分类原理的理解
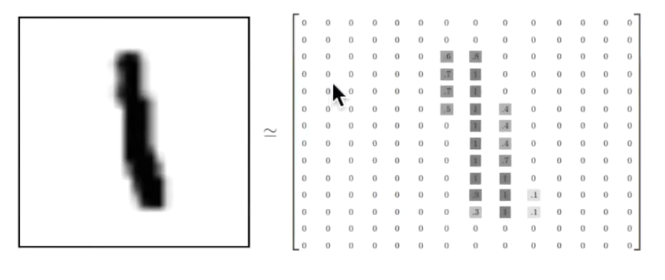
像该张图片一样,该图片一共有28X28个像素点,在白色部分为0,不为白色的部分为有数字的像1、2、3
上面的性质为器在x轴平面上的特性,在y轴方向上,其为一个10行1列的矩阵,在1的位置上有1且在其他方向上都为0的时候为1、同理在2的位置上为1且在其他位置上都为0的时候表示数字2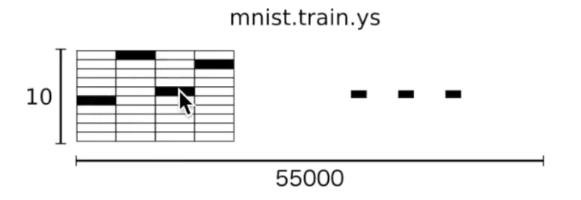
tensorflow的classification的主要构架
import tensorflow as tffrom tensorflow.example.tutorials.mnist import input_datamnist = input_data.read_data_sets('MNIST_data',one_hot=True)#获取网上开源的数据集def add_layer(input,in_size,out_size,acitation_function=None):#添加层函数的定义with tf.name_scope('layer'):with tf.name_scope('wights'):Weight=tf.Variable(tf.random_normal([in_size,out_size]),name='W')##定义一个in_size X out_size的矩阵with tf.name_scope('biases'):biases=tf.Variable(tf.zeros([1,out_size])+0.1,name='B')#biases初始值推荐不为0,所以加上0.1with tf.name_scope('Wx_plus_b'):Wx_plus_b=tf.matmul(input,Weight)+biases #这里看似是两个矩阵的相乘,但是实际上是一个数乘以一个数,最终是一个只有一列的数据乘以只有一行的数据if acitation_function is None:outputs=Wx_plus_belse:outputs=acitation_function(Wx_plus_b)return outputs##为input定义placeholderxs= tf.placeholder(tf.float32,[None,784])#28x28,表示x数据有784列,行不定,该数据的大小主要取决于图片的像素点的多少ys= tf.placeholder(tf.float32,[None,10])#与上面同理,表示y数据有10列,行不定,该数据的大小取决于图片的y轴的数据的多少
为机器的学习添加层
prediction=add_layer(xs,784,10,activation_function=tf.nn.softmax)
在自行定义的add_layer的函数中,第一个参数表示输入的数据,第二个参数表示输入的数据的大小,第三个参数表示输出的数据的大小,第四个参数表示使用的激励函数
在该过程中,我们采用的是softmax这个激励函数
softmax函数的详解
softmax函数的名字可以分为soft和max两部分,其中soft是该函数的最大的特点
在通常的情况下,我们会使用numpy或者tensorflow模块来对数据求最大值,但是使用该方式的求法通常求得的是数据的hardmax,就是求出一组数据的客观意义上的最大值
但是在实际的生活工作问题中,我们常常面临的不是求简单的最大值,我们更加希望可以求出每个输出分类的概率值,
比如对于文本分类来说,一篇文章或多或少包含着各种主题信息,我们更期望得到文章对于每个可能的文本类别的概率值(置信度),可以简单理解成属于对应类别的可信度。所以此时用到了soft的概念,Softmax的含义就在于不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
cross_entropy算法的计算常常可以于softmax结合来使用,以达到classification的目的,实际上,cross_entropy可以理解为就是计算了一个loss
train_step=tf.train.GradienDescentOptimizer(0.5).minimize(cross_entropy)
精确度计算compute_accuracy函数的定义
def compute_accuracy(v_xs,v_ys):global predictiony_pre = sess.run(prediction,feed_dict={xs:v_xs})correct_prediction = tf.equal(tf.argmax(y_pre,1),tf.argmax(v_ys,1))#对比预测值与真实数据的差别accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))result = sess.run(accuracy,feed_dict={xs:v_xs,ys:v_ys})return result
最终代码块的运行程序
sess=tf.Session()sess.run(tf.initailize_all_variables())for i in range(1000):batch_xs,batch_ys = mnist.train.nextbatch(100)#提取少部分的数据sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys})if i%50 == 0:print(compute_accuracy(mnist.test.images,mnist.test.labels))
MNIST_data中的数据的说明
在MNIST数据集中的每张图片由28x28个像素点构成,每个像素点使用一个灰度值表示,我们将28x28个像素点展开为一个一维的行向量,这些行向量就是图片数组中的行,每行784个值,就是说每行代表一个图片
load_mnist 函数返回的第二个数组(labels) 包含了相应的目标变量, 也就是手写数字的类标签(整数 0-9).
tf.argmax函数解析
该函数中的参数一般使用两个,在本实验中我们使用两个参数,第一个参数为要处理的数组,第二个参数为针对处理的数据为行还是列,求出每行或每列的最大的之,并返回最大值所在的索引。
在本实验中,我们使用该函数来计算y_pre和v_ys中每列的最大值并返回索引
tf.equal函数解析
该函数按照其英文名词的解释就是用来比较两个数组的值是否相等,本实验中用来计算y_pre和v_ys中每列的最大值的索引是否相等,返回值是一个布尔类型的数组

若有收获,就点个赞吧
0 人点赞
