在使用流之前,首先需要拥有一个数据源,并通过StreamAPI提供的一些方法获取该数据源的流对象。数据源可以有多种形式:
一、创建
Stream可以通过集合创建。
这种数据源较为常用,通过stream()方法即可获取流对象:
1、Collection.stream()
通过 java.util.Collection.stream() 方法用集合创建流,支持Collection下面的子类,List,Set,Map 等等
1.1、list
// 1、通过 java.util.Collection.stream() 方法用集合创建流List<String> list = Arrays.asList("a", "b", "c", "d");// 创建一个顺序流Stream<String> stream = list.stream();// 创建一个并行流Stream<String> parallelStream = list.parallelStream();
1.2、Set
Set<String> set = new HashSet<>(Arrays.asList("A", "B", "C"));
Stream<String> stream5 = set.stream();
System.out.println("stream5:" + stream5.collect(joining()));
1.3、Map
Map<String, String> map = new HashMap<>();
map.put("1", "A");
map.put("2", "B");
map.put("3", "C");
Stream<String> stream6 = map.values().stream();
System.out.println("stream6:" + stream6.collect(joining()));
2、Arrays.stream(T[] array)
用数组创建流
通过Arrays类提供的静态函数stream()获取数组的流对象:
// 2、使用 Arrays.stream(T[] array),用数组创建流
int[] array = {1, 3, 5, 7, 9};
IntStream intStream = Arrays.stream(array);
3、Stream的静态方法
通过Stream的静态方法of(),iterate(),generate()创建
直接将几个值变成流对象:
3.1、Stream.of()
- 可变参数
Stream<String> stream1 = Stream.of("A", "B", "C"); System.out.println("stream1:" + stream1.collect(joining()));输出:stream1:ABC
- 数组
String[] values = new String[]{"A", "B", "C"}; Stream<String> stream2 = Stream.of(values); System.out.println("stream2:" + stream2.collect(joining()));输出:stream2:ABC
3.2、Stream.iterate()
创建无限的流Stream
//从0开始,逐次加3,到4为止
Stream<Integer> limit = Stream.iterate(0, (x) -> x + 3).limit(4);
limit.forEach(System.out::println);
3.3、Stream.generate()
Stream<Double> doubleStream = Stream.generate(Math::random).limit(3);
doubleStream.forEach(System.out::println);
4、Pattern
正则匹配进行生成Stream,本质上和数组的方式类似
String value = "A B C";
Stream<String> stream8 = Pattern.compile("\\W").splitAsStream(value);
System.out.println("stream8:" + stream8.collect(joining()));
5、Files.lines()
文件生成Stream
try {
Stream<String> stream9 = Files.lines(Paths.get("d:/data.txt"));
System.out.println("stream9:" + stream9.collect(joining()));
} catch (IOException e) {
e.printStackTrace();
}
PS:Java7简化了IO操作,把打开IO操作放在try后的括号中即可省略关闭IO的代码。 使用try-resource
try(Stream lines = Files.lines(Paths.get(“文件路径名”),Charset.defaultCharset())){
//可对lines做一些操作
}catch(IOException e){
}
2、区别
stream:
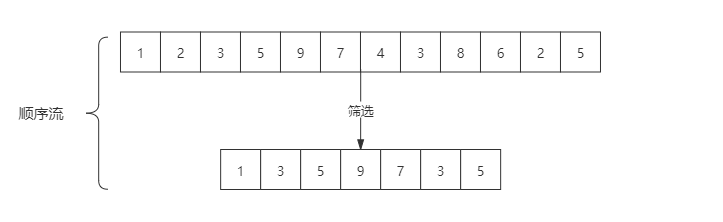
parallelStream:
并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。最后合并每个数据块的计算结果。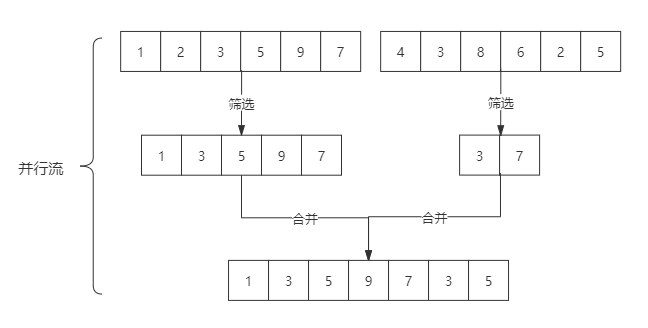
如果流中的数据量足够大,并行流可以加快处速度。
除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流:
Optional<Integer> findFirst = list.stream().parallel().filter(x->x>6).findFirst();
将一个并发流转成顺序的流只要调用 sequential() 方法
stream.parallel().filter(...).sequential().map(...).parallel().reduce();
这两个方法可以多次调用,只有最后一个调用决定这个流是顺序的还是并发的。
并发流使用的默认线程数等于你机器的处理器核心数。
通过这个方法可以修改这个值,这是全局属性
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12");
并非使用多线程并行流处理数据的性能一定高于单线程顺序流的性能,因为性能受到多种因素的影响。
如何高效使用并发流的一些建议:
- 如果不确定, 就自己测试。
- 尽量使用基本类型的流 IntStream, LongStream, DoubleStream
- 有些操作使用并发流的性能会比顺序流的性能更差,比如limit,findFirst,依赖元素顺序的操作在并发流中是极其消耗性能的。findAny的性能就会好很多,应为不依赖顺序。
- 考虑流中计算的性能(Q)和操作的性能(N)的对比, Q表示单个处理所需的时间,N表示需要处理的数量,如果Q的值越大, 使用并发流的性能就会越高。
- 数据量不大时使用并发流,性能得不到提升。
- 考虑数据结构:并发流需要对数据进行分解,不同的数据结构被分解的性能时不一样的。
流的数据源和可分解性
| 源 | 可分解性 |
|---|---|
ArrayList |
非常好 |
LinkedList |
差 |
IntStream.range |
非常好 |
Stream.iterate |
差 |
HashSet |
好 |
TreeSet |
好 |
流的特性以及中间操作对流的修改都会对数据对分解性能造成影响。 比如固定大小的流在任务分解的时候就可以平均分配,但是如果有filter操作,那么流就不能预先知道在这个操作后还会剩余多少元素。
考虑终端操作的性能:如果终端操作在合并并发流的计算结果时的性能消耗太大,那么使用并发流提升的性能就会得不偿失

若有收获,就点个赞吧
0 人点赞
