(regex_locations) {
for(leti =0; i < regex_locations.length; i ++) {
if(track) track(regex_locations[i].id);
letn =null;
if(regex_locations[i].rcaseless) {
n = uri.match(newRegExp(regex_locations[i].name));
}else{
n = uri.match(newRegExp(regex_locations[i].name),”i”);
}
if(n) {returnregex_locations[i];
}
}
}
returnrc;
}
案例分析
案例 1
server {
server_name website.com;
location /doc {
return701;
# 用这样的方式,可以方便的知道请求到了哪里
}
location ~* ^/document$ {
return702;
# 用这样的方式,可以方便的知道请求到了哪里
}
}
curl -I website.com:8080/document
返回HTTP/1.1 702
按照上述的规则,第二个会有更高的优先级
案例 2
server {
server_name website.com;
location ^~ /doc {
return701;
}
location ~* ^/document$ {
return702; }
}
curl http://website.com/document
返回HTTP/1.1 701
第一个前缀匹配^~命中以后不会再搜寻正则匹配,所以会第一个命中
案例 3
server {
server_name website.com;
location /docu {
return701;
}
location /doc {
return702;
}
}
curl -I website.com:8080/document
返回HTTP/1.1 701,
server {
server_name website.com;
location /doc {
return702;
}
location /docu {
return701;
}
}
curl -I website.com:8080/document
返回HTTP/1.1 701
无论配置是先还是后,都会匹配701,返回701
前缀匹配下,返回最长匹配的 location,与 location 所在位置顺序无关
案例 4
server {
listen 8080;
server_name website.com;
location ~ ^/doc[a-z]+ {
return701;
}
location ~ ^/docu[a-z]+ {
return702;
}
}
curl -I website.com:8080/document
返回HTTP/1.1 701
把顺序换一下
server {
listen 8080;
server_name website.com;
location ~ ^/docu[a-z]+ {
return702;
}
location ~ ^/doc[a-z]+ {
return701;
}
}
curl -I website.com:8080/document
返回HTTP/1.1 702
正则匹配是使用文件中的顺序,找到返回
访问认证
就是用其他的软件,加了一个访问页面需要输入密码的功能
这里不说了,百度上一大把资料

若有收获,就点个赞吧
0 人点赞
