HTTP的基本介绍
基本访问流程
打开网页
找本地host及DNS缓存是否有网页的解析记录,有则返回
本地DNS没有缓存记录,则会找DNS系统,也就是根(.)的服务器请求,有则返回
本地收到返回信息后做DNS的缓存,以备后续访问需要
说明:
根NDS服务器全球13台,DNS的解析流程与http的访问流程相似
常见请求方法
| HTTP方法 | 作用描述 |
|---|---|
| GET | 客户端请求指定资源信息,服务器返回指定资源 |
| HEAD | 只请求响应报文中的HTTP首部 |
| POST | 将客户端的数据提交到服务器,例:注册表单 |
| PUT | 从客户端向服务器传送的数据取代指定的文档内容 |
| DELETE | 请求服务器删除Request-URI所标识的资源 |
| MOVE | 请求服务器将制定的页面移至另一个网络地址 |
常见HTTP状态码
| 状态码范围 | 作用描述 |
|---|---|
| 100-199 | 用于指定客户端相应的某些动作 |
| 200-299 | 用于表示请求成功 |
| 300-399 | 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息 |
| 400-499 | 用于指出客户端的错误 |
| 500-599 | 用于指出服务器端的错误 |
| 状态代码 | 详细描述说明 |
|---|---|
| 200~OK | 服务器成功返回网页,这是成功的http请求,返回的标准状态码 |
| 301-Moved Permanently | 永久跳转,所有请求的网页将永久跳转到被设定的新的位置,例如:从baidu.com跳转到www.baidu.com |
| 302 | 临时跳转 |
| 403-Forbidden | 禁止访问,这个请求是合法的,但是服务器端因为匹配了预先设置的规则而拒绝响应客户端的请求,此类问题一般为服务器或服务权限配置不当所致。 |
| 404-Not Found | 服务器找不到客户端请求的指定页面,可能是客户端请求了服务器上不存在的资源导致 |
| 500-Internal Server Error | 内部服务器错误,服务器遇到了意料不到的情况,不能完成客户的请求。这是一个较为笼统地报错,一般为服务器的设置或者内部程序问题导致。例如SElinux开启,而又没有为http设置规则许可,客户端访问就是500 |
| 502-Bad Gateway | 坏的网关,一般是代理服务器请求后端服务时,后端服务不可用或没有完成响应网关服务器。一般为反向代理服务器下面的节点出问题导致。 |
| 503-Service Unavailable | 服务当前不可用,可能因为服务器超载或停机维护导致,或者是反向代理服务器后面没有可以提供服务的节点 |
| 504-Gateway Timeout | 网关超时,一般是网关代理服务器请求后端服务时,后端服务没有在特定的时间内完成处理请求,一般是服务器过载导致没有在指定的时间内返回数据给前端代理服务器。 |
HTTP响应报文介绍
| 报文格式 | 报文信息 |
|---|---|
| 起始行 | 协议及版本号 数字状态码 状态信息 |
| 响应头部 | 字段1:值1 字段2:值2 |
| 空行 | 空白内容 |
| 响应报文主体 | 就是html的网页 |
下面对响应报文的每个部分逐一阐述:可以打开一个网页F12查看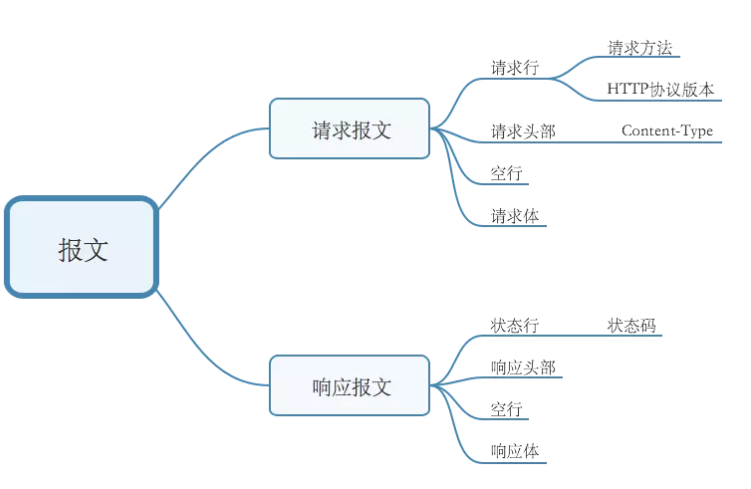
(1)起始行
响应报文的起始行,也叫状态行,用来说明服务器响应客户端请求的状况。一般为协议及版本号,数字状态码,状态情况。例如:HTTP/1.1 200 OK
(2)响应头部
和请求报文类似,起始行的后面一般有若干个头部字段。每个头部字段都包含一个名字和一个值,两者之间用冒号分隔。头部结尾也是以一个空行结束。
(3)空行
最后一个响应头部信息之后是一个空行,发送回车符和换行符,通知客户端空行下文无头部信息。
(4)响应报文主体
GET没有请求数据,POST有
响应报文主体中装载了要返回给客户端的数据。这些数据可以是文本,也可以是二进制的(图片,视频)。
例:
POST /user HTTP/1.1 //起始行 Host: www.user.com Content-Type: application/x-www-form-urlencoded Connection: Keep-Alive User-agent: Mozilla/5.0. //以上是响应头
(此处必须有一空行) //空行分割header和请求内容 name=world 请求体
比如
请求报文查看
wget 域名或ip地址 —debug
curl -v 域名或ip地址
响应报文查看
HTTP的资源类型
URL和URI介绍
URL,统一资源定位符,也被叫做网址
组成的3部分:
- 第一部分是协议,例如:http
- 第二部分是主机资源服务器IP地址或域名(端口号),例如:www.baidu.com
- 第三部分是主机资源的具体地址,如目录和文件名等,例如:html/index.html
提示:
第一部分和第二部分之间用“://”符号隔开,第二部分和第三部分用”/“符号隔开。第一部分和第二部分是不可缺少的,第三部分可以省略。
标准的URL及说明
| 协议 | 分隔符号 | IP地址域名 | 分隔符号 | 资源目录地址 |
|---|---|---|---|---|
| http | :// | www.baidu.com | / | html/index.html |
URI,统一资源标识符,唯一的资源标识。
URN,统一资源命名符,通过名字标识资源。
通俗的说,URL和URN是URI的子集,被包含在URI里面了
看下面这个例子,这个人的解释通俗易懂
链接:https://www.zhihu.com/question/21950864/answer/154309494
统一资源标志符URI就是在某一规则下能把一个资源独一无二地标识出来。
拿人做例子,假设这个世界上所有人的名字都不能重复,那么名字就是URI的一个实例,通过名字这个字符串就可以标识出唯一的一个人。
现实当中名字当然是会重复的,所以身份证号才是URI,通过身份证号能让我们能且仅能确定一个人。
那统一资源定位符URL是什么呢。也拿人做例子然后跟HTTP的URL做类比,
就可以有:动物住址协议://地球/中国/浙江省/杭州市/西湖区/某大学/14号宿舍楼/525号寝/张三.人。
可以看到,这个字符串同样标识出了唯一的一个人,起到了URI的作用,所以URL是URI的子集。
URL是以描述人的位置来唯一确定一个人的。
在上文我们用身份证号也可以唯一确定一个人。
对于这个在杭州的张三,我们也可以用:身份证号:123456789来标识他。
所以不论是用定位的方式还是用编号的方式,我们都可以唯一确定一个人,都是URl的一种实现,而URL就是用定位的方式实现的URI。
回到Web上,假设所有的Html文档都有唯一的编号,记作html:xxxxx,xxxxx是一串数字,即Html文档的身份证号码,这个能唯一标识一个Html文档,那么这个号码就是一个URI。
而URL则通过描述是哪个主机上哪个路径上的文件来唯一确定一个资源,也就是定位的方式来实现的URI。
对于现在网址我更倾向于叫它URL,毕竟它提供了资源的位置信息,如果有一天网址通过号码来标识变成了http://741236985.html,那感觉叫成URI更为合适,不过这样子的话还得想办法找到这个资源咯…
网页的类型
静态页面
动态页面
1)网页扩展名后缀常见为:.asp,.aspx,.php,.jsp,.do,cgi等
2)网页一般以数据库技术为基础,大大降低了网站维护的工作量
3)采用动态网页技术的网站可以实现更多的功能,如用户注册,用户登录,在线调查,投票,用户管理,订单管理,发博文等等
4)动态网页并不是独立存在于服务器上的网页文件,当用户请求服务器上的动态程序时,服务器解析这些程序并可能读取数据库返回一个完整的网页内容。
5)动态网页中的“?”在搜索引擎的收录方面存在一定问题,搜索引擎一般不会从一个网站的数据库中访问全部网页,或者出于技术等方面的考虑,搜索蜘蛛一般不会去抓去网址中“?”后面的内容,因此在企业通过搜索引擎进行推广时,需要针对采用动态网页的网站做一定的技术处理(伪静态技术),以便适应搜索因穷的抓取要求。
6)程序在服务器端解析,这相当于顾客点餐,饭店厨师做饭做菜,耗时长,效率低。由于程序在服务端解析,因此,会消耗大量的CPU和内存,I/O等资源,并且多数还要读取数据库等服务,因此,其访问效率远不如静态网页,在服务端解析动态程序的服务常见的有PHP引擎,Java容器(tomcat,resin,jboss,weblogic)
流量度量
IP
就是这个网页有多少个IP来访问
PV
就是页面点击量
UV
独立的电脑访问一个地址,计数为1
并发数统计
1)统计当下时刻的linux的网络连接数并发,netstat -an|grep -i “est”|wc -l
2)nginx web 层 active status
3) QPS
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 80% ) / ( 每天秒数 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
磁盘读写性能就往磁盘里dd一个文件,然后算呗

若有收获,就点个赞吧
0 人点赞
